| 深度估计到底有多重要?如何应用到单目3D目标检测和跟踪中? | 您所在的位置:网站首页 › 三维目标有什么作用呢 › 深度估计到底有多重要?如何应用到单目3D目标检测和跟踪中? |
深度估计到底有多重要?如何应用到单目3D目标检测和跟踪中?
|
作者 | 黄浴 编辑 | 汽车人 原文链接:https://zhuanlan.zhihu.com/p/527290019 点击下方卡片,关注“自动驾驶之心”公众号 ADAS巨卷干货,即可获取 点击进入→自动驾驶之心【深度估计】技术交流群 后台回复【深度估计综述】获取单目、双目深度估计等近5年内所有综述! arXiv2022年6月8号上传的论文“Depth Estimation Matters Most: Improving Per-Object Depth Estimation for Monocular 3D Detection and Tracking“,作者来自谷歌WayMo公司、Johns-Hopkins大学和Cornell大学。 
近年来,基于单目图像的3D感知技术在自动驾驶的应用非常活跃。然而,与基于激光雷达的技术相比,包括检测和跟踪在内,单目3D感知方法的性能往往较差。通过系统分析,发现每个目标的深度估计精度是影响性能的主要因素。基于这一观察结果,提出一种多层融合方法,该方法将目标不同的表征(RGB和伪激光雷达)和时域多帧信息(tracklet)相结合,以增强每个目标的深度估计。 该融合方法在Waymo开放数据集、KITTI检测数据集和KITTI MOT数据集上实现了每目标深度估计的最好性能。简单地将估计深度替换为融合增强深度,可以显著改善单目3D感知任务,包括检测和跟踪。 现有的自动驾驶车辆感知系统主要依赖于昂贵的传感器,如激光雷达和雷达。由于摄像机的低成本、低功耗和更长的感知范围,单目图像感知近年来吸引了业界和研究界的极大兴趣。这种感知任务往往具有挑战性,单目感知系统与基于激光雷达/雷达的系统之间存在很大的性能差距。 常见的3D单目感知系统包括两个主要模块:3D目标检测和3D跟踪。前者需要学习目标的3D位置、长方体大小和旋转/朝向,而后者需要使用外观和运动线索跨帧跟踪检测。在这两项任务中,不清楚系统的哪个组件对性能有最关键的影响。为了充分了解哪个组件限制了总体性能,用真值替换最先进检测模型的每个输出,然后用最先进的检测器评估检测和tracking-by-detection性能的变化。 如图所示,在图像中包括旋转、大小、深度和非模态中心在内的所有属性中,发现只有每个目标的深度,即车辆3D中心的深度,才起作用(请参见每个目标深度估计完美时的显著性能改进,以及其他信号完美时的非主体改进)。基于这一观察,单目标深度估计是单目3D检测和检测跟踪的主要瓶颈。对其他最先进的检测器进行相同的分析,例如带AB3D跟踪器的RTM3D框架,结果表明,深度是改善单目3D检测的关键因素,跟踪是横穿模型的总结论。 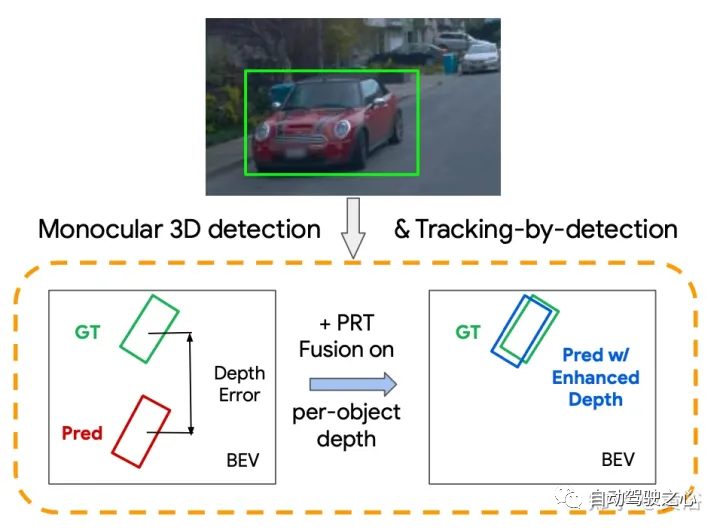
从单目图像估计物体深度的一个主要挑战是获得一个表征,对从2D信息到3D深度的转换进行编码。最近的工作(例如,3D单目检测)主要集中于直接从原始RGB图像学习,或利用从预测的密集深度图中提取伪激光雷达表征。 直觉上,上述两种表示法在估计每个目标的深度方面可能是互补的,单独从其中任何一种学习都可能是次优的:RGB图像实际上编码了外观、纹理和2D几何等,但不包含3D直接信息,在不过拟合无关信息的情况下,很难学习如何将RGB特征精确映射到深度;另一方面,伪激光雷达表征通过估计的密集深度图直接建模目标三维结构,这使得学习每个目标的深度变得简单,然而估计的密集深度图通常是有噪声的(通常具有至少8%的平均相对误差)。 受先前的融合(如RGB图像特征和用于动作识别的光流)方法启发,融合在两种表征中编码的互补信号可能有助于每个目标的深度估计。 此外,单目图像的深度估计基本上是不适定问题,因为场景的单个2D视图可以由许多看似合理的3D场景来解释。然而,随时间推移,观察一个目标可以对目标的基本时间和运动一致性进行建模,能提供上下文信息,以便在3D中更好地定位目标。在其他任务中也有类似的想法,如基于2D视频的目标检测。 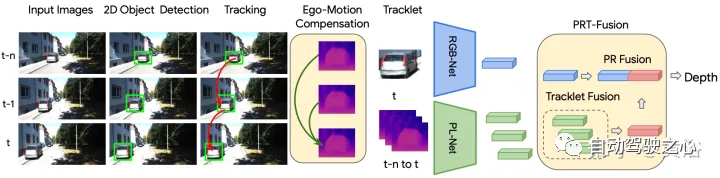
上图显示用于逐目标深度估计的多级融合框架概述:首先进行二维目标检测和跨帧跟踪检测,为每个目标构建一个tracklet;然后,构建跨帧目标的伪激光雷达表示,以及当前帧的RGB图像特征;自运动补偿应用于每个tracklet的所有伪激光雷达patch,并转换到相同的坐标系;最后,对当前帧的RGB图像特征和时间融合的伪激光雷达特征进行融合,以产生逐个目标深度。 PR-融合,利用RGB和伪激光雷达表示编码的互补信息。给定一幅大小为H×W的RGB图像I,使用预训练的卷积神经网络FRGB可以提取整个图像的紧凑特征。对于具有2D边框b的任何目标,用预定义的池化操作池(FRGB(I),b)提取边框的RGB图像特征R。从图像I中提取目标边框b的图像特征R的过程可以表示为 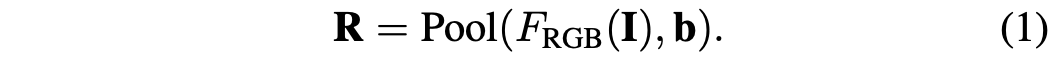
伪激光雷达表示的提取过程包括三个步骤:(1)每个图像的密集深度估计,(2)提升预测的密集深度到伪激光雷达,(3)用神经网络提取伪激光雷达表示。对于任何RGB图像I,深度估计可以通过使用密集深度估计网络Fd完成 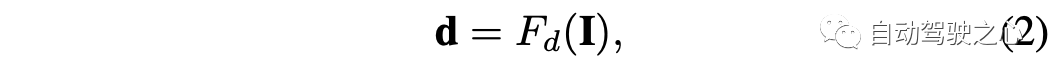
然后,用以下基于摄像头模型将整个深度图的每个像素提升到点云: 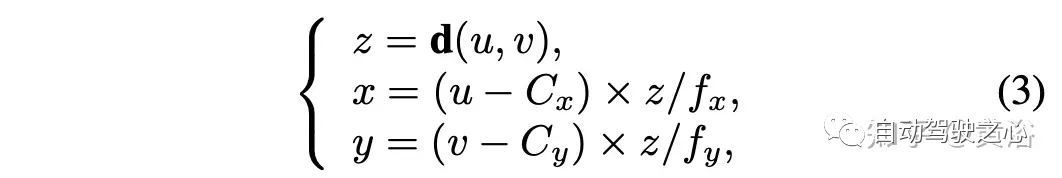
在变换之后,密集深度图d中的每个像素被变换为三个通道,表示在摄像头坐标中对应像素在3D空间的绝对位置。 在获得图像I的伪激光雷达表示后,可以基于2D边框对时间戳t的目标bt伪激光雷达patch Pt进行裁剪,其中Pt是框bt内的伪激光雷达点集。可以用另一个特征编码器Fp提取目标bt的伪激光雷达特征PL,如 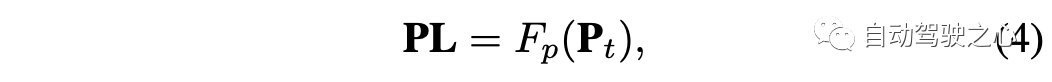
PR-融合则表示为 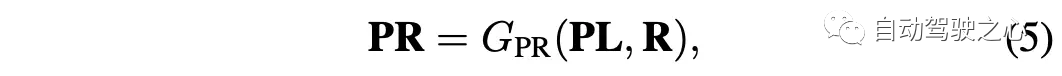
直接从单个帧预测每个目标的深度很有挑战性,因为摄像头图像中的单个目标可以由具有不同深度的多个看似合理的目标来解释。受视频任务的时间融合方法启发,提出跨多帧融合目标级信息,增强预测的时间和运动一致性。给定2D检测结果,首先进行2D数据关联,为目标构建tracklet,然后在时间窗口融合tracklet的特征。 一种简单的方法是直接跨帧融合图像特征,然而直接融合不同帧的RGB特征可能不太理想,因为RGB特征将摄像头自运动和目标运动耦合在一起,很难从2D图像序列中学习运动和时间一致性。为了对深度估计进行有效的时间融合,必须对摄像机运动进行补偿,以确保不同帧的特征位于同一坐标系中。幸运的是,摄像头的自运动可以通过伪激光雷达表示在3D空间中轻松补偿。因此,提出一种基于伪激光雷达表示带自运动补偿的T-融合法。 T-融合的输入包括在不同帧Pt, Pt−1 , ..., Pt−n中每个目标的伪激光雷达patch,而Pt位于t帧的三维摄像头坐标中。自运动用基于传统六自由度的4×4齐次矩阵H表示:平移[γx,γy,γz]以米为单位,旋转[ρx,ρy,ρz]以弧度为单位。 首先,用摄像头坐标到全局坐标的转换矩阵H,将来自不同帧的所有伪激光雷达patch投影到全局坐标系中。假设摄像头坐标到全局坐标的变换矩阵为Ht−j,对于任何时间戳Pt-j的伪激光雷达patch,转换如下: 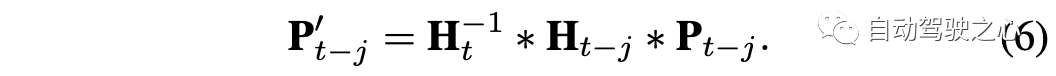
坐标变换后,自动驾驶汽车的自运动得到补偿,变换后的Pt′−j与Pt在同一坐标系中。将相同的变换应用于所有时间戳的伪激光雷达patch,消除自运动对每个目标的伪激光雷达点位置造成的影响。 给定伪激光雷达的任何特征编码器Fp(),数据中不同时间戳的特征可以提取为Fp(P′t),Fp(P′t−1 ), ..., Fp(P′t−n),其中′表示伪激光雷达patch做自运动补偿。然后,可以用神经网络编码器GTF对目标序列的融合特征进行建模,如下所示: 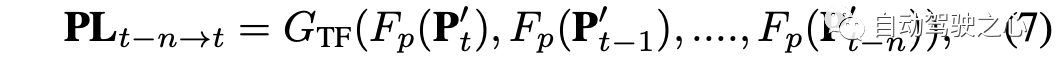
PR-融合和T-融合聚合了两个不同领域的特征。将这两种融合方法结合在一起进一步提高性能是很自然的。给定一系列跨时间的目标框,bt,bt−1, ...., bt−n,目标bi的RGB图像特征可以用图像特征编码器FRGB()表示,其伪激光雷达特征可以用编码器Fp()提取。PRT-融合分为两个步骤:给定当前帧的目标及其前一帧的目标,首先对多帧的伪激光雷达表示进行带自运动补偿的T-融合;然后将其与当前帧t的RGB特征融合为 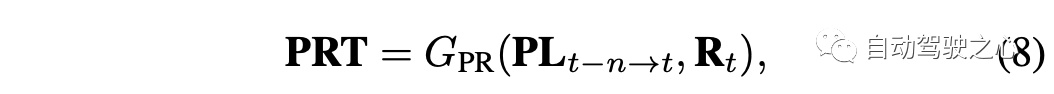
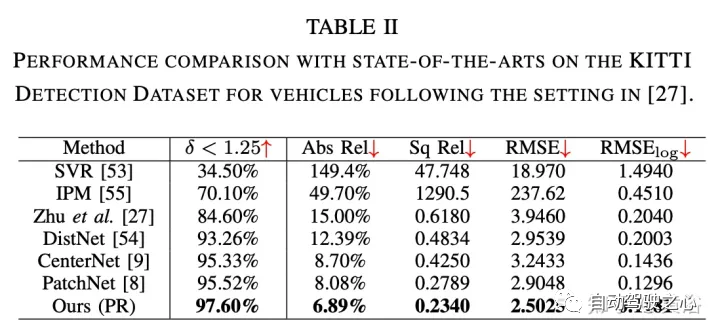
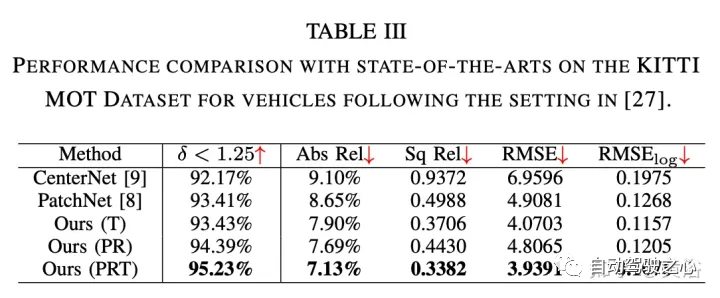
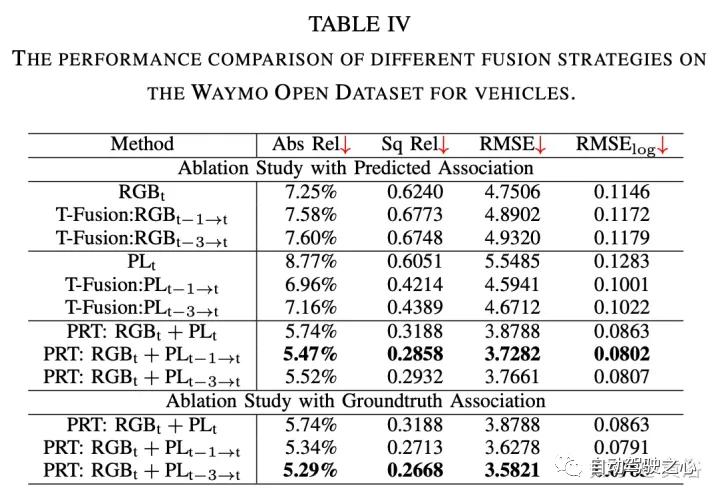
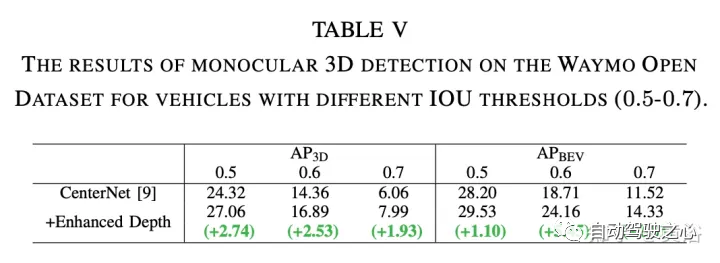
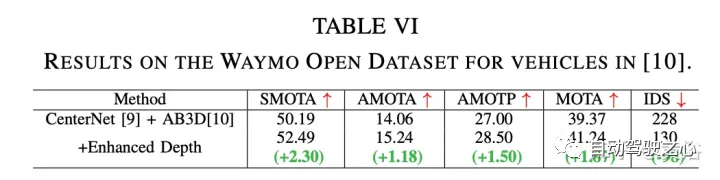
RGB特征提取采用CenterNet和CenterTrack,它们最近在nuScenes数据集上的单目3D检测任务上取得了最先进的性能。遵循其公式和网络架构,以ResNet50为骨干进行2D检测。 伪激光雷达特征提取采用PatchNet,其最近显著提高基于伪激光雷达的检测性能。选择它作为主干模型来提取基于伪激光雷达的特征,其作为基线和该方法的输入。 为了跟踪2D检测形成tracklet,用基于卡尔曼滤波器的跟踪器。 实验结果如下: 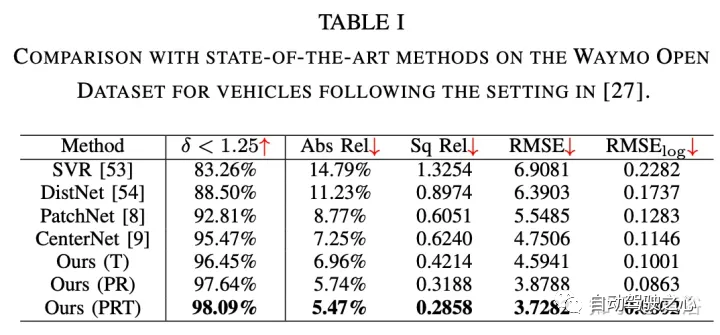
如图所示:绿色、红色和蓝色边框对应于GT、基线深度估计和检测(BL),以及PRT-融合中具有增强逐目标深度的边框。可以观察到明显更好的深度估计及其在检测方面的进一步改进。 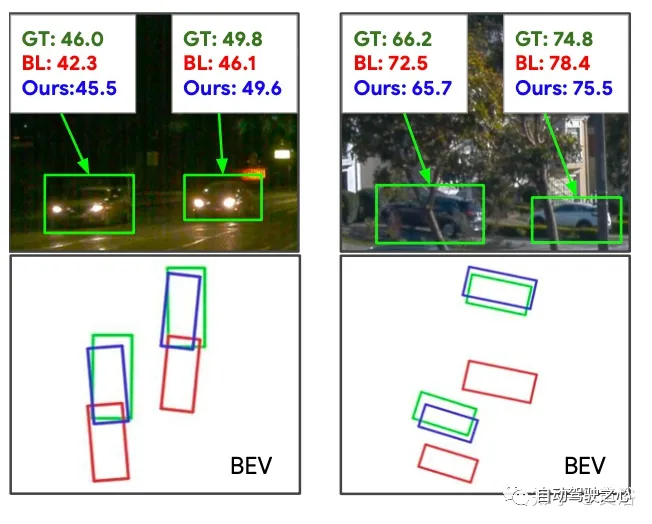
如图所示:由于(a)中显示的深度估计不准确,3D跟踪器错误地关联了帧间的检测,从而导致ID切换。根据(b)中提出的融合模型预测的增强深度,跟踪器可以正确地关联检测。 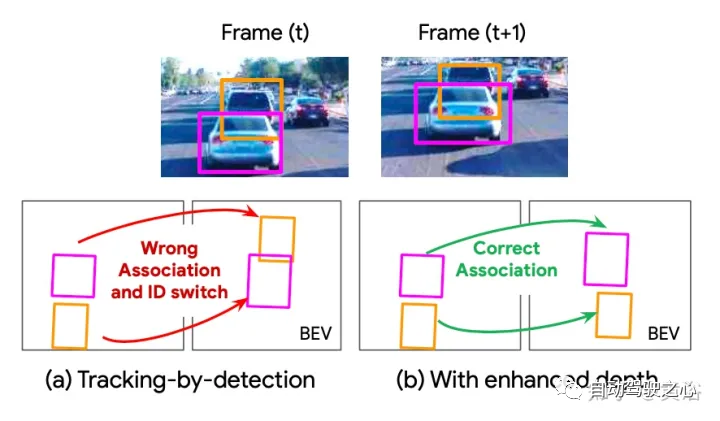
(一)视频课程来了! 自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、多传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)
(扫码学习最新视频) 视频官网:www.zdjszx.com (二)国内首个自动驾驶学习社区 近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!
(三)【自动驾驶之心】全栈技术交流群 自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;
添加汽车人助理微信邀请入群 备注:学校/公司+方向+昵称 |



【本文地址】