| 【YOLO系列】 | 您所在的位置:网站首页 › yolo检测结果输出是索引 › 【YOLO系列】 |
【YOLO系列】
|
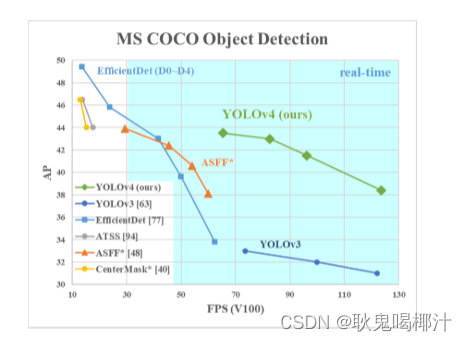
YOLOv4(YOLOv4: Optimal Speed and Accuracy of Object Detection)(原文+解读/总结+翻译) YOLO系列解读直通车🚀: YOLO系列-【YOLOv1】🚀 YOLO系列-【YOLOv2】🚀 YOLO系列-【YOLOv3】🚀 YOLO系列-【YOLOv4】🚀 YOLO系列-【YOLOv5】🚀 论文链接:https://arxiv.org/abs/2004.10934 源码链接:https://github.com/AlexeyAB/darknet 论文翻译:YOLOv4论文翻译(已校正)_耿鬼喝椰汁的博客-CSDN博客 前言上一篇文章我们讨论了yolov3,yolov3在速度与精度上达到了一个较好的平衡,堪称经典之作,可惜在yolov3之后的原作者Joseph Redmon因为yolo的军事应用和对他人个人隐私风险而退出了yolo系列的研究,从此cv界痛失一员大将,大家都以为yolo系列已经终结的时候,Yolov4横空出世,虽然作者已经大换血,但论文中给出的测试结果依然保留yolo系列的血统:保持相对较高的mAP的同时,大大降低计算量,可谓是学术成果在工业应用的典范,至于实际使用如何,还需要时间的进一步检验,期望v4能够如v3一般强大。 整体而言,YOLOv4几乎没有像前几代YOLO一样提出一些创新性的东西,而是大量列举了近几年以来关于目标检测的一些最新技术和成果,并对这些方法进行了大量的人工试验,可以认为是一种人工NAS,用试验的方式来选择一系列新的方法来对YOLOv3从网络结构、训练、数据增强等多个层面进行相应的增强,从而达到更好的效果。虽说没有提出令人惊艳的理论创新,但单单是用工作量如此巨大的人工搜索,了解并实践了如此多的最新研究成果,并将其中较优的方法应用于YOLO这样一个工业化如此优秀的检测器中,就已经足够令人感到赞叹了。 Yolov4相较于Yolov3改进的地方:(1)主干特征由DarkNet53改为CSPDarkNet53,主要在残差块进行了改进,引入了大残差块; (2)加入了SPP和PANNnet网络,用来增加图像的特征提取量,反复提取特征,并且SPP网络也可以增大感受野。 (3)在激活函数方面:从Yolov3的Leaky_relu函数,在Yolov4使用新的Mish激活函数(Mish激活函数是一种自正则的非单调神经激活函数,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。论文中提出,相比Swish有0.494%的提升,相比ReLU有1.671%的提升;该方法也在yolov4中得到了验证;)。 除了以上改进的地方,Yolov4还采用Mosaic数据增强,CIOU,学习率余弦退火衰减、标签平滑防止过拟合等操作。 速度改进后与其他模型对比如下(YOLOv4和其他最先进的物体探测器的比较。YOLOv4的运行速度是EfficientDet的两倍,性能相当。将YOLOv3的AP和FPS分别提高10%和12%。):
YOLOv4 网络的结构可分为四部分:输入端、主干网络(Backbone)-主干特征提取网络、颈部网络(Neck)-加强特征提取网络和头部网络(Head)--用来预测(Prediction)下图为 YOLOv4 算法的网络框架示意图。
以下是对这四个结构进行的改进: 1.输入端:这里指的创新主要是训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练2.主干网络(Backbone)-主干特征提取网络:将各种新的方式结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock3.颈部网络(Neck)-加强特征提取网络:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构4.头部网络(Head)--用来预测:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms基于深度学习的现在目标检测算法中主要有三个组件:Backbone、Neck和Head Backbone:骨干网络,主要指用于特征提取的,已在大型数据集(例如ImageNet|COCO等)上完成预训练,拥有预训练参数的卷积神经网络,例如:ResNet-50、Darknet53等Head:检测头/头部网络,主要用于预测目标的种类和位置(bounding boxes)Neck:颈部网络,在Backone和Head之间,会添加一些用于收集不同阶段中特征图的网络层。基于深度学习的目标检测模型的结构是这样的:输入->主干->脖子->头->输出。主干网络提取特征,脖子提取一些更复杂的特征,然后头部计算预测输出。 1.输入端创新 1.1 Mosaic数据增强Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。 1.为什么要进行Mosaic数据增强呢? 解决在整体的数据集中,小、中、大目标的占比并不均衡。-在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。针对这种状况,Yolov4的作者采用了Mosaic数据增强的方式,使大、中、小目标分配更加均匀。 小、中、大目标的定义: 2019年发布的论文《Augmentation for small object detection》对此进行了区分:
2.进行Mosaic数据增强的优点 丰富数据集: 随机使用4张图像,随机缩放后随机拼接,增加很多小目标,大大增加了数据多样性。增强模型鲁棒性: 混合四张具有不同语义信息的图片,可以让模型检测超出常规语境的目标。加强批归一化(Batch Normalization)的效果: 当模型设置 BN 操作后,训练时会尽可能增大批样本总量(BatchSize),因为 BN 原理为计算每一个特征层的均值和方差,如果批样本总量越大,那么 BN 计算的均值和方差就越接近于整个数据集的均值和方差,效果越好。有利于提升小目标检测性能: Mosaic 数据增强图像由四张原始图像拼接而成,这样每张图像会有更大概率包含小目标,从而提升了模型的检测能力。 1.2 CutMix数据增强CutMix数据增强这种增强方式v4中没有使用到,这里介绍一下: 数据增强的原因:在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。Coco数据集中小目标占比达到41.4%,数量比中目标和大目标都要多。但在所有的训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。 核心思想:将一部分区域cut掉但不填充0像素,而是随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配。 处理方式:对一对图片做操作,随机生成一个裁剪框Box,裁剪掉A图的相应位置,然后用B图片相应位置的ROI放到A图中被裁剪的区域形成新的样本,ground truth标签会根据patch的面积按比例进行调整。 另外两种数据增强的方式: (1)Mixup: 将随机的两张样本按比例混合,分类的结果按比例分配 (2)Cutout: 随机的将样本中的部分区域Cut掉,并且填充0像素值,分类的结果不变 1.3 Self-Adversarial Training--SAT自对抗训练自对抗训练也是一种新的数据增强方法,可以一定程度上抵抗对抗攻击。其包括两个阶段,每个阶段进行一次前向传播和一次反向传播。 第一阶段,CNN通过反向传播改变图片信息,而不是改变网络权值。通过这种方式,CNN可以进行对抗性攻击,改变原始图像,造成图像上没有目标的假象。第二阶段,对修改后的图像进行正常的目标检测。通过引入噪音点进行数据增强:
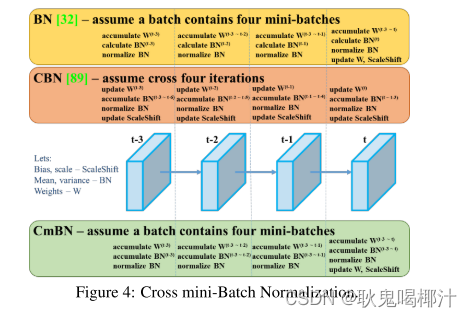
1. BN: 无论每个batch被分割为多少个mini batch,其算法就是在每个mini batch前向传播后统计当前的BN数据(即每个神经元的期望和方差)并进行Nomalization,BN数据与其他mini batch的数据无关。 2. CBN: 每次iteration中的BN数据是其之前n次数据和当前数据的和(对非当前batch统计的数据进行了补偿再参与计算),用该累加值对当前的batch进行Nomalization。好处在于每个batch可以设置较小的size。 3.CmBN: 只在每个Batch内部使用CBN的方法,若每个Batch被分割为一个mini batch,则其效果与BN一致;若分割为多个mini batch,则与CBN类似,只是把mini batch当作batch进行计算,其区别在于权重更新时间点不同,同一个batch内权重参数一样,因此计算不需要进行补偿。
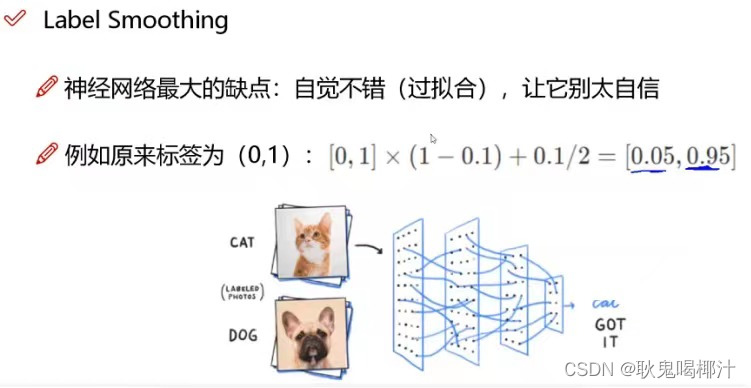
原因:对预测有100%的信心可能表明模型是在记忆数据,而不是在学习。如果训练样本中会出现少量的错误样本,而模型过于相信训练样本,在训练过程中调整参数极力去逼近样本,这就导致了这些错误样本的负面影响变大。 具体做法:标签平滑调整预测的目标上限为一个较低的值,比如0.9。它将使用这个值而不是1.0来计算损失。这样就缓解了过度拟合。说白了,这个平滑就是一定程度缩小label中min和max的差距,label平滑可以减小过拟合。所以,适当调整label,让两端的极值往中间凑凑,可以增加泛化性能。
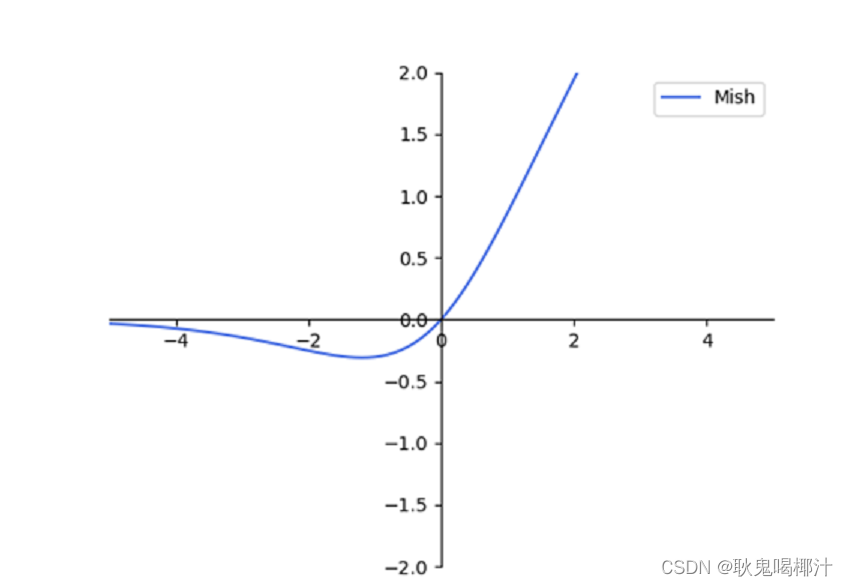
CSPDarknet53是在Yolov3主干网络Darknet53的基础上,借鉴2019年CSPNet的经验,产生的Backbone结构,其中包含了5个CSP模块。 1.为什么采用CSP模块? CSPNet全称是Cross Stage Paritial Network,主要从网络结构设计的角度解决推理中从计算量很大的问题。CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。因此Yolov4在主干网络Backbone采用CSPDarknet53网络结构 2.使用CSP模块优点 1.增强CNN的学习能力,使得在轻量化的同时保持准确性。 2.:降低计算瓶颈 3.:降低内存成本 2.2 Mish激活函数Mish激活函数是2019年下半年提出的激活函数,其函数图像如下:
Yolov4的Backbone中都使用了Mish激活函数,而后面的网络则还是使用leaky_relu函数. 1.为什么采用Mish激活函数? 作者实验测试时,使用CSPDarknet53网络在ImageNet数据集上做图像分类任务,发现使用了Mish激活函数的TOP-1和TOP-5的精度比没有使用时都略高一些。
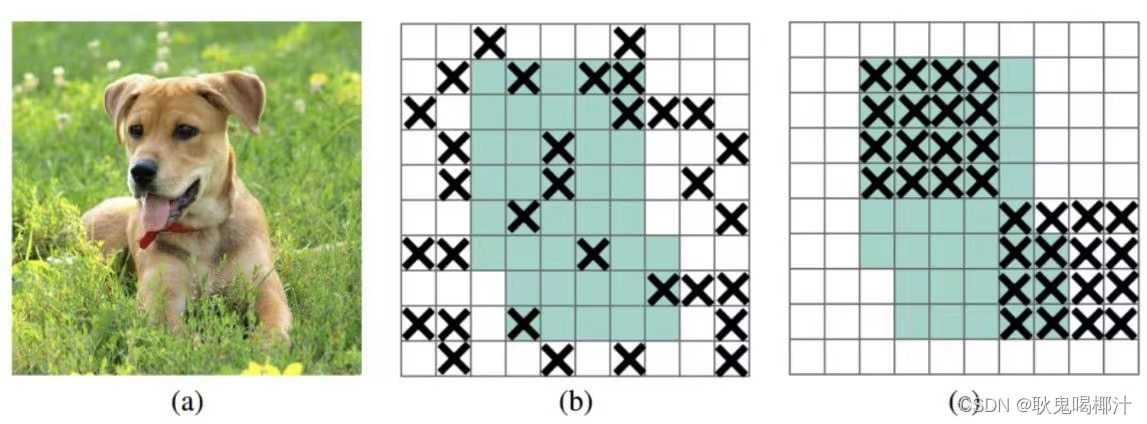
2.采用Mish激活函数优点: (1)从图中可以看出该激活函数,在负值时并不是完全截断,而允许比较小的负梯度流入从而保证了信息的流动 (2)Mish激活函数无边界,这让他避免了饱和(有下界,无上界)且每一点连续平滑且非单调性,从而使得梯度下降更好。 2.3 DropblockYolov4中使用的2018年提出的Dropblock,其实和常见网络中的Dropout功能类似,也是缓解过拟合的一种正则化方式,对网络的正则化过程进行了全面的升级改进。 传统的Dropout:随机删除减少神经元的数量,使网络变得更简单。而Dropblock和Dropout相似。 Dropblock:DropBlock技术在称为块的相邻相关区域中丢弃特征。Dropblock方法的引入是为了克服Dropout随机丢弃特征的主要缺点,Dropout主要作用在全连接层,而Dropblock可以作用在任何卷积层之上。这样既可以实现生成更简单模型的目的,又可以在每次训练迭代中引入学习部分网络权值的概念,对权值矩阵进行补偿,从而减少过拟合。 之前的Dropout是随机选择点(b),现在随机选择一个区域:
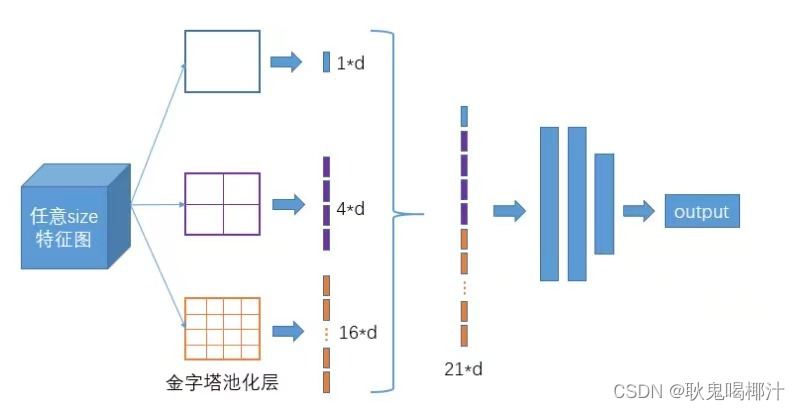
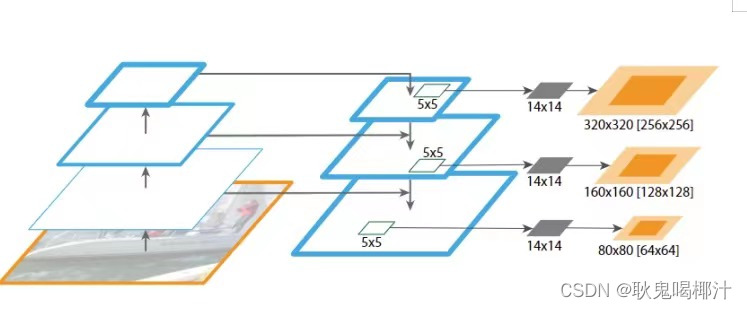
Yolov4的Neck结构主要采用了SPP模块、FPN+PAN的方式。 3.1 SPP模块SPP-Net全称Spatial Pyramid Pooling Networks,是何恺明大佬提出的,主要是用来解决不同尺寸的特征图如何进入全连接层的,在网络的最后一层concat所有特征图,后面能够继续接CNN模块。 如下图所示,下图中对任意尺寸的特征图直接进行固定尺寸的池化,来得到固定数量的特征。
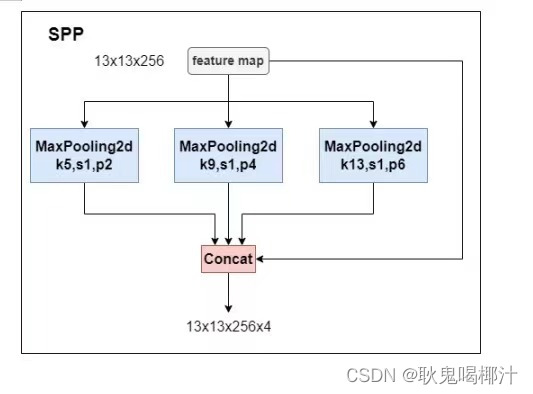
具体结构看下图:
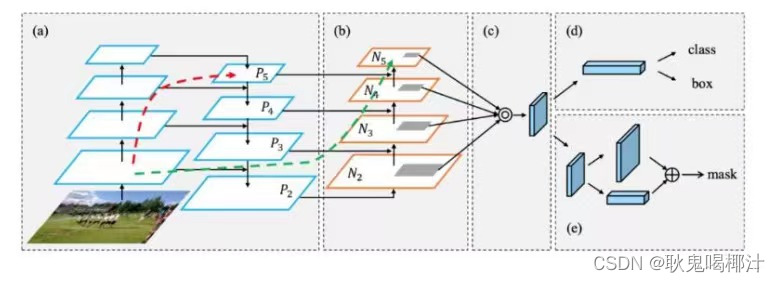
SPP模块,其实在Yolov3中已经存在了,在Yolov4的C++代码文件夹中有一个Yolov3_spp版本,但有的同学估计从来没有使用过,在Yolov4中,SPP模块仍然是在Backbone主干网络之后。Yolov4的作者在使用608*608大小的图像进行测试时发现,在COCO目标检测任务中,以0.5%的额外计算代价将AP50增加了2.7%,因此Yolov4中也采用了SPP模块。 3.2 FPN+PANYolov4中Neck这部分除了使用FPN外,还在此基础上使用了PAN结构。和Yolov3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔,其中包含两个PAN结构。 FPN+PAN借鉴的是18年CVPR的PANet,PAN其具体结构由反复提升特征的意思。当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
上图为原始的PANet的结构,可以看出来其具有一个非常重要的特点就是特征的反复提取。 在(a)里面是传统的特征金字塔结构,在完成特征金字塔从下到上的特征提取后,还需要实现(b)中从上到下的特征提取。 YOLOv3中的neck只有自顶向下的FPN,对特征图进行特征融合,而YOLOv4中则是FPN+PAN的方式对特征进一步的融合。引入了自底向上的路径,使得底层信息更容易传到顶部 下面是YOLOv3的neck中的FPN,如图所示:
FPN是自顶向下的,将高层的特征信息通过上采样的方式进行传递融合,得到进行预测的特征图。 YOLOv4中的neck如下:
而在YOLOV4当中,其主要是在三个有效特征层上使用了PANet结构。
这篇论文的学习和总结到这里就结束啦,如果有什么问题可以在评论区留言呀~ 如果帮助到大家,可以一键三连支持下~ 参考文献: Yolov4论文翻译与解析(一)_m米咔00的博客-CSDN博客 (1 封私信 / 2 条消息) yolov4详解 - 搜索结果 - 知乎 (zhihu.com) (5条消息) 睿智的目标检测30——Pytorch搭建YoloV4目标检测平台_睿智的yolov4_Bubbliiiing的博客-CSDN博客 |

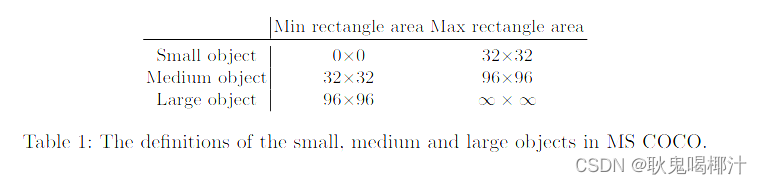





【本文地址】