| Python数据挖掘与可视化探索 | 您所在的位置:网站首页 › 人口普查app下载 › Python数据挖掘与可视化探索 |
Python数据挖掘与可视化探索
|
目录 (1)数据集背景介绍 (2)读取数据并导入需要的第三方库 (3)通过判断每个属性的取值范围来估计属性及其类型 (4)删除数据值前的空格,调整数据格式 (5)处理缺失数据 (6)属性可视化分析及数据变换 ①"age" 年龄分析 ②"workclass" 工作类型分析 ③"education" 学历分析 ④"education_num" 受教育时间分析 ⑤"marital_status" 婚姻状态分析 ⑥"occupation" 职业分析 ⑦"relationship" 关系分析 ⑧"race" 种族分析 ⑨"sex" 性别 ⑩"capital_gain" 资本收益 与 "capital_loss" 资本损失之间的关系分析 ⑪"capital_gain" 资本收益分析 ⑫"capital_loss" 资本损失分析 ⑬"hours_per_week" 每周工作小时数分析 ⑭"native_country" 原籍分析 (1)数据集背景介绍
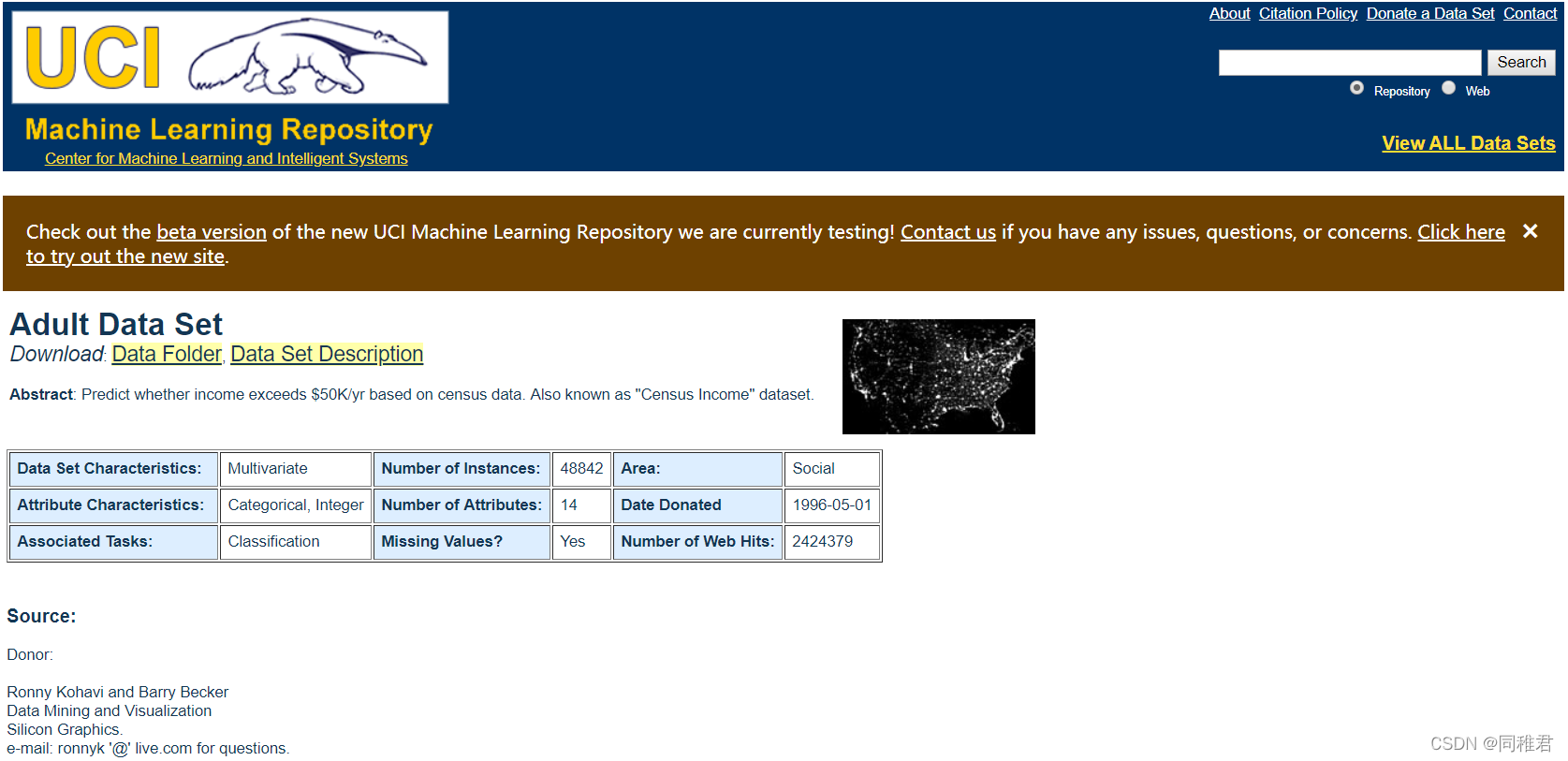
数据来源于1994年美国人口普查数据库。(下载地址https://archive.ics.uci.edu/ml/datasets/Adult) 该数据集共32560条数据,15个变量。 数据详细说明地址:Index of /ml/machine-learning-databases/adult (2)读取数据并导入需要的第三方库需要用到的数据分析工具包有:numpy、pandas 需要用到的数据可视化工具包有:pyecharts、matplotlib、missingno、seaborn import csv from pyecharts.charts import * from pyecharts import options as opts from pyecharts import options as opst import matplotlib.pyplot as plt import missingno as msno import numpy as np import pandas as pd import seaborn as sns iris_file = open("income dataset/adult.data", "r", encoding='utf-8') reader = csv.reader(iris_file) dataSet = [] for row in reader: dataSet.append(row) (3)通过判断每个属性的取值范围来估计属性及其类型假设我们目前还不清楚数据集各个特征属性的详细信息(如名称、数据类型、数据量等),通过提取各个属性的取值范围(即非重复值)来估计该属性的一些情况。 def AttributeTypeJudgment(dataSet): attributeNum = len(dataSet[0]) #计算属性个数,包括最后的类别 uniqueAttributeDict = {} for i in range(attributeNum): #遍历每个属性 attributeValueList = [] for j in range(len(dataSet)): attributeValueList.append(dataSet[j][i]) uniqueAttributeValue = list(set(attributeValueList)) #将属性值去重,得到第i个属性的取值的范围 uniqueAttributeDict[i] = uniqueAttributeValue print(i, ":", uniqueAttributeValue) return uniqueAttributeDict AttributeTypeJudgment(dataSet)第 0 个属性所有非重复值:
第1个属性所有非重复值:
第2个属性部分非重复值:
第3个属性所有非重复值:
······ 第13个属性部分非重复值:
类别所有非重复值:
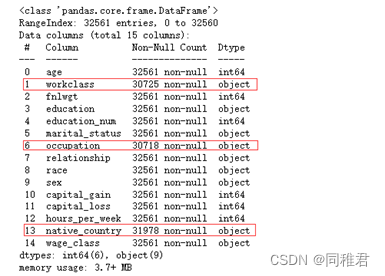
通过对每个属性所有非重复值的观察与分析,可以猜测到部分属性可能的名称,以及判断每一个属性的值的数据类型。再通过查找关于该数据集的介绍性的资料,得出该数据集各个属性名称及数据类型如下: 属性 名称 属性类型 数据格式 age 年龄 离散属性 Int64 workclass 工作类型 标称属性 object fnlwgt 序号 连续属性 Int64 education 学历 标称属性 object education_num 受教育时间 连续属性 Int64 marital_status 婚姻状态 标称属性 object occupation 职业 标称属性 Object relationship 关系 标称属性 Object race 种族 标称属性 Object sex 性别 二元属性 object capital_gain 资本收益 连续属性 Int64 capital_loss 资本损失 连续属性 Int64 hours_per_week 每周工作小时数 离散属性 Int64 native_country 原籍 标称属性 object 类别 名称 数据格式 wage_class 收入类别 Object (4)删除数据值前的空格,调整数据格式可以注意到数据集里面的每一个数据的数据类型都是字符串类型,并且开头存在一个空格,因此需要先去除每个数据前的空格,并且把每个特征数据里面的数据类型由字符串转换成其对应有的数据类型。 attributeLabels = ["age", #年龄 int64 离散属性 "workclass", #工作类型 object 标称属性 有缺失 "fnlwgt", #序号 int64 连续属性 "education", #学历 boject 标称属性 "education_num", #受教育时间 int64 连续属性 "marital_status", #婚姻状态 object 标称属性 "occupation", #职业 object 标称属性 有缺失 "relationship", #关系 object 标称属性 "race", #种族 object 标称属性 "sex", #性别 object 二元属性 "capital_gain", #资本收益 int64 连续属性 "capital_loss", #资本损失 int64 连续属性 "hours_per_week", #每周工作小时数 int64 离散属性 "native_country", #原籍 object 标称属性 有缺失 "wage_class"] #收入类别 object 二元属性 # 更改数据集格式为pandas 的DataFrame格式 dataFrame = pd.DataFrame(dataSet, columns=attributeLabels) # 将缺失值部分的“ ?” 置为空,即 np.NaN,便于使用pandas来处理缺失值 newDataFrame = dataFrame.replace(" ?", np.NaN) #删除数据值前的空格 for label in attributeLabels: newDataFrame[label] = newDataFrame[label].str.strip() # 更改数据集中每一种数的值的数据格式,当前全为字符串对象,以便接下来的可视化分析 # 将"age"、"fnlwgt"、“education_num”、"capital_gain"、“capital_loss”、“hours_per_week” 改为 int64 类型 newDataFrame[['age', 'fnlwgt', 'education_num', 'capital_gain', 'capital_loss', 'hours_per_week']] = newDataFrame[['age', 'fnlwgt', 'education_num', 'capital_gain', 'capital_loss', 'hours_per_week']].apply(pd.to_numeric) #查看对数据集数据分布的描述 print(newDataFrame.describe())数据集中数值型属性数据分布如下:
首先查看有数据缺失的属性: #可视化查看特征属性缺失值 msno.matrix(newDataFrame, labels=True, fontsize=9) # 矩阵图 plt.show()
可以直观看出属性“workclass”、“occupation”、“native_country”存在缺失值,数据集中样本总数为32561个。 再查看具体缺失数量: print(newDataFrame.describe())
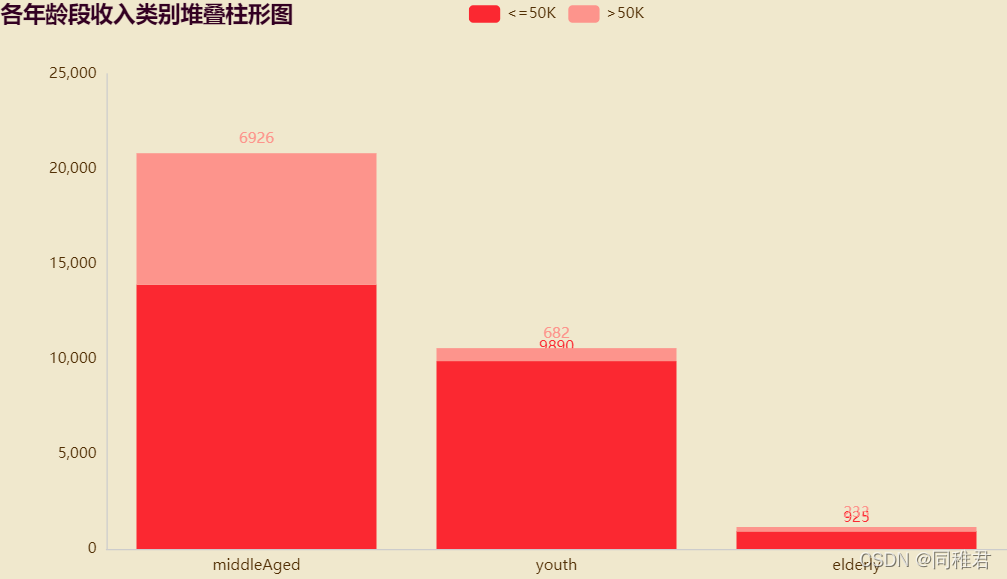
可以看到,三个属性的缺失值数量均较少,因此可以采取补的方法,由于这三个属性均是标称属性,所以可以采取用属性中出现次数最多的值来代替(即使用最有可能值来代替缺失值)。三个属性中出现次数最多的值分别为:“Private”、“Prof-specialty”、“United-States”。 #填补属性workclass缺失值, 是标称属性,且缺失数量较少,所以用出现次数最多的值来代替(即使用最有可能值) print(newDataFrame['workclass'].value_counts()) newDataFrame['workclass'].fillna("Private", inplace=True) #填补属性occupation缺失值, 是标称属性,且缺失数量较少,所以用出现次数最多的值来代替(即使用最有可能值) print(newDataFrame['occupation'].value_counts()) newDataFrame['occupation'].fillna("Prof-specialty", inplace=True) #填补属性native_country缺失值, 是标称属性,且缺失数量较少,所以用出现次数最多的值来代替(即使用最有可能值) print(newDataFrame['native_country'].value_counts()) newDataFrame['native_country'].fillna("United-States", inplace=True) (6)属性可视化分析及数据变换 ①"age" 年龄分析 # "age" 年龄分析 page_age = Page() print(newDataFrame['age'].describe()) #查看年龄分布 # plt.hist(newDataFrame['age'], bins =20) # plt.show() #根据取值将年龄分段,年龄为[17,30) [30,65) [65,100), 段标签为:youth、middleAged、elderly newDataFrame['age'] = pd.cut(newDataFrame['age'], bins=[16, 30, 65, 100], labels=['youth', 'middleAged', 'elderly']) #各个年龄段人数柱形图 # print(newDataFrame['age'].value_counts()) x_age = list(dict(newDataFrame['age'].value_counts()).keys()) #获取年龄段列表 y_age= list(newDataFrame['age'].value_counts()) #获取各个年龄段的人数值 bar_age = ( Bar(init_opts=opts.InitOpts(theme="romantic")) .add_xaxis(x_age) .add_yaxis("人数", y_age, label_opts=opts.LabelOpts(is_show=True)) .set_global_opts(title_opts=opts.TitleOpts(title="年龄段人数柱形图", pos_left="left"), legend_opts=opts.LegendOpts(is_show=True)) ) y_age_wageclass1 = [ len(list(newDataFrame.loc[(newDataFrame['age']=='middleAged')&(newDataFrame['wage_class']=='50K'), 'wage_class'])) ] #各年龄段收入类别堆叠柱形图 stackBar_age = ( Bar(init_opts=opts.InitOpts(theme="romantic")) .add_xaxis(x_age) .add_yaxis("50K", y_age_wageclass2, stack=True) .set_global_opts(title_opts=opst.TitleOpts(title="各年龄段收入类别堆叠柱形图", pos_left="left"), legend_opts=opst.LegendOpts(is_show=True, pos_left="center")) ) page_age.add(bar_age, stackBar_age) page_age.render("charts/age.html")由于“age”属性值处于[16, 100]区间之间,且年龄大小与收入相关性较大,因此可以将年龄根据实际划分为3个年龄段 [17,30)、[30,65)、[65,100),年龄段标签为:youth、middleAged、elderly,用年龄段标签来代替具体数值,使数据集适合用于分类模型。
从图中可以直观看出,三个年龄段中中年阶段收入>50K的人数占比最大,青年阶段和老年阶段人的收入大多50K占比最多的是“Self-emp-inc” 自由职业者类。
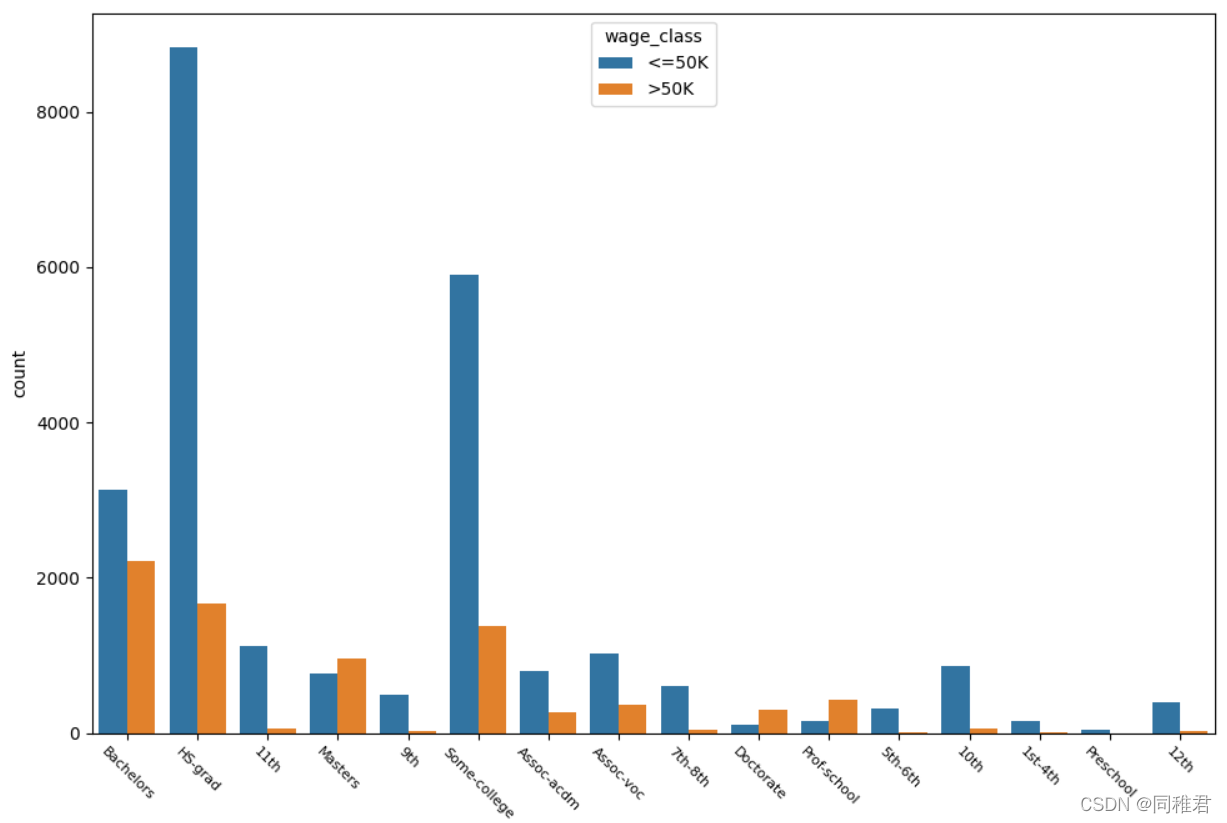
“education”是标称属性,取值有: 'HS-grad', 'Some-college', 'Bachelors', 'Masters', 'Assoc-voc', '11th', 'Assoc-acdm', '10th', '7th-8th', 'Prof-school', '9th', '12th', 'Doctorate', '5th-6th', '1st-4th', 'Preschool'。从下图可以看出,学历越高收入>50K的占比越高,大部分人受过高等教育。
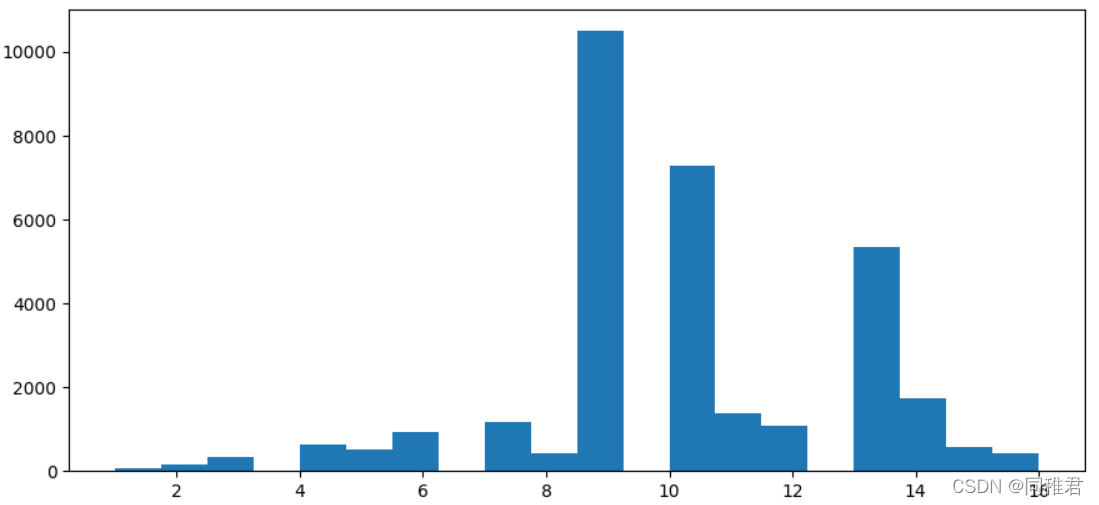
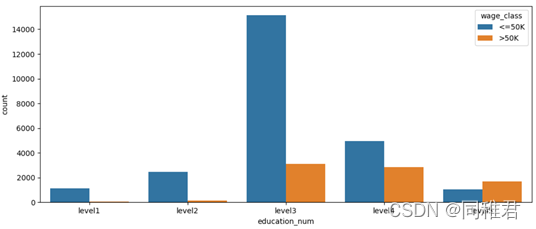
“education_num”是连续属性,因此可以将其离散化,从下方的受教育时间数据分布直方图来看,受教育时间可以分为5类,因此用等距法来画分数据,划分为'level1', 'level2', 'level3', 'level4', 'level5'五个范围。划分后可以直观看出受教育时间处于中等层次的人数最多,越往后收入>50K占比越高。 其次“education”与“education_num”属性含义重复程度较高,在建模时可以考虑去除其中一个属 性,以降低数据冗余。
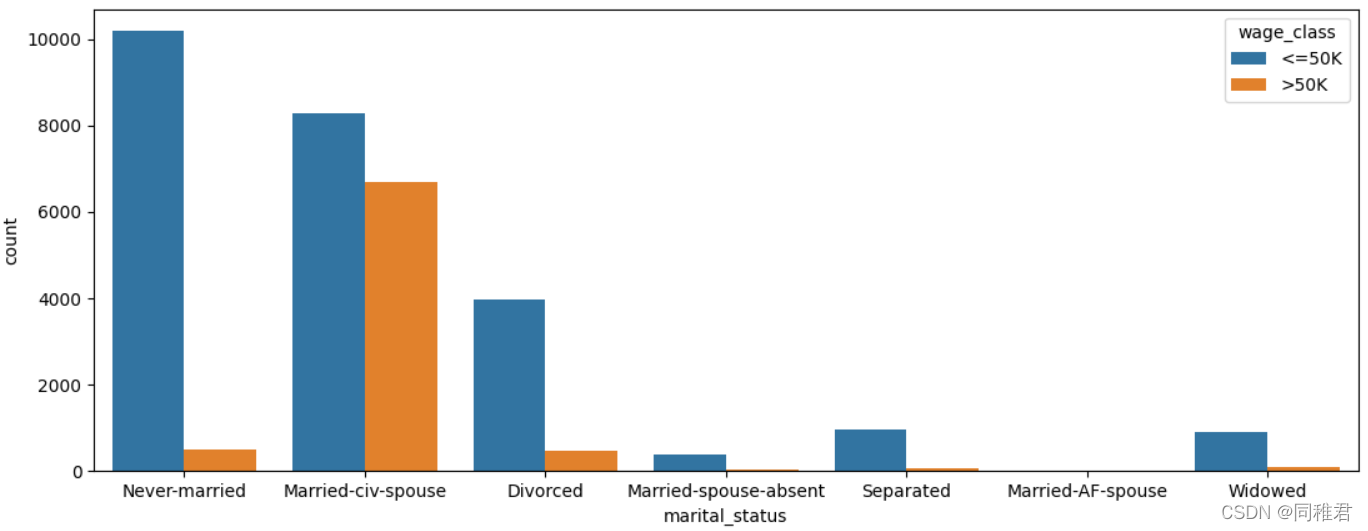
下图可以看出单身人群收入普遍小于等于50K。
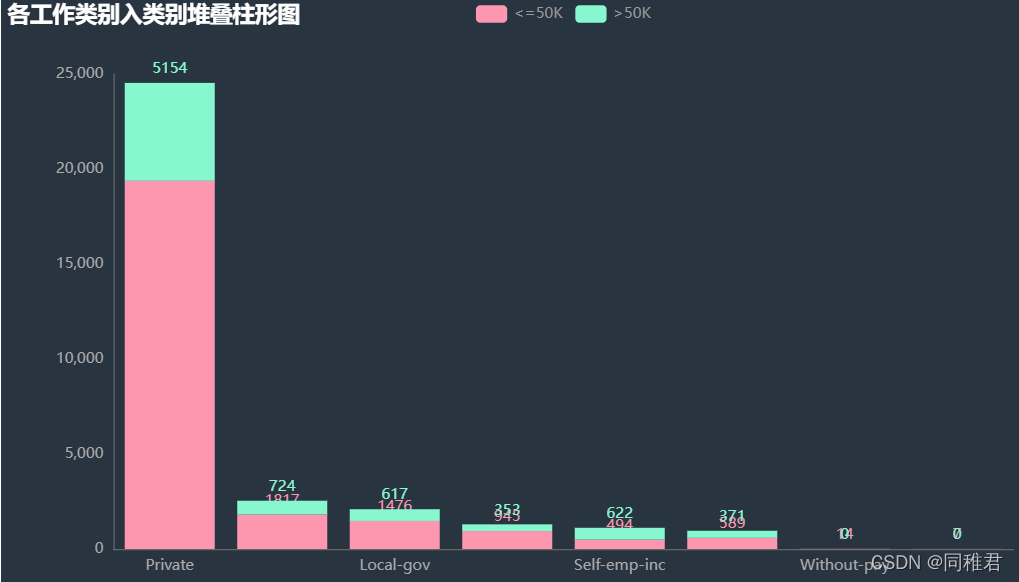
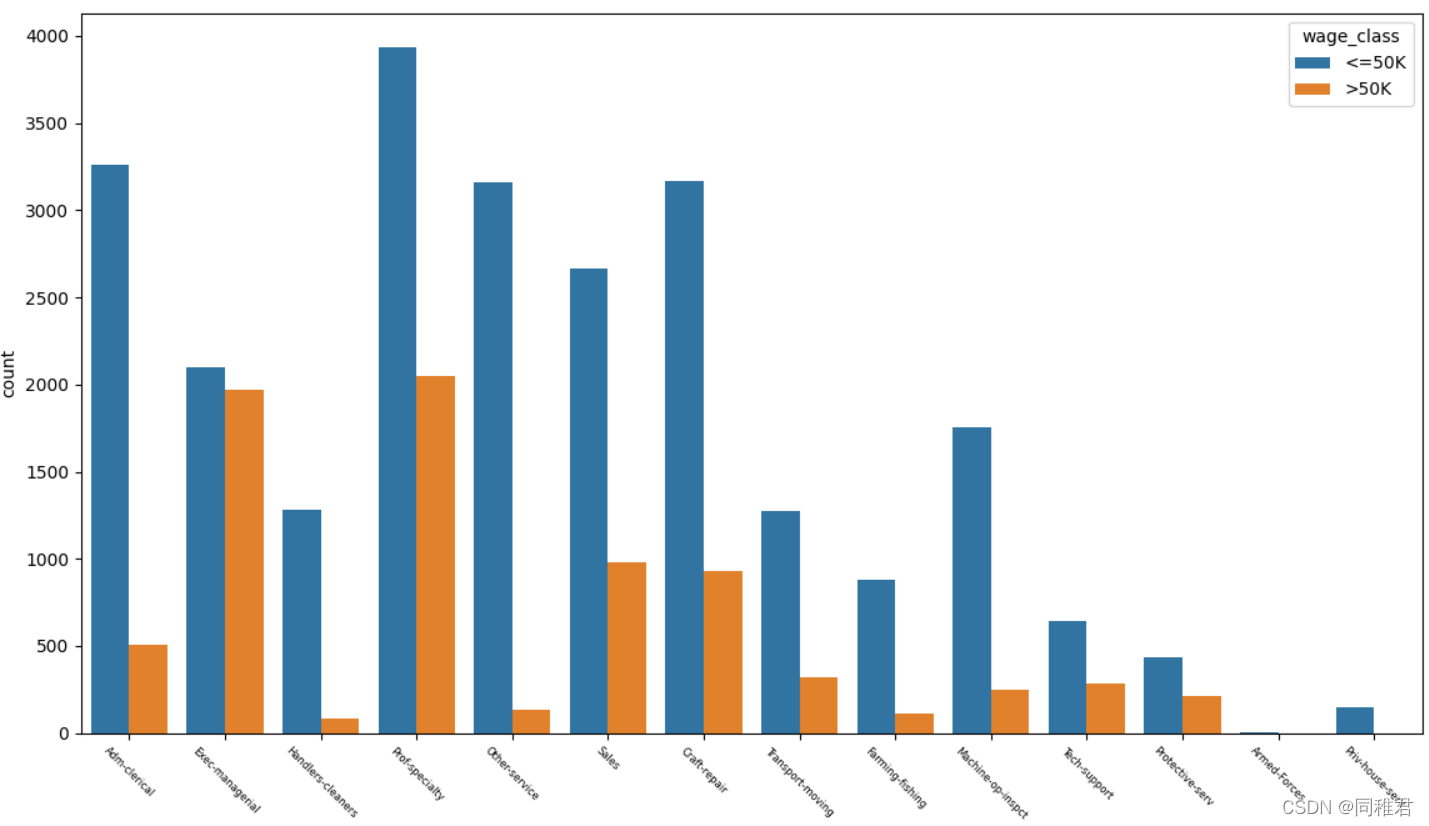
从下图中可以直观看出高收入占比比较高的是Exec-managerial、Prof-specialty,比较低的是Handlers-cleaners、Farming-fishing。
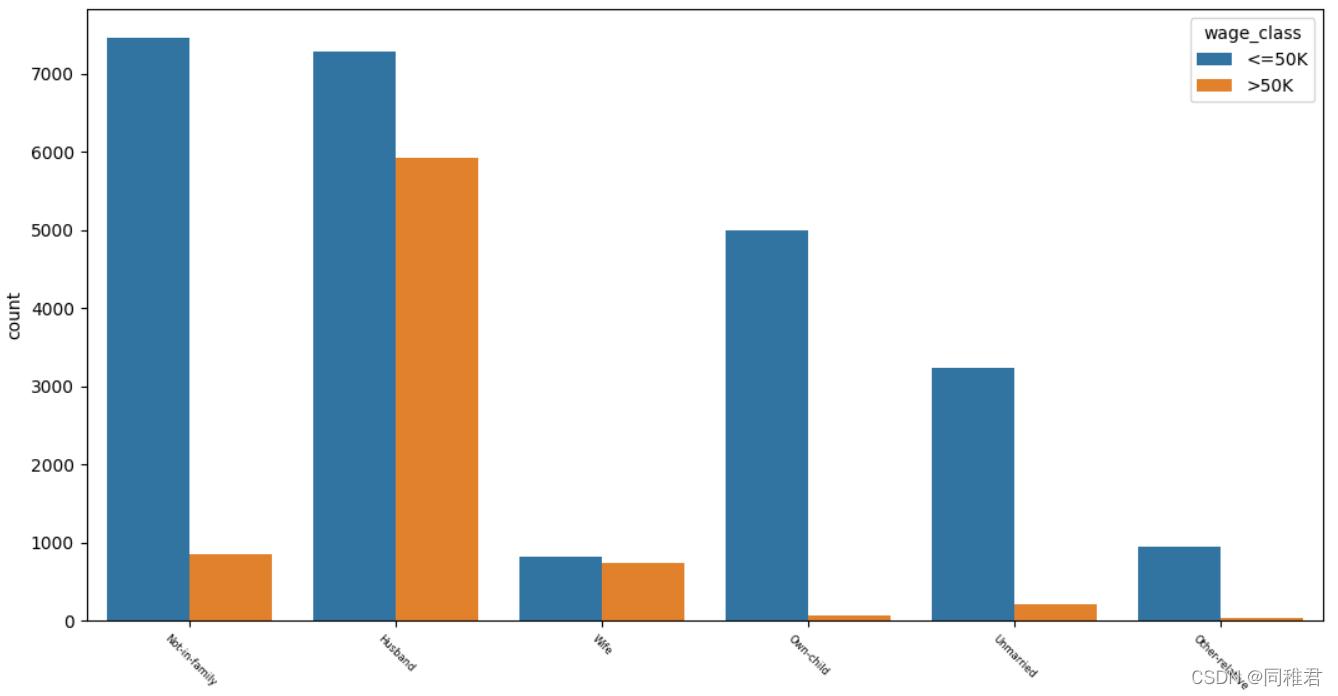
从下图中可以看出拥有家庭的人的收入普遍较高,其中“妻子”角色工作人数较少,说明家庭中一般是“丈夫”在工作。未结婚或有孩子的人的收入普遍小于等于50K。
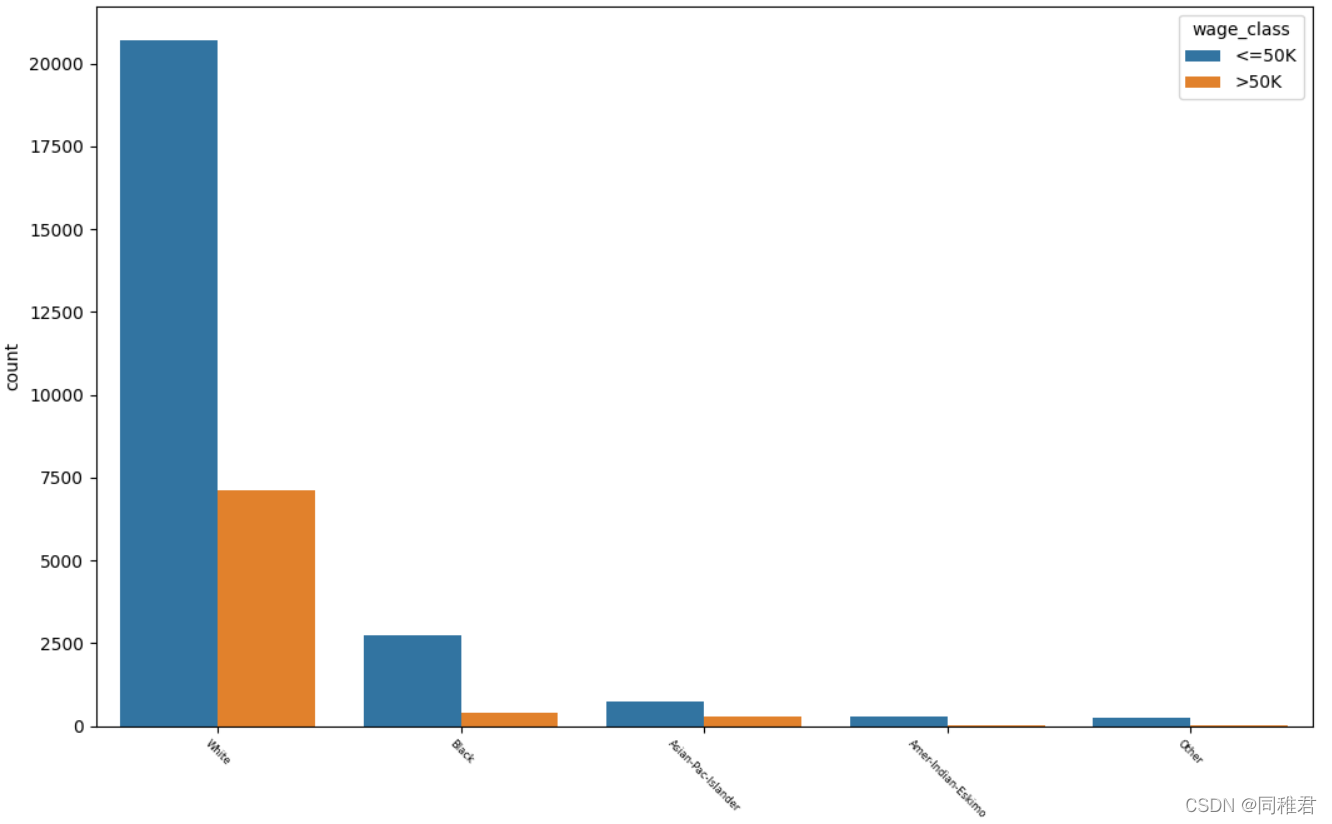
从下图中可以看出白人在总人数中占比最高,白人与亚洲太平洋岛民收入>50K占比较高,黑人中高收入群体占比较低。
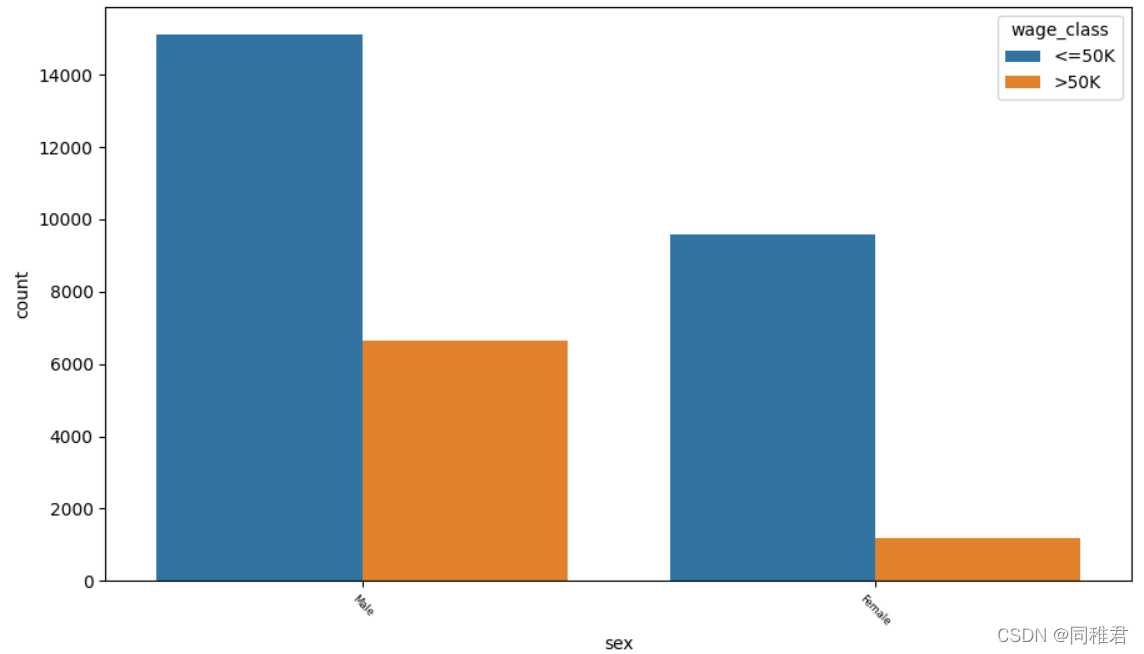
从下图中可以看出男性在人数以及高收入占比上均高于女性。
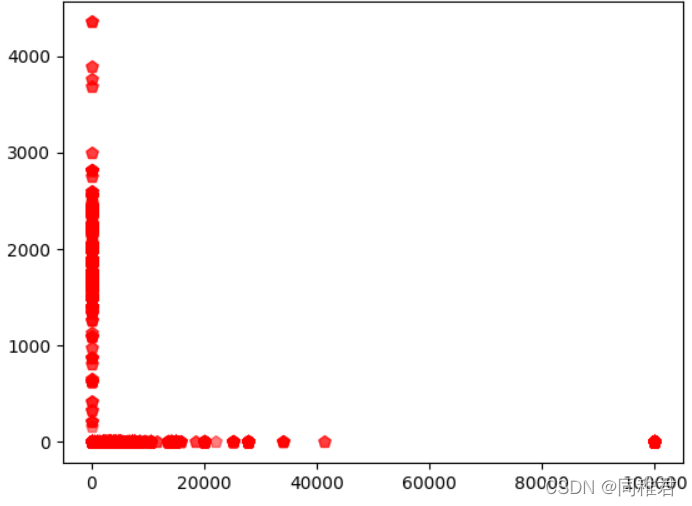
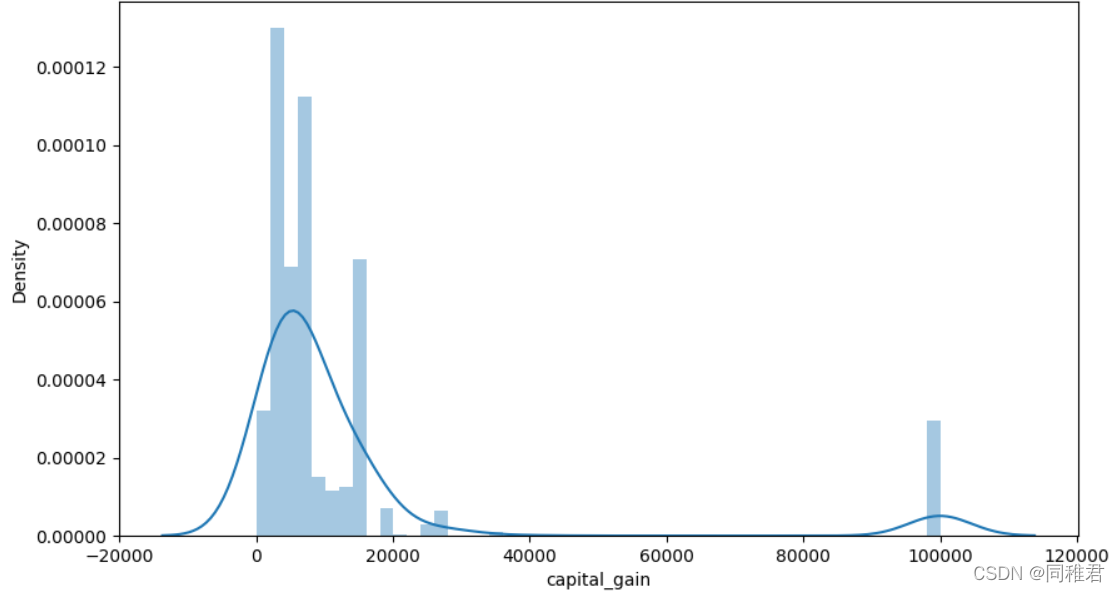
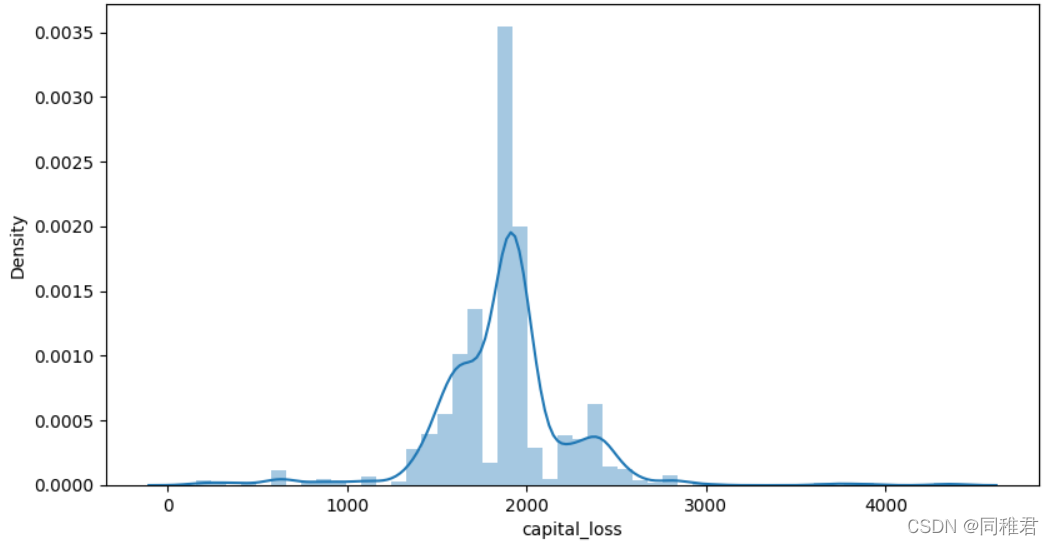
可以看出资本收益与资本损失并不成某种定量关系,反而是程两极关系,存在三种情况:有损失无收益、有收益无损失、既无收益也无损失。
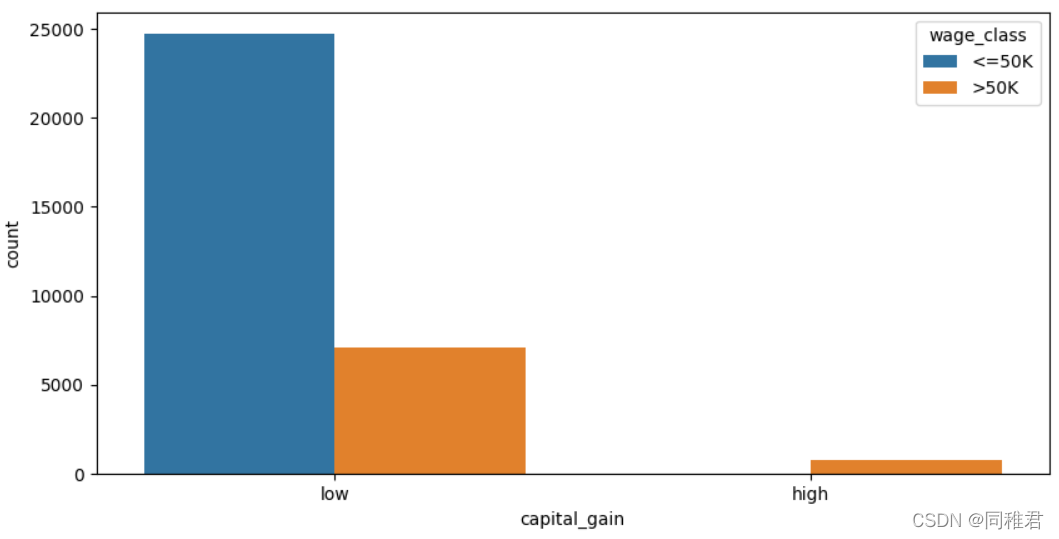
“capital_gain”属性为连续属性,因此可以离散化,首先查看资本收益数据分布情况,可以看到大部分人收益小于10000$。根据数据分布可以将资本收益分为low和high两个层次。离散化后可以看出低资本收益的人占大多数,高资本收益的人高收入占比也高。
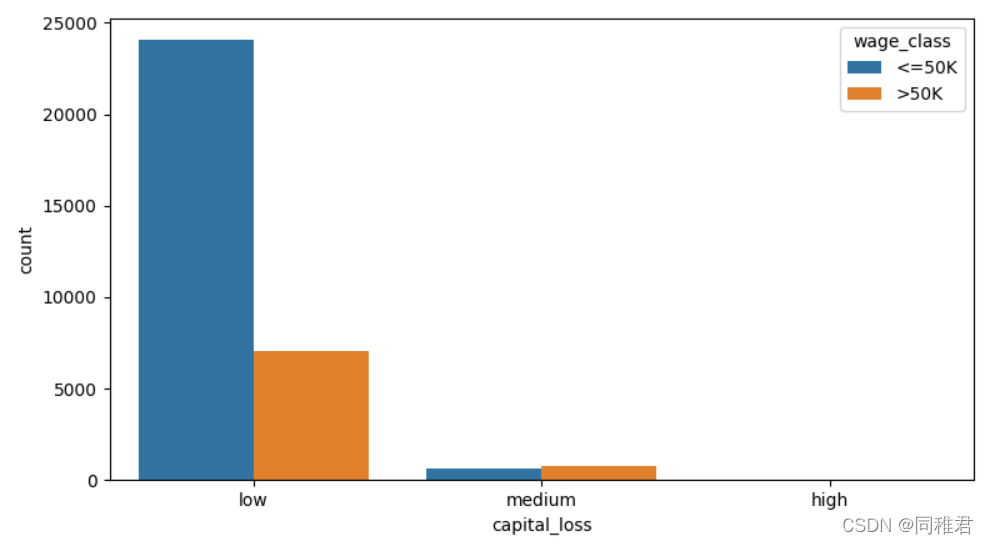
同样的,从资本损失数据分布上分析,可以将资本损失离散化,等距分为“low”、“medium”、“high”三个层次。从离散化后的图表上可以看出资本损失高的群体其高收入人群占比反而高于第资本损失群体。
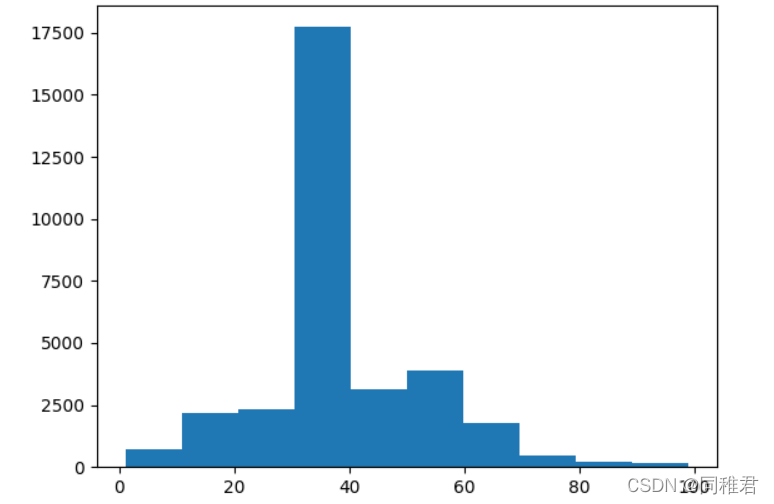
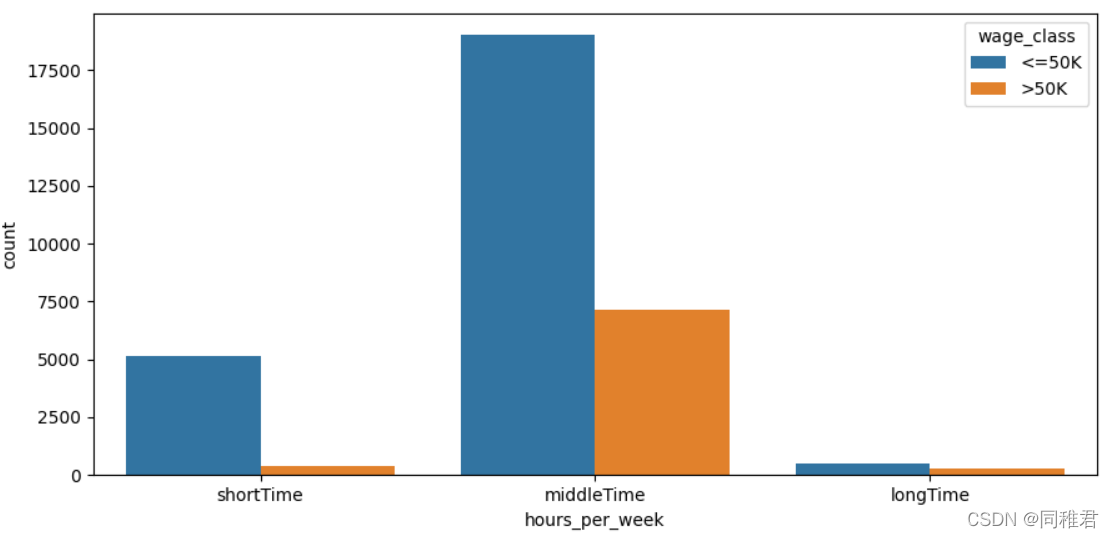
“hours_per_week”是连续属性,因此也需要离散化。从每周工作小时数数据分布直方图上看,可以将每周工作小时数等距划分为3个层次:'shortTime', 'middleTime', 'longTime'。从划分后的图表上看,随着每周工作小时数的增加,高收入占比也在增高。
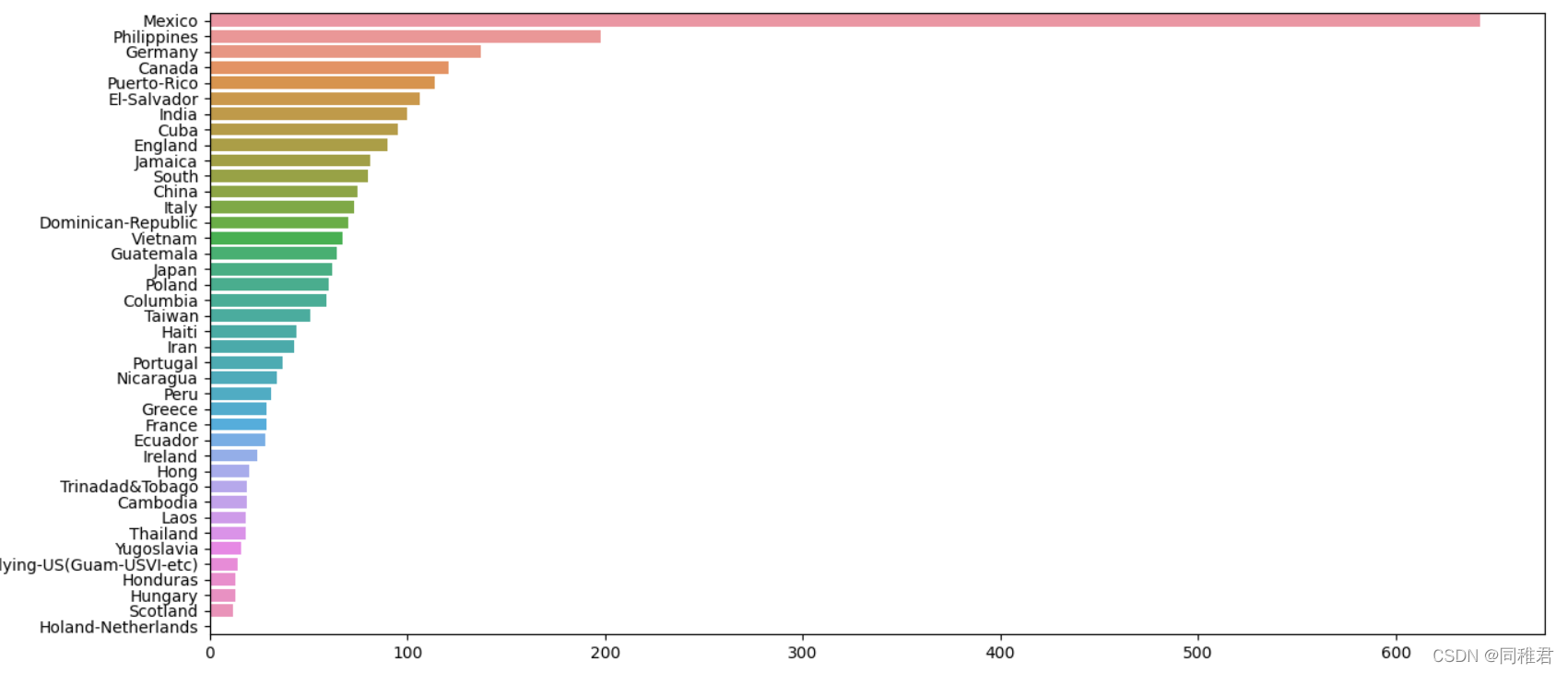
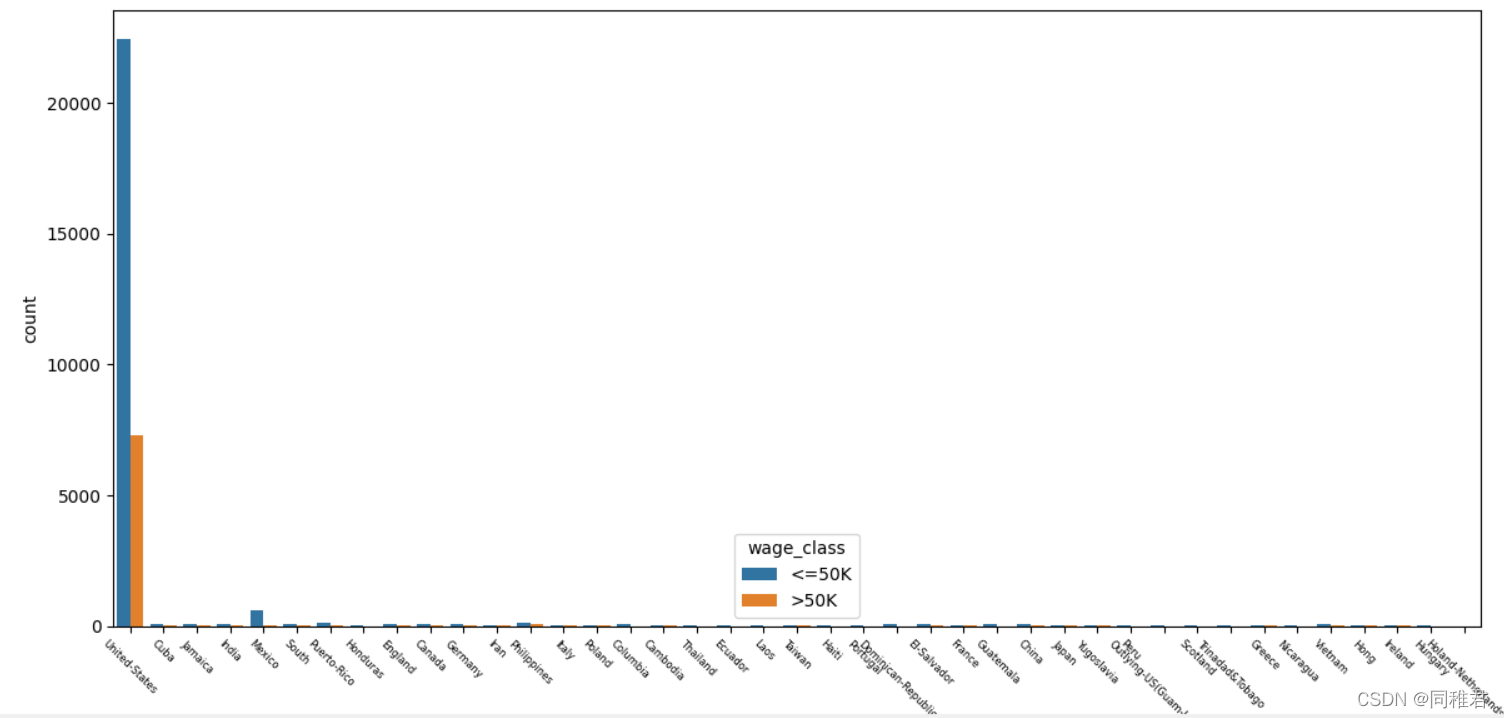
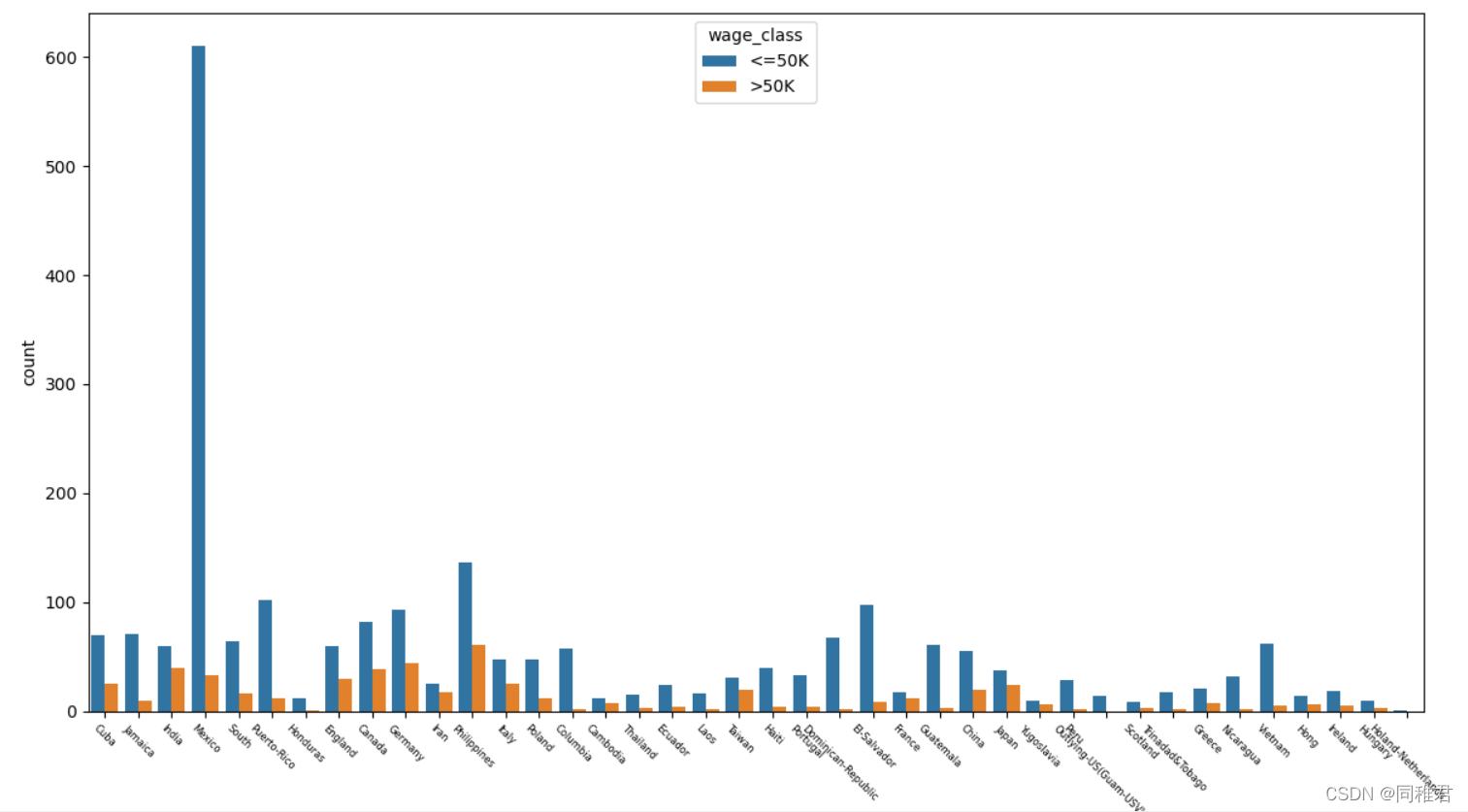
从下图中可以看出美国籍样本占了绝大部分,Mexico,Philippines,Germany籍样本,由于美国籍样本数量过多,影响了其他国际样本数据在图表中的显示,所以在绘制原籍样本数量条形图和原籍收入柱形图中分别绘制包含原籍'United-States'的图表和不包含'United-States'的图表。
本文通过美国人口普查年收入数据集演示了对原始数据的数据挖掘与探索过程,包括数据预处理、特征工程、数据转换、数据可视化分析过程,《数据挖掘导论》与《数据挖掘-实用机器学习工具与技术》提供理论指导。希望通过本文对大家学习数据挖掘有所帮助,对数据进行挖掘是为了更好地进行加下来的数据建模。 |

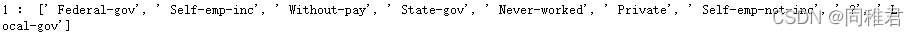

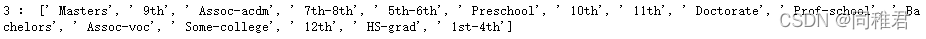

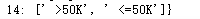



【本文地址】