| KMP算法详解,能认字就能搞懂 | 您所在的位置:网站首页 › 什么是前缀索引和后缀 › KMP算法详解,能认字就能搞懂 |
KMP算法详解,能认字就能搞懂
|
目录
你需要知道的有关KMP算法的概念
KMP算法的核心思想以及原理
什么是前缀表,什么是前缀,后缀?
如何用代码实现前缀表?
用前缀表去做对应匹配(KMP算法的完整实现)
文章说明
你需要知道的有关KMP算法的概念
在弄懂KMP算法之前先要了解其中涉及的概念。 ①首先你要明确KMP算法解决的是字符串的匹配问题。 ②KMP中涉及两个字符串,一个是文本串(主串),另外一个是模式串,而KMP算法就是在文本串(主串)中去寻找模式串。 ③KMP算法实现的过程中少不了一个重要的零部件 – 前缀表,而前缀表我们在解决问题的时候使用next数组去实现的,换句话说你可以就把next数组当作前缀表。(有些地方会把next数组,说成profix table 这也是阔以的😊) (这些东西具体有啥用后面会说。) KMP算法的核心思想以及原理KMP的核心思想:在你去匹配两个字符串的时候,如果出现不匹配的情况,KMP算法可以通过之前记录的已经匹配好的部分,进行一些回退操作(这个地方不懂也没关系,后面也会讲),从而防止从头开始再去匹配。 什么意思呢?就是说一般你去匹配两个字符串是用两个for循环(假设两个字符串一个为A,一个为B,你的目的是在A中匹配到B),如果不匹配A就会往后一位同时取与B相同长度,再去与B从头开始比对。而KMP算法就是避免这个从头开始的动作,转而通过某种方法从B的中间某一位置,继续与A 进行比对。(这个某种方法,就是利用前缀表,如果你不知道什么是前缀表,没事继续往后看。) KMP算法的原理:可能你现在有很多疑问,为什么不用从头开始匹配,而是就可以直接在B中找一个位置继续进行匹配呢?上图
如下图,是前缀后缀有重合的情况: 首先明确前缀表的长度与模式串的长度一样(也就是上面提到的字符串B,他就可以称为模式串),他的作用:记录最长的公共(相同)前后缀。他的作用对象:模式串。 那么什么是前后缀? 前缀:不包含最后一个字符的,所有以第一个字符为头的连续子字符串。 后缀:不包含第一个字符的,所有以最后一个字符为尾的连续子字符串。 我们前面提到,前缀表的作用是记录最长的公共前后缀,那么我们为什么要去记录最长的公共前后缀呢,换句话说我们为什么需要前缀表这个东西?前面我们说过KMP算法的原理,那么此时我们就应该有一种抽象的意识,去找到上面两个示意图中的结构,这样我们就不用从头开始匹配。而这种结构就由最长的公共前后缀组成。这样我们就可以说前缀表告诉了我们回退到什么位置,去继续匹配。由此可见前缀表在KMP算法中的重要性。 可能你对最长公共前后缀仍不是很了解,下面我列举一些,加深你的理解程度: “a” 最长公共前后缀为:0 “aa” 最长公共前后缀为:1 “aab” 最长公共前后缀为:0 “aaa” 最长公共前后缀为:2 “aaba” 最长公共前后缀为:1 “aaaa” 最长公共前后缀为:3 “aabaa” 最长公共前后缀为:2 “aabac” 最长公共前后缀为:0当你了解了前后缀之后,你再回看我上面两幅图里的结构,就会发现:回退就是从当前匹配失败的位置(后缀的后面),回到前缀的后面。(前提是前后缀相同) 如何用代码实现前缀表?前面我们说过前缀表在代码中用next数组去实现,它的长度与模式串相同,前缀表的每一格代表:此格对应的模式串以及前面部分的最长公共前后缀。 如图: 因为i指针自始自终都是规律性的前移,我们可以把它并入for循环中。 代码实现如下:( 以力扣28题实现strStr()为例 ) //此方法构建前缀表(next数组,profix table) public void builtNums(int[] next,String needle){ //构建双指针i(指向后缀的结尾),j(指向前缀的结尾) //此处构建的前缀表不进行任何修改(如整体减一,或者右移等) int j = 0; next[j] = 0; for(int i = 1;i 0){ j = next[j - 1]; } //若两指针所指数据相同,则j向前移动 if(needle.charAt(i) == needle.charAt(j)){ j++; } next[i] = j; } } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19此时你可能还有一个疑问:按理来说求最长公共前后缀这种东西不应该有个计数器什么东西的吗,每统计一个区间就把计数器的数据填入到next数组中,为什么这里是把一个指针的数值填了进去,他难道不是用来表示索引(角标)的吗?这确实是一个难点,不过我们可以用另一种方式去理解它。寻找最长公共前后缀,我们可以以前缀为基准,对它的长度进行调试(这个调试操作其实就是回退)直到它与后缀的内容匹配,这个时候前缀的长度就是最长公共前后缀的值。而我们前面提到j指针它永远指向前缀的尾端,当匹配成功之后j会自增,这正好就代表了前缀的长度(长度 = 尾索引 + 1)。 再来理解代码中while中的部分,这个while中装的就是当i,j两个指针指向的内容不同时,j 指针回退的操作。此处用到了KMP算法的核心思想与原理,当不匹配的时候,不是从头重新开始匹配,而是找到"那种"结构,让j指针回退到前缀的尾端,而该回退到哪儿,前面我说过前缀表会告诉我们,因为当不匹配时,j指针前面那一位的最长公共前后缀已经统计过了,故可以直接用。这就是j = next[j - 1]的含义。 再上一张图更好理解:
回退就是从当前匹配失败的位置(后缀的后面),回到前缀的后面。(前提是前后缀相同) 2这个值代表红圈部分的最长公共前后缀,也就是说最长前缀也是2,而我们要回到的前缀后面的这个位置所对应的索引值也是2,这一切就可以说得通了。 用前缀表去做对应匹配(KMP算法的完整实现)这里以力扣的28.实现strStr()作为例子。 题目: 实现 strStr() 函数。 给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串出现的第一个位置(下标从 0 开始)。如果不存在,则返回 -1 。 说明: 当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。 对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与 C 语言的 strstr() 以及 Java 的 indexOf() 定义相符。 示例: 输入:haystack = “hello”, needle = “ll” 输出:2 输入:haystack = “aaaaa”, needle = “bba” 输出:-1 输入:haystack = “”, needle = “” 输出:0 完整代码实现: public static void main(String[] args) { LeetCode28 haha = new LeetCode28(); int[] ans = new int[6]; haha.builtNums(ans,"aabaaf"); System.out.println(Arrays.toString(ans)); System.out.println(haha.strStr("hello","ll")); } //此方法构建前缀表(next数组,profix table) public void builtNums(int[] next,String needle){ //构建双指针i(指向后缀的结尾),j(指向前缀的结尾) //此处构建的前缀表不进行任何修改(如整体减一,或者右移等) int j = 0; next[j] = 0; for(int i = 1;i 0){ j = next[j - 1]; } //若两指针所指数据相同,则j向前移动 if(needle.charAt(i) == needle.charAt(j)){ j++; } next[i] = j; } } //此方法运用前缀表进行对比匹配 public int strStr(String haystack, String needle) { //根据题意,如果为空串则直接返回0 if (needle.length() == 0){ return 0; } //创建next数组,并根据needle进行计算 int[] next = new int[needle.length()]; builtNums(next,needle); //建立双指针,一个指针(j)指向needle头部,另一个指针(i)指向haystack头部,为匹配做准备 int j = 0; for(int i = 0;i 0){ j = next[j - 1]; } if(haystack.charAt(i) == needle.charAt(j)){ j++; } //当指针j已经处于needle的尾部的后一位时候,说明匹配操作已经完成! if(j == needle.length()){ return i - j + 1; } } // 若外层循环完成之后(也就是i指针已经到haystack的尾部了),而j仍未处于needle的尾部的后一位 // 则说明haystack中确实没有needle,故返回-1. return -1; } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55注意:为什么不是if(j == needle.length() - 1){……},而是:if(j == needle.length()){……}: 因为你如果两个指针所指的内容相同的话,j会往后进一位,而如果恰好到达needle的末尾的话(也就是needle.length() - 1),他就直接返回了,相当于needle的最后一位没有比较,默认就相同了。 文章说明这篇文章也是我的拙见,因为本人也是新人小白,难免有地方犯错,或者不规范,敬请谅解。但这篇文章哪怕只有一点地方给了你启示,那么我的目的也就达到了😊。 文章来源: blog.csdn.net,作者:十八岁讨厌编程,版权归原作者所有,如需转载,请联系作者。 原文链接:blog.csdn.net/zyb18507175502/article/details/122310090 |
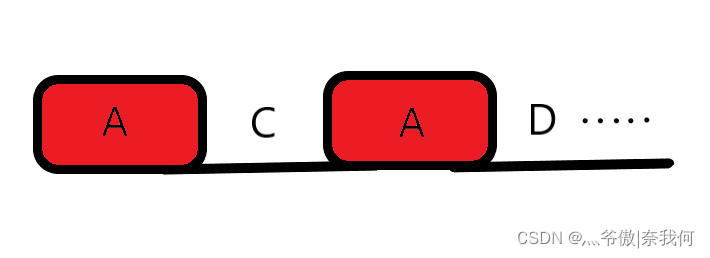 你可以把它看作字符串B(也就是要在A中寻找匹配的字符串),其中两个红色的A区域为两部分一模一样的内容。设想一下现在字符串B经过一个个的比对后到了D处,结果发现D与A字符串开始不匹配了,按照常理来说A会向后移一位,再去与B字符串重新从头开始匹配,但KMP算法会回退到C处继续与字符串A匹配。 既然字符串B能匹配到D处,那么就说明D前面的部分它与字符串A是完美匹配的,所以就可以得出此时D处前面的A部分他也是匹配的,既然这样的话我们为什么要从头开始匹配呢?从C处继续匹配显然更高效快捷,因为此时C处前面也有相同的A部分,所以这种做法是完全可行的。(上面的示意图是前缀与后缀没有重合的情况,不知道前缀后缀没关系后面也会讲。)
你可以把它看作字符串B(也就是要在A中寻找匹配的字符串),其中两个红色的A区域为两部分一模一样的内容。设想一下现在字符串B经过一个个的比对后到了D处,结果发现D与A字符串开始不匹配了,按照常理来说A会向后移一位,再去与B字符串重新从头开始匹配,但KMP算法会回退到C处继续与字符串A匹配。 既然字符串B能匹配到D处,那么就说明D前面的部分它与字符串A是完美匹配的,所以就可以得出此时D处前面的A部分他也是匹配的,既然这样的话我们为什么要从头开始匹配呢?从C处继续匹配显然更高效快捷,因为此时C处前面也有相同的A部分,所以这种做法是完全可行的。(上面的示意图是前缀与后缀没有重合的情况,不知道前缀后缀没关系后面也会讲。)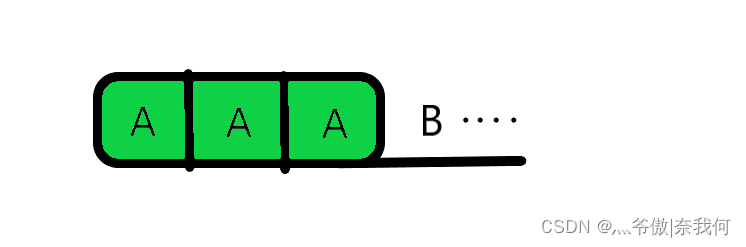 同样的理解:在匹配到B处不符合时,可以回退到绿色区域最靠右边的A处继续匹配。
同样的理解:在匹配到B处不符合时,可以回退到绿色区域最靠右边的A处继续匹配。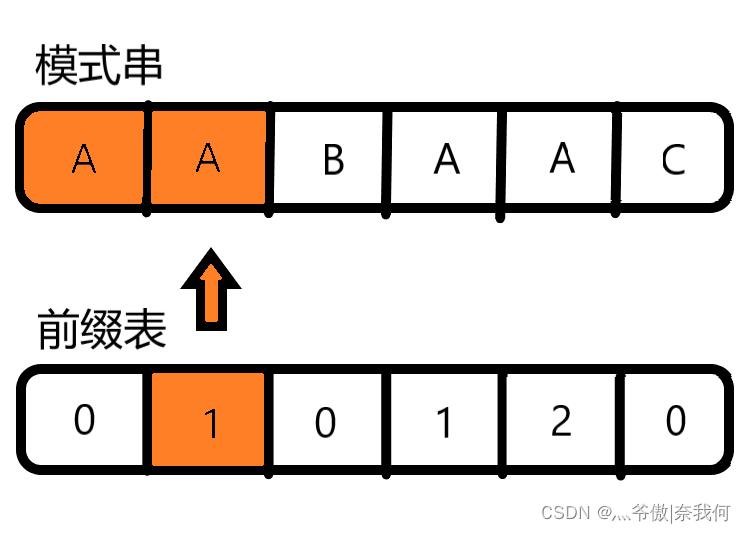 首先我们要创建两个指针(可以命名为j,i),指针j指向前缀的尾部,指针i指向后缀的尾部。将他们指针初始化,j指向0索引处,i指向1索引处。
首先我们要创建两个指针(可以命名为j,i),指针j指向前缀的尾部,指针i指向后缀的尾部。将他们指针初始化,j指向0索引处,i指向1索引处。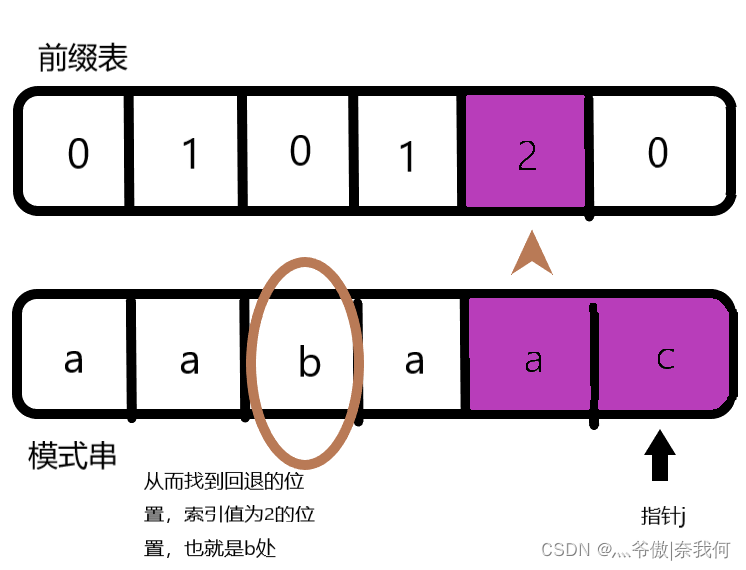 如果你此时心中有着为什么可以这样,这两个有啥联系的疑问,这说明我前面写的内容你可能还没有完全领会。这里我再解释一下:我们寻找前一位(也就是c前面的a)在前缀表中的对应值,是因为c处于红圈部分的后缀的尾部。
如果你此时心中有着为什么可以这样,这两个有啥联系的疑问,这说明我前面写的内容你可能还没有完全领会。这里我再解释一下:我们寻找前一位(也就是c前面的a)在前缀表中的对应值,是因为c处于红圈部分的后缀的尾部。 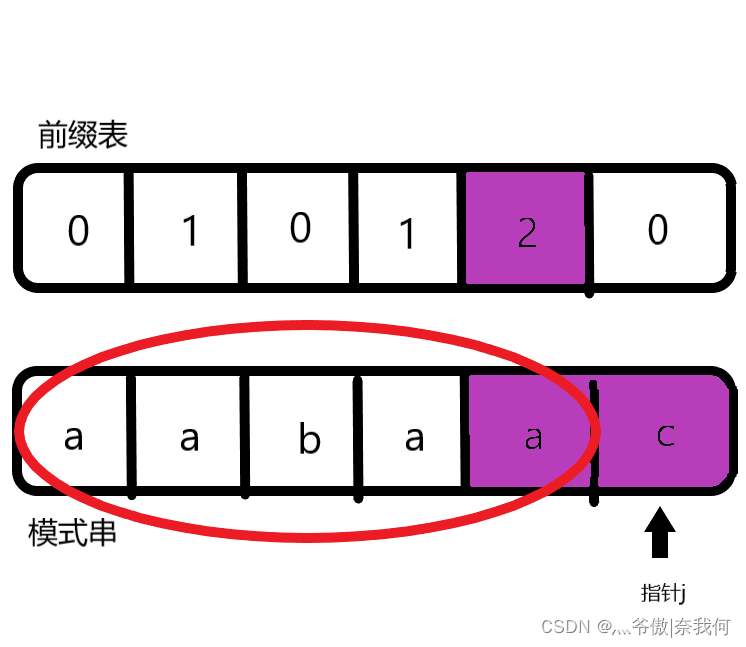 而我们前面提到过:
而我们前面提到过:【本文地址】