| 关于源文件用不同的编码方式编写,会导致执行结果不一样的现象及解决方法 | 您所在的位置:网站首页 › 不同的进程所执行的程序代码一定不同吗 › 关于源文件用不同的编码方式编写,会导致执行结果不一样的现象及解决方法 |
关于源文件用不同的编码方式编写,会导致执行结果不一样的现象及解决方法
|
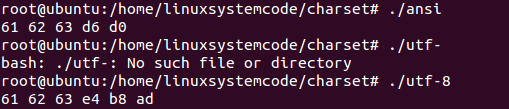
如果我们编写以下程序,并分别另存为ANSI和UTF-8两种不同的编码方式保存,放到Linux下编译并运行如下图,两端相同的程序以不同的编码方式保存编译后的运行结果不一样,./ansi采用ANSI编码方式,会自动采用GBK方式来保存中文汉字“中”(“中”的GBK编码就是d6 d0,utf-8则是e4 b8 ad),那么我们有没有什么办法能够解决不同编码方式保存才来的执行结果不同的问题呢 #include int main(int argc, char **argv) { int i = 0; unsigned char *str="abc中"; while (str[i]) { printf("%02x ", str[i]); i++; } printf("\n"); return 0; }
怎么解决?编译程序时,要指定字符集 我们通过man gcc ,并以/charset查找可以知道,我们可以在编译程序的时候指定编码方式如下 -finput-charset=charset 表示源文件的编码方式, 默认以UTF-8来解析 -fexec-charset=charset 表示可执行程序里的字时候以什么编码方式来表示,默认是UTF-8
gcc -finput-charset=GBK -fexec-charset=UTF-8 -o utf-8_2 ansi.c 指定源文件的编码方式为GBK(GBK兼容ansiic码的,因为ansiic码很少,只有200多个) 指定可执行程序里的字时候以UTF-8编码方式来表示,结果如下图,我们成功地解决了这个编码问题。
如果我们没有指定,源文件的编码方式, 默认以UTF-8来解析,可执行程序里的字默认也是UTF-8,那么我们之前编译第一个程序./ansi的时候,ansi.c的编码方式是ANSI,而我们默认采用UTF-8为什么没有报错呢,这只能说gcc编译器没有那么的伟大,自动识别出来(毕竟不是专门做字符的编码处理的),需要我们手动地指定才能够得出正确结果。 |



【本文地址】
公司简介
联系我们