| Stable Diffusion教程 | 您所在的位置:网站首页 › 五人合绘模板图片 › Stable Diffusion教程 |
Stable Diffusion教程
|
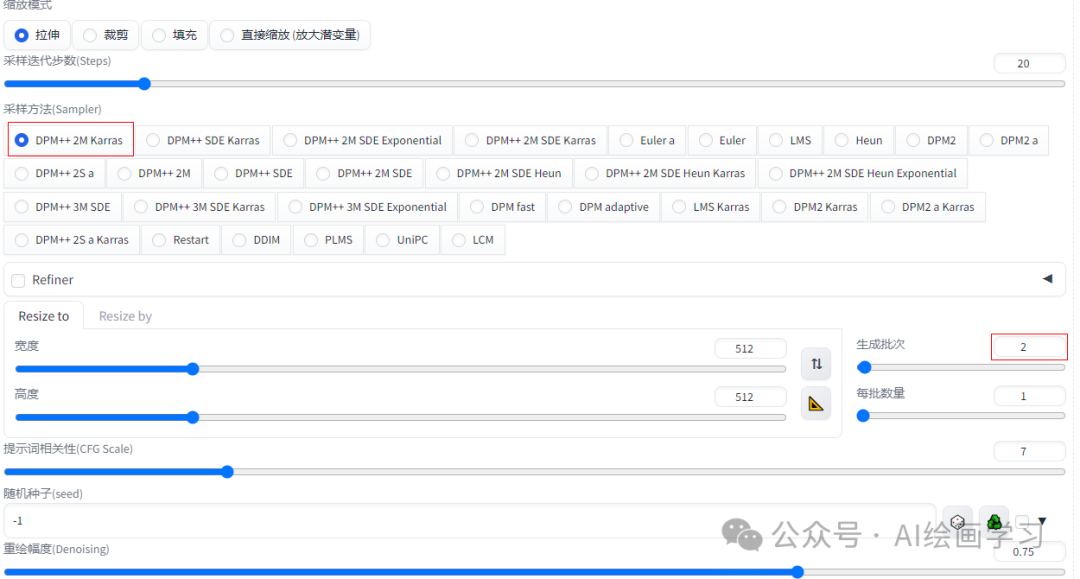
局部重绘是Stable Diffusion模型在图像生成应用中的一个核心特性,它赋予用户针对图像特定部分进行再创作的能力,以此实现丰富多彩的视觉表达与创新效果。通过启用局部重绘功能,AI绘画的创新潜力与操作灵活性得到显著提升,使得用户能够在广阔的创意疆域内随心所欲地试验与实践各类图像编辑与生成任务,尽情释放想象力。 目录 1 局部重绘 2 涂鸦重绘 3 上传重绘蒙版 4 批量重绘 一、局部重绘 功能介绍 SD和其他AI绘画Midjourney最大的区别就是可控,局部重绘功能就是增加这种可控性,它能够针对图像的局部按需重绘,从而实现更加细致和图像的编辑。 实战技巧 1【用局部重绘换脸】 step 1 选择一个写实大模型“麦橘写实”,进入到“图生图”页面,切换到“局部重绘”,上传一张大头照 512*512。
模型下载地址:https://www.liblib.art/modelinfo/bced6d7ec1460ac7b923fc5bc95c4540 模型存放目录: …\novelai-webui-aki-v3\models\Stable-diffusion step 2 使用涂抹工具,可以把脸部全部涂抹上(如果你看过之前的教程,可以安装插件,快捷键调整笔触和图片大小,涂抹得更加精确)
step 3 选择采样器和生成批次2,其他设置默认不变,提示词也不用写,除非你要描述脸部特征,直接生成。
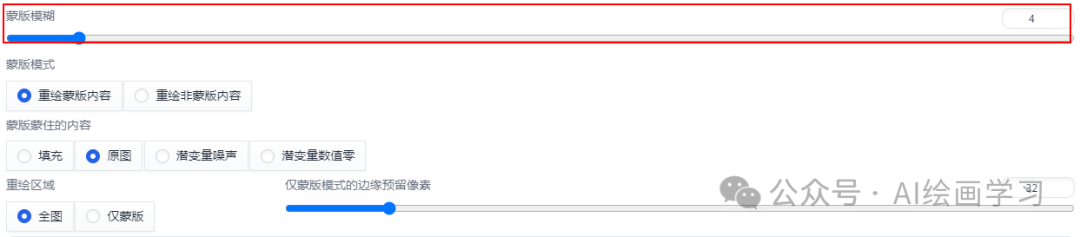
(换成了一胖一瘦两张脸,刘海也变了,但边缘处不太完美,下巴脖颈处有很大的痕迹) *小技巧1:蒙版模糊设置*
让重绘的边缘模糊,类似ps里面的羽化功能,能更好的融合重绘内容和原图的过渡区域,默认值4,可以根据情况不断尝试。参数范围0~64,分别测试了20、30、40、50,到了40以上下巴被修复。
*实战技巧 2*【换主体-换背景】 蒙版模式:重绘蒙版内容,换主体,用上面换脸的方式涂抹小狗,然后提示词“a cat”生成即可。 注意:这时候蒙版模糊要小,不然会保留一些狗的轮廓,我这里设置5。
重绘蒙版内容-狗变猫 蒙版模式:重绘非蒙版内容,换背景,提示词“forest”
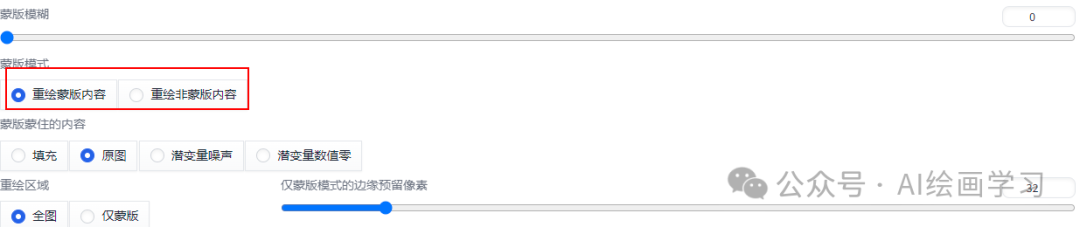
重绘非蒙版内容-换背景 *实战技巧 3*【无中生有】 ** ** 蒙版蒙住的内容:是对蒙版重绘的初始画面设置 ** **
填充 原图 潜变量噪声 潜变量数字零
重绘幅度0.02 的不同效果 原图(微调):在原来图像上重绘,适合微调图像布局。 填充(大改):将重绘区模糊效果,让AI重新降噪生成图像。 潜变量数值零(大改):与填充类似,生成一个色调相似的纯色在重绘。 潜变量噪声(无中生有):铺马赛克并重新降噪生成图像,产生变化很大,从而无中生有。 *其他设置:* 重绘区域:全图和仅蒙版,通常选“全图”,不然过渡区容易衔接不好,除非重绘区域极小。 仅蒙版区域下边缘预留像素:和蒙版模糊道理类似,值约高AI会参考周边的像素进行重绘,我这里设置的100,大家可自行尝试,值不同生成的内容会不同。 **二、**涂鸦重绘 ** ** 功能介绍 绘图(涂鸦)+提示词,比局部重绘控制更精准一些,我们可以自由的创作和定制图像,比如:根据涂鸦形状设计产品,或给人物加上饰品、戴上眼镜、换衣服、换发型等 实战技巧 【戴眼镜】 setp1 切换到“绘图”,选择一个颜色,涂一个眼睛的形状,提示词“red glasses”,点击生成。
setp2 涂鸦区域比较糙,可以调大重绘幅度,让AI自由发挥,我这里是0.75,值越大,除了涂鸦的部分,其他部分也发生了更大变化。
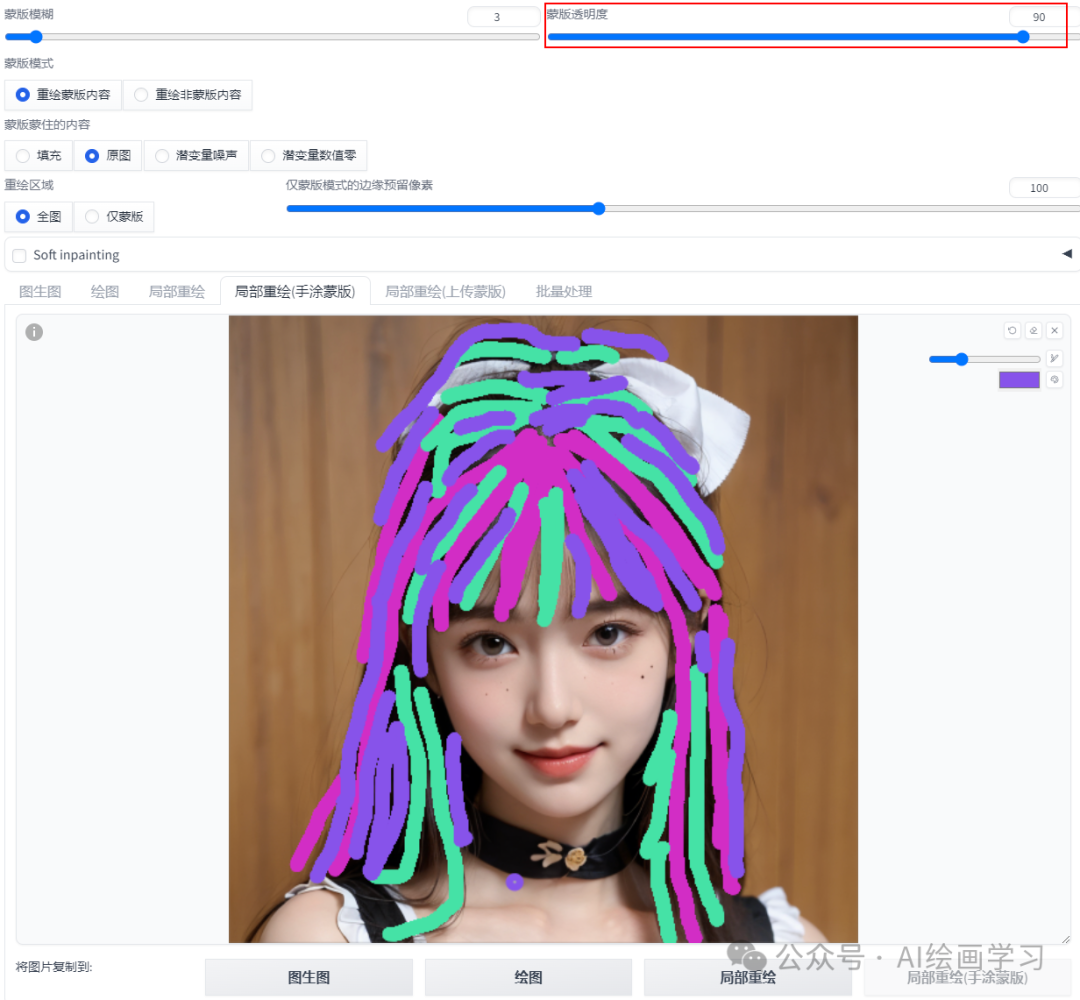
戴上红眼镜 【染个发】 切换到“手涂蒙版”,选择不同颜色,画几缕头发, 设置“蒙版透明度=90”,点击生成。
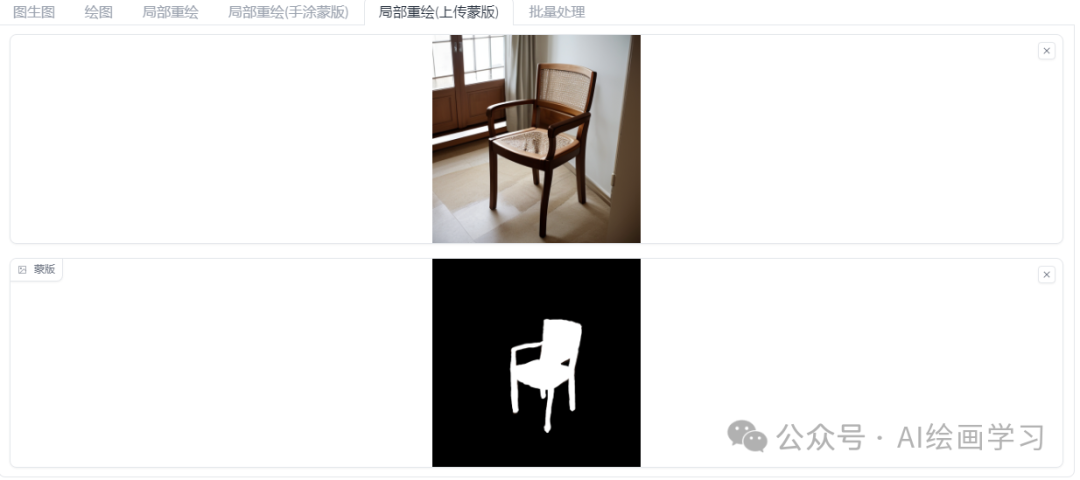
AI染发前后 注意:透明度越大,越透明和原图越融合。 ** ** ** ** *三、上传**重绘蒙版* * * 功能介绍 由于涂鸦是鼠标操作,涂不太准,如果想更精准的涂蒙版,可以用PS去精准蒙版后,再上传到SD,从而达成精准的重绘。 实战技巧 【家具换把椅子】 setp1 用Photoshop或别的抠图软件,打开一张图片,用选择工具,快速选择椅子。 setp2 选区内,填充白色,反选选区,填充黑色。 setp3 回到SD,上传蒙版,提示词“chair”
注意:精细化蒙版 白色区域替换 黑色区域保留 * * * * *四、批量重绘 * 功能介绍 同时处理多张上传蒙版并重绘图像,需要先设置好输入的目录、输出目录等路径。
注意:输入目录、输出目录路径不能有中文和特殊字符。 如果还是看不懂的,可以微信扫描下方CSDN官方认证二维码,手把手教你生成AI绘画!  关于AI绘画技术储备
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助! 👉[[CSDN大礼包:《StableDiffusion安装包&AI绘画入门学习资料》免费分享]](安全链接,放心点击) 对于0基础小白入门: 如果你是零基础小白,想快速入门AI绘画是可以考虑的。 一方面是学习时间相对较短,学习内容更全面更集中。 二方面是可以找到适合自己的学习方案 包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画! 1.stable diffusion安装包 (全套教程文末领取哈)随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。 最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。 这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
|




























【本文地址】