| 3.深度强化学习 | 您所在的位置:网站首页 › 伪代码的特点 › 3.深度强化学习 |
3.深度强化学习
|
文章地址: PPO: Proximal Policy Optimization Algorithms 一. PPO资料PPO原理讲解BLOG①:这篇blog详细讲了PPO算法的产生过程及原理,包含部分理论推导,看完这篇blog基本就理解PPO了。 PPO原理讲解BLOG②:可参考,其中包含部分tensorflow实现代码。 二. PPO原理简述 2.1 背景PPO是基于基本的Policy Gradient进行改进的算法,关于PG的更新过程这里不详细描述了,可以根据上述BLOG①或其他资料推导理解一下即可。总之,得到的关于PG的策略更新过程的loss可以写为: L ( θ ) = E [ l o g π ( a ∣ s , θ ) f ( s , a ) ] = ∑ l o g π ( a ∣ s , θ ) f ( s , a ) L(\theta) = \mathrm{E} [log\pi(a|s,\theta)f(s,a)]= \sum log\pi(a|s,\theta)f(s,a) L(θ)=E[logπ(a∣s,θ)f(s,a)]=∑logπ(a∣s,θ)f(s,a) L P G ( θ ) = E ^ t [ log π θ ( a t ∣ s t ) A ^ t ] L^{P G}(\theta)=\hat{\mathbb{E}}_{t}\left[\log \pi_{\theta}\left(a_{t} \mid s_{t}\right) \hat{A}_{t}\right] LPG(θ)=E^t[logπθ(at∣st)A^t] 其中 f ( s , a ) f(s,a) f(s,a)是对状态动作对的价值评估,计算该值有多种方式(可查看BLOG①),通常采用Advantage的方式更优,但为了更好的平衡偏差和方差的问题,一般采用GAE即 T D ( λ ) TD(\lambda) TD(λ)的形式 T D ( λ ) TD(\lambda) TD(λ)可以理解为对n个n-step 的估计值作加权平均得到的结果 2.2 原理 PG所存在的一个问题是在更新计算Advantage时并不准确,实际上是有偏差的,如果policy一次更新得太远,那么下次基于更新后的policy进行采样的动作就会存在很大的偏差,如此就会陷入一个恶性循环,TRPO的核心思想是将policy的更新约束在一个trust region内,这样就可保证policy整个更新过程是单调上升的。如下图所示: IS实际上实现的过程就是用一种分布的采样均值来代替另一种分布的期望 PPO的主要贡献是提出了clipped surrogate objective,如下所示 ϵ \epsilon ϵ通常来说是一个比较小的值,论文中作者设置为0.2时在比较好的实验效果,这个clip操作实际上是限制了策略更新的幅度,避免策略的一次更新偏离太远。 PPO论文中还给出了对TRPO方法的一种近似/替代 PPO最终的loss如下: openai dota five对sample reuse有不同的定义 先写到这里吧,后续有好的资料或者代码实现再更新 |
 这里注意TRPO的loss与之前所推导得到的PG的loss不一样,这是由于采用了importance sampling。TRPO是on-policy的,为什么这里采用IS?对于TRPO及PPO而言,虽然是基于on-policy的思想构建算法,但是对于on-policy而言,采样得到的数据仅训练一次就丢掉有些浪费,因此通常是将一次采样得到的经验数据分为多个minibatch进行训练,一般的还会sample reuse一下。如此一来,策略更新时所依赖的经验数据并非是实时采样得到的数据,这样就会造成一种off-policy的情况,因此就会引入importance sampling进行纠正。
这里注意TRPO的loss与之前所推导得到的PG的loss不一样,这是由于采用了importance sampling。TRPO是on-policy的,为什么这里采用IS?对于TRPO及PPO而言,虽然是基于on-policy的思想构建算法,但是对于on-policy而言,采样得到的数据仅训练一次就丢掉有些浪费,因此通常是将一次采样得到的经验数据分为多个minibatch进行训练,一般的还会sample reuse一下。如此一来,策略更新时所依赖的经验数据并非是实时采样得到的数据,这样就会造成一种off-policy的情况,因此就会引入importance sampling进行纠正。 note that the probability ratio
r
r
r is clipped at
1
−
ϵ
1-\epsilon
1−ϵ or
1
+
ϵ
1+\epsilon
1+ϵ depending on whether the advantage is positive or negative
note that the probability ratio
r
r
r is clipped at
1
−
ϵ
1-\epsilon
1−ϵ or
1
+
ϵ
1+\epsilon
1+ϵ depending on whether the advantage is positive or negative 即使用一个penalty代替TRPO中的constraint。这里作者引入了一个系数
β
\beta
β,文中针对
β
\beta
β又给出了两种情况,一种是
β
\beta
β固定的情况一种是自适应调整
β
\beta
β值的情况。具体查看论文即可
即使用一个penalty代替TRPO中的constraint。这里作者引入了一个系数
β
\beta
β,文中针对
β
\beta
β又给出了两种情况,一种是
β
\beta
β固定的情况一种是自适应调整
β
\beta
β值的情况。具体查看论文即可 最终得到的PPO的算法伪代码如下:
最终得到的PPO的算法伪代码如下:  这里借鉴BLOG①的资料讨论一下PPO在一次iteration中更新了多少次?一次sample reuse的概念和使用: 从算法伪代码中可以看出,PPO单次采样NT的经验数据,然后按照某个minibatch size训练K个epochs:假设设置K=3,minibatch size = NT/4,因此就可以得到PPO在一次iteration中就更新了12次。 这里的K把它定义为sample reuse ratio,如果这个ratio=1,那么就相当于完全on-policy,使得经验数据利用率很低。最理想的情况下是一次采样多次训练更新,一直更新到clip函数的边界,这样就可以最大化的利用单次所采样的经验数据。 按照上述推导过程,也就是说actor或worker越大,单次采样的数据量也就越多,在控制训练次数前提下的batch size也就越大,对梯度的估计也就越准确,bias也就越小,效果越好。
这里借鉴BLOG①的资料讨论一下PPO在一次iteration中更新了多少次?一次sample reuse的概念和使用: 从算法伪代码中可以看出,PPO单次采样NT的经验数据,然后按照某个minibatch size训练K个epochs:假设设置K=3,minibatch size = NT/4,因此就可以得到PPO在一次iteration中就更新了12次。 这里的K把它定义为sample reuse ratio,如果这个ratio=1,那么就相当于完全on-policy,使得经验数据利用率很低。最理想的情况下是一次采样多次训练更新,一直更新到clip函数的边界,这样就可以最大化的利用单次所采样的经验数据。 按照上述推导过程,也就是说actor或worker越大,单次采样的数据量也就越多,在控制训练次数前提下的batch size也就越大,对梯度的估计也就越准确,bias也就越小,效果越好。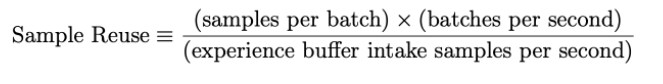 其含义就是每秒样本使用量除以样本的生成量
其含义就是每秒样本使用量除以样本的生成量【本文地址】