| 二维特征分类的基础 | 您所在的位置:网站首页 › 二维特征空间的定义 › 二维特征分类的基础 |
二维特征分类的基础
|
1.分类问题不要用回归来做 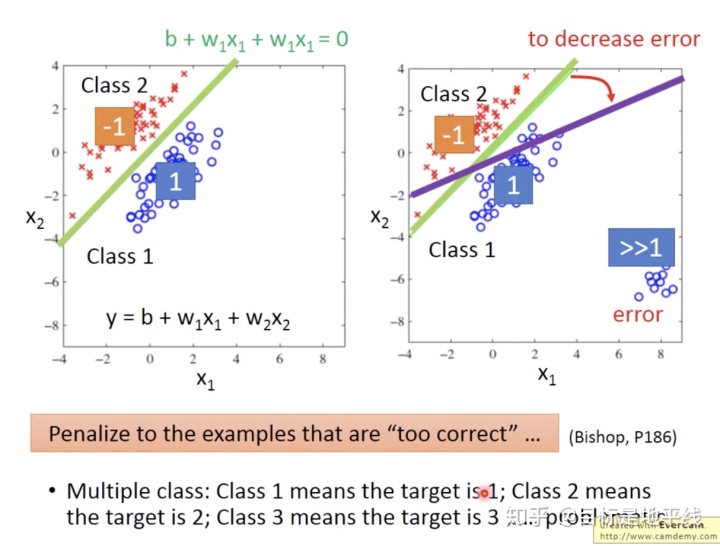
正确做法:  Generative Model:(几率模型)
Generative Model:(几率模型)
生成模型:无穷样本->概率密度模型->产生模型->预测 生成方法由数据学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)=P(X,Y)/P(X)作为预测的模型。这样的方法之所以成为生成方法,是因为模型表示了给定输入X产生输出Y的生成关系。用于随机生成的观察值建模,特别是在给定某些隐藏参数情况下。典型的生成模型有:朴素贝叶斯法、马尔科夫模型、高斯混合模型。这种方法一般建立在统计学和Bayes理论的基础之上。 朴素贝叶斯分类: 
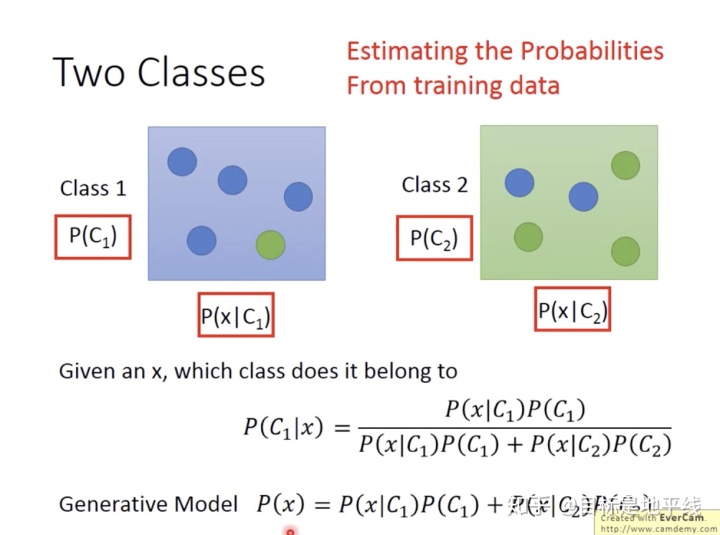
示例:假设训练集中有79只水系的宝可梦,61只一般系的宝可梦。 
每一个宝可梦都是用一堆feature(向量)【这里只用防御力和特殊防御力表示】来表示。挑选出x=海龟那么它属于水系的概率是多少呢?海龟不在training data中哈。 
要从training data 中估测呀,比如这里用的高斯分布。 
高斯分布的结果几率由两方面组成: 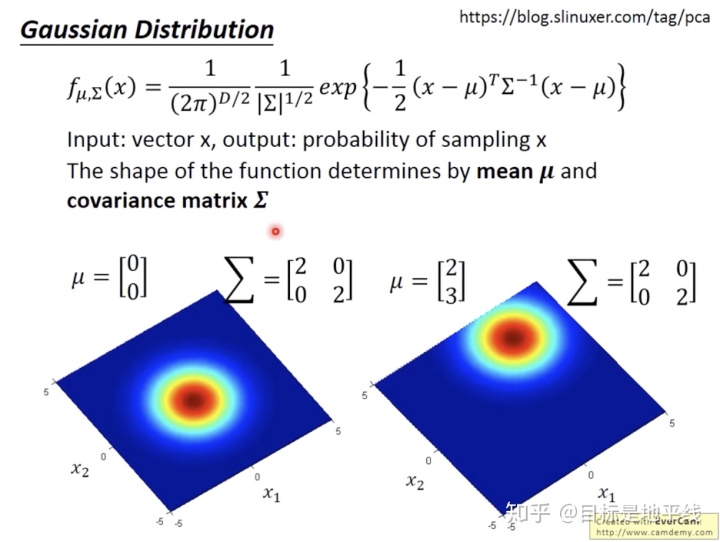
那么通过训练集sample79次就可以找出来训练集高斯分布的两个参数,则对于新的new x 带入就可以得到正比于预测几率的结果了,这个结果这里就叫做几率了。 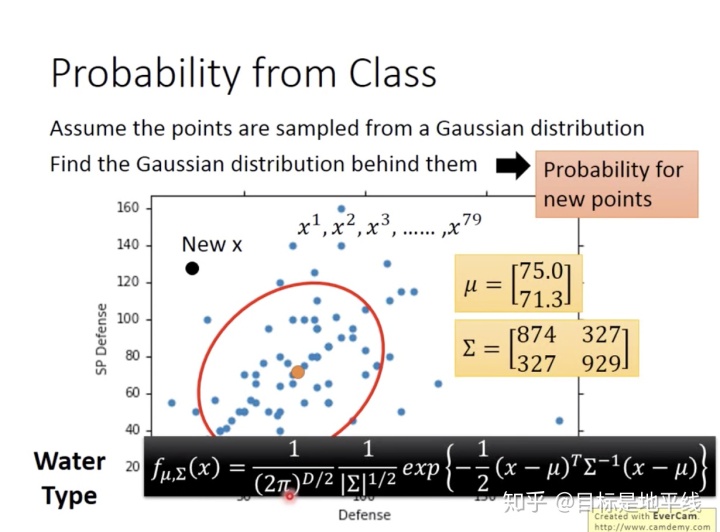
那么这两个参数如何找呢?通过最大似然估计法:每一个高斯分布都可以sampled出来79个点,但是他们的可能性是不一样的。一个高斯分布sampled出来79个点的几率相乘总几率是 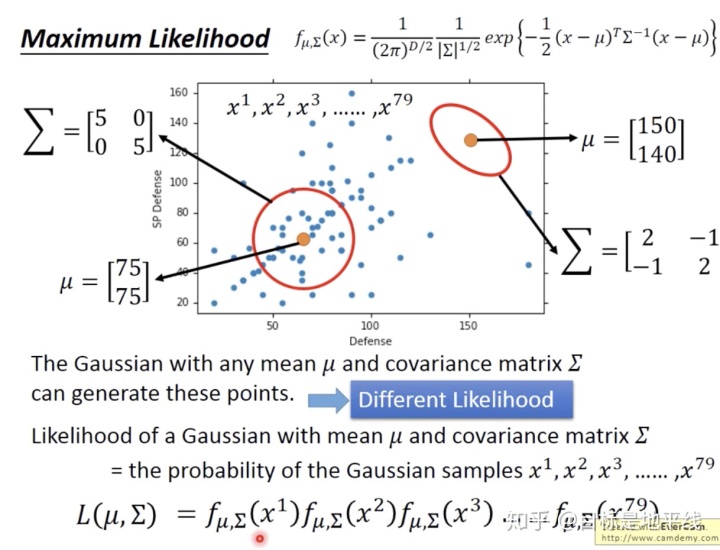
如何计算的: 
通过上面方法,宝可梦情景的两个分类问题的两个高斯分布系数就有了: 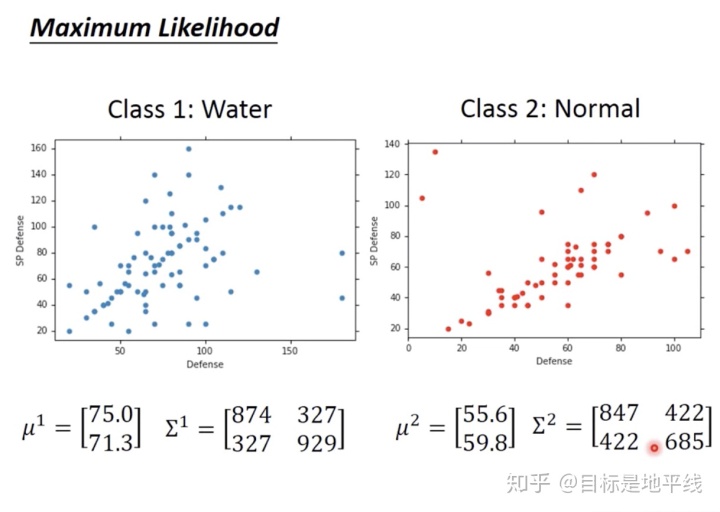
接下来概率分布的各项都生成了,就可以做分类预测了: 
老师做的结果来说,二维分的不好,但是宝可梦是7维特征可分的。 
tips: less params 
这样的技巧会让高斯分布生成linear model,但是对于7维的feature这样操作,准确率到了73%。 
几率模型范式: 
对某个x的几率,其实就是它的各个feature产生的几率之积,至于分布可以选用不同的数学分布模型: 
神奇的数学推导: 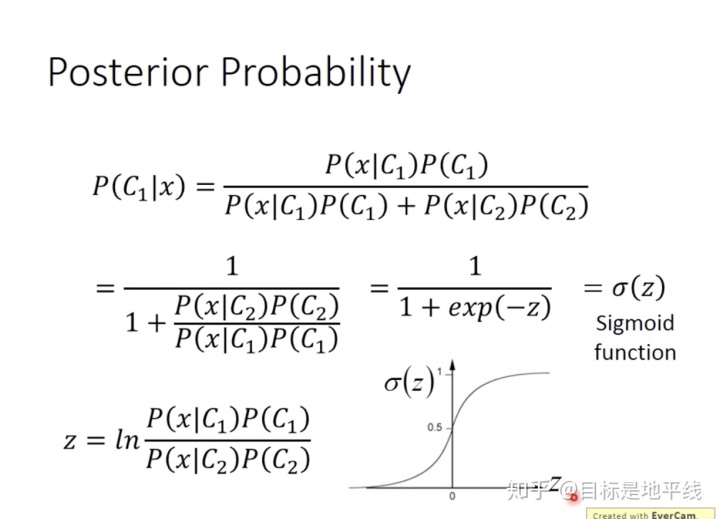
具体推到省略得到: 
上面的公式推导真是看到了数学之美,但是我们做了一大堆实际上就为了找到w,b。 |
【本文地址】