| Java网络爬虫 | 您所在的位置:网站首页 › 京东扫码下单安全吗 › Java网络爬虫 |
Java网络爬虫
|
文章目录
介绍maven坐标jsoup使用1.解析url,获取前端代码2.解决京东安全界面跳转3.获取每一组的数据4.获取商品数据的具体信息4.最终代码
补充一:获取p-price出现空指针异常
介绍
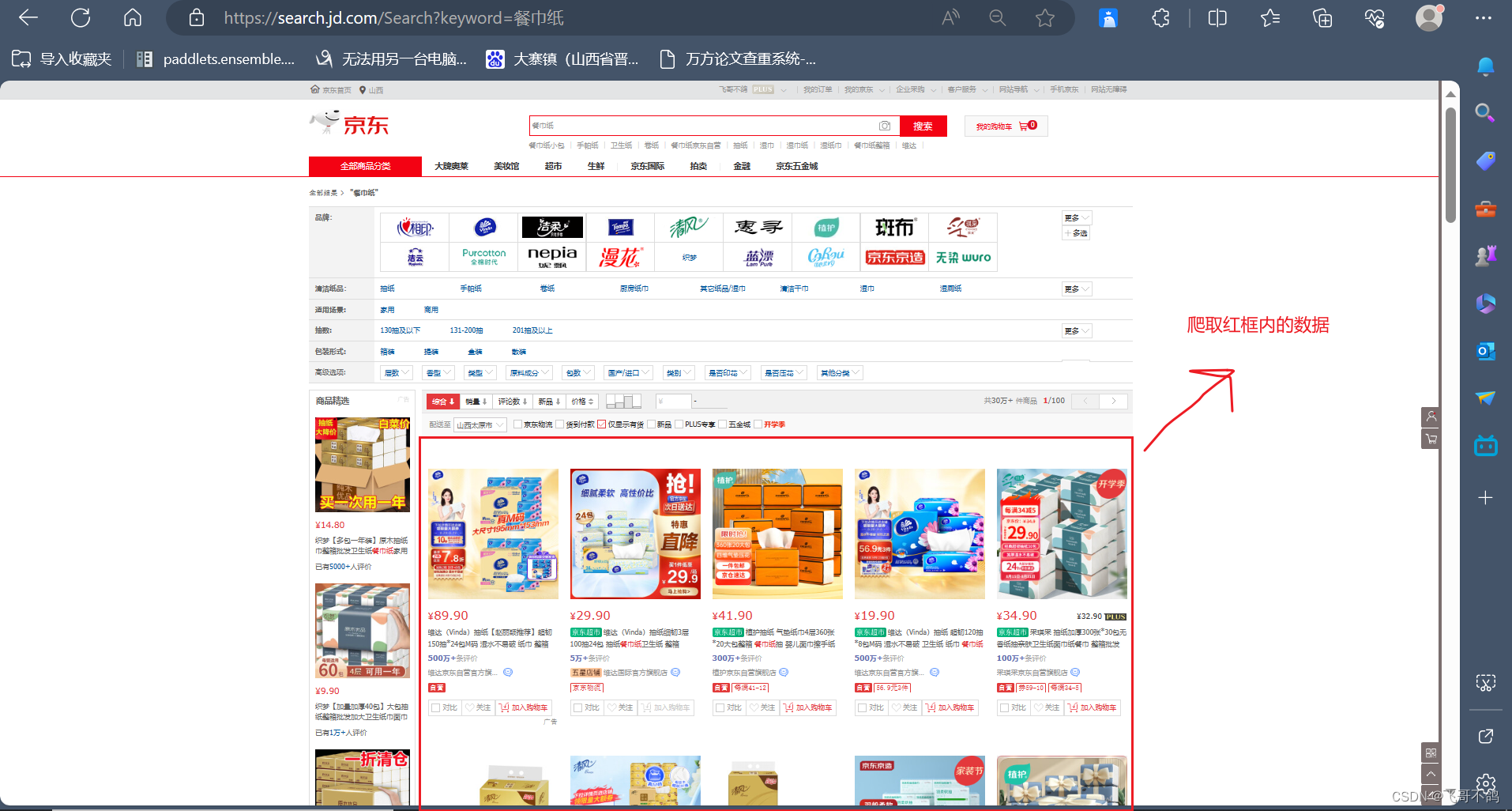
网络爬虫,就是在浏览器上,代替人类爬取数据,Java网络爬虫就是通过Java编写爬虫代码,代替人类从网络上爬取信息数据。程序员通过设定既定的规则,让程序代替我们从网络上获取海量我们需要的数据,比如图片,企业信息等。爬虫的关键是对于网页信息的解析。 什么是jsoup: jsoup是一个用于处理现实世界HTML的Java库。它提供了一个非常方便的API,用于获取URL以及提取和操作数据,使用最好的HTML5 DOM方法和CSS选择器 maven坐标 org.jsoup jsoup 1.11.3 jsoup使用 连接url,爬取网页代码(html代码)解析网页代码,获取需要部分的数据我们以解析京东网页,红框数据为例
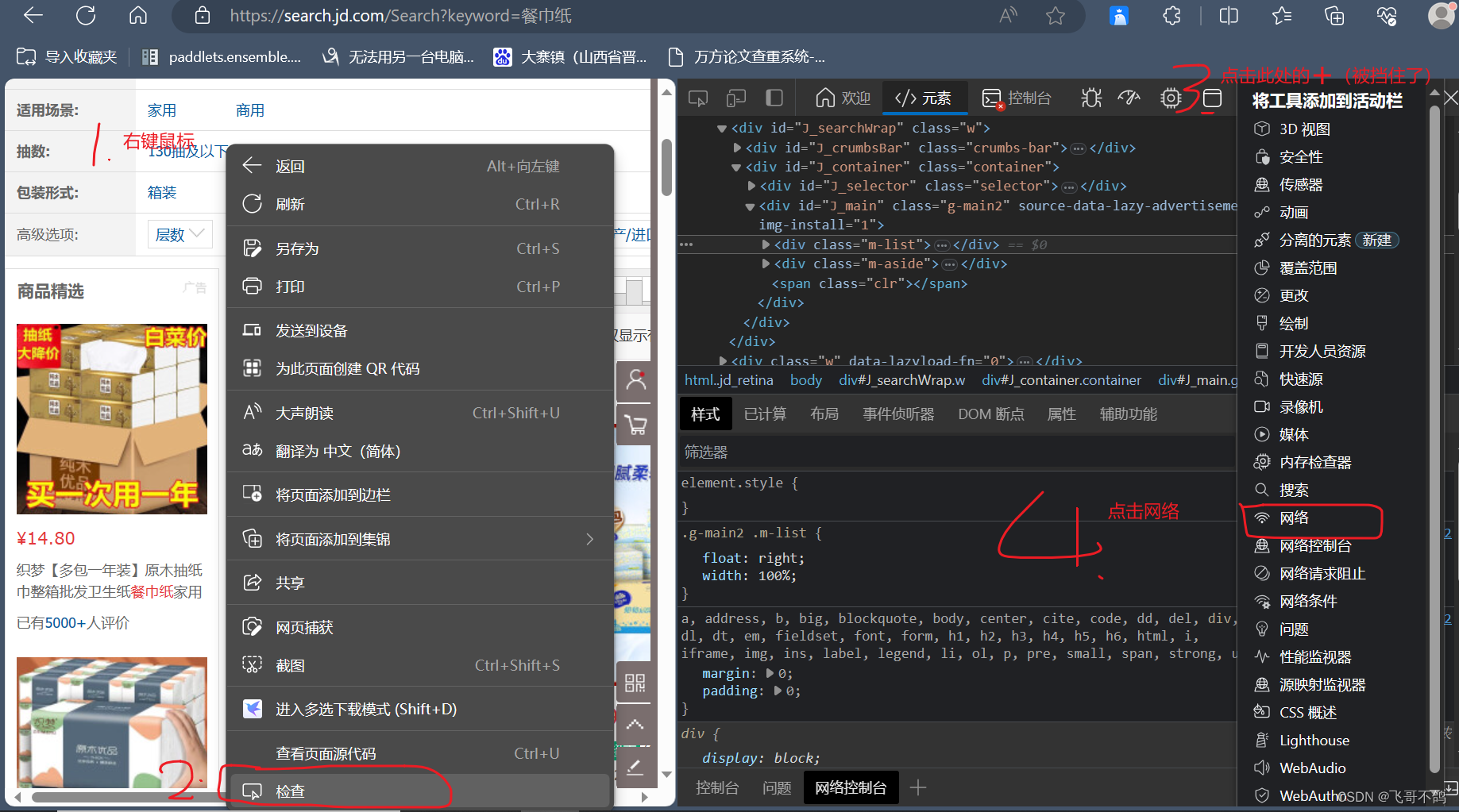
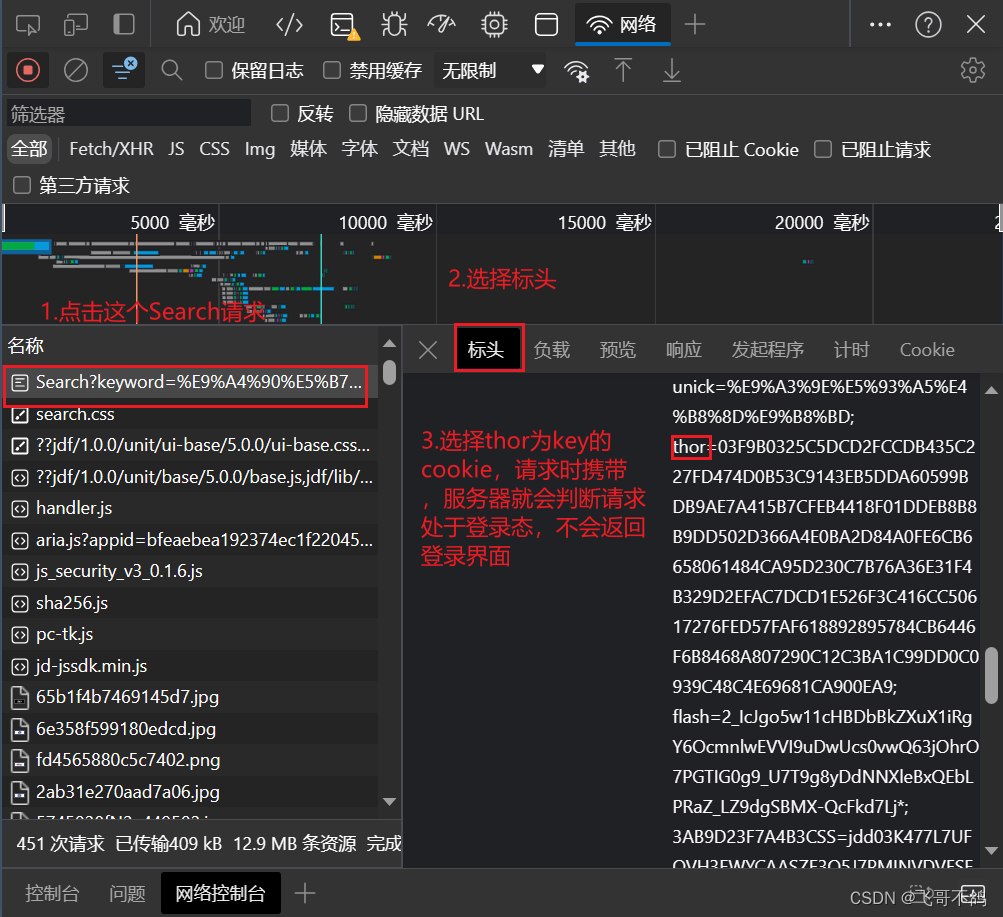
直接通过url访问,经常遇到弹出京东安全的界面 doctype html> 京东安全这算是对于爬取数据的一种反制措施。直接通过url请求,服务器会认为客户端没有登录,因此会跳出京东安全的登陆界面,让他们登录。以前可以通过添加header解决,现在得添加cookie了。获取cookie的方式如下
以下,就是修正后的代码 package com.xhf; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.IOException; import java.net.URL; import java.util.HashMap; import java.util.Map; public class JsoupTest { static String url = "https://search.jd.com/Search?keyword=%E9%A4%90%E5%B7%BE%E7%BA%B8"; public static void main(String[] args) throws IOException { // 设置cookie Map cookies = new HashMap(); cookies.put("thor", "03F9B0325C5DCD2FCCDB435C227FD474D0B53C9143EB5DDA60599BDB9AE7A415B7CFEB4418F01DDEB8B8B9DD502D366A4E0BA2D84A0FE6CB6658061484CA95D230C7B76A36E31F4B329D2EFAC7DCD1E526F3C416CC50617276FED57FAF618892895784CB6446F6B8468A807290C12C3BA1C99DD0C0939C48C4E69681CA900EA9"); // 解析网页, document就代表网页界面 Document document = Jsoup.connect(url).cookies(cookies).get(); System.out.println(document); } } doctype html> 餐巾纸 - 商品搜索 - 京东jsoup中的document可以当作js中的document使用,解析网站内容就是在js中操作document,获取信息 3.获取每一组的数据
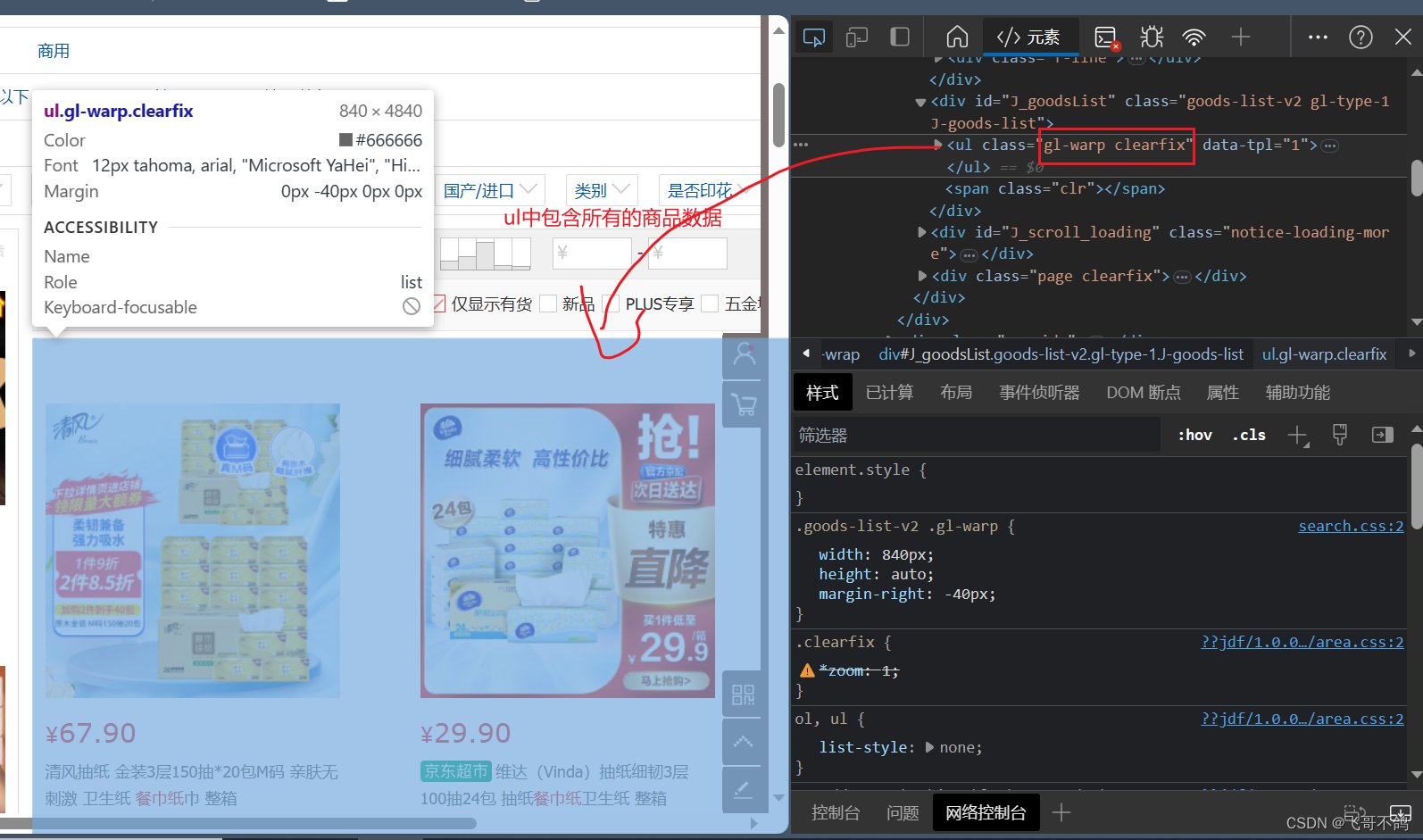
我们发现,所有的商品数据都是通过ul标签进行渲染
每单个数据,则是用li标签渲染 所以,如果我们要获取每个商品数据,我们可以先通过class,获取ul元素,然后选择出ul元素内包含的所有li元素 // 通过class获取ul标签 Elements ul = document.getElementsByClass("gl-warp clearfix"); // 获取ul标签下的所有li标签 Elements liList = ul.select("li"); for (Element element : liList) { System.out.println("------------------"); System.out.println(element); System.out.println(); } ------------------ ¥78.90 维达(Vinda)抽纸 超韧150抽*24包S码 湿水不易破 卫生纸 纸巾 餐巾纸 整箱 【纸选维达,实力出发】爆品低至6.6折,抢新品低价试用 【神券疯狂领】满199减40神券 【会员福利送】下单满1元赢手机好礼,直达开抢! 维达京东自营官方旗舰店 自营 2件9折 对比 关注 加入购物车 ------------------ ¥54.90 洁柔抽纸 活力阳光橙3层120抽面巾纸*24包 母婴可用 全家适用 【洁柔新品来袭】洁柔爱马仕设计师联名款重磅上线!爆款好物空前钜惠,爆品低至6.6折!【洁柔大会员】抢神券,会员臻享八大特权go 洁柔京东自营官方旗舰店 自营 对比 关注 加入购物车 ...其余数据不做展示 4.获取商品数据的具体信息通过遍历上述代码中出现的liList,可以获取到每一个li元素。每个元素都代表了商品的一组信息。具体如下所示。
如果我们要获取更为具体的信息,比如价格,图片,介绍等信息。我们就需要对li标签所封装的对象进行数据的截取。
我们可以用getElementsByTag("img")来获取带有img标签的对象,然后获取其data-lazy-img属性的数据 String pict = element.getElementsByTag("img").first().attr("data-lazy-img");价格 我们可以通过getElementsByClass("p-price")的方式获取对象,然后获取其中内容 String price = element.getElementsByClass("p-price").first().text();shop名称,类似价格获取方式 4.最终代码 package com.xhf; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import java.io.IOException; import java.net.URL; import java.util.HashMap; import java.util.Map; /** * 解析京东界面, 爬取商品数据 */ public class JsoupTest { static String url = "https://search.jd.com/Search?keyword=%E9%A4%90%E5%B7%BE%E7%BA%B8"; public static void main(String[] args) throws IOException { // 设置cookie Map cookies = new HashMap(); cookies.put("thor", "03F9B0325C5DCD2FCCDB435C227FD474D0B53C9143EB5DDA60599BDB9AE7A415B7CFEB4418F01DDEB8B8B9DD502D366A4E0BA2D84A0FE6CB6658061484CA95D230C7B76A36E31F4B329D2EFAC7DCD1E526F3C416CC50617276FED57FAF618892895784CB6446F6B8468A807290C12C3BA1C99DD0C0939C48C4E69681CA900EA9"); // 解析网页, document就代表网页界面 Document document = Jsoup.connect(url).cookies(cookies).get(); // 通过class获取ul标签 Elements ul = document.getElementsByClass("gl-warp clearfix"); // 获取ul标签下的所有li标签 Elements liList = ul.select("li"); for (Element element : liList) { System.out.println("------------------"); String pict = element.getElementsByTag("img").first().attr("data-lazy-img"); String price = element.getElementsByClass("p-price").first().text(); String shopName = element.getElementsByClass("p-shop").first().text(); System.out.println(pict); System.out.println(price); System.out.println(shopName); } } } 补充一:获取p-price出现空指针异常有不少观众在爬取网页代码时,在获取p-price属性时出现了空指针问题(如下图所示),作为文章的补充内容,统一回复一下
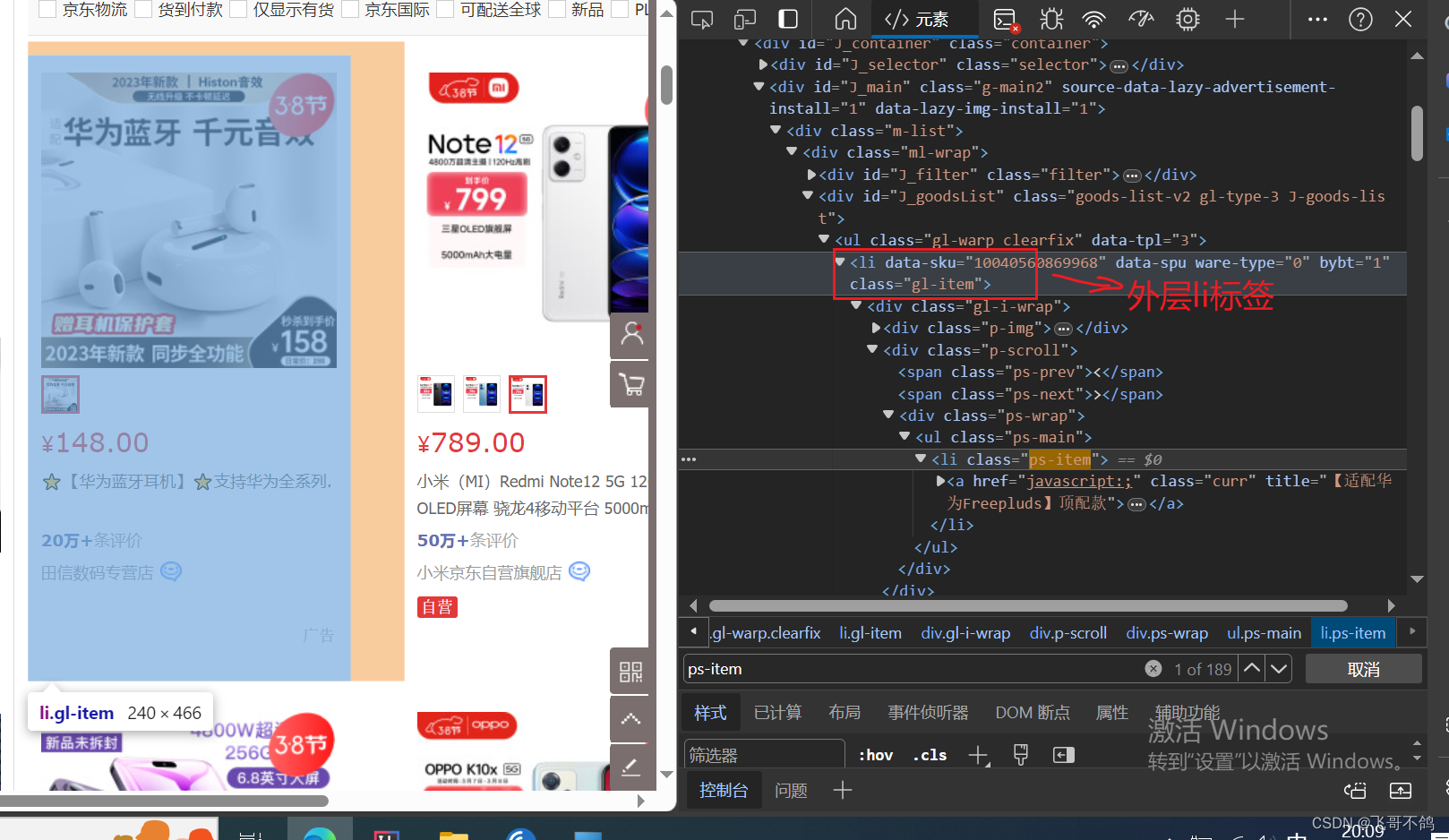
对于某些京东页面(有些界面存在这样的情况,有的没有),每个商品元素可能存在多份图片。一种是详细图、另一种是缩略图。在前端代码中,详细图是被外层li标签包裹,外层li标签含有p-price属性;而缩略图被内层li标签包裹,内层li标签不含有p-price属性。当在进行爬虫时,爬取到内层li标签时,因为没有p-price属性,因此返回null值。调用空对象的方法,自然抛出空指针异常问题。 这么说有些抽象,我们上图解释
针对上述分析,我们可以在获取li标签时进行内外层次的区分。过滤掉内层li标签,我们不需要缩略图的信息。 仔细观察,我们发现内外li标签存在以下区别 外层li标签,class = "gl-item"内层li标签,class = "ps-item"因此在遍历li时,可以根据class进行筛选,具体代码如下 // 过滤内层标签 if ("ps-item".equals(element.attr("class"))) { continue; }通过.attr("class")获取标签的class属性,如果class为ps-item,则当前标签为内层标签,过滤 完整代码 public class JsoupTest { static String url = "https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&wq=%E6%89%8B%E6%9C%BA&pvid=8858151673f941e9b1a4d2c7214b2b52&czLogin=1"; public static void main(String[] args) throws IOException { // 设置cookie Map cookies = new HashMap(); cookies.put("thor", "51664BB815480B40C9BC99D1E3E76D810043E59D85A51BA3D7CF12A986735FD21314241E8DACE095E51DC048D68501E00F568A0A6387017449D23996F3FF832BF501CCCD7E17747CBBD81D86B59C2DAD1E8ADD845F3D78D34F3F7C98B077CC6122B5EA67CB52C5E3E2297F0C00C70F048384E7C719D954A3C3B925E7B7DEBAD77964C1AD145AAAA2A0797B928B4ABC3EEA676CD673C2283BFD0CEC7738C0156C"); // 解析网页, document就代表网页界面 Document document = Jsoup.connect(url).cookies(cookies).get(); // 通过class获取ul标签 Elements ul = document.getElementsByClass("gl-warp clearfix"); // 获取ul标签下的所有li标签 Elements liList = ul.select("li"); for (Element element : liList) { System.out.println("------------------"); // 过滤内层标签 if ("ps-item".equals(element.attr("class"))) { continue; } String pict = element.getElementsByTag("img").first().attr("data-lazy-img"); String price = element.getElementsByClass("p-price").first().text(); String shopName = element.getElementsByClass("p-shop").first().text(); System.out.println(pict); System.out.println(price); System.out.println(shopName); } } } |
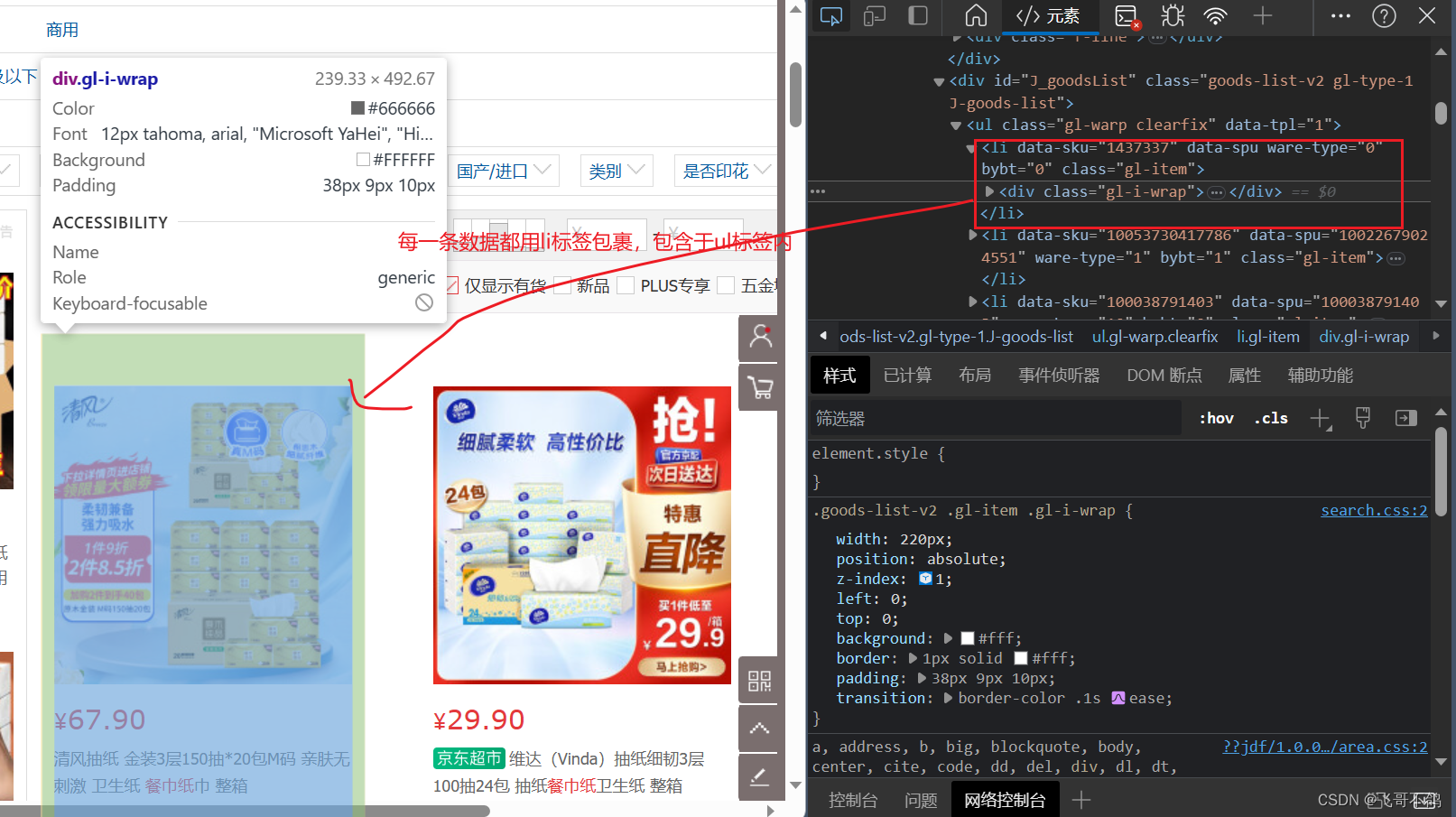


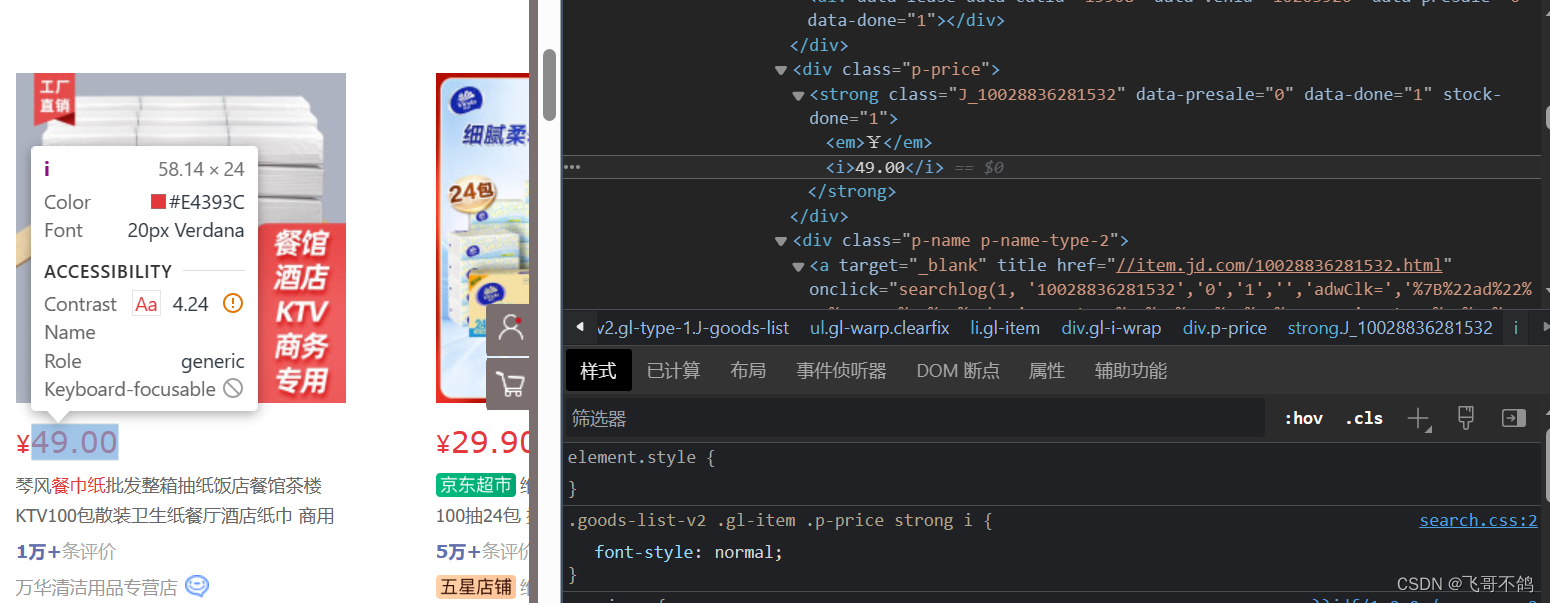

 如上图所示,外层li标签包裹整个商品数据,同时包含了图片、价格等信息
如上图所示,外层li标签包裹整个商品数据,同时包含了图片、价格等信息 而这幅图就是内层li标签所包裹的对象——缩略图信息。因为缩略图不含有价格信息,因此代码获取不到对应信息。
而这幅图就是内层li标签所包裹的对象——缩略图信息。因为缩略图不含有价格信息,因此代码获取不到对应信息。【本文地址】