| 【机器学习基础】一元线性回归(适合初学者的保姆级文章) | 您所在的位置:网站首页 › 一元回归分析与多元回归分析的主要区别是 › 【机器学习基础】一元线性回归(适合初学者的保姆级文章) |
【机器学习基础】一元线性回归(适合初学者的保姆级文章)
|
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!后面的内容会越来越有意思~ 💡往期推荐: 【机器学习基础】机器学习入门(1) 【机器学习基础】机器学习入门(2) 【机器学习基础】机器学习的基本术语 【机器学习基础】机器学习的模型评估(评估方法及性能度量原理及主要公式) 💡本期内容:本篇文章开始机器学习的模型,我们从最简单的开始,所以从线性的开始,而线性模型中一元的最简单,最基础,所以先讲解一下一元线性回归~超级基础的文章,赶紧收藏学习吧!!! 文章目录 1 线性模型2 一元线性回归2.1 引例及模型表示2.2 代价函数(Cost function) 3 一元梯度下降求参数3.1 代价函数的简化3.2 二元的代价函数3.3 梯度下降3.3.1 理解梯度下降3.3.2 利用梯度下降求解线性回归 1 线性模型给定由d个属性描述的示例x,其中xi是x在第i个属性上的取值,线性模型(linear model)试图学得一个通过属性的线性组合来进行预测的函数,即 一元线性回归是一种统计分析方法,用于建立一个自变量和一个因变量之间的线性关系模型。在一元线性回归中,只有一个自变量(即解释变量)与一个因变量(即被解释变量)相关。 该模型的目标是找到一个最佳拟合直线,使得该直线能够最好地拟合已知的数据点并预测未知的数据点。最常用的评估拟合程度的指标是最小二乘法,它通过最小化观测值与拟合直线的差距的平方和来确定最佳拟合直线。 一元线性回归的模型可以表示为:Y = β₀ + β₁X + ε 其中,Y 是因变量,X 是自变量,β₀ 和 β₁ 是模型的系数,ε 是随机误差项。 通过一元线性回归,我们可以估计自变量和因变量之间的关系,并进行预测和推断。 以上是官方解释,看不懂没事,我们来举一个经典的例子: 2.1 引例及模型表示这个例子是关于预测房屋价格的,我们已知这样一个数据集: 你可以构建一个模型,比如拟合一条直线,如上图所示。从这个模型来看,也许你可以告诉你的朋友,他可以以大约220000(美元)左右的价格卖掉这个房子。这其实就是一个回归问题的例子! ℎ是一个函数,也是模型,代表的是从输入到输出的一个映射。这里输入是房屋尺寸大小,输出是房屋的价格。 回到例子中,我们需要借助h来预测房价。实际上 ,我们是要将训练集(已知的部分数据)“喂”给我们的学习算法,进而学习得到一个函数ℎ,然后将我们要预测的房屋的尺寸作为输入变量输入给ℎ,预测出该房屋的交易价格作为输出变量输出为结果。这个过程类似于在中学学到的求解直线方程,只是需要多次迭代。 那这个迭代过程究竟跟我们中学阶段的求解有什么区别呢?这里就要引出下面这个概念: 2.2 代价函数(Cost function)对于一元线性函数,每一对参数都可以得到一种曲线的画法
如何求解代价函数呢?我们通常使用梯度下降的方法。 3.1 代价函数的简化我们先理解含有一个参数的代价函数。 上面是之含有一个参数的代价函数,这里我们把另一个参数加上去,看看怎么求解: 多了一个参数相当于多了一个维度,图像也由一开始的二维拓展到了三维。求代价函数的最小值仍然是我们的目标。 可是要遍历的点太多了,我们怎么知道哪里是最小的点呢?下面介绍求代价函数最小值的方法:梯度下降 3.3 梯度下降梯度下降是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)。在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降是最常采用的方法之一。 3.3.1 理解梯度下降举个例子,梯度下降法就是从山顶找一条最短的路走到山谷最低的地方。在这个过程中,每次都会沿着当前点的梯度方向(即函数在该点的斜率)走一步,逐步向最低点靠近。在机器学习中,基于基本的梯度下降法发展了两种梯度下降方法,分别为随机梯度下降法和批量梯度下降法。 接下来我们让梯度下降与线性回归相结合(关键在于对代价函数求偏导): 其主要思想如下: 公式的推导:
|
 一般用向量形式写成
一般用向量形式写成 w和b学得之后,模型就得以确定
w和b学得之后,模型就得以确定 横坐标表示房屋的面积,纵坐标表示房屋的价格。我们的目标是预测在给定房屋面积的情况下,房屋的价格是多少。例如,如果你的朋友的房子是1250平方英尺大小,你可以使用上面的数据集来预测其可能售价。那么,我们应该如何进行预测呢?
横坐标表示房屋的面积,纵坐标表示房屋的价格。我们的目标是预测在给定房屋面积的情况下,房屋的价格是多少。例如,如果你的朋友的房子是1250平方英尺大小,你可以使用上面的数据集来预测其可能售价。那么,我们应该如何进行预测呢? Notation:
Notation: 在一元线性回归模型中如何表示h呢?
在一元线性回归模型中如何表示h呢?  这里表示的就是单变量(一元)线性回归,其图像描述如下图所示:
这里表示的就是单变量(一元)线性回归,其图像描述如下图所示: 
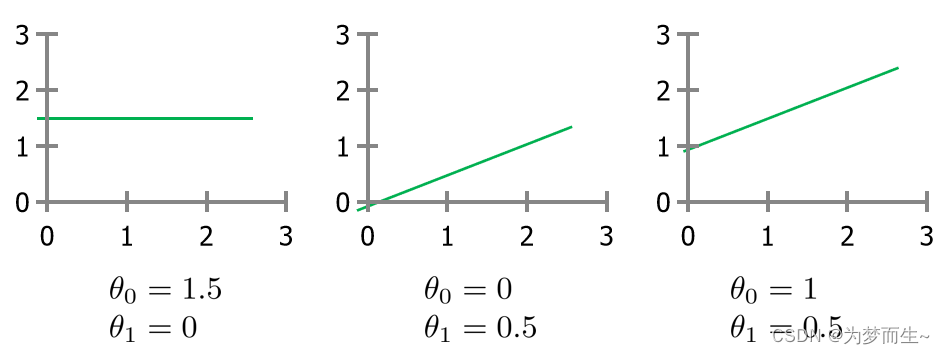 那么哪一种是最适合的呢?我们用假设函数来表示我们预测结果的模型。那么,这个模型好还是不好呢?我们需要有一个判别标准,这个标准就叫作代价函数。其表示形式如下:
那么哪一种是最适合的呢?我们用假设函数来表示我们预测结果的模型。那么,这个模型好还是不好呢?我们需要有一个判别标准,这个标准就叫作代价函数。其表示形式如下: 对于代价函数的解释:
对于代价函数的解释: 那么我们现在的问题就转化为了如何利用训练集最小化代价函数
那么我们现在的问题就转化为了如何利用训练集最小化代价函数 下面是当 𝜃1 = 1时的代价函数与假设函数
下面是当 𝜃1 = 1时的代价函数与假设函数  下面是 𝜃1 = 0.5时的曲线
下面是 𝜃1 = 0.5时的曲线  下面做出 𝜃1 = 0 时的曲线并把代价函数所有的点连起来
下面做出 𝜃1 = 0 时的曲线并把代价函数所有的点连起来 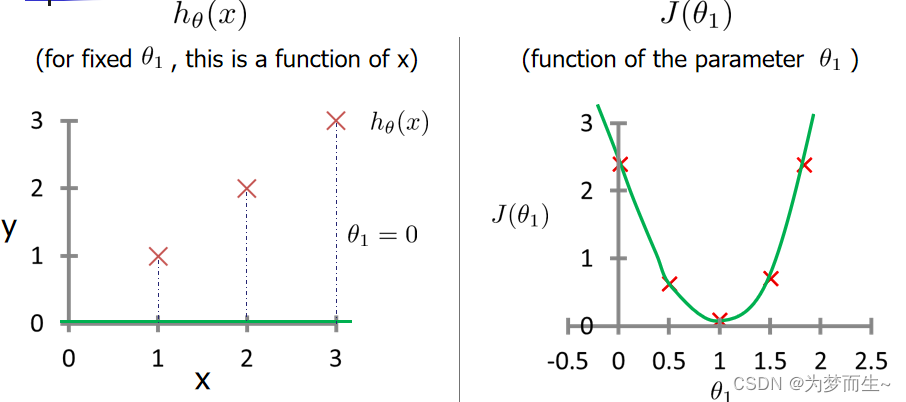 由图像我们可以知道,当J(
θ
1
\theta _{1}
θ1)取最小值时的参数所对应的假设函数是拟合数据最好的直线。
由图像我们可以知道,当J(
θ
1
\theta _{1}
θ1)取最小值时的参数所对应的假设函数是拟合数据最好的直线。 再利用上面的方法,尝试每一个特殊的点,得到代价函数在坐标系中的位置后将他们连起来,我们就得到了一个二元代价函数,它是一个三维图形
再利用上面的方法,尝试每一个特殊的点,得到代价函数在坐标系中的位置后将他们连起来,我们就得到了一个二元代价函数,它是一个三维图形  同样利用上面的方法,遍历每一个参数
θ
0
\theta _{0}
θ0,
θ
1
\theta _{1}
θ1,找到使得代价函数最小的参数。
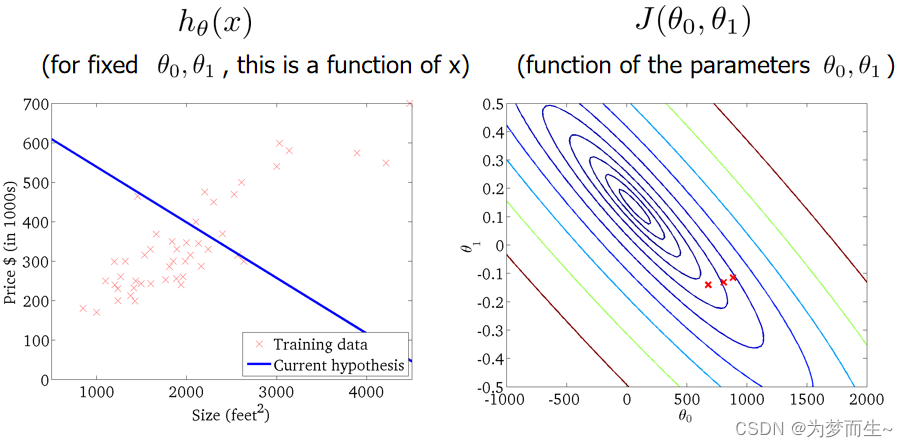
同样利用上面的方法,遍历每一个参数
θ
0
\theta _{0}
θ0,
θ
1
\theta _{1}
θ1,找到使得代价函数最小的参数。 

 那么具体到一元线性回归的代价函数,我们如何使用梯度下降呢?
那么具体到一元线性回归的代价函数,我们如何使用梯度下降呢? 其中𝑎是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向 向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。
其中𝑎是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向 向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。  偏导
(
φ
φ
θ
j
J
(
θ
)
)
(\frac{\varphi }{\varphi \theta _{j}}J(\theta ))
(φθjφJ(θ))的目的是为了确定下山的方向
偏导
(
φ
φ
θ
j
J
(
θ
)
)
(\frac{\varphi }{\varphi \theta _{j}}J(\theta ))
(φθjφJ(θ))的目的是为了确定下山的方向  当偏导大于0或小于0时代表了函数的不同增长趋势,与导数的意义相同
当偏导大于0或小于0时代表了函数的不同增长趋势,与导数的意义相同 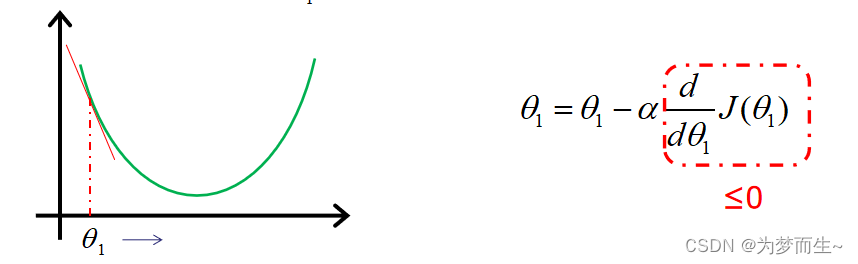 每走一步(每一次迭代)我们都需要确定新的参数,因为只有更新了参数才能确定下一步的方向。 每走一步都计算其梯度,经过不断的迭代,最终就可以找到最小值了。
每走一步(每一次迭代)我们都需要确定新的参数,因为只有更新了参数才能确定下一步的方向。 每走一步都计算其梯度,经过不断的迭代,最终就可以找到最小值了。
 这样,我们就可以通过迭代,更快的找到最小值了
这样,我们就可以通过迭代,更快的找到最小值了 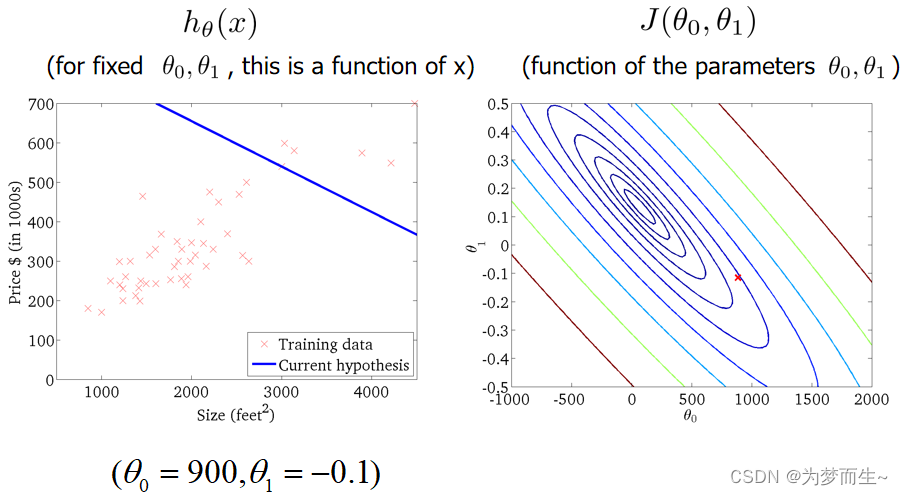

【本文地址】