| 提高效率|批量下载网页上所有的PDF文件 | 您所在的位置:网站首页 › 不用vip的听音乐软件 › 提高效率|批量下载网页上所有的PDF文件 |
提高效率|批量下载网页上所有的PDF文件
|
写在前面:最近有一个下载整理某网页上所有文件的任务,打开网页粗略估算了一下大概有上千个PDF文件需要下载并分类到不同的文件夹,如果用鼠标重复地机械劳动可能要花上一整天...于是乎,我决定尝试把这个任务交给Python来干!这里就写一篇Blog来记录一下~ 在不同网站上,下载PDF文档的链接类型有多种,其中最常见的为直接以pdf为后缀的链接,比如https://arxiv.org/pdf/2107.09939.pdf。而还有一种情况 (ps. 刚才为了找例子发现这种情况好像不是很多),链接没有pdf作为结尾,如果直接复制该链接到下载器中默认解析出来下载的不是PDF文档而是html页面,如在浏览器中复制该链接,Chrome浏览器默认打开该PDF的预览界面,需要再点击下载才可以进行手动下载。 由于第一种类型的PDF文档直接使用迅雷、FDM (巨好用,这里安利一下!!)等工具就可以很方便地下载,本人这次也是遇到了第二种类型的情况,本篇Blog就主要关注第二种类型PDF文档的批量下载。 1 使用Chrome浏览器插件Link Grabber抓取页面上的下载链接在批量下载文档之前,需要先将文档的下载链接批量获取,Chrome的Link Grabber插件可以帮上大忙。以MIT的公开课网页为例,一个课程的网页上会有很多课程Slides等PDF资料的链接。 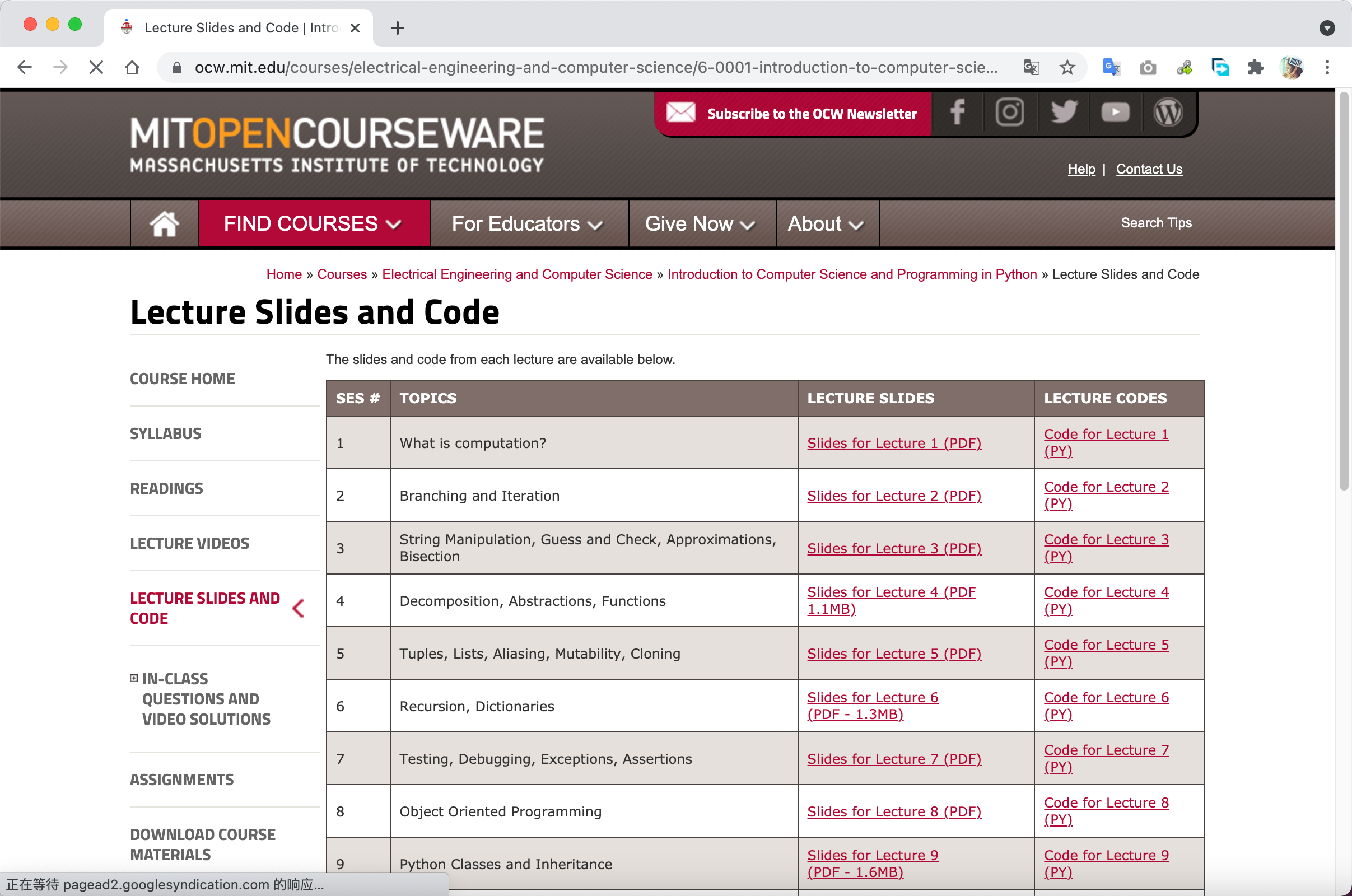
点击Link Grabber插件,可以获取该页面上的所有下载链接,这个页面上的PDF文档下载链接就是以pdf作为后缀的链接。 
由于这次任务涉及的网页不方便公开,这里就没有第二类链接的例子啦~ 使用上面的插件获取下载链接之后,复制到一个txt文本中保存,便于后面读取进行批量访问。 2 用Python实现自动打开Chrome浏览器下载PDF文档在搜索如何批量下载第二类PDF文档的结果时,发现Chrome浏览器可以设置浏览器访问该种下载链接时直接下载文档,而不是打开PDF预览界面。具体设置方法如下: 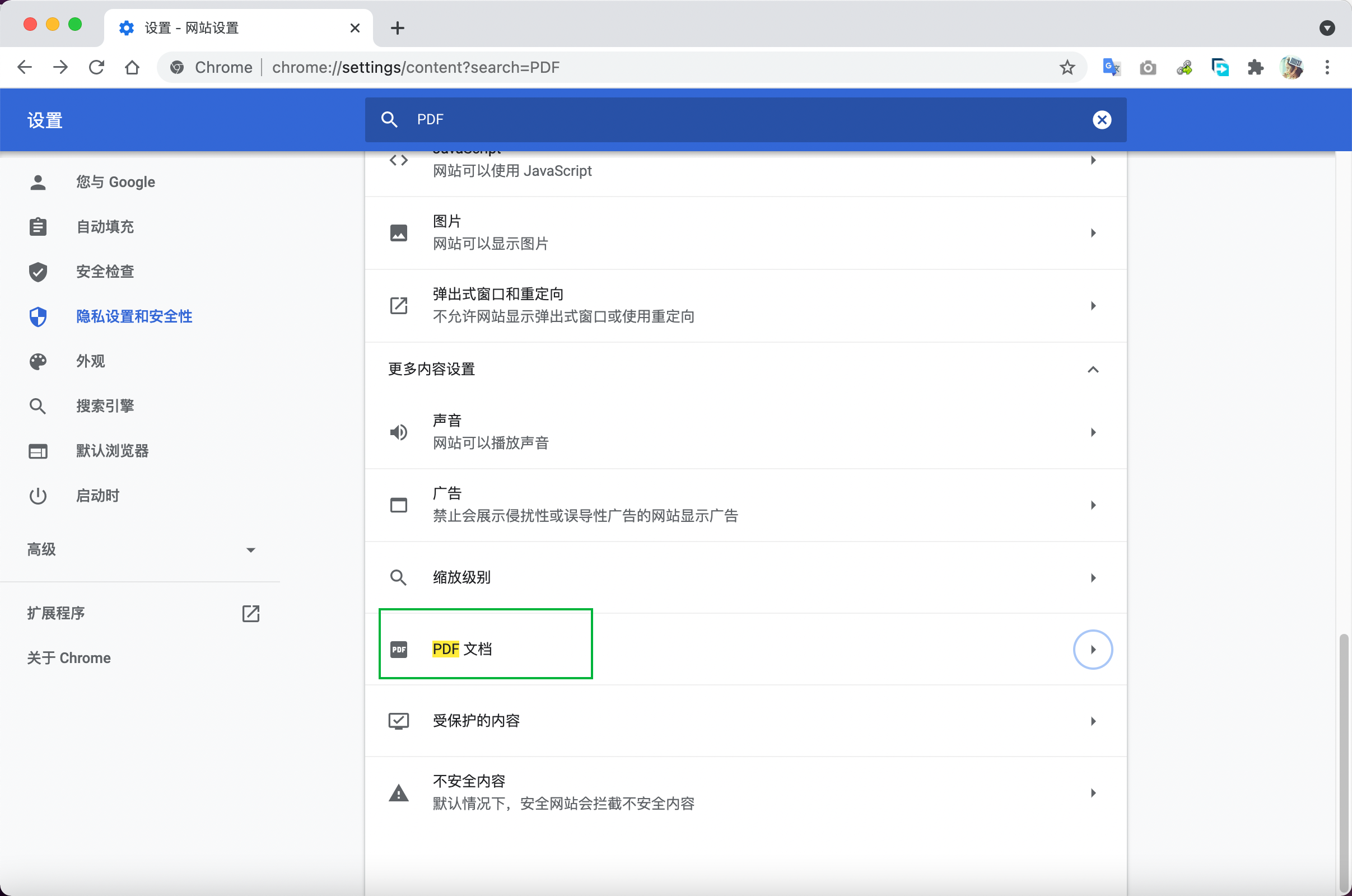
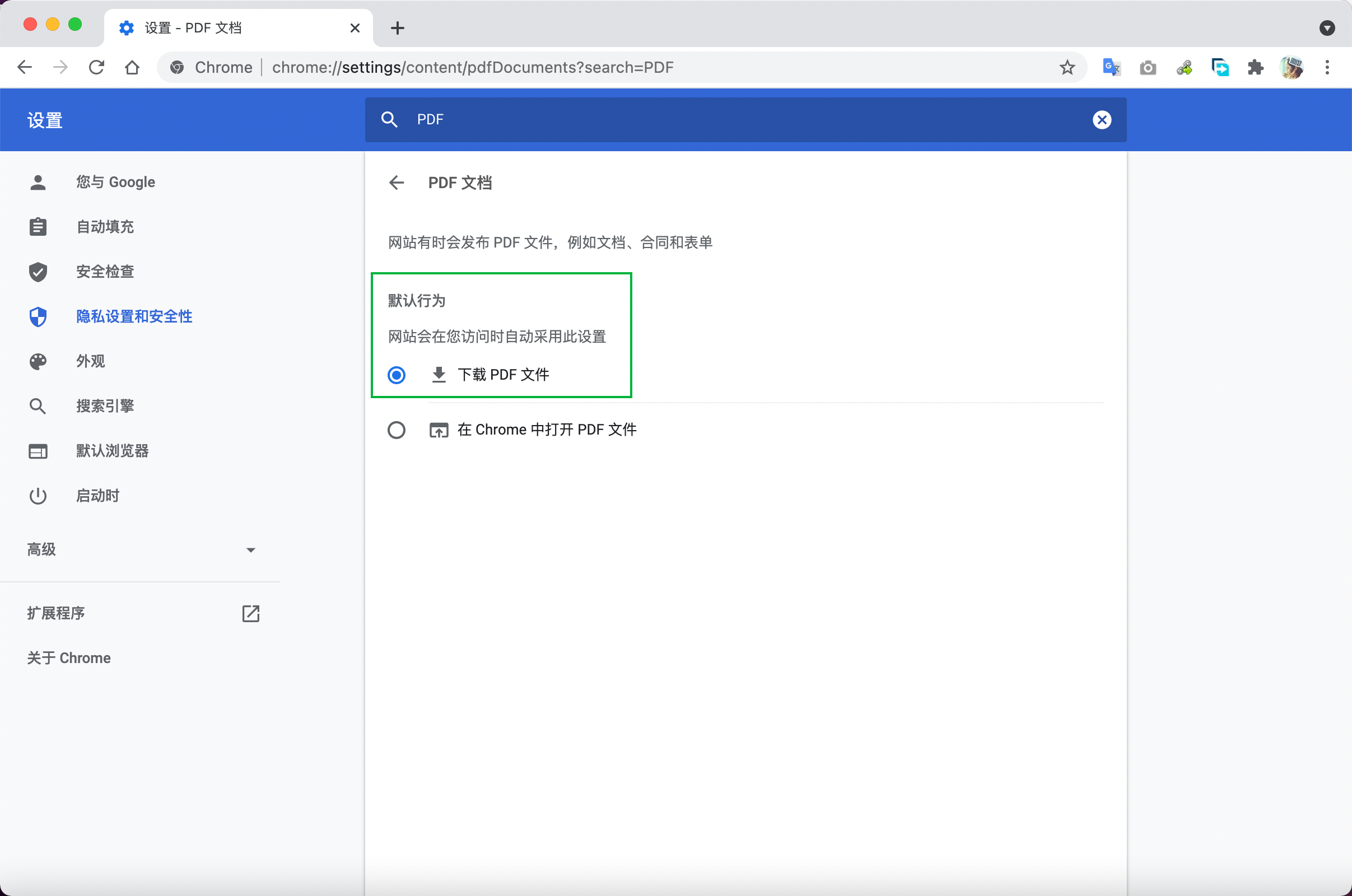
这么一来,就可以尝试用Python自动打开Chrome浏览器,访问需要下载的PDF文档的下载链接,就自动直接下载了文件!网上有很多相关博客,例如这一篇。在搜索一系列资料之后,大概摸索出来了如下的实现方案。 2.1 pip安装selenium在cmd (mac中的终端)中敲入pip安装selenium模块 pip install selenium 2.2 安装Chrome浏览器驱动chromedriver在这里下载安装对应Chrome版本的chromedriver,注意之后将下载解压的文件放在python所在的文件夹下,否则会出现这篇文章中介绍的报错。 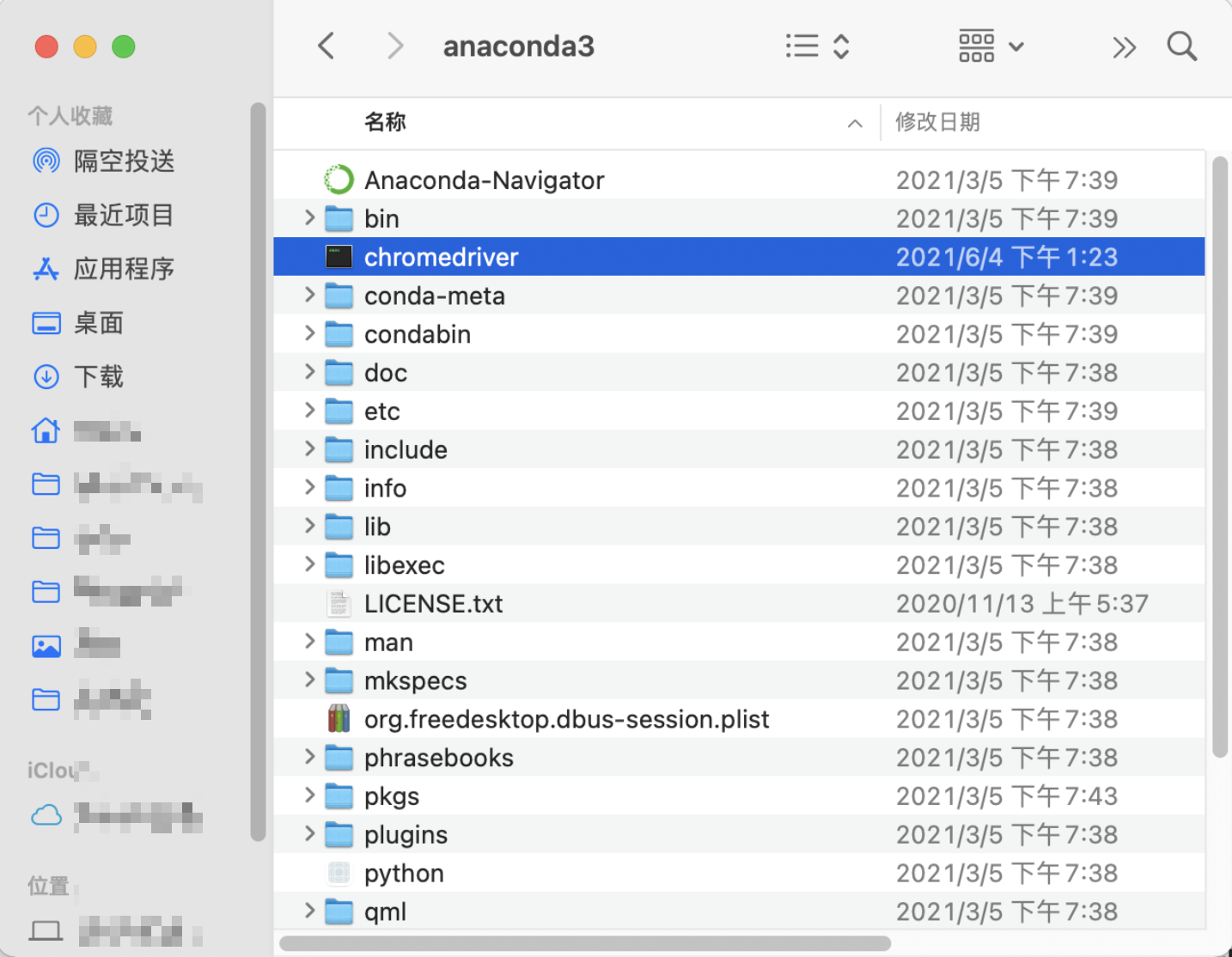 2.3 Python控制Chrome自动网页登录
2.3 Python控制Chrome自动网页登录
由于很多网页的下载链接需要首先进行用户登陆才可以进行后续访问,在Chrome自动访问下载链接之前,需要先写几行代码控制Chrome自动登录,这里参考了这篇博客(非常详细 建议收藏!!)实现。注意具体的网页需要具体分析~ 本人感觉xpath的解析方式比较好用。 2.4 设置Chrome打开链接即下载文件及下载到指定文件夹如本节开头所说,这个实现方案是通过Chrome设置打开链接即下载文件来实现的,所以需要进行相应的设置,同时参考这个页面进行了下载到指定文件夹的设置。实现的过程中发现文件夹放在桌面上可以自动下载,如果指定某个内部文件夹会弹出下载弹窗。 3 主要代码块主要的代码总结如下,根据个人下载和整理文件的需求可以进行相应的扩展,比如将不同类的下载链接保存到不同的URL.txt中,利用for循环多次下载,通过拼接文件名自动将文档下载到对应的新文件夹中。 from os import name from selenium import webdriver import time # 设置谷歌浏览器打开pdf链接时自动下载到指定文件夹 options = webdriver.chrome.options.Options() download_dir = "/Users/whale/Desktop/Download_PDF" # 这里是自定义的下载文件夹地址 options.add_experimental_option('prefs', { "download.default_directory": download_dir, "download.prompt_for_download": False, "download.directory_upgrade": True, "plugins.always_open_pdf_externally": True } ) path = "/Users/whale/opt/anaconda3/chromedriver" driver = webdriver.Chrome(path,options=options) # 登陆网页,注意代码因页面而异 driver.get('https://MainPage/login.com') # 设置登录页面的网址 driver.find_element_by_name("username").send_keys('Whale') driver.find_elements_by_id('password')[0].send_keys('Whale\'s password') driver.find_element_by_xpath('//*[@id="form1"]/table/tbody/tr/td/table/tbody/tr[4]/td/input[1]').click() # 模拟点击登陆按钮 # 读取URL文件并保存到url_list中 url_list = [] f = open("URL.txt","r") lines = f.readlines() for line in lines: url_list.append(line) # 逐个访问下载链接,开始自动下载,最后关闭浏览器 for url in url_list: driver.get(url) time.sleep(5) time.sleep(100) #注意设置浏览器停留时间,一些较大的PDF下载时间较长,需增大等待时间 driver.close()写在最后:总的来说虽然上面这个实现方案没有实现完全的自动化(需要手动复制+保存下载链接),但已经极大程度地提高了我的工作效率!上述方案还不能很好地解决文件命名的问题,这里就留一个坑,有机会再想一下如何解决~ 参考资料 使用selenium模块访问谷歌浏览器指定页面: https://www.cnblogs.com/liugx/p/9739639.html webdriver打开谷歌浏览器报错: https://blog.csdn.net/cckavin/article/details/79514790 使用python + selenium实现浏览器自动登录: https://www.jianshu.com/p/d7a966ec1189 python逐行读取文件内容的三种方法: https://blog.csdn.net/fevershen/article/details/81296404 设置python调用谷歌浏览器下载到指定文件夹 https://www.5axxw.com/questions/content/ptip33 |
【本文地址】