| 基于YOLOv5算法实现人数统计和人脸识别并部署于开发板rk3588 | 您所在的位置:网站首页 › 人脸分割算法表面积计算 › 基于YOLOv5算法实现人数统计和人脸识别并部署于开发板rk3588 |
基于YOLOv5算法实现人数统计和人脸识别并部署于开发板rk3588
|
基于YOLOv5算法实现人数统计和人脸识别并部署于开发板rk3588
一、问题背景二、模型介绍1、YOLO简介2、YOLOv5模型介绍
三、人数统计功能实现1、数据集的准备2、使用YOLOv5代码本地训练模型
四、算法部署1、常见的模型部署2、YOLOv5算法模型部署与开发板rk35881、使用正确版本(v5.0)的yolov5进行训练得到pt模型2、将pt模型使用yolov5工程中的export.py转换为onnx模型
一、问题背景
在深度学习中,目标识别问题是我们所熟知的最经典最重要的问题之一。目标识别需要在一幅大图片中定位到多个目标的位置和类别。目标检测的应用范围很广,比如在超市通过视频检测消费者的进出、工业制造业领域中的异常行为检测等。另一个典型的场景是,在自动驾驶时车辆需要定位视线范围内的所有物体,并识别其类别以判断危险程度。这都给目标检测这一领域提供了丰富的应用空间。所以,在本次实验中,我根据课堂场景使用YOLO系列算法实现人数统计与人脸识别功能,在此基础上将其算法模型部署于开发板上,实现项目的落地测试。 二、模型介绍 1、YOLO简介YOLOv1是典型的目标检测one stage方法,在YOLO算法中,核心思想 就是把物体检测(object detection)问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。用回归的方法去做目标检测,执行速度快,达到非常高效的检测,其背后的原理和思想也非常简单。相对于R-CNN系列算法将检测问题分解为划定位置和判定类别分两步做,YOLO系列算法没有显式寻找区域的过程,可以实现端到端的快速预测,即输入一幅图片,在输出中给出若干目标的位置、类别和置信度。 而相对于同样是一步到位的SSD算法,YOLO系列的特点在于算法一经发出,便有各种各样的人和团队对他进行更新迭代。通过不断地更新迭代模型版本,YOLO也得到了效果上持续的提升和更广泛的关注。 2、YOLOv5模型介绍我们首先介绍一下最原始的YOLO模型,然后简要介绍一下YOLOv5版本的改进,主要通过具体的例子一起看看怎么把YOLOv5模型用好。 YOLOv1的网络结构并没有什么特别,和我们熟悉的图像分类一样都是卷积神经网络,但它的输出向量却不太一样。如果把神经网络看作我们熟悉的回归分析问题,那YOLO做的事情就是改变了模型响应Y的结构,而这也奠定了YOLO目标检测的基础。YOLO的输出向量不仅包括目标的类别,还有边界框的坐标和预测的置信度。它的核心思想在于把图像分割成S*S的若干个小块,在每个格子中预先放置两个边界框,通过卷积神经网络预测得到每个边界框的坐标、类别和置信度,然后通过非极大值抑制获得局部唯一的预测框。
yolov5使用的是coco数据集,实现对80种类别的检测。而我们只需要对人的检测,是所以必须更换所使用的数据集,一个合适的数据集是保证目标检测算法准确性的重要指标。 我们采用真实公开的人脸识别数据集WIDER FACE进行YOLOv5模型的训练和测试,从网上获取一些目标检测的数据集资源标签的格式都是VOC(xml格式)的,而yolov5训练所需要的文件格式是yolo(txt格式)的,这里就需要对xml格式的标签文件转换为txt文件。同时训练自己的yolov5检测模型的时候,数据集需要划分为训练集和验证集。
具体本地训练流程在我的另外一篇文章有详细介绍; https://blog.csdn.net/Lost_The_Mind/article/details/130583159?spm=1001.2014.3001.5502 这是使用我们本地训练的模型文件检测的图片结果
至此,我们就得到了可以用来检测人脸的模型文件,实现人数统计的功能。 四、算法部署 1、常见的模型部署(1)服务器:① HTTP 网页协议、 ② socket (2)PC: ① pt(pytorch内置打包API)、② onnx:支持跨平台和tensorRT部署方式、③ tvm… (3)手机:①安卓、 ② IOS……同样可以通过调用onnx进行部署。 (4)IOT部署: ① 英伟达Jetson:支持cuda、② 华为海思、 ③ 瑞芯微、 ④ 树莓派(cpu)…… IOT(物联网)部署是指将各种物联网设备和传感器与相应的软件和网络连接起来,以实现数据的收集、存储、分析和交互。 2、YOLOv5算法模型部署与开发板rk3588瑞芯微RK3588是一款搭载了NPU的国产开发板。NPU(neural-network processing units)可以说是为了嵌入式神经网络和边缘计算量身定制的,但若想调用RK3588的NPU单元进行推理加速,则需要首先将模型转换为**.rknn格式**的模型,否则无法使用。 这次我们的任务是将yolov5训练得到的pt模型,一步步转换为rknn模型,并将rknn模型部署在搭载RK3588的主机上,使用NPU推理。 具体流程如下: 1、使用正确版本(v5.0)的yolov5进行训练得到pt模型上述流程中,我们已经在本地复现了yolov5算法,训练得到了用于人脸检测可使用的pt模型文件。 2、将pt模型使用yolov5工程中的export.py转换为onnx模型实际上,由于我们训练得到pt模型文件与yolov5官方版本的yolov5s.pt模型文件结构并不相同,所以需要对本工程中的相关文件进行修改才能得到可用的onnx模型文件。 下图所示是用来检测人脸的pt文件做转换的onnx模型结构 而官方yolov5s.pt文件转换得到的onnx模型如下图: |
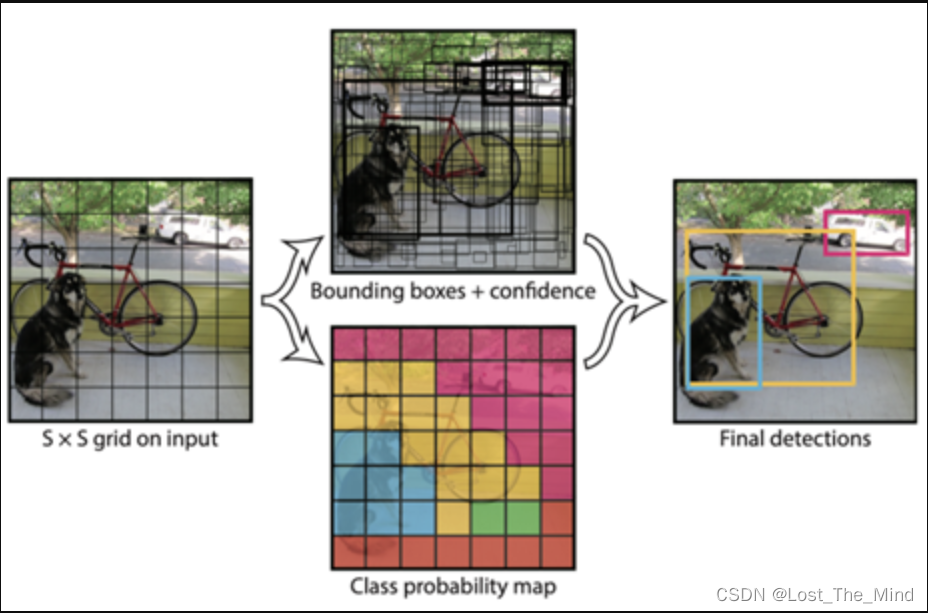 经过YOLO算法的迭代发展,YOLOv5的网络结构博采众长,已经变得格外复杂,主要包括在Backbone中通过卷积和池化网络结构提取特征,在Neck部分不断地和之前提取的特征进行融合,Head部分则是用来进行最终的检测和输出,如下图所示。
经过YOLO算法的迭代发展,YOLOv5的网络结构博采众长,已经变得格外复杂,主要包括在Backbone中通过卷积和池化网络结构提取特征,在Neck部分不断地和之前提取的特征进行融合,Head部分则是用来进行最终的检测和输出,如下图所示。 

 而使用YOLOv5算法自带的多目标检测模型文件得到结果:
而使用YOLOv5算法自带的多目标检测模型文件得到结果:
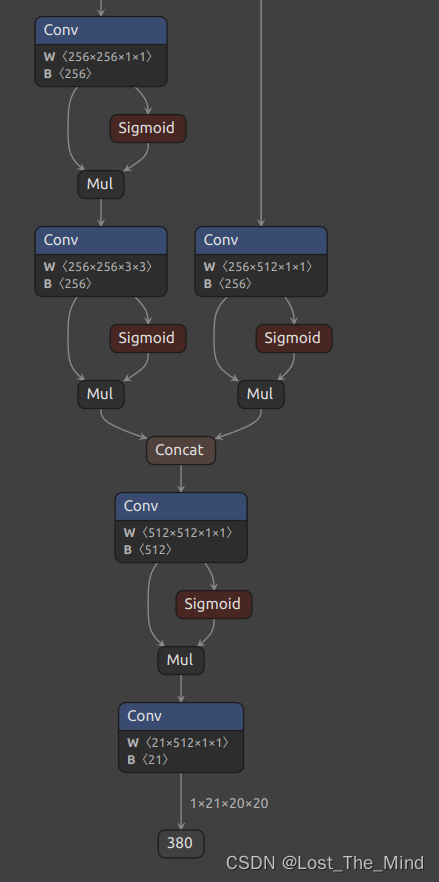 这里最终的输出结果维度为:1×21×20×20,具体可以改写为1×3×7×20×20。 因为yolov5中采用大、中、小三类anchor检测框,为“3”,两类检测目标(人脸和帽子)再加上目标框的左上角坐标(x和y),框的长和宽以及一个置信度,所以为“7”。
这里最终的输出结果维度为:1×21×20×20,具体可以改写为1×3×7×20×20。 因为yolov5中采用大、中、小三类anchor检测框,为“3”,两类检测目标(人脸和帽子)再加上目标框的左上角坐标(x和y),框的长和宽以及一个置信度,所以为“7”。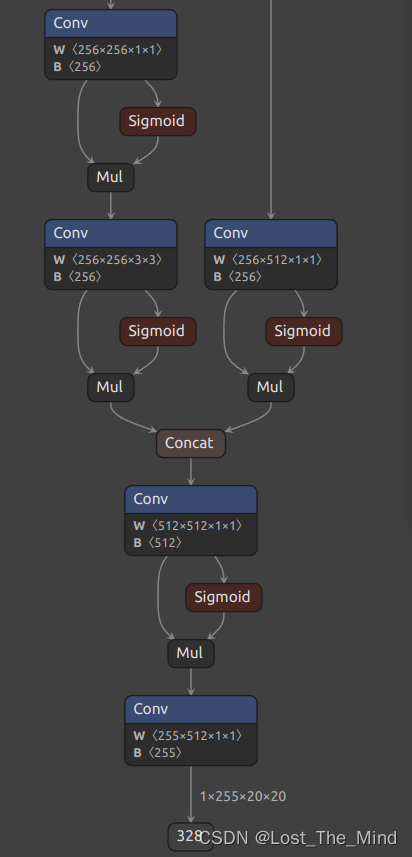
【本文地址】