| 如何理解遗传算法中的编码与解码?以二进制编码为例 | 您所在的位置:网站首页 › 二进制编码什么意思啊 › 如何理解遗传算法中的编码与解码?以二进制编码为例 |
如何理解遗传算法中的编码与解码?以二进制编码为例
|
文章目录
前言编码解码补充
前言
遗传算法的编码方法各种各样,但二进制串编码方式是最经典的一种,那么它的编码和解码该如何进行呢?或许本博客能给你一个具有参考价值的答案。 编码经典遗传算法中使用“染色体”来代指个体,它由二进制串组成,如下图所示: 
它的每一维称为一个基因,取值为0或1。 下面用一个具体的优化问题来解释个体(染色体)的编码和解码: m a x m i z e f ( x ) = − x 2 + 10 cos ( 2 π x ) + 30 , − 5 ≤ x ≤ 5 maxmize \ f(x)\ =\ -x^2+10\cos{(2\pi x)}+30,\ -5\le x \le 5 maxmize f(x) = −x2+10cos(2πx)+30, −5≤x≤5 对于上述待优化函数,我们的编码应该设置多长的二进制串呢? 我们首先明确,编码长度取决于自变量的范围(更准确点应该是决策变量的范围)和搜索精度,所以围绕它们来考虑如何编码。 在本例,我们假设精度是0.01,记清楚了,是 0.01。 首先,我们可以确定自变量的范围(更准确点应该是决策变量的范围)是5-(-5)= 10. 另外,我们需要的精度是0.01,也就是说我们要能用我们的编码把自变量范围10以10.00表示,但二进制串只能表示整数没法表示小数(其实可以表示小数的,但我们不讨论这种情况),所以我们换个思路,我们用1000来表示10.00,但请注意,二进制串转化为十进制时不能刚好得到1000,而是得到
2
n
2^n
2n,所以我们得找到一个最大值大于1000的二进制串。 |
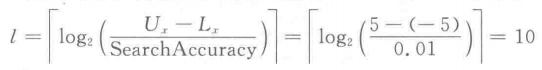 根据上图,我们发现可以用长度为10的二进制串来“容纳”上述的1000,为什么我用“容纳”来表述呢?因为长度为10的二进制串可以表示
0
∼
(
2
10
−
1
)
0 \thicksim (2^{10}-1)
0∼(210−1),也就是
0
∼
1023
0 \thicksim 1023
0∼1023,有
1023
>
1000
1023>1000
1023>1000;而
0
∼
(
2
9
−
1
)
0 \thicksim (2^{9}-1)
0∼(29−1)是
0
∼
511
0 \thicksim 511
0∼511, 有
511
<
1000
511
根据上图,我们发现可以用长度为10的二进制串来“容纳”上述的1000,为什么我用“容纳”来表述呢?因为长度为10的二进制串可以表示
0
∼
(
2
10
−
1
)
0 \thicksim (2^{10}-1)
0∼(210−1),也就是
0
∼
1023
0 \thicksim 1023
0∼1023,有
1023
>
1000
1023>1000
1023>1000;而
0
∼
(
2
9
−
1
)
0 \thicksim (2^{9}-1)
0∼(29−1)是
0
∼
511
0 \thicksim 511
0∼511, 有
511
<
1000
511【本文地址】