| OpenCV调用海康威视等摄像头(处理rtsp视频流)方法以及,出现内存溢出(error while decoding)或者高延迟问题解决 | 您所在的位置:网站首页 › yolo使用网络摄像头 › OpenCV调用海康威视等摄像头(处理rtsp视频流)方法以及,出现内存溢出(error while decoding)或者高延迟问题解决 |
OpenCV调用海康威视等摄像头(处理rtsp视频流)方法以及,出现内存溢出(error while decoding)或者高延迟问题解决
|
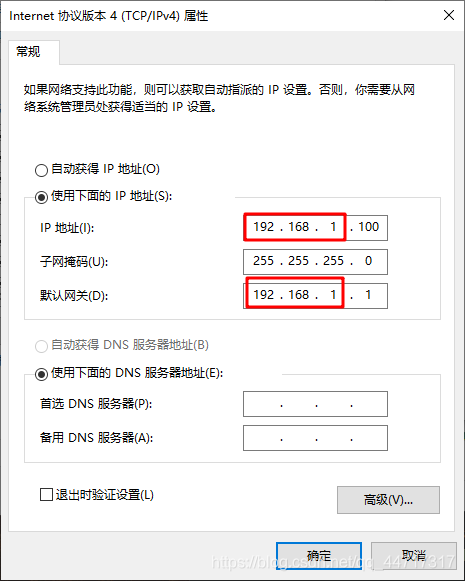
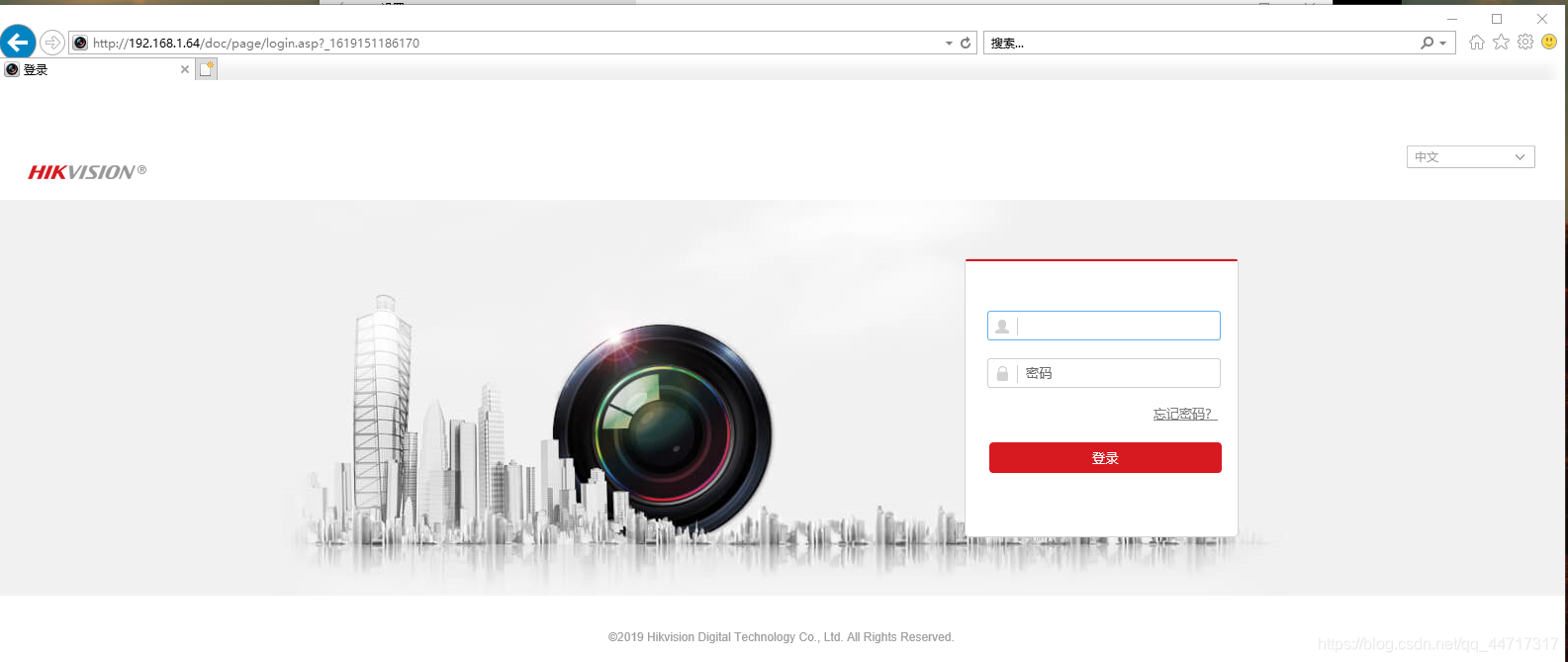
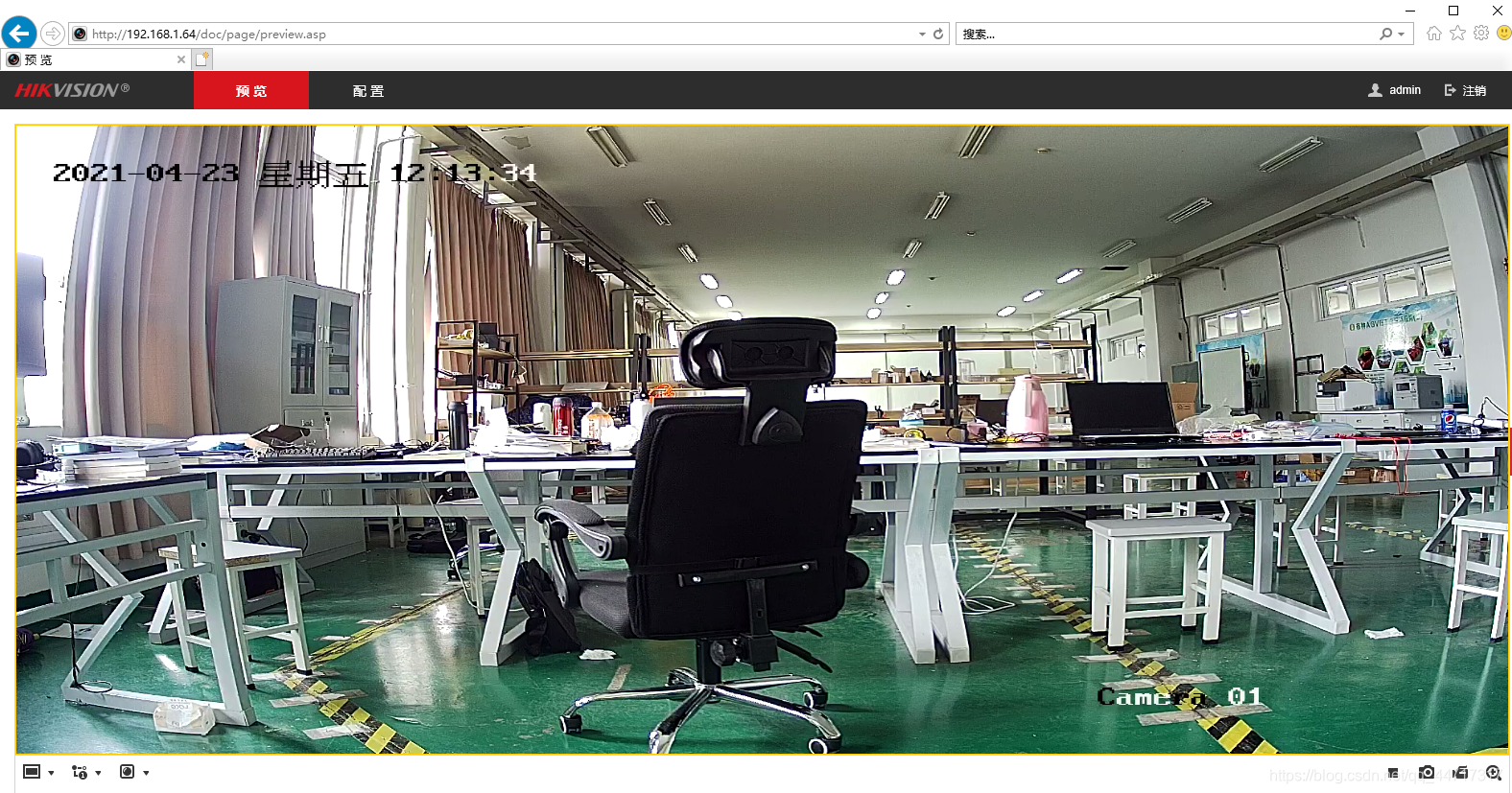
首先,你需要获得hikvision摄像头的密码以及用户名(不知道的可以去打客服电话进行咨询),这里不做介绍; 其次,将电脑的ip设置与hikvision同频段,一般来说,海康威视的ip为192.168.1.64,电脑设置如下: 最后,使用IE浏览器(其他可能不支持),输入ip:192.168.1.64并登陆 输入用户名和密码即可获取视频画面(可以观察到,视频有畸变) 在使用openCV获取监控画面,具体代码如下 url格式为:“rtsp://用户名(一般默认admin):密码@网络IP(海康威视一般为:192.168.1.64)/Streaming/Channels/1” import cv2 url = "rtsp://admin:*******@192.168.1.64/Streaming/Channels/1" cap = cv2.VideoCapture(url) ret, frame = cap.read() while ret: # 读取视频帧 ret, frame = cap.read() # 显示视频帧 cv2.imshow("frame", frame) #等候1ms,播放下一帧,或者按q键退出 if cv2.waitKey(1) & 0xFF == ord('q'): break #释放视频流 cap.release() #关闭所有窗口 cv2.destroyAllWindows()输出画面默认是1080P的高清画面,我们可以写一个resize方法,等比例缩为720P的画面,代码实现如下: def img_resize(image): height, width = image.shape[0], image.shape[1] # 设置新的图片分辨率框架 640x369 1280×720 1920×1080 width_new = 1280 height_new = 720 # 判断图片的长宽比率 if width / height >= width_new / height_new: img_new = cv2.resize(image, (width_new, int(height * width_new / width))) else: img_new = cv2.resize(image, (int(width * height_new / height), height_new)) return img_new然后在显示之前调用该函数进行处理: # 读取视频帧 ret, frame = cap.read() # 显示视频帧 img_new = img_resize(frame) cv2.imshow("frame", img_new) #等候1ms,播放下一帧,或者按q键退出实现效果如下:
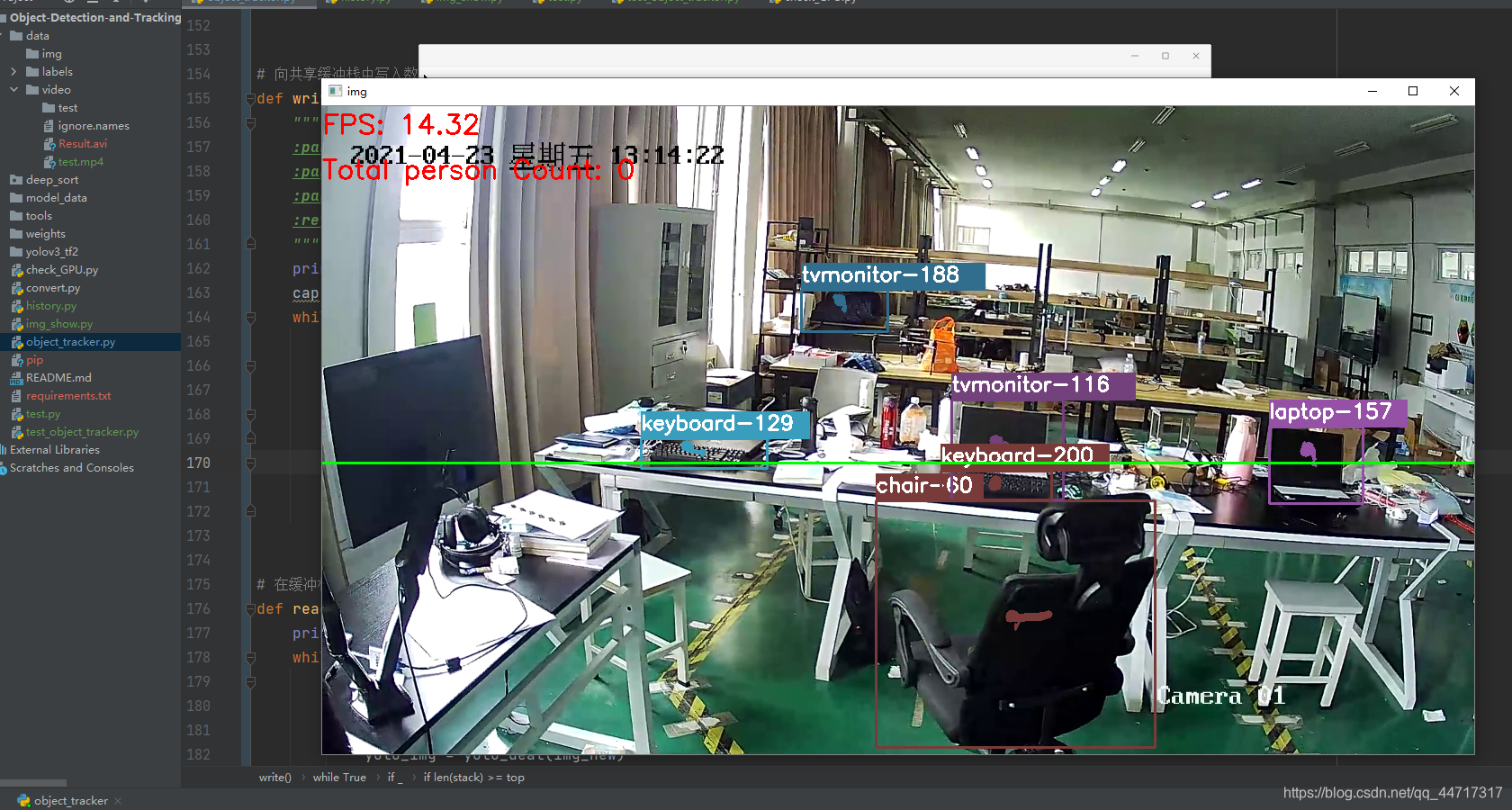
我的毕业设计主要使用YOLOv3+deep-sort实现目标检测与实时跟踪,在这里不做详细的理论介绍,以及具体代码的实现,后面会有相关的博客进行专门系统性的讲述,这里主要讲一种处理内存溢出或者高延迟问题的有效解决方案,在使用模型处理图像之后,每次将处理的画面显示出来,只有三秒的时间(下面为处理后的画面) 然后随后就会发生内存溢出的现象,报错内容如下:
但是,当我使用电脑默认的摄像头,就发现非常的流畅,没有内存溢出的现象,这就十分的诡异,然后我猜测是不是因调用rtsp视频流或取得没帧的分辨率多大,导致检测速度过慢,引起传入帧数与处理帧数不对等引起的内存的溢出,但是我尝试减小了分辨率,甚至于获取的帧图像大小比电脑内置摄像头还有小,结果没有任何的改善; 解决这个问题也寻求网上很多解决方案,以下具体结合各位前辈做一下总结: 使用多线程解决:首先,需要思考,为什么会造成这种现象?有大佬给出这样的解决方案:
FFMPEG Lib对在rtsp协议中的H264 videos不支持? 维基百科: 实时流协议(Real Time Streaming Protocol,RTSP)是一种网络应用协议,专为娱乐和通信系统的使用,以控制流媒体服务器。该协议用于创建和控制终端之间的媒体会话。媒体服务器的客户端发布VCR命令,例如播放,录制和暂停,以便于实时控制从服务器到客户端(视频点播)或从客户端到服务器(语音录音)的媒体流。 FFmpeg 是一个开放源代码的自由软件,可以运行音频和视频多种格式的录影、转换、流功能[1],包含了libavcodec——这是一个用于多个项目中音频和视频的解码器库,以及libavformat——一个音频与视频格式转换库。 这个项目最初是由法国程序员法布里斯·贝拉(Fabrice Bellard)发起的,而现在是由迈克尔·尼德梅尔(Michael Niedermayer)在进行维护。许多FFmpeg的开发者同时也是MPlayer项目的成员,FFmpeg在MPlayer项目中是被设计为服务器版本进行开发。 2011年3月13日,FFmpeg部分开发人士决定另组Libav,同时制定了一套关于项目继续发展和维护的规则 不管怎么说,就是不支持的意思,就是无法实现,我尝试了这位博主的方法,然而并没有解决的问题,效果还是原来的效果,还是三秒,真就是三秒啊~ 参考博客:解决Python OpenCV 读取IP摄像头(RTSP等)出现error while decoding的问题 博主代码实现如下: import cv2 import queue import time import threading q=queue.Queue() def Receive(): print("start Reveive") cap = cv2.VideoCapture("rtsp://admin:[email protected]") ret, frame = cap.read() q.put(frame) while ret: ret, frame = cap.read() q.put(frame) def Display(): print("Start Displaying") while True: if q.empty() !=True: frame=q.get() cv2.imshow("frame1", frame) if cv2.waitKey(1) & 0xFF == ord('q'): break if __name__=='__main__': p1=threading.Thread(target=Receive) p2 = threading.Thread(target=Display) p1.start() p2.start() 使用多进程其实造成内存溢出,主要是由于利用opencv程序调取rtsp视频流时,处理程序要消耗的CPU时间过于长,VideoCapture的read是按帧读取所导致的,解决问题点在于把读取视频和处理视频分开,这样就可以消除因处理图片所导致的延迟。 其实使用多线程当然也可以实现两个动作分开进行,但是为什么几乎没有任何的效果呢? 原因主要是GIL的存在: 维基百科: 全局解释器锁(英语:Global Interpreter Lock,缩写GIL),是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。[1]即便在多核心处理器上,使用 GIL 的解释器也只允许同一时间执行一个线程。常见的使用 GIL 的解释器有CPython与Ruby MRI。 在Windows上为Win thread,完全由操作系统调度线程的执行。一个Python解释器进程内有一个主线程,以及多个用户程序的执行线程。即便使用多核心CPU平台,由于GIL的存在,也将禁止多线程的并行执行。 Python解释器进程内的多线程是以协作多任务方式执行。当一个线程遇到I/O任务时,将释放GIL。计算密集型(CPU-bound)的线程在执行大约100次解释器的计步(ticks)时,将释放GIL。计步(ticks)可粗略看作Python虚拟机的指令。计步实际上与时间片长度无关。可以通过sys.setcheckinterval()设置计步长度。 因此,选择使用多进程 然后要考虑怎样在两个进程中传参的问题: multiprocessing中有Quaue、SimpleQuaue等进程间传参类,还有Manager这个大管家。Quaue这一类都是严格的数据结构队列类型Manager比较特殊,它提供了可以在进程间传递的列表、字典等python原生类型 还要考虑怎样才能达到处理进程可以在读取进程中得到最新的一帧: 其实VideoCapture是一个天生的队列,先进先出。如果要达到实时获得最新帧的目的,就需要栈来存储视频帧,而不是队列。这样的话,Quaue这一大类就都没有可能了,肯定不能用它来传参。提到栈突然想到了python的列表,它的append和pop操作完全可以当”不严格“的栈来用。所以顺理成章地multiprocessing.Manager.list就是最好的进程间传参类型。 再就是传参栈自动清理的问题,压栈频率肯定是要比出栈频率高的,时间一长就会在栈中积累大量无法出栈的视频帧,会导致程序崩溃,这就需要有一个自动清理机制: 设置一个传参栈容量,每当达到这个容量就直接把栈清空,再利用gc库手动发起一次python垃圾回收。这样就不会导致严重的内存溢出和程序崩溃。代码: import os import cv2 import gc from multiprocessing import Process, Manager # 向共享缓冲栈中写入数据: def write(stack, cam, top: int) -> None: """ :param cam: 摄像头参数 :param stack: Manager.list对象 :param top: 缓冲栈容量 :return: None """ print('Process to write: %s' % os.getpid()) cap = cv2.VideoCapture(cam) while True: _, img = cap.read() if _: stack.append(img) # 每到一定容量清空一次缓冲栈 # 利用gc库,手动清理内存垃圾,防止内存溢出 if len(stack) >= top: del stack[:] gc.collect() # 在缓冲栈中读取数据: def read(stack) -> None: print('Process to read: %s' % os.getpid()) while True: if len(stack) != 0: value = stack.pop() # 对获取的视频帧分辨率重处理 img_new = img_resize(value) # 使用yolo模型处理视频帧 yolo_img = yolo_deal(img_new) # 显示处理后的视频帧 cv2.imshow("img", yolo_img) # 将处理的视频帧存放在文件夹里 save_img(yolo_img) key = cv2.waitKey(1) & 0xFF if key == ord('q'): break if __name__ == '__main__': # 父进程创建缓冲栈,并传给各个子进程: q = Manager().list() pw = Process(target=write, args=(q, url, 100)) pr = Process(target=read, args=(q,)) # 启动子进程pw,写入: pw.start() # 启动子进程pr,读取: pr.start() # 等待pr结束: pr.join() # pw进程里是死循环,无法等待其结束,只能强行终止: pw.terminate()实时画面如下: 存入视频帧: nice! 项目实现后续系统讲述… |



【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |