| python爬虫自学宝典 | 您所在的位置:网站首页 › 今年湖人夺冠过程图片高清大图视频下载 › python爬虫自学宝典 |
python爬虫自学宝典
|
前文回顾 获取高清图片的任务交给爬虫也是一个不错的选择,现在很多图片网站的图片,大部分都是用爬虫进行爬取的。原因很简单,与其一张一张入库,不如直接利用爬虫爬取入库,效率简直是天差地别。本节呢,讲述如何到专门的图片发布网址上爬取高清图片并且下载下来。 登录以下网址: https://unsplash.com 进去之后,可见这是一个专门为图片发布提供的网址,其主页结构如下: scrapy shell -s user-agent=‘Mozilla/5.0’ https://unsplash.com/napi/photos?page=1&per_page=12 上述表示我们调试的是第一页,每页图片加载数目为12; 再在调试控制台上输入: response.text response.text,打印响应信息,以便我们阅览。其结果如下: import json len(json.loads(response.text)) 可以看到如下输出结果: 上面已经将我们要爬取的网站网页结构讲清楚了,接下来就是实施了。 首先,我们需要创建一个爬虫项目,本次演示创建的爬虫项目名为:downloadImgAtUnsplash。方法如下: win+R——>cmd打开DOS窗口,输入如下命令: scrapy startproject downloadImgAtUnsplash 结果如下: cd downloadImgAtUnsplash scrapy genspider demo unsplash.com 其结果如下: 修改虫子demo: # -*- coding: utf-8 -*- import scrapy import json from downloadImgAtUnsplash.items import DownloadimgatunsplashItem class DemoSpider(scrapy.Spider): name = 'demo' allowed_domains = ['unsplash.com'] start_urls = ['https://unsplash.com/napi/photos?page=1&per_page=12'] def __init__(self, **kwargs): super().__init__(**kwargs) self.index = 1 def parse(self, response): photo_list = json.loads(response.text) for info in photo_list: items = DownloadimgatunsplashItem() items['id'] = info['id'] items['download'] = info['links']['download'] yield items self.index += 1 nextLink = 'https://unsplash.com/napi/photos?page=' + str(self.index) + '&per_page=12' yield scrapy.Request(nextLink, callback=self.parse)修改管道流文件pipeline.py,如下: # -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html from urllib.request import * import os class DownloadimgatunsplashPipeline(object): def __init__(self): path = 'images' if not os._exists(path): os.mkdir(path) def process_item(self, item, spider): downLink = item['download'] + '?force=true' try: with urlopen(downLink) as imgInfo: data = imgInfo.read() with open('images/' + item['id'] + '.jpg', mode='wb+') as file: file.write(data) except: print("DownloadError:I don't know why!!!") def close_spider(self, spider): print("Info scrapy end!!!")在上述的代码中,初始化文件中判断了下载目录是否存在。在parse函数中,有一段代码为downLink = item[‘download’] + ‘?force=true’;这并不是我们非要加+?force=true的,因为要模仿浏览器行为加的。如果你登录到我们要爬取的图片网址,点击下载图片时,会看到状态栏有这个东西。 还有一段代码值得说一下,如:with open(‘images/’ + item[‘id’] + ‘.jpg’, mode=‘wb+’) as file。为什么用wb打开文件呢?因为图片只能用字节形式保存下来。提个醒,如果你想要读取音乐文件,图片文件,视频文件,其实都要用字节流来控制。 修改setting.py文件如下: BOT_NAME = 'downloadImgAtUnsplash' SPIDER_MODULES = ['downloadImgAtUnsplash.spiders'] NEWSPIDER_MODULE = 'downloadImgAtUnsplash.spiders' ROBOTSTXT_OBEY = True DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', 'user-agent': 'Mozilla/5.0' } ITEM_PIPELINES = { 'downloadImgAtUnsplash.pipelines.DownloadimgatunsplashPipeline': 300, }setting.py中,内容很多,大部分都是注释,不过你只需要取消上面我列出的两个注释就行了。一个是默认请求头,一个是项目管道流。 该写的都写完了,接下来在dos窗口运行我们的虫子,到dos窗口下,cd/d定位到爬虫项目下,输入如下命令: scrapy crawl demo 结果如下: 本节讲述了如何爬取高清图片,其中我想让大家知道的是,爬虫最关键的并不是些什么项目文件,而是要看的懂人家网站的结构。只有你看懂了网站结构,你才可以如鱼得水般的使用爬虫。下一节,讲述如何反放爬虫,只有你读懂了下一节,你才可以算作一个爬虫高手。 欲知后事如何,且听下回分解。 |
 如果你要浏览这个网页的信息,除了上面的那部分的菜单栏外,只能下滑了解其他信息。这种结构,我们通常称之为“瀑布结构”,意思就是像瀑布一样,只能下滑浏览网页,即不存在翻页功能。使用瀑布结构的网页还有任天堂游戏官网等网址。废话不多说了,我们查看这个网址的网页元素,即HTML代码(一般按F12):
如果你要浏览这个网页的信息,除了上面的那部分的菜单栏外,只能下滑了解其他信息。这种结构,我们通常称之为“瀑布结构”,意思就是像瀑布一样,只能下滑浏览网页,即不存在翻页功能。使用瀑布结构的网页还有任天堂游戏官网等网址。废话不多说了,我们查看这个网址的网页元素,即HTML代码(一般按F12): 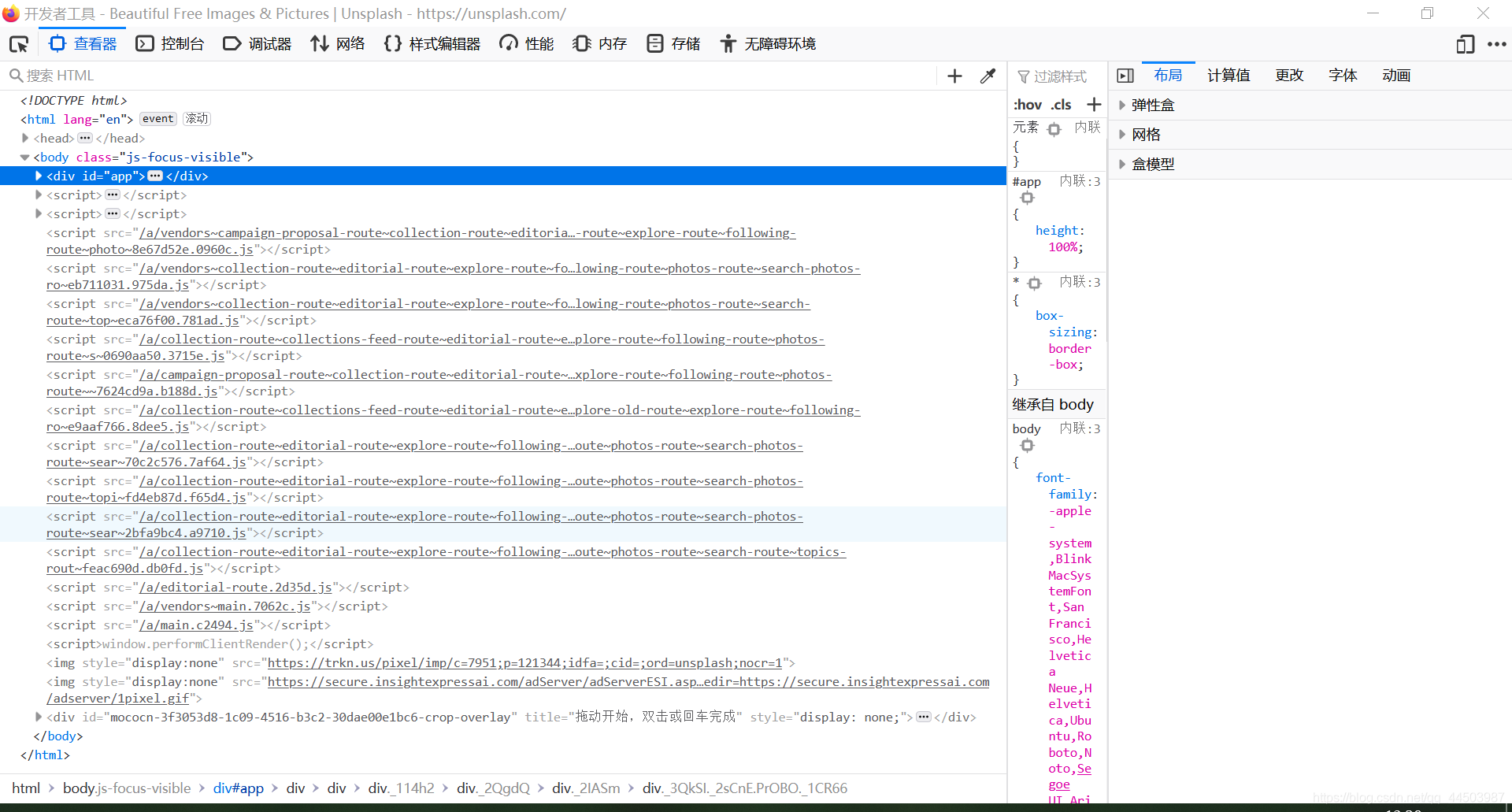 可以清晰的看见,这个网址上,导出都是脚本代码,也就是说这个网址是动态控制的。不过不要紧,只要找到网页资源的出处,就能准确的爬取网址的图片。打开网络控制台(chrome是NETWORK,IE和火狐都准确的标明了中文),如下:
可以清晰的看见,这个网址上,导出都是脚本代码,也就是说这个网址是动态控制的。不过不要紧,只要找到网页资源的出处,就能准确的爬取网址的图片。打开网络控制台(chrome是NETWORK,IE和火狐都准确的标明了中文),如下: 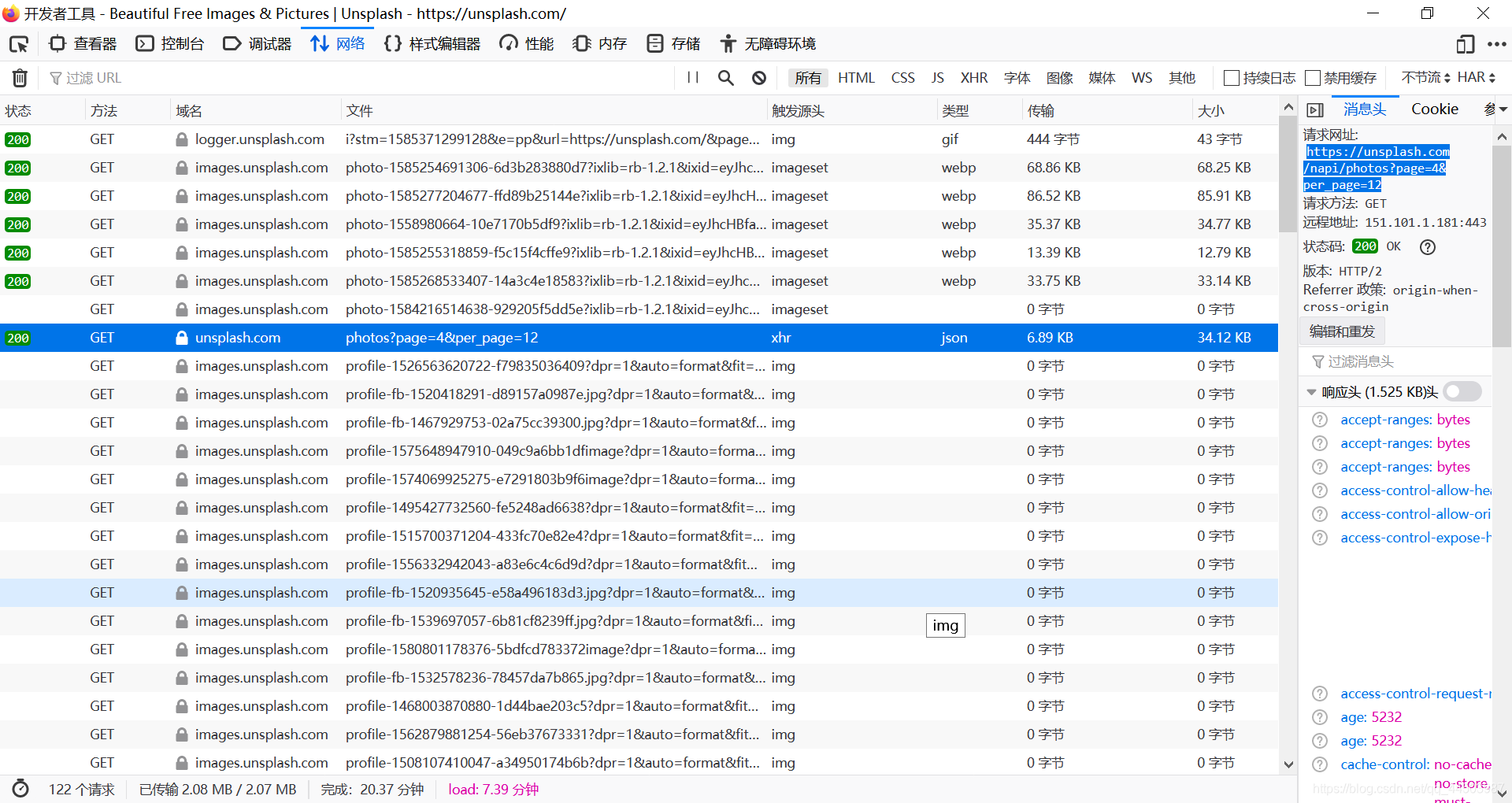 清晰可见,上面类型出有个json的,而且左边的url是“https://unsplash.com/napi/photos?page=4&per_page=12”。这个就是实现瀑布结构的关键,其中page代表第几页,per_page代表每页加载的数量。 使用scrapy shell 工具来调试一下这个网址,顺便变一下上面的page和per_page参数,win+R——>cmd打开dos窗口,输入如下命令:
清晰可见,上面类型出有个json的,而且左边的url是“https://unsplash.com/napi/photos?page=4&per_page=12”。这个就是实现瀑布结构的关键,其中page代表第几页,per_page代表每页加载的数量。 使用scrapy shell 工具来调试一下这个网址,顺便变一下上面的page和per_page参数,win+R——>cmd打开dos窗口,输入如下命令: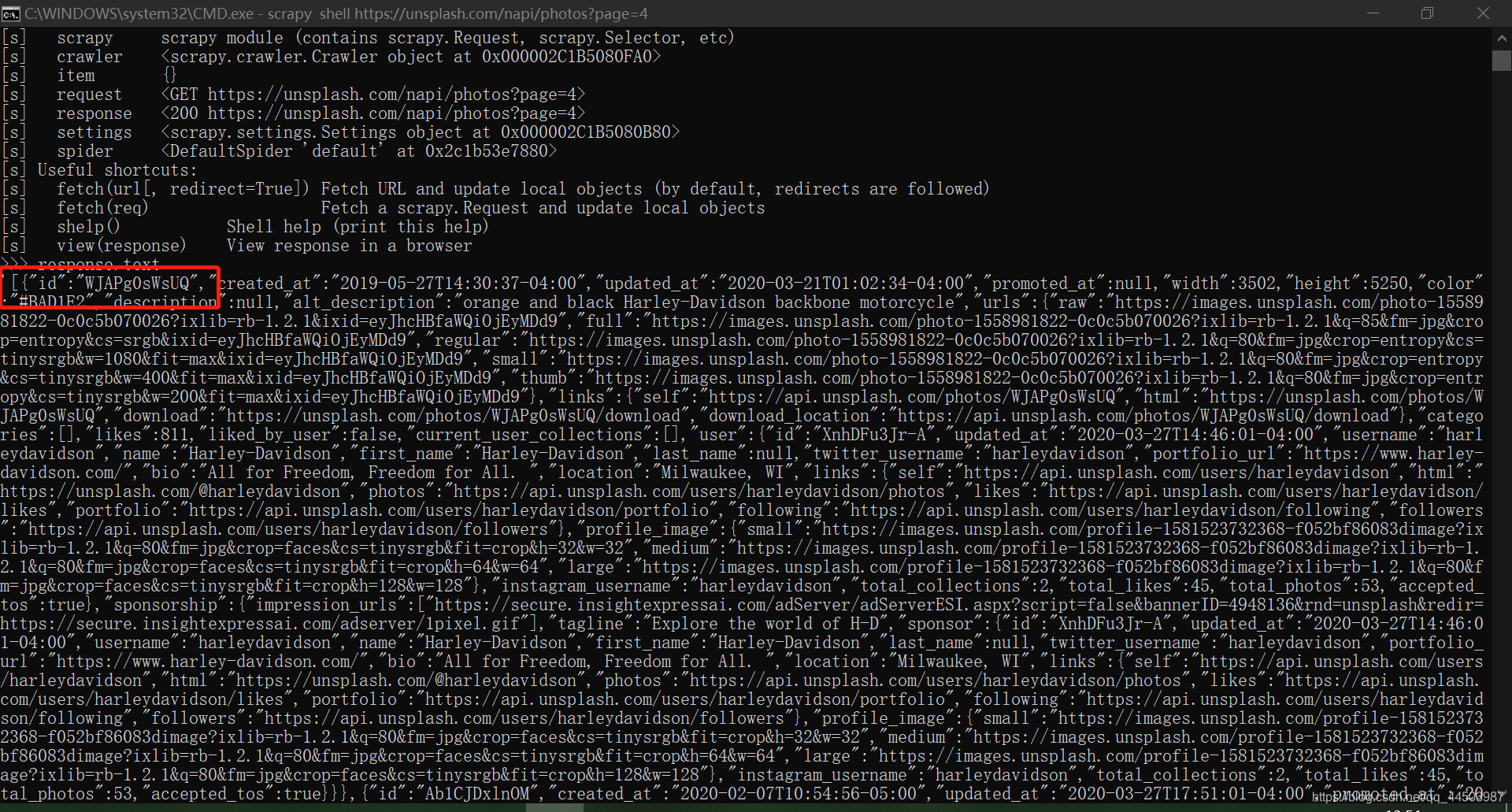 注意我上面的红框,表示是一个字符串,且是由list列表内嵌dict字典构成的字符串。所以说我们可以利用json.loads()函数,将这些信息导出来,为我们所用。 再在dos命令行中输入如下命令:
注意我上面的红框,表示是一个字符串,且是由list列表内嵌dict字典构成的字符串。所以说我们可以利用json.loads()函数,将这些信息导出来,为我们所用。 再在dos命令行中输入如下命令: 嘿,奇怪了,为什么只有十个数值呢?我们明明调试的时候,传入的per_page参数值为12,但是为什么只有十个呢?其实很简单,因为第一页就只有十个值,后面两个值自动被忽略。 接下来,我们需要了解response.text返回信息中,List镶嵌的dict数据结构,两种办法,一种是你直接找个空白文档,复制上面response.text打印出来的信息到空白文档,自信的查看,不过我估计,你会头晕。第二种方法就相对简单一些了,直接在浏览器地址输入我们dos控制台调试的网址就行了。 给浏览器地址栏输入:https://unsplash.com/napi/photos?page=1&per_page=12,可以看到如下内容:
嘿,奇怪了,为什么只有十个数值呢?我们明明调试的时候,传入的per_page参数值为12,但是为什么只有十个呢?其实很简单,因为第一页就只有十个值,后面两个值自动被忽略。 接下来,我们需要了解response.text返回信息中,List镶嵌的dict数据结构,两种办法,一种是你直接找个空白文档,复制上面response.text打印出来的信息到空白文档,自信的查看,不过我估计,你会头晕。第二种方法就相对简单一些了,直接在浏览器地址输入我们dos控制台调试的网址就行了。 给浏览器地址栏输入:https://unsplash.com/napi/photos?page=1&per_page=12,可以看到如下内容:  可以清晰的看大,每项就是一个图片,每张图片包含id,create_at,update_at等图片信息。其中的links属性为图片的链接资源信息,links下的self代表浏览图片时的url,download才是要下载的url,download_location表示什么鬼东西,我也不知道,我试着点了一下,反馈信息为请求错误。不过让我从字面意思理解为下载地点,难道是和cook有关联?不管了,先不想那么多,最主要的任务是先下载下来图片。其实呢,上面的links链接,你可以随便的点,随便的看,反正没啥大的影响。
可以清晰的看大,每项就是一个图片,每张图片包含id,create_at,update_at等图片信息。其中的links属性为图片的链接资源信息,links下的self代表浏览图片时的url,download才是要下载的url,download_location表示什么鬼东西,我也不知道,我试着点了一下,反馈信息为请求错误。不过让我从字面意思理解为下载地点,难道是和cook有关联?不管了,先不想那么多,最主要的任务是先下载下来图片。其实呢,上面的links链接,你可以随便的点,随便的看,反正没啥大的影响。 再在命令行中输入如下命令,创建虫子:
再在命令行中输入如下命令,创建虫子: 老办法,修改items.py文件如下:
老办法,修改items.py文件如下: 查看我们的项目目录,有如下目录结构:
查看我们的项目目录,有如下目录结构:  上述的test.py是我临时写的测试文件,不必在意。打开我们的图片保存目录,会看到如下结果:
上述的test.py是我临时写的测试文件,不必在意。打开我们的图片保存目录,会看到如下结果:  为什么只有两张图片,因为网太慢了,还有就是访问的是外网,资源下载很慢的。但是要说明的是,程序没有任何问题,你尽可拿去随便测试。
为什么只有两张图片,因为网太慢了,还有就是访问的是外网,资源下载很慢的。但是要说明的是,程序没有任何问题,你尽可拿去随便测试。【本文地址】