| PostgreSQL数据库查询 | 您所在的位置:网站首页 › yylex函数 › PostgreSQL数据库查询 |
PostgreSQL数据库查询
|
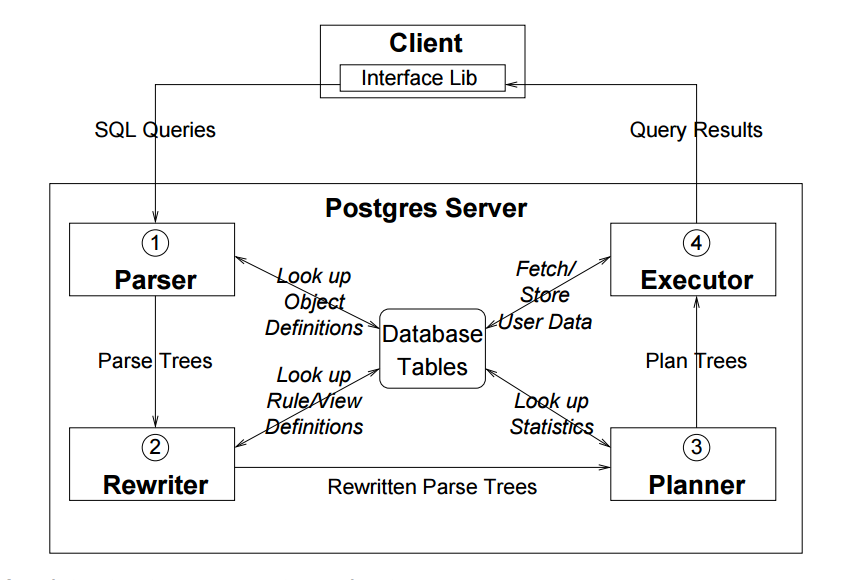
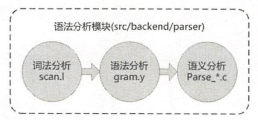
上面这张图从整体上概括了Postgresql的查询处理的步骤以及牵涉到的各个模块,源码参考自postgresql-12.6。 一、Parser(查询分析模块)查询分析模块主要是pg_parse_query函数(\src\backend\tcop\postgres.c 631行),输入const char * query_string,输出List *raw_parsetree_list。由于query_string中可能存在多个命令,函数返回值就是多个parsetrees(RawStmt nodes)组成的列表。pg_parse_query函数代码如下,主要逻辑就是调用raw_parser函数。 1 List *pg_parse_query(const char *query_string) { 2 List *raw_parsetree_list; 3 TRACE_POSTGRESQL_QUERY_PARSE_START(query_string); 4 if (log_parser_stats) 5 ResetUsage(); 6 raw_parsetree_list = raw_parser(query_string); 7 if (log_parser_stats) 8 ShowUsage("PARSER STATISTICS"); 9 #ifdef COPY_PARSE_PLAN_TREES 10 /* Optional debugging check: pass raw parsetrees through copyObject() */ 11 { 12 List *new_list = copyObject(raw_parsetree_list); 13 /* This checks both copyObject() and the equal() routines... */ 14 if (!equal(new_list, raw_parsetree_list)) 15 elog(WARNING, "copyObject() failed to produce an equal raw parse tree"); 16 else 17 raw_parsetree_list = new_list; 18 } 19 #endif 20 /* Currently, outfuncs/readfuncs support is missing for many raw parse tree nodes, so we don't try to implement WRITE_READ_PARSE_PLAN_TREES here. */ 21 TRACE_POSTGRESQL_QUERY_PARSE_DONE(query_string); 22 return raw_parsetree_list; 23 }语法分析模块位于src/backend/parser下,src/backend/parser/parser.c包含raw_parser和base_yylex两个函数。raw_parser函数以字符串格式输入查询,返回raw(未分析)的分析树列表,该列表的元素永远是RawStmt节点。
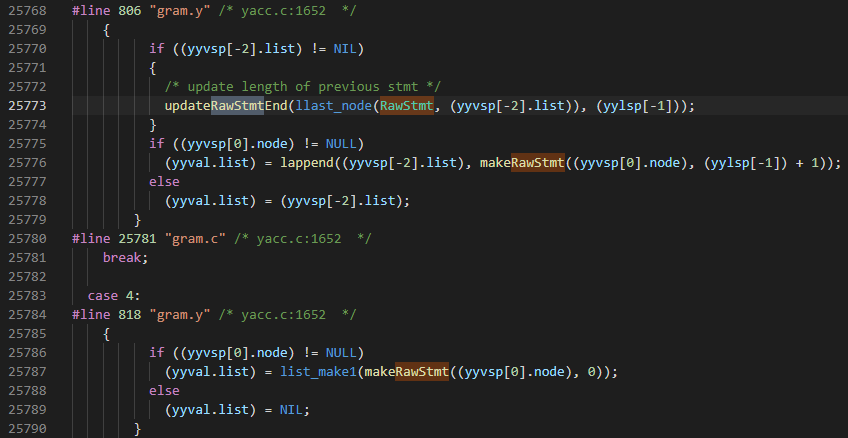
先分析一下raw_parser函数返回的RawStmt节点列表的数据结构,RawStmt是任何statement raw分析树的容器,stmt_location/stmt_len定位该raw statement在源字符串的位置。PG数据库中的结构体采用了统一的形式,都是基于Node结构体进行扩展,Node结构体值包含一个NodeTag成员,NodeTag是enum类型,RawStmt也不列外。 1 typedef struct RawStmt { 2 NodeTag type; 3 Node *stmt; /* raw parse tree */ 4 int stmt_location; /* start location, or -1 if unknown */ 5 int stmt_len; /* length in bytes; 0 means "rest of string" */ 6 } RawStmt;以List为例,ListCell的data连接体可以指向RawStmt,从而可以在List存放RawStmt节点,组成raw(未分析)的分析树列表。 1 typedef struct List{ 2 NodeTag type; /* T_List, T_IntList, or T_OidList */ 3 int length; 4 ListCell *head; 5 ListCell *tail; 6 } List; 7 struct ListCell{ 8 union{ 9 void *ptr_value; 10 int int_value; 11 Oid oid_value; 12 } data; 13 ListCell *next; 14 };如下所示是新建RawStmt节点的函数,Node *stmt指向makeRawStmt函数的第一个参数。从gram.c中的第25768行可以看到创建RawStmt列表。如第25785行可以看到代码list_nake1(makeRawStmt((yyvsp[0].node),0))。 1 // gram.c第45878行 2 static RawStmt *makeRawStmt(Node *stmt, int stmt_location){ 3 RawStmt *rs = makeNode(RawStmt); 4 rs->stmt = stmt; 5 rs->stmt_location = stmt_location; 6 rs->stmt_len = 0; /* might get changed later */ 7 return rs; 8 }
查询分析模块最重要的函数raw_parser主要执行流程如下: 声明变量yyscanner和yyextra 调用 scanner_init函数初始化yyscanner和yyextra 设置yyextra.have_lookahead = false 调用parser_init设置yyextra->parsetree = NIL 调用base_yyparse进行词法分析 调用scanner_finish释放内存 返回语法树 1 List *raw_parser(const char *str){ 2 core_yyscan_t yyscanner; 3 base_yy_extra_type yyextra; 4 int yyresult; 5 /* initialize the flex scanner */ 6 yyscanner = scanner_init(str, &yyextra.core_yy_extra, &ScanKeywords, ScanKeywordTokens); 7 /* base_yylex() only needs this much initialization */ 8 yyextra.have_lookahead = false; 9 /* initialize the bison parser */ 10 parser_init(&yyextra); 11 /* Parse! */ 12 yyresult = base_yyparse(yyscanner); 13 /* Clean up (release memory) */ 14 scanner_finish(yyscanner); 15 if (yyresult) /* error */ 16 return NIL; 17 return yyextra.parsetree; 18 }该函数所涉及的变量的类型,core_yyscan_t是空指针类型,base_yy_extra_type是一个结构体,主要保存用于解析词法语法的私有状态变量。
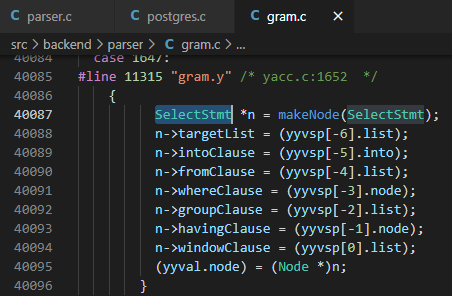
对于base_yy_extra_type结构体中的parsetree是gram.c第25760行的代码来填充的,代码如下图所示。
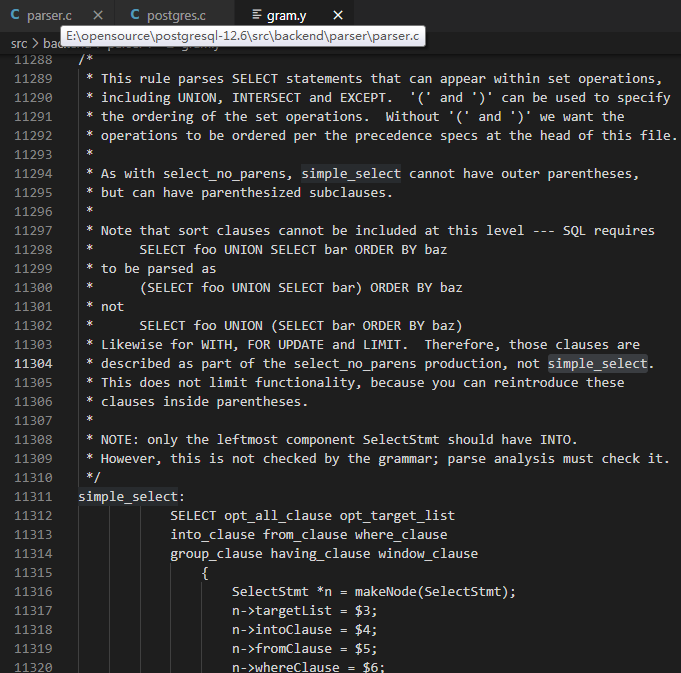
1.1 词法和语法分析模块 上面简述了查询分析模块最重要的函数raw_parser主要执行流程如下:声明变量yyscanner和yyextra;调用 scanner_init函数初始化yyscanner和yyextra;设置yyextra.have_lookahead = false;调用parser_init设置yyextra->parsetree = NIL;调用base_yyparse进行词法分析;调用scanner_finish释放内存;返回语法树。scanner_init函数声明变量scanner,调用core_yylex_init为scanner开辟内存空间,调用函数core_yyset_extra(将scanner赋值给yyg(struct yyguts_t结构体,保存了可重入scanner的状态),yyextra赋值给yyg->yyextra_r),设置yyextra的keywordlist和keyword_tokens等参数,初始化yyextra的文字缓冲区,返回scanner。 parser_init设置yyextra->parsetree = NIL,代码如下所示: 1 /* parser_init() Initialize to parse one query string */ 2 void parser_init(base_yy_extra_type *yyext) { 3 yyext->parsetree = NIL; /* in case grammar forgets to set it */ 4 }我们先通过一个标准SELECT语句分析lex和bison输出的scan.c和gram.c代码,从gram.y中给出的SSELECT语句定义可以看出其包括目标列、FROM子句、条件语句等。 1 simple_select: 2 SELECT opt_distinct opt_target_list 3 into_clause from_clause where_clause 4 group_clause having_clause window_clause
由simple_select可以看出,当PG语法分析器识别为第一种情况时,则在相应的动作部分执行创建SelectStmt类型对象并将该对象的targetList、fromClause等域设置为对应的opt_target_list、from_clause等语句的操作。如下所示是该部分代码在gram.c中的位置。
base_yylex函数是parser和核心lexer(scan.l中的core_yylex)之间的中间filter。
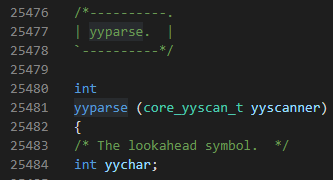
base_yyparse函数 声明各种变量值并初始化,如yystate保存语法分析器当前的状态,该状态能反映出刚刚读取的记号,yyssp指向分析栈栈顶的指针 yybackup:yylex(base_yylex)函数在这里调用,判断是否向前看了token,若是则将yyextra内记录的lookahead_token赋给当前标记cur_token,否则调用函数core_yylex,读入下一个token;查看cur_token,记录长度,如果cur_token是NOT、NULLS_P、WITH则执行前看动作,否则直接返回cur_token;调用core_yylex读入下一个token,赋值给yyextra->lookahead_token;根据本次读入的next_token,将cur_token(即NOT、NULLS_P、WITH中的一个)替换为NOT_LA,NULLS_LA,WITH_LA;返回cur_token。 yyreduce根据文法进行规约和语法制导翻译。
PostgreSQL数据库查询——scan.l分析
1.2 语义分析模块 函数pg_analyze_and_rewrite接受一棵原始语法树并通过对该原始语法树的分析和重写操作后,函数将该原始语法树转换为一棵(或多棵)查询语法树,而该查询语法树是后续所有优化操作的基础,函数调用如下querytree_list = pg_analyze_and_rewrite(parsetree, query_string, NULL, 0, NULL)。原始语法树到查询树的转换过程分为两个阶段:原始语法树的分析阶段和原始查询语法树的重写操作,这里的原始语法树的分析阶段就是这里的语义分析模块。
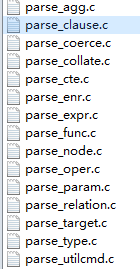
函数parse_analyze(处于analyze.c文件中)主要工作是处理语义分析,其会根据分析树生成一个对应的查询树,函数调用如下所示: query = parse_analyze(parsetree, query_string, paramTypes, numParams, queryEnv)。语义分析阶段会检查命令中是否有不符合语义规定的成分。例如,所使用的表、属性、过程函数等是否存在,聚集函数(如求和函数SUM、平均函数AVG等)是否可以合法使用等。其主要作用在于检查该命令是否可以正确执行。语义分析器会根据分析树中的内容得到更有利于执行的数据,例如,根据表的名字得到其OID,根据属性名得到其属性号,根据操作符的名字得到其对应的计算函数等。 1 Query * parse_analyze(RawStmt *parseTree, const char *sourceText, Oid *paramTypes, int numParams, QueryEnvironment *queryEnv){ 2 ParseState *pstate = make_parsestate(NULL); 3 Query *query; 4 Assert(sourceText != NULL); /* required as of 8.4 */ 5 pstate->p_sourcetext = sourceText; 6 if (numParams > 0) 7 parse_fixed_parameters(pstate, paramTypes, numParams); 8 pstate->p_queryEnv = queryEnv; 9 query = transformTopLevelStmt(pstate, parseTree); 10 if (post_parse_analyze_hook) 11 (*post_parse_analyze_hook) (pstate, query); 12 free_parsestate(pstate); 13 return query; 14 }函数parse_analyze首先将生成一个ParseState结构用于记录语义分析的状态,然后通过调用函数transformStmt来完成语义分析过程。transformTopLevelStmt函数负责在调用transformOptionalSelectInto函数之后,将parseTree中的stmt_localtion和stmt_len复制到查询树Query相应字段中。而transformOptionalSelectInfo函数的作用是在select语句中还有INTO时,将其转换为CREATE TABLE AS。 1 Query * transformTopLevelStmt(ParseState *pstate, RawStmt *parseTree){ 2 Query *result; 3 /* We're at top level, so allow SELECT INTO */ 4 result = transformOptionalSelectInto(pstate, parseTree->stmt); 5 result->stmt_location = parseTree->stmt_location; 6 result->stmt_len = parseTree->stmt_len; 7 return result; 8 } 9 10 static Query *transformOptionalSelectInto(ParseState *pstate, Node *parseTree){ 11 if (IsA(parseTree, SelectStmt)){ 12 SelectStmt *stmt = (SelectStmt *) parseTree; 13 /* If it's a set-operation tree, drill down to leftmost SelectStmt */ 14 while (stmt && stmt->op != SETOP_NONE) 15 stmt = stmt->larg; 16 Assert(stmt && IsA(stmt, SelectStmt) &&stmt->larg == NULL); 17 if (stmt->intoClause){ 18 CreateTableAsStmt *ctas = makeNode(CreateTableAsStmt); 19 ctas->query = parseTree; 20 ctas->into = stmt->intoClause; 21 ctas->relkind = OBJECT_TABLE; 22 ctas->is_select_into = true; 23 /* Remove the intoClause from the SelectStmt. This makes it safe for transformSelectStmt to complain if it finds intoClause set (implying that the INTO appeared in a disallowed place). */ 24 stmt->intoClause = NULL; 25 parseTree = (Node *) ctas; 26 } 27 } 28 return transformStmt(pstate, parseTree); 29 }函数transformStmt会根据不同的查询类型调用相应的函数进行处理,其将命令类型分为七种情况处理【UTILITY(建表、建索引等附件命令)、EXPLAIN(显示查询的执行计划)、DECLARECURSOR(定义游标)、UPDATE、DELETE、INSERT、SELECT、CREATE TABLE AS、CALL】。transformStmt函数只有两个参数,一个是ParseState,另一个就是要处理的包装成节点的分析树。通过节点type字段,transformStmt可以处理七种分析树,并调用相应的处理函数。 NodeTag值 语义分析函数 T_InsertStmt transformInsertStmt T_DeleteStmt transformDeleteStmt T_UpdateStmt transformUpdateStmt T_SelectStmt transformSelectStmt或transformValuesClause或transformSetOperationStmt T_DeclareCursorStmt transformDeclareCursorStmt T_ExplainStmt transformExplainStmt T_CreateTableAsStmt transformCreateTableAsStmt T_CallStmt transformCallStmt 其他 作为Utility类型处理,直接在分析树上封装一个Query节点返回1 Query *transformStmt(ParseState *pstate, Node *parseTree){ 2 Query *result; 3 /* We apply RAW_EXPRESSION_COVERAGE_TEST testing to basic DML statements; we can't just run it on everything because raw_expression_tree_walker() doesn't claim to handle utility statements. */ 4 #ifdef RAW_EXPRESSION_COVERAGE_TEST 5 switch (nodeTag(parseTree)){ 6 case T_SelectStmt: 7 case T_InsertStmt: 8 case T_UpdateStmt: 9 case T_DeleteStmt: 10 (void) test_raw_expression_coverage(parseTree, NULL); 11 break; 12 default: 13 break; 14 } 15 #endif /* RAW_EXPRESSION_COVERAGE_TEST */ 16 switch (nodeTag(parseTree)){ 17 /* Optimizable statements */ 18 case T_InsertStmt: 19 result = transformInsertStmt(pstate, (InsertStmt *) parseTree); 20 break; 21 case T_DeleteStmt: 22 result = transformDeleteStmt(pstate, (DeleteStmt *) parseTree); 23 break; 24 case T_UpdateStmt: 25 result = transformUpdateStmt(pstate, (UpdateStmt *) parseTree); 26 break; 27 case T_SelectStmt:{ 28 SelectStmt *n = (SelectStmt *) parseTree; 29 if (n->valuesLists) 30 result = transformValuesClause(pstate, n); 31 else if (n->op == SETOP_NONE) 32 result = transformSelectStmt(pstate, n); 33 else 34 result = transformSetOperationStmt(pstate, n);} 35 break; 36 /* Special cases */ 37 case T_DeclareCursorStmt: 38 result = transformDeclareCursorStmt(pstate,(DeclareCursorStmt *) parseTree); 39 break; 40 case T_ExplainStmt: 41 result = transformExplainStmt(pstate, (ExplainStmt *) parseTree); 42 break; 43 case T_CreateTableAsStmt: 44 result = transformCreateTableAsStmt(pstate,(CreateTableAsStmt *) parseTree); 45 break; 46 case T_CallStmt: 47 result = transformCallStmt(pstate, (CallStmt *) parseTree); 48 break; 49 default: 50 /* other statements don't require any transformation; just return the original parsetree with a Query node plastered on top. */ 51 result = makeNode(Query); 52 result->commandType = CMD_UTILITY; 53 result->utilityStmt = (Node *) parseTree; 54 break; 55 } 56 /* Mark as original query until we learn differently */ 57 result->querySource = QSRC_ORIGINAL; 58 result->canSetTag = true; 59 return result; 60 } 以transformDeleteStmt函数为例,其将Delete语句进行语义解析,会执行函数transformWithClause、setTargetTable、transformFromClause、transformWhereClause、transformReturningList、assign_query_collations、parseCheckAggregates。transformWithClause函数定义在parse_cte.c文件中,setTargetTable、transformFromClause和transformWhereClause定义在parse_clause.c文件中,transformReturnungList函数定义在analyze文件中,assign_query_collations函数定义在parse_cllate.c文件中,parseCheckAggregates函数定义在parse_agg.c文件中。 1 static Query *transformDeleteStmt(ParseState *pstate, DeleteStmt *stmt){ 2 Query *qry = makeNode(Query); 3 ParseNamespaceItem *nsitem; 4 Node *qual; 5 qry->commandType = CMD_DELETE; 6 /* process the WITH clause independently of all else */ 7 if (stmt->withClause){ 8 qry->hasRecursive = stmt->withClause->recursive; 9 qry->cteList = transformWithClause(pstate, stmt->withClause); 10 qry->hasModifyingCTE = pstate->p_hasModifyingCTE; 11 } 12 /* set up range table with just the result rel */ 13 qry->resultRelation = setTargetTable(pstate, stmt->relation,stmt->relation->inh,true,ACL_DELETE); 14 /* grab the namespace item made by setTargetTable */ 15 nsitem = (ParseNamespaceItem *) llast(pstate->p_namespace); 16 /* there's no DISTINCT in DELETE */ 17 qry->distinctClause = NIL; 18 /* subqueries in USING cannot access the result relation */ 19 nsitem->p_lateral_only = true; 20 nsitem->p_lateral_ok = false; 21 /* The USING clause is non-standard SQL syntax, and is equivalent in functionality to the FROM list that can be specified for UPDATE. The USING keyword is used rather than FROM because FROM is already a keyword in the DELETE syntax. */ 22 transformFromClause(pstate, stmt->usingClause); 23 /* remaining clauses can reference the result relation normally */ 24 nsitem->p_lateral_only = false; 25 nsitem->p_lateral_ok = true; 26 qual = transformWhereClause(pstate, stmt->whereClause, EXPR_KIND_WHERE, "WHERE"); 27 qry->returningList = transformReturningList(pstate, stmt->returningList); 28 /* done building the range table and jointree */ 29 qry->rtable = pstate->p_rtable; 30 qry->jointree = makeFromExpr(pstate->p_joinlist, qual); 31 qry->hasSubLinks = pstate->p_hasSubLinks; 32 qry->hasWindowFuncs = pstate->p_hasWindowFuncs; 33 qry->hasTargetSRFs = pstate->p_hasTargetSRFs; 34 qry->hasAggs = pstate->p_hasAggs; 35 assign_query_collations(pstate, qry); 36 /* this must be done after collations, for reliable comparison of exprs */ 37 if (pstate->p_hasAggs) 38 parseCheckAggregates(pstate, qry); 39 return qry; 40 }由上例可以看出语义分析模块提供的函数主要集中在如下parse_*.c文件下
1.3 查询分析模块调试 打印bison语法分析过程: 修改gram.c(去掉78行的注释,变为define YYDEBUG 1;将25201行的int yydebug赋值为1,变为int yydebug = 1) 重新编译源码
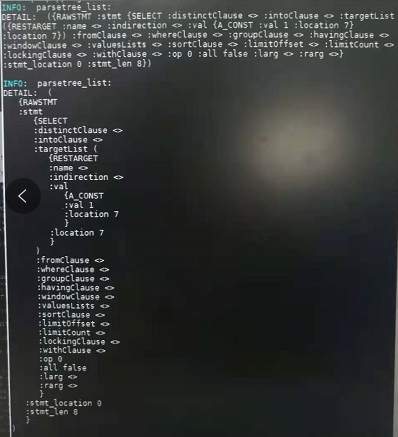
打印parsetree_list: (gdb)call elog_node_display(17,"parsetree_list",parsetree_list,0)或(gdb)call elog_node_display(17,"parsetree_list",parsetree_list,1)
二、Rewriter(重写模块) 查询重写的核心就是规则系统,而规则系统则由一系列的规则组成。系统表pg_write存储重写规则(每一个元祖代表一条规则)。对于每条规则,该元组的ev_class属性表示该规则适用的表名,如果在该表的指定属性(由ev_attr属性记录)上执行特定的命令(由ev_type属性记录)且满足了规则的条件(由ev_qual属性记录)时,用规则的动作(由ev_action属性记录)替换原始命令的动作或将规则的动作附加在原始命令之前(或者之后)。 名字 类型 引用 描述 rulename name 规则名 ev_class oid pg_class.oid 使用该规则的表名称 ev_attr int2 规则使用的属性 ev_type char 规则使用的命令类型:1=SELECT,2=UPDATE,3=INSERT,4=DELETE is_instead bool 如果是INSEAD规则,则为真 ev_qual text 规则的条件表达式(WHERE子句) ev_action text 规则动作的查询树(DO子句)根据系统表pg_rewrite的不同属性,规则可以按两种方式分类:按照规则适用的命令类型分类,可以分成SELECT、UPDATE、INSERT和DELETE四种;按照规则执行动作的方式分类,可以分成INSTEAD(替代)规则和ALSO规则。 SELECT/INSERT/UPDATE/DELETE四种规则通过其pg_rewrite元组的ev_type属性值来区分。SELECT规则中只能有一个动作,而且只能是不带条件的INSTEAD规则,SELECT规则的执行效果类似于视图,使用方法可以参考“视图和规则系统”部分的举例。INSERT/UPDATE/DELETE规则具有以下特性:可以没有动作,可以有多个动作,可以是INSTEAD型规则(替代规则)或ALSO型规则(缺省),可以使用伪关系NEW和OLD,可以使用规则条件,不是修改查询树,而是创建零个或多个新查询树并且可能把原始的查询树丢弃。 INSTEAD规则和ALSO规则通过规则的pg_rewrite元组的is_instead属性值来区分,为真表示INSTEAD规则,为假则表示ALSO规则。INSTEAD规则执行动作的方式很简单,就是用规则中定义的动作替代原始的查询树中的对规则所在表的引用。ALSO型规则中原始查询和规则动作都会被执行,但执行顺序根据不同的命令也有所不同,对于INSERT规则,原始查询在规则动作执行之前完成,这样可以保证规则动作能引用插入的行,对于UPDATE和DELETE规则,原始查询在规则动作之后完成,这样能保证规则动作可以引用将要更新或删除的元组;否则,那些要访问旧版本元组的规则动作就无法完成。 PG的视图是通过规则系统实现。在创建视图时,系统会自动按照其定义生成相应的规则,当查询涉及该视图时,查询重写模块都会用对应的规则对该查询进行重写,将对视图的查询改写为对基本表的查询。在生成视图的规则时,规则动作是视图创建命令中SELECT语句的拷贝,并且该规则是无条件的INSTEAD规则。
定义重写规则
删除重写规则
对查询树进行重写 pg_rewrite_query函数对CMD_UTILITY不做任何处理,直接调用list_make1(query)生成querytree_list。对于其他语句进行重写,调用querytree_list = QueryRewrite(query)。QueryRewrite函数会使用规则系统判断来进行查询树的重写,并且有可能会将这个查询树改写成一个包含多棵查询树的链表。查询重写的源代码在src/backend/rewrite文件夹中。 1 static List * pg_rewrite_query(Query *query){ 2 List *querytree_list; 3 if (Debug_print_parse) 4 elog_node_display(LOG, "parse tree", query, Debug_pretty_print); 5 if (log_parser_stats) 6 ResetUsage(); 7 if (query->commandType == CMD_UTILITY){ 8 /* don't rewrite utilities, just dump 'em into result list */ 9 querytree_list = list_make1(query); 10 } else { 11 /* rewrite regular queries */ 12 querytree_list = QueryRewrite(query); 13 } 14 if (log_parser_stats) 15 ShowUsage("REWRITER STATISTICS"); 16 #ifdef COPY_PARSE_PLAN_TREES 17 /* Optional debugging check: pass querytree through copyObject() */ 18 { 19 List *new_list; 20 new_list = copyObject(querytree_list); 21 /* This checks both copyObject() and the equal() routines... */ 22 if (!equal(new_list, querytree_list)) 23 elog(WARNING, "copyObject() failed to produce equal parse tree"); 24 else 25 querytree_list = new_list; 26 } 27 #endif 28 #ifdef WRITE_READ_PARSE_PLAN_TREES 29 /* Optional debugging check: pass querytree through outfuncs/readfuncs */ 30 { 31 List *new_list = NIL; 32 ListCell *lc; 33 /* We currently lack outfuncs/readfuncs support for most utility statement types, so only attempt to write/read non-utility queries. */ 34 foreach(lc, querytree_list){ 35 Query *query = castNode(Query, lfirst(lc)); 36 if (query->commandType != CMD_UTILITY){ 37 char *str = nodeToString(query); 38 Query *new_query = stringToNodeWithLocations(str); 39 /* queryId is not saved in stored rules, but we must preserve it here to avoid breaking pg_stat_statements. */ 40 new_query->queryId = query->queryId; 41 new_list = lappend(new_list, new_query); 42 pfree(str); 43 } else 44 new_list = lappend(new_list, query); 45 } 46 /* This checks both outfuncs/readfuncs and the equal() routines... */ 47 if (!equal(new_list, querytree_list)) 48 elog(WARNING, "outfuncs/readfuncs failed to produce equal parse tree"); 49 else 50 querytree_list = new_list; 51 } 52 #endif 53 if (Debug_print_rewritten) 54 elog_node_display(LOG, "rewritten parse tree", querytree_list, Debug_pretty_print); 55 return querytree_list; 56 }QueryRewirte函数位于src/backend/rewrite/rewriteHandler.c的第3964行,函数流程共分为三个步骤:1. Apply all non-SELECT rules possibly getting 0 or many queries 2. Apply all the RIR rules on each query 3. Determine which, if any, of the resulting queries is supposed to set the command result tag; and update the canSetTag fields accordingly. If the original query is still in the list, it sets the command tag. Otherwise, the last INSTEAD query of the same kind as the original is allowed to set the tag. (Note these rules can leave us with no query setting the tag. The tcop code has to cope with this by setting up a default tag based on the original un-rewritten query.) The Asserts verify that at most one query in the result list is marked canSetTag. If we aren't checking asserts, we can fall out of the loop as soon as we find the original query. 1 List *QueryRewrite(Query *parsetree){ 2 uint64 input_query_id = parsetree->queryId; 3 List *querylist; 4 List *results; 5 ListCell *l; 6 CmdType origCmdType; 7 bool foundOriginalQuery; 8 Query *lastInstead; 9 Assert(parsetree->querySource == QSRC_ORIGINAL); 10 Assert(parsetree->canSetTag); 11 /* Step 1 */ 12 querylist = RewriteQuery(parsetree, NIL); 13 /* Step 2 */ 14 results = NIL; 15 foreach(l, querylist){ 16 Query *query = (Query *) lfirst(l); 17 query = fireRIRrules(query, NIL); 18 query->queryId = input_query_id; 19 results = lappend(results, query);} 20 /* Step 3 */ 21 origCmdType = parsetree->commandType; 22 foundOriginalQuery = false; 23 lastInstead = NULL; 24 foreach(l, results){ 25 Query *query = (Query *) lfirst(l); 26 if (query->querySource == QSRC_ORIGINAL){ 27 Assert(query->canSetTag); 28 Assert(!foundOriginalQuery); 29 foundOriginalQuery = true; 30 #ifndef USE_ASSERT_CHECKING 31 break; 32 #endif 33 }else{ 34 Assert(!query->canSetTag); 35 if (query->commandType == origCmdType &&(query->querySource == QSRC_INSTEAD_RULE || query->querySource == QSRC_QUAL_INSTEAD_RULE)) 36 lastInstead = query; 37 } 38 } 39 if (!foundOriginalQuery && lastInstead != NULL) 40 lastInstead->canSetTag = true; 41 return results; 42 }QueryRewrite的处理流程如下:1)用非select规则将一个查询重写为0个或多个查询,此工作通过调用函数RewriteQuery完成 2)对上一步得到的每个查询分别用RIR规则(无条件INSERT规则,并且只能有一个SELECT规则动作)重写,通过调用函数fireRIRrules完成 3)将这些查询树作为查询重写的结果返回。
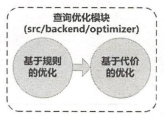
三、Planner(查询计划模块) 通过数据库的查询优化方法分为两个层次:基于规则的查询优化(逻辑优化,Rule Based Optimization,简称RBO);基于代价的查询优化(物理优化,Cost Based Optimization,简称CBO)。逻辑优化是建立在关系代数基础上的优化,关系代数中有一些等价的逻辑变换规则,通过对关系代数表达式进行逻辑上的等价变换,可能会获得执行性能比较好的等式,这样就能提高查询的性能;而物理优化则是在建立物理执行路径的过程中进行优化,关系代数中虽然指定了两个关系如何进行连接操作,但是这时的连接操作符属于逻辑运算符,它没有指定以何种方式实现这种逻辑连接操作,而查询执行器是不认识关系代数中的逻辑连接操作的,我们需要生成多个物理连接路径来实现关系代数中的逻辑连接操作,并根据查询执行器的执行步骤,建立代价计算模式,通过计算所有的物理连接路径的代价,从中选择出最优的路径。
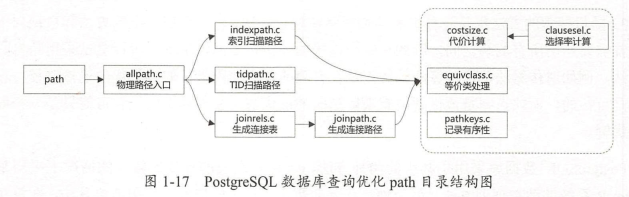
PostgreSQL数据库的查询优化的代码在src/backend/optimizer目录下,其中有plan、prep、path、geqo、util共5个子目录,plan是总入口目录,它调用了prep目录进行逻辑优化,调用path、geqo目录进行物理优化,util目录是一些公共函数,供所有目录使用。在执行中,从Plan模块入口,先调用Prep模块进行预处理,再调用Path模块进行优化。Path模块中有开关,指示是否启用遗传算法进行优化,如果启用,且连接的表超过11,就调用geqo目录中的遗传算法进行优化。prep目录主要处理逻辑优化中的逻辑重写的部分,对投影、选择条件、集合操作、连接操作都进行了重写。path目录则主要是生成物理路径的部分,包括生成扫描路径、连接路径等。geqo目录主要是实现了一种物理路径的搜索算法——遗传算法,通过这种算法可以处理参与连接的表比较多的情况。
查询规划的最终目的是得到可被执行模块执行的最优计划,整个过程可分为预处理、生成路径和生成计划三个阶段。预处理实际上是对查询树(Query结构体)的进一步改造,这种改造可通过SQL语句体现。在此过程中,最重要的是提升子链接和提升子查询。在生成路径阶段,接收到改造后的查询树后,采用动态规划算法或遗传算法,生成最优连接路径和候选路径链表。在生成计划阶段,用得到的最优路径,首先生成基本计划树,然后添加GROUP BY、HAVING和ORDER BY等子句所对应的计划节点形成完整计划树。 预处理 依照 PostgreSQL 数据库逻辑优化的源代码的分布情况,我们把逻辑优化分成了两部分逻辑重写优化和逻辑分解优化。划分的依据是:在逻辑重写优化阶段主要还是对查询树进行“重写”,也就是说在查询树上进行改造,改造之后还是 颗查询树,而在逻辑分解阶段,会将查询树打散,会重新建立等价于查询树的逻辑关系。
生成路径
生成计划 四、Executor(执行模块) 同查询编译器一样,查询执行器也是被函数exec_simple_query调用,从总体上看,查询执行器实际就是按照执行计划的安排,有机地调用存储、索引、并发等模块,按照各种执行计划中各种计划节点的实现算法来完成数据的读取或者修改的过程。 查询执行器有四个主要的子模块:Portal、ProcessUtility、Executot和特定功能子模块部分。从查询编译器输出执行计划,到执行计划被具体的执行部件处理这一过程,被称为执行策略的选择过程,负责完成执行策略选择的模块称为执行策略选择器。Portal模块就是这样的策略选择器,它会根据输入执行计划选择相应的处理模块(ProcessUtility或Executor)。Exceutor输入包含了一个查询计划树(Plan Tree),用于实现针对数据表中元组的增删查改等操作。ProcessUtility处理其他各种情况,这些情况间差别很大(如游标、表的模式创建、事务相关操作等),所以在ProcessUtility中为每种情况实现了处理流程。在两种执行模块中都少不了各种辅助的子系统,例如执行过程中会涉及表达式计算、投影运算以及元组操作等,这些功能相对独立,并且在整个查询执行过程中会被重复调用,因此将其单独划分为一个模块(特定功能子模块)。 对于Executor模块,它根据输入的查询计划树按部就班地处理数据表中元组的增删改查(DML)操作,它的执行逻辑是统一的(所有的增删改查最后都归结为SELECT,只是分别在SELECT的基础上进行一些额外的操作)。其主要代码放在src/backend/executor下。 对于ProcessUtility模块,由于处理的是除了增删改查之外的所有其他操作,而这些操作往往差异很大,例如数据定义操作(DDL),事务的处理以及游标用户角色定义这些,因此在ProcessUtility模块中,为每种操作单独地设计了子过程(函数)去处理。主要代码在src/backend/commands下。
可优化语句说白了就是DML语句,这些语句的特点就是都要查询到满足条件的元组。这类查询都在查询规划阶段生成了规划树,而规划树的生成过程中会根据查询优化理论进行重写和优化以提高查询速度,因此称作可优化语句,由Executor模块处理。那反过来讲,那些没有生成执行计划树的功能性操作就是非可优化语句了,语句之间功能相对独立,所以也被称为功能性操作,由ProcessUtility模块处理。 从以下五个部分介绍查询执行模块:1.查询执行策略 2.非可优化语句的执行 3.可优化语句的执行 4.计划节点 5.其它子功能
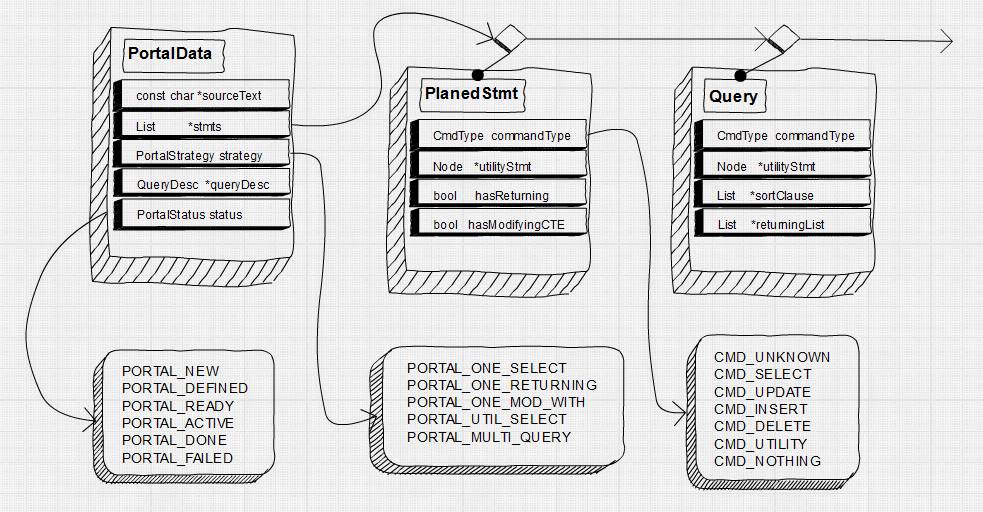
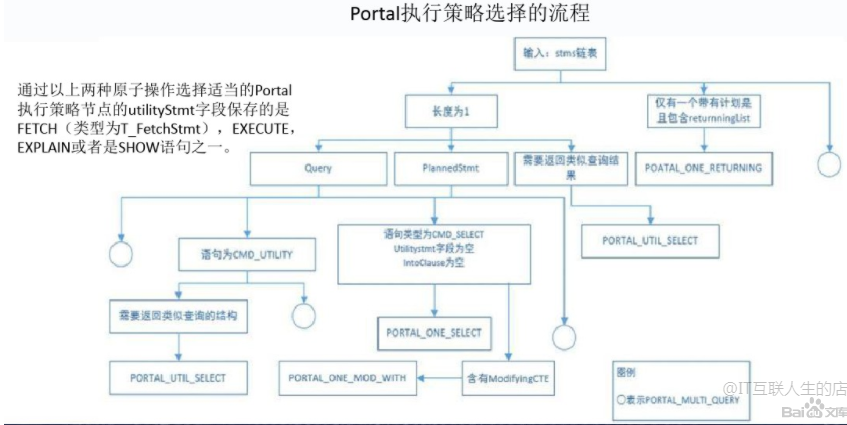
1.1 五种执行策略 一条简单的SQL语句会被查询编译器转化为一个执行计划树或者一个非计划树操作。而一条复杂的SQL语句往往同时带有DDL和DML语句,即它会被转换为一个可执行计划树和非执行计划树操作的序列。由查询编译器输出的每一个执行计划树或者一个非计划树操作所代表的处理动作称为一个原子操作。而可执行计划树和非可执行计划树是由不同的子模块去处理的。这样就有了三种不同的情况,需要三种不同的策略去应对。 然而除此之外,我们还有一种额外的情况需要考虑到:有些SQL语句虽然可以被转换为一个原子操作,但是其执行过程中由于各种原因需要能够缓存语句执行的结果,等到整个语句执行完毕在返回执行结果。具体的说: 对于可优化语句,当执行修改元组操作时,希望能够返回被修改的元组(例如带RETURNING子句的DELETE),由于原子操作的处理过程不能被可能有问题的输出过程终止,因此不能边执行边输出,因此需要一个缓存结构来临时存放执行结果; 某些非优化语句是需要返回结果的(例如SHOW,EXPLAIN) ,因此也需要一个缓存结构暂存处理结果。 针对以上情况,PG实现了不同的执行流程,共分为五类执行策略: 1)PORTAL_ONE_SELECT:处理单个的SELECT语句,调用Executor模块; 2)PORTAL_ONE_RETURNING:处理带RETURNING的UPDATE/DELETE/INSERT语句,调用Executor模块; 3)PORTAL_UTIL_SELECT:处理单个的数据定义语句,调用ProcessUtility模块; 4)PORTAL_ONE_MOD_WITH:处理带有INSERT/UPDATE/DELETE的WITH子句的SELECT,其处理逻辑类似PORTAL_ONE_RETURNING。调用Executor模块; 5)PORTAL_MULTI_QUERY:是前面几种策略的混合,可以处理多个原子操作。 1.2 策略实现 执行策略选择器的工作是根据查询编译阶段生成的计划树链表来为当前的查询选择五种执行策略中的一种。在这个过程中,执行策略选择器会使用数据结构PortalData来存储查询计划树链表以及最后选中的执行策略等信息,对于Portal这一数据结构定义在src/include/utils/portal.h。 1 typedef struct PortalData{ 2 /* Bookkeeping data */ 3 const char *name;/* portal's name */ 4 ...... 5 /* The query or queries the portal will execute */ 6 const char *sourceText;/* text of query (as of 8.4, never NULL) 原始SQL语句*/ 7 const char *commandTag;/* command tag for original query */ 8 List *stmts;/* PlannedStmts and/or utility statements 查询编译器输出的查询计划树链表 */ 9 ...... 10 ParamListInfo portalParams; /* params to pass to query */ 11 12 /* Features/options */ 13 PortalStrategy strategy;/* see above 为当前查询选择的执行策略 */ 14 PortalStatus;/* Portal的状态 */ 15 /* If not NULL, Executor is active; call ExecutorEnd eventually: */ 16 QueryDesc *queryDesc;/* info needed for executor invocation 查询描述符,存储执行查询所需的所有信息 */ 17 /* If portal returns tuples, this is their tupdesc: */ 18 TupleDesc tupDesc;/* descriptor for result tuples tupDesc描述可能的返回元组的结构 */ 19 ...... 20 } PortalData;对于查询执行器来说,在执行一个SQL语句时都会以一个Portal作为输入数据,在Portal中存放了与执行该SQL相关的所有信息,例如查询树、计划树和执行状态等。Portal结构和与之相关的主要字段的结构如下所示:
stmts字段是由查询编译器输出的原子操作的链表,,图中仅给出两种可能的原子操作PlannedStmt和 Query,两者都能包含查询计划树,用于保存含有查询的操作。当然,有些含有查询计划树的原子操作不一定是SELECT语句,例如游标的声明(utilityStmt字段不为空),以及SELECT INTO类型的语句(intoClause字段不为空)。对于UPDATE、INSERT、DELETE类型,含有RETURNING子句时returningList字段不为空。
PostgreSQL主要根据原子操作的命令类型以及stmts中原子操作的个数来为Portal选择合适的执行策略。由查询编译器输出的每一个查询计划树中都包含一个类型为CmdType的字段,用于标识该原子操作对应的命令类型。命令类型分类如下: 1 // src/include/nodes/nodes.h 2 typedef enum CmdType{ 3 CMD_UNKNOWN, /* 未定义 */ 4 CMD_SELECT, /* select stmt SELECT查询类型 */ 5 CMD_UPDATE,/* update stmt 更新操作 */ 6 CMD_INSERT, /* insert stmt 插入操作 */ 7 CMD_DELETE, /* 删除操作 */ 8 CMD_UTILITY, /* cmds like create, destroy, copy, vacuum, 功能性操作(数据定义语句) 9 * etc. */ 10 CMD_NOTHING /* dummy command for instead nothing rules 用于由查询编译器新生成的操作,即如果一个语句通过编译器的处理之后需要额外生成一个附加的操作,则该操作的命令类型就被设置为CMD_NOTHING 11 * with qual */ 12 } CmdType;选择PORTAL_ONE_SELECT策略应满足以下条件:stmts链表中只有一个PlannedStmt类型或是Query类型的节点;节点是CMD_SELECT类型操作;节点的utilityStmt字段和intoClause字段为空。 选择PORTAL_UTIL_SELECT策略应满足以下条件:stmts链表仅有的一个Query类型的节点;节点是CMD_UTILITY类型操作;节点的utilityStmt字段保存的是FETCH语句(类型为T_FetchStmt)、EXECUTE语句(类型为T_ExecuteStmt)、EXPLAIN语句(类型为T_ExplainStmt)或是SHOW语句(类型为T_VariableShowStmt)之一。 选择PORTAL_ONE_RETURNING策略适用于stmts链表中只有一个包含RETURNING子句(returningList不为空)的原子操作。其他的各种情况都将以PORTAL_MULTI_QUERY策略进行处理。 执行策略选择器的主函数名为ChoosePortalStrategy,其输入为PortalData的stmts链表,输出的是预先定义的执行策略枚举类型PortalStrategy。
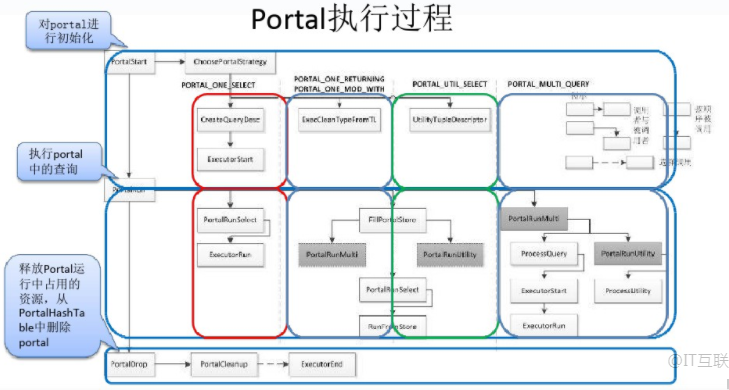
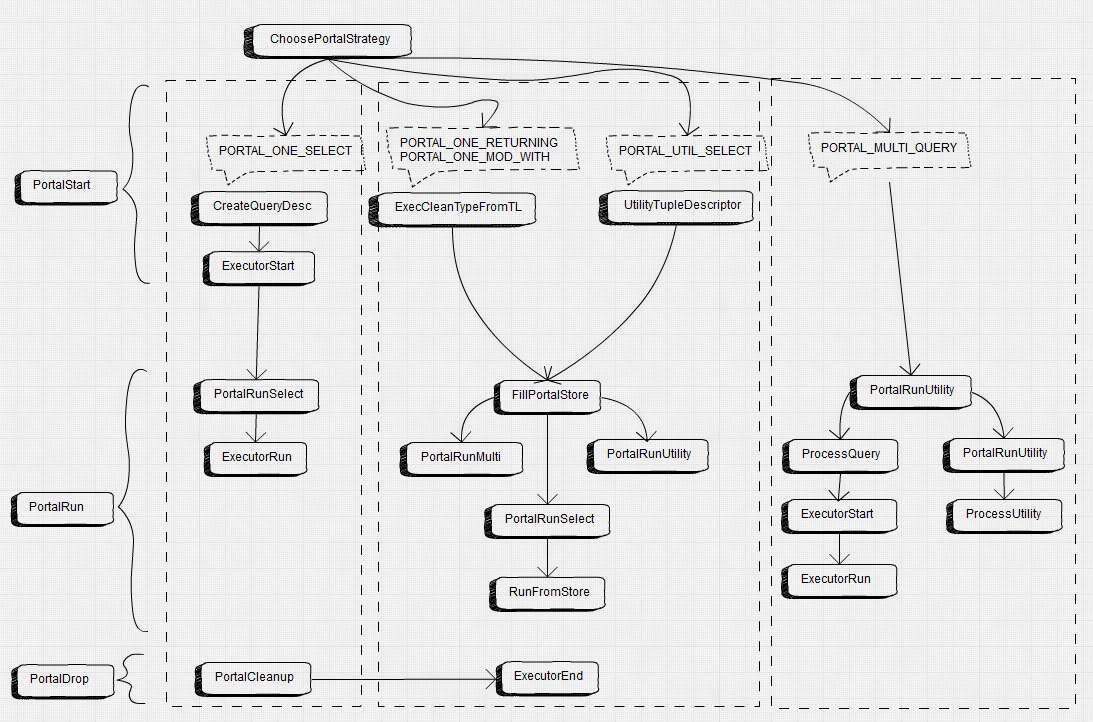
1.3 Portal的执行过程 Portal是查询执行器执行一个SQL语句的门户,所有SQL语句的执行都从一个选择好执行策略的Portal开始。所有Portal的执行过程都必须依次调用PortalStart(初始化)、PortalRun(执行)、PortalDrop(清理)三个过程,PostgreSQL为Portal提供的几种执行策略实现了单独的执行流程,每种策略的Portal在执行时会经过不同的处理过程。
Portal的创建、初始化、执行及清理过程都在exec_simple_query函数中进行,其过程如下: 1) 调用函数CreatePortal创建一个干净的Portal,其中内存上下文、资源跟踪器、清理函数等都已经设置好,但sourceText、stmts等字段并没有设置。 2) 调用函数PortalDefineQuery为刚创建的Portal设置sourceText、stmts等字段,这些字段的值都来自于查询编译器输出的结果,其中还会将Portal的状态设置为PORTAL_DEFINED表示Portal已被定义。 3) 调用函数PortalStart对定义好的Portal进行初始化,初始化工作主要如下: 1. 调用ChoosePortalStrategy为Portal选择策略 2. 如果选择的是PORTAL_ONE_SELECCT策略,调用CreateQueryDesc为Portal创建查询描述符 3. 如果选择的是PORTAL_ONE_RETURNING或者PORTAL_UTIL_SELECT策略,为Portal创建返回元组的描述符 4. 将Portal的状态设置为PORTAL_READY,表示Portal已经初始化好,准备开始执行 4) 调用函数PortalRun执行Portal,该函数将按照Portal中执行的策略调用相应的执行部件来执行Portal。 5) 调用函数PortalDrop清理Portal,主要是对Portal运行中所占用的资源进行释放,特别是用于缓存结果的资源。
对于PORTAL_ONE_SELECT策略的Portal,其中包含一个简单SELECT类型的查询计划树,在PortalStart中将调用ExecutorStart进行Executor初始化,然后在PortalRun中调用ExecutorRun开始执行器的执行过程。PORTAL_ONE_RETURNING和PORTAL_UTIL_SELECT策略需要在执行后将结果缓存,然后将缓存的结果按要求进行返回。因此,在PortalStart中仅会初始化返回元组的结构描述信息。接着PortalRun会调用FillPortalStore执行查询计划得到所有的结果元组并填充到缓存中,然后调用RunFromStore从缓存中获取元组并返回。从图中可以看到,FillPortalStore中对于查询计划的执行会根据策略不同而调用不同的处理部件,PORTAL_ONE_RETURING策略会使用PorttalRunMulti进行处理,而PORTAL_UTIL_SELECT使用PortalRunUtility处理。Portal_MULTI_QUERY策略在执行过程中,PortalRun会使用PortalRunMulti进行处理。
2. 非可优化语句的执行 数据定义语言是一类用于定义数据模式、函数等的功能性语句。不同于元组增删查改的操作,其处理方式是为每一种类型的描述语句调用相应的处理函数。数据定义语句的处理过程比较简单,其执行流程最终会进入到ProcessUtility处理器,然后执行语句对应的不同处理过程。由于数据定义语句的种类很多,因此整个处理过程中的数据结构和方式种类繁冗、复杂,但流程相对简单、固定。 数据定义语句执行流程 由于ProcessUtility需要处理所有类型的数据定义语句,因此其输入数据结构的类型也是各种各样,每种类型的数据结构表示不同的操作类型。ProcessUtility将通过判断数据结构中NodeTag字段的值来区分各种不同节点,并引导执行流程进入相应的处理函数。针对各种不同的查询树,
执行实例 1 CREATE TABLE course (no SERIAL, name VARCHAR, credit INT, CONSTRAINT con1 CHECK(credit >= 0 AND name "), PRIMARY KEY (no));查询编译器会生成一个仅包含一个T_CreateStmt类型节点的查询树链表,因此对应的Portal的stmts字段中也只包含一个T_CreateStmt类型节点。创建及初始化Portal-->PortalStart-->ChooseProtalStrategy:ChooseProtalStrategy函数根据stmts字段值选择策略时会选择PORTAL_MULTI_QUERY策略。调用Portal执行过程-->PortalRun-->PortalRunMulti-->PortalRunUtility-->ProcessUtility-->transformCreateStmt-->DefineRelation:PortalRun函数将会调用PortalRunMulti来执行PORTAL_MULTI_QUERY策略,将会把处理流程引导到ProcessUtility中,ProcessUtility将首先调用函数trandformCreateStmt对T_CreateStmt节点进行转换处理。
主要的功能处理器函数 3. 可优化语句的执行物理代数与处理模型 物理操作符的数据结构 执行器的运行 执行实例 4. 计划节点控制节点 扫描节点 物化节点 连接节点 5. 其它子功能元组操作 表达式计算 投影操作 五、各个模块tree打印 打印parse tree、rewritten parse tree、plan tree,在postgresql.conf文件中,修改如下配置为on #debug_print_parse = off --> 开启该选项所对应执行的代码处于pg_rewrite_query函数(postgres.c 773行) if (Debug_print_parse) elog_node_display(LOG,"parse tree",query,Debug_pretty_print); #debug_print_rewritten = off --> 开启该选项所对应执行的代码处于pg_rewrite_query函数(postgres.c 848行)if (Debug_print_rewritten) elog_node_display(LOG,"rewritten parse tree",querytree_list,Debug_pretty_print); #debug_print_plan = off --> 开启该选项所对应执行的代码处于pg_plan_query函数(postgres.c 929行)if (Debug_print_plan) elog_node_display(LOG,"plan",plan,Debug_pretty_print); #debug_pretty_print = on 也可在gdb调试情况下,使用(gdb) call elog_node_display(17, "what ever", Node * var, 0 or 1),17代表INFO,详见elog.h,比如希望打印在日志里,将17替换为16,0或1取决于debug_pretty_print为on还是off。
将打印信息图形化工具:https://github.com/shenyuflying/pgNodeGraph 使用流程:1. copy and paste the node tree in text form 2. put it in node dir 3. run ./pgNodeGraph
|










【本文地址】