| 机器学习(ML) | 您所在的位置:网站首页 › 什么是梯度下降的意思 › 机器学习(ML) |
机器学习(ML)
|
出chatgpt独享账号!内含120美元!仅需38元/个!独享永久使用!点击购买! 写在开头:小白写给自己总结思考 1.什么是线性回归 线性回归属于机器学习中有监督学习的一种回归任务。机器学习中的算法包括监督学习、无监督学习和强化学习等,其中监督学习包括回归和分类,无监督学习包括聚类和降维。 线性回归这一词中,第一眼感觉哪一个是重点?线性还是回归?这个感觉当然是回归啦,那么什么是回归呢,说的通俗点,就是拟合一条线,让所有的数据都尽可能的在这条线的上,或离这条线很近。这条线如果直线,就是单变量回归。例如: 这是我们常见的一元线性方程,它也表示单变量回归的方程。 为什么要这个呢?监督学习的实质就是对于给定的原始数据,在这里就是拟合一条线性的回归直线,根据这条直线,来预测数据集外同类型的数据信息。这里的原始数据集也就是训练集,给定的数据就是测试集啦,然后放到一些模型中,欻欻欻的去实现。 2.损失函数数据能拟合的线千千万,如何能找到最优的那条呢?这时候我们的损失函数就来啦!这里损失函数的意思就是数据集里面的点到拟合的线之间的距离,也可以理解为他们之间要重合所需要的损耗,所以称为损失函数(其实是翻译过来的,我瞎解释的,哈哈哈)。式子如下(吴恩达的机器学习书中):
书中图片如下(狗头):
这里的h-y是真实值与预测值之间的误差,在机器中,通用的就是咱们的计算机中,咱给他平方再求和,这样就比较好计算了。其实这里有个问题,为什么取h-y,而不是点到直线的最短距离呢?可能是后面那种比较难算?亦或是我们是需要预测值更接近真实值的,所以这样所得到的最小误差回让预测的结果更加的准确?有待我后面继续研究...... 将上面的一元方程系数改写一下,然后代入求导。
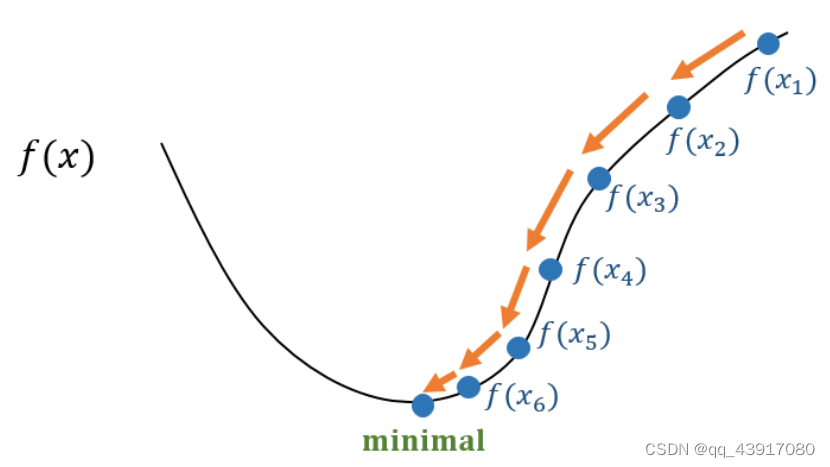
接下来,那么损失函数的最小值怎么求解呢?这里我们使用的算法是梯度下降法,是不是感觉很熟悉。梯度?在高数中,是一个向量,表示该点处的方向导数取得最大值,也就是下降最快的方向。这里的意思也就是沿着下降速度最快的方向去求得 下面是书上背后思想的复述:开始时我们随机选取一个参数组合,计算损失函数,然后我们寻找下一个能让损失函数下降最多的组合,持续这样做直到找到一个局部最小值。选择不同的初始参数组合,寻找另外的局部最小值,最后求得全局最小值。算法公式如下:
对于
这里的f(x)看成J(
是否有点懵逼?哈哈哈,确实。后面的容我再思考思考,拜了个拜。
|
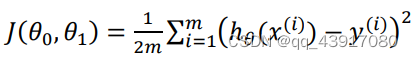

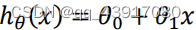


【本文地址】