| Java分布式事务(四) | 您所在的位置:网站首页 › 事务日志文件的作用 › Java分布式事务(四) |
Java分布式事务(四)
|
文章目录
🔥MySQL事务的实现原理_什么是redo log🔥MySQL事务的实现原理_什么是undo log
🔥MySQL事务的实现原理_什么是redo log
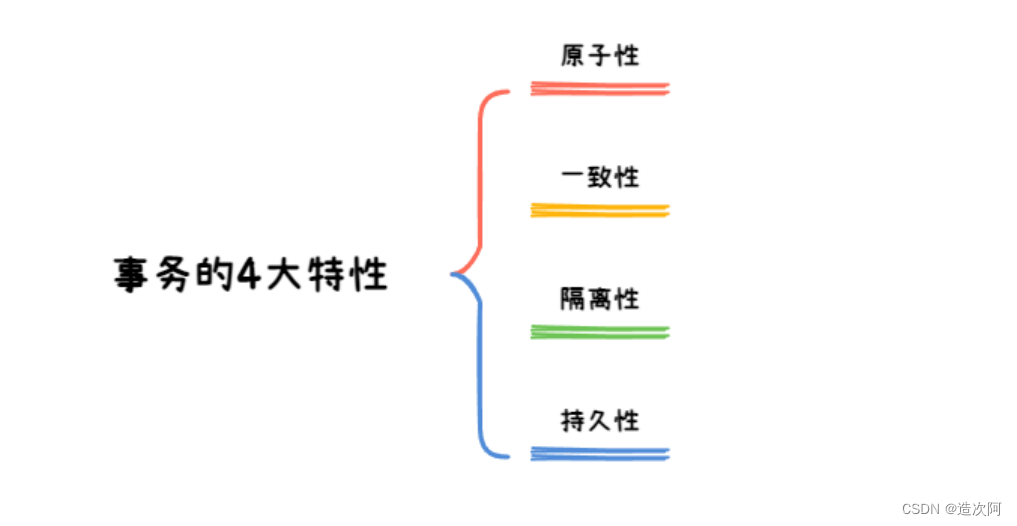
MySQL的事务实现离不开Redo Log和Undo Log。从某种程度上说,事务的隔离性是由锁和MVCC机制实现的,原子性和持久性是由Redo Log实现的,一致性是由Undo Log实现的。
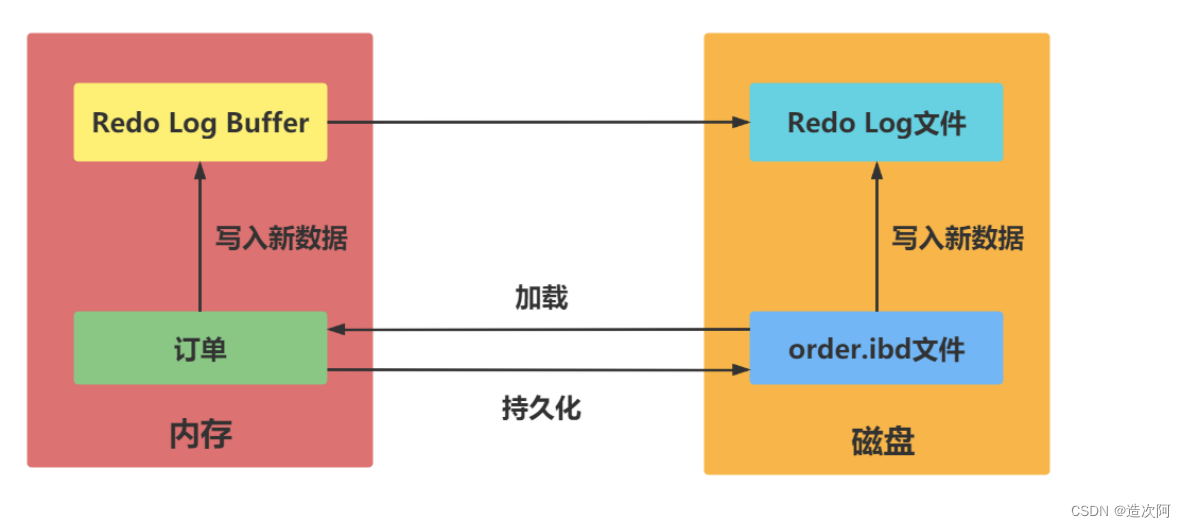
什么是redo log redo log叫做重做日志,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log),前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都会存到该日志中。 注意: 先写日志,再写磁盘的技术就是MySQL里经常说到的 WAL(Write-Ahead Logging) 技术。 Redo Log刷盘规则 在计算机操作系统中,用户空间 ( user space )下的缓冲区数据一般情况下是无法直接写入磁盘的,中间必须经过操作系统内核空间( kernel space )缓冲区( OS Buffer )。因此,redo log buffer 写入 redo log file 实际上是先写入 OS Buffer ,然后再通过系统调用 fsync() 将其刷到 redo log file 中。 innodb_flush_log_at_trx_commit。 参数值含义0(延迟写)事务提交时不会将 redo log buffer 中日志写入到 os buffer ,而是每秒写入 os buffer并调用 fsync() 写入到 redo log file 中。也就是说设置为0时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失1秒钟的数据。1(实时写,实时刷)事务每次提交都会将 redo log buffer 中的日志写入 os buffer 并调用 fsync() 刷到redo log file 中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差。2(实时写,延迟刷)每次提交都仅写入到 os buffer ,然后是每秒调用 fsync() 将 os buffer 中的日志写入到redo log file 。Redo Log刷盘最佳实践 不同的Redo Log刷盘规则,对MySQL数据库性能的影响也不同。 创建测试数据库 create database if not exists test; create table flush_disk_test( id int not null auto_increment, name varchar(20), primary key(id) )engine=InnoDB;编写存储过程 为了测试方便,这里创建一个名为insert_data的存储过程,接收一个int类型的参数。这个参数表示向flush_disk_test数据表中插入的记录行数。 drop procedure if exists insert_data; -- 该段命令是否已经结束了,mysql是否可以执行了。 delimiter $$ create procedure insert_data(i int) begin -- 声明变量 s declare s int default 1; -- 声明变量 c declare c varchar(50) default 'binghe'; -- while循环 while s call insert_data (100000); Query OK, 0 rows affected (2.18 sec)注意: 可以看到,当innodb_flush_log_at_trx_commit变量的值设置为0时,向表中插入10万条数据耗时2.18s。 第二步 将innodb_flush_log_at_trx_commit变量的值设置为1。 set global innodb_flush_log_at_trx_commit=1;调用insert_data向flush_disk_test数据表中插入10万条数据,如下所示。 mysql> call insert_data (100000); Query OK, 0 rows affected (16.18 sec)注意: 可以看到,当innodb_flush_log_at_trx_commit变量的值设置为1时,向表中插入10万条数据耗时16.18s。 第三步 将innodb_flush_log_at_trx_commit变量的值设置为2。 set global innodb_flush_log_at_trx_commit=2;调用insert_data向flush_disk_test数据表中插入10万条数据,如下所示。 mysql> call insert_data (100000); Query OK, 0 rows affected (3.05 sec)注意: 可以看到,当innodb_flush_log_at_trx_commit变量的值设置为2时,向表中插入10万条数据耗时3.05s。 总结 ⭐⭐⭐⭐⭐ 当innodb_flush_log_at_trx_commit变量的值设置为0或者2时,插入10万条数据耗费的时间差别不是很大,但是与innodb_flush_log_at_trx_commit变量的值设置为1对比来看,耗时差别较大。需要注意的是,虽然将innodb_flush_log_at_trx_commit变量的值设置为0或者2时,插入数据的性能比较高,但是在系统发生故障时,可能会丢失1s的数据,而这1s内可能会产生大量的数据。也就是说,可能会造成大量数据丢失。 🔥MySQL事务的实现原理_什么是undo log
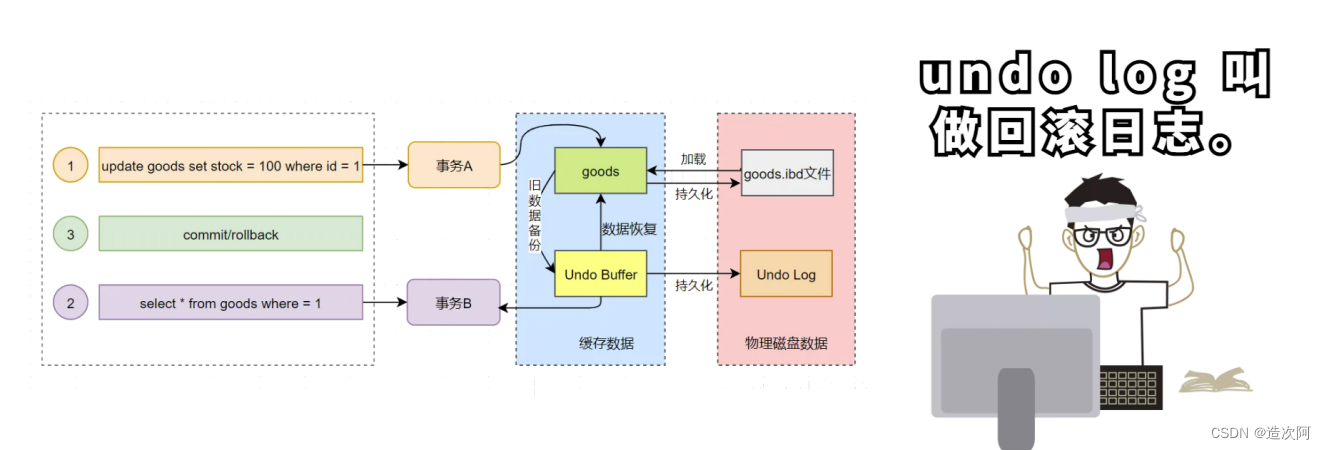
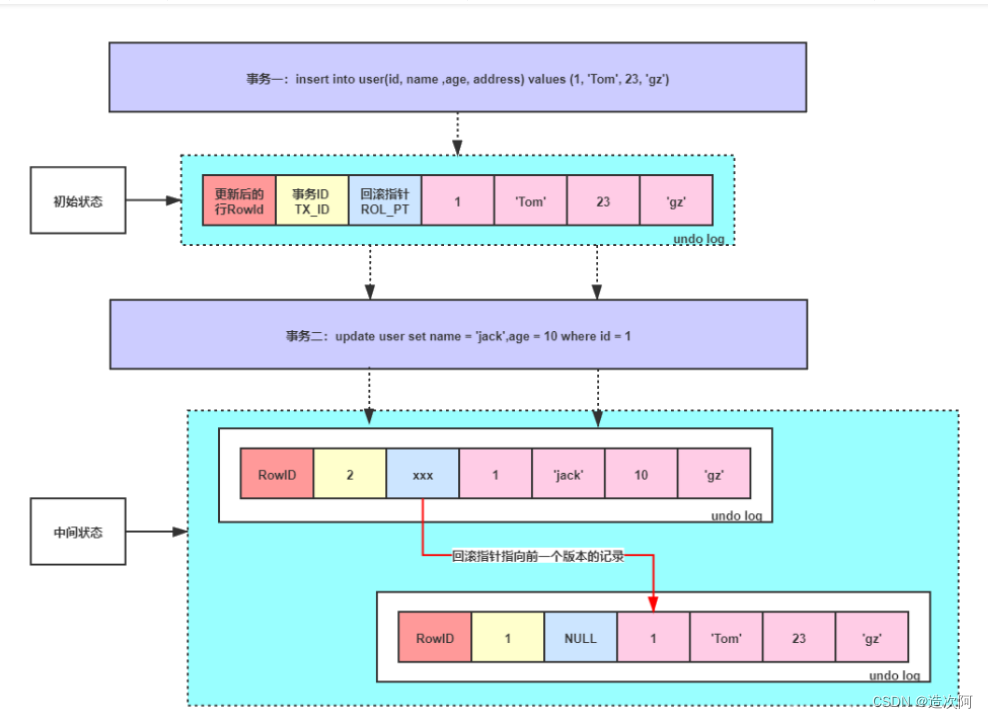
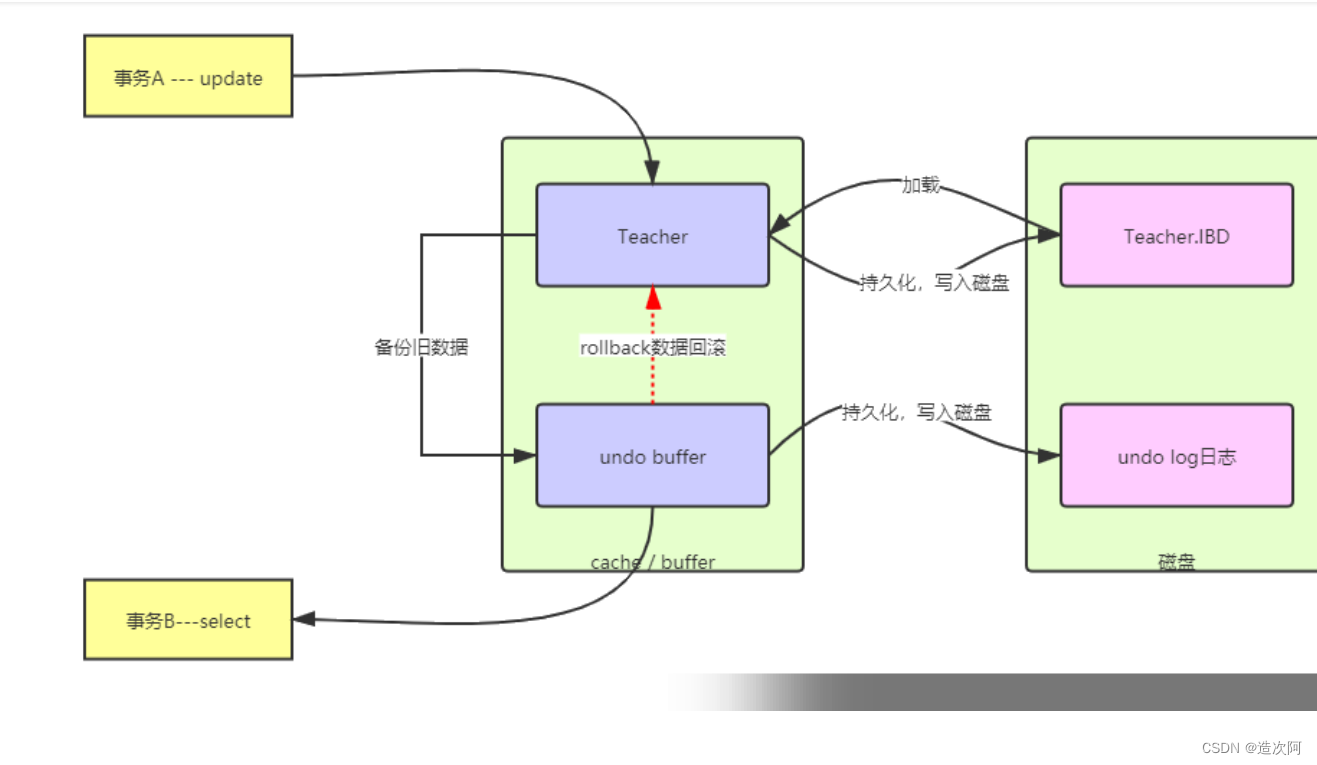
undo log的概念 undo log是mysql中比较重要的事务日志之一,顾名思义,undolog是一种用于撤销回退的日志,在事务没提交之前,MySQL会先记录更新前的数据到 undo log日志文件里面,当事务回滚时或者数据库崩溃时,可以利用 undo log来进行回退。 undo log的作用 在MySQL中,undo log日志的作用主要有两个: ⭐提供回滚操作 ---修改之前name = 张三 update user set name = "李四" where id = 1; ----此时undo log会记录一条相反的update语句,如下: update user set name = "张三" where id = 1;❗❗❗: 如果这个修改出现异常,可以使用undo log日志来实现回滚操作,以保证事务的一致性。 ⭐提供多版本控制(MVCC) MVCC,即多版本控制。在MySQL数据库InnoDB存储引擎中,用undo Log来实现多版本并发控制(MVCC)。当读取的某一行被其他事务锁定时,它可以从undo log中分析出该行记录以前的数据版本 是怎样的,从而让用户能够读取到当前事务操作之前的数据【快照读】。 快照读: SQL读取的数据是快照版本【可见版本】,也就是历史版本,不用加锁,普通的SELECT就是快照读。 当前读: SQL读取的数据是最新版本。通过锁机制来保证读取的数据无法通过其他事务进行修改UPDATE、DELETE、INSERT、SELECT… LOCK IN SHARE MODE、SELECT … FOR UPDATE都是当前 读。 undo log的存储机制 undo log的存储由InnoDB存储引擎实现,数据保存在InnoDB的数据文件中。在InnoDB存储引擎中,undo log是采用分段(segment)的方式进行存储的。 undo log的工作原理 在更新数据之前,MySQL会提前生成undo log日志,当事务提交的时候,并不会立即删除undo log,因为后面可能需要进行回滚操作,要执行回滚(rollback)操作时,从缓存中读取数据。undo log日志的删除是通过通过后台purge线程进行回收处理的。 总结 undo log是用来回滚数据的用于保障未提交事务的原子性。 |

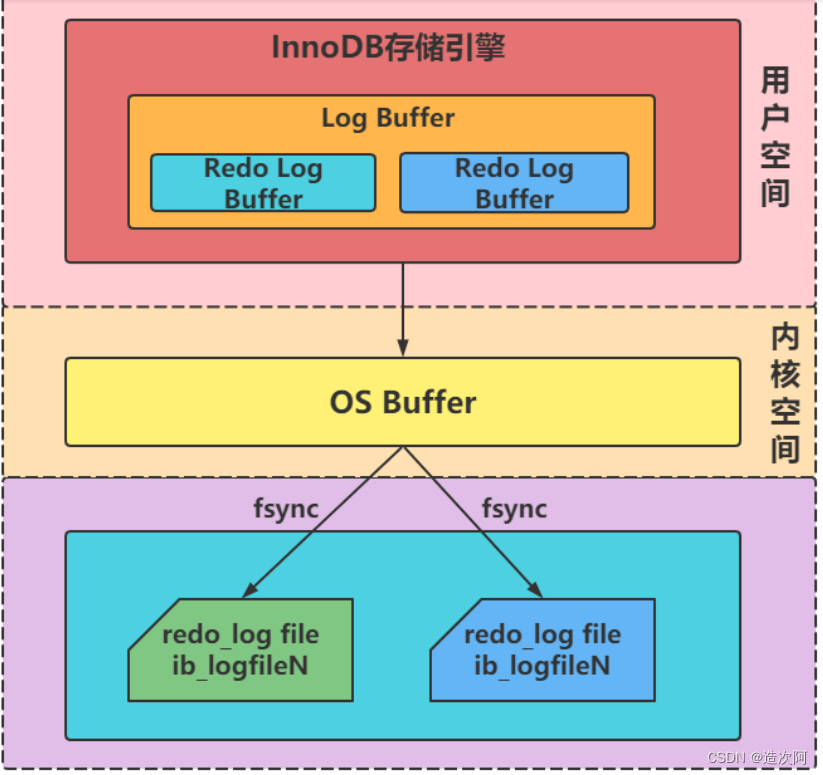 mysql 支持三种将 redo log buffer 写入 redo log file 的时机。
mysql 支持三种将 redo log buffer 写入 redo log file 的时机。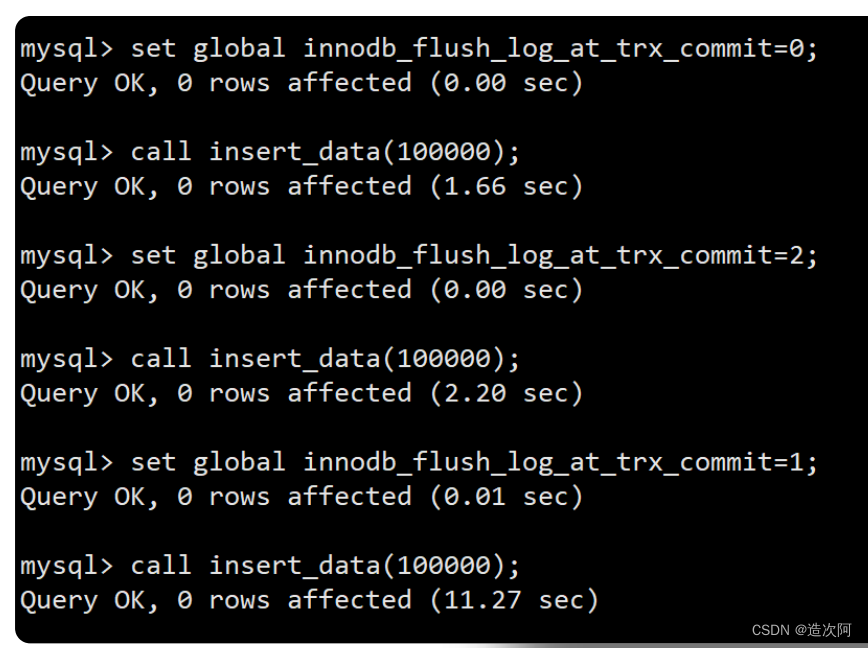
【本文地址】