| 目标检测经典工作发展(超详细对比):R | 您所在的位置:网站首页 › yolo与rcnn的区别 › 目标检测经典工作发展(超详细对比):R |
目标检测经典工作发展(超详细对比):R
|
序
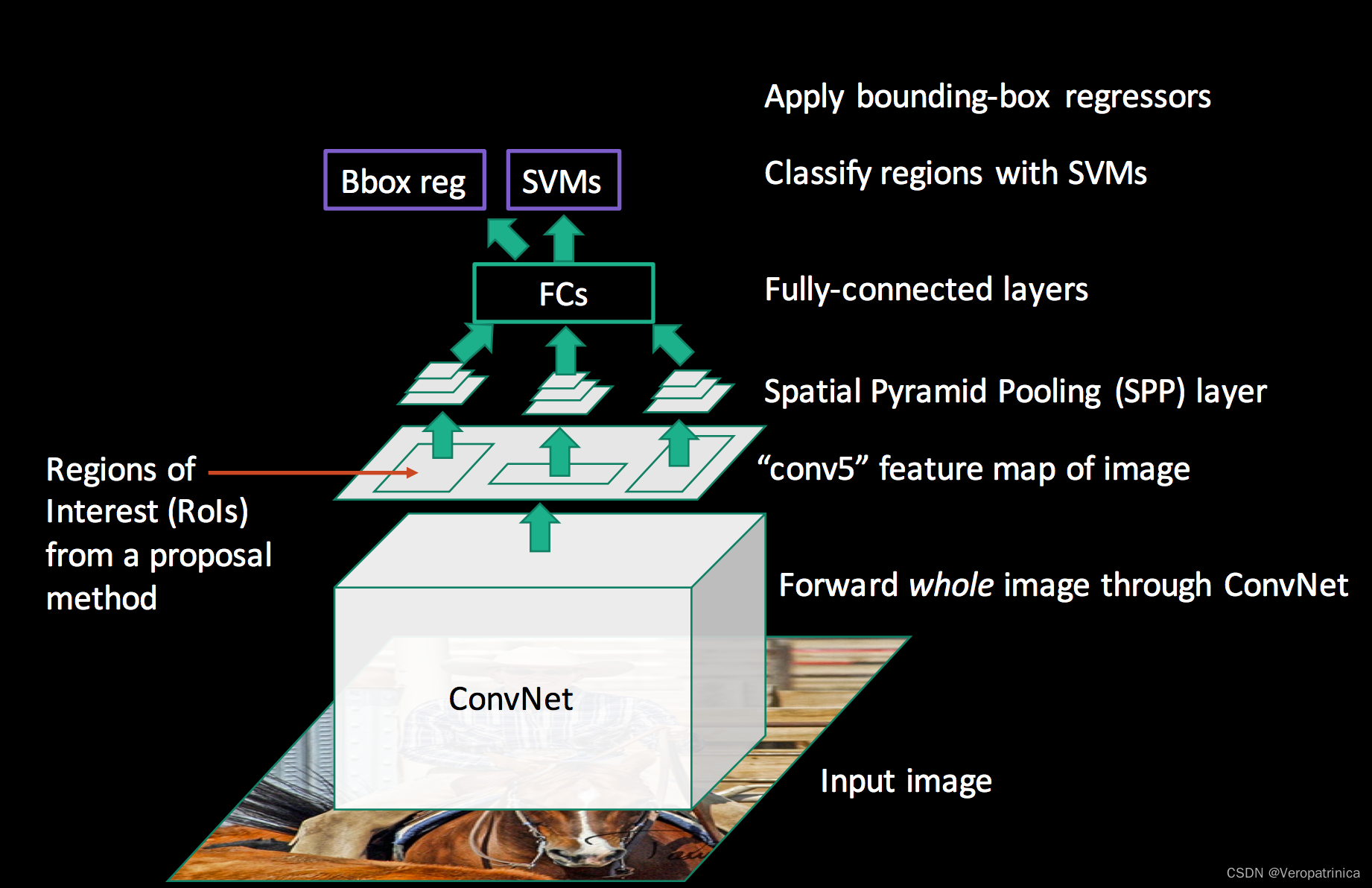
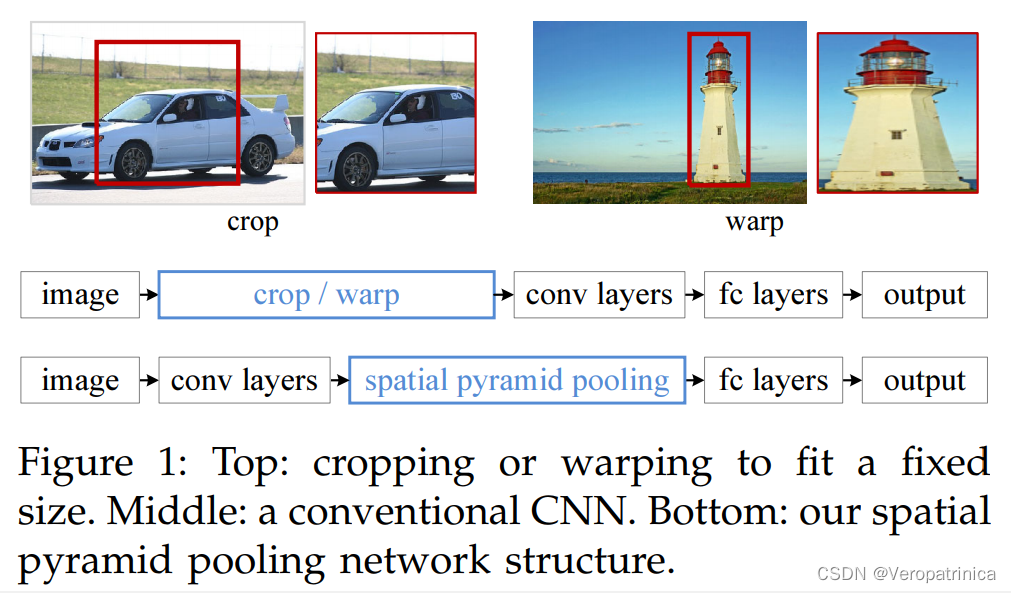
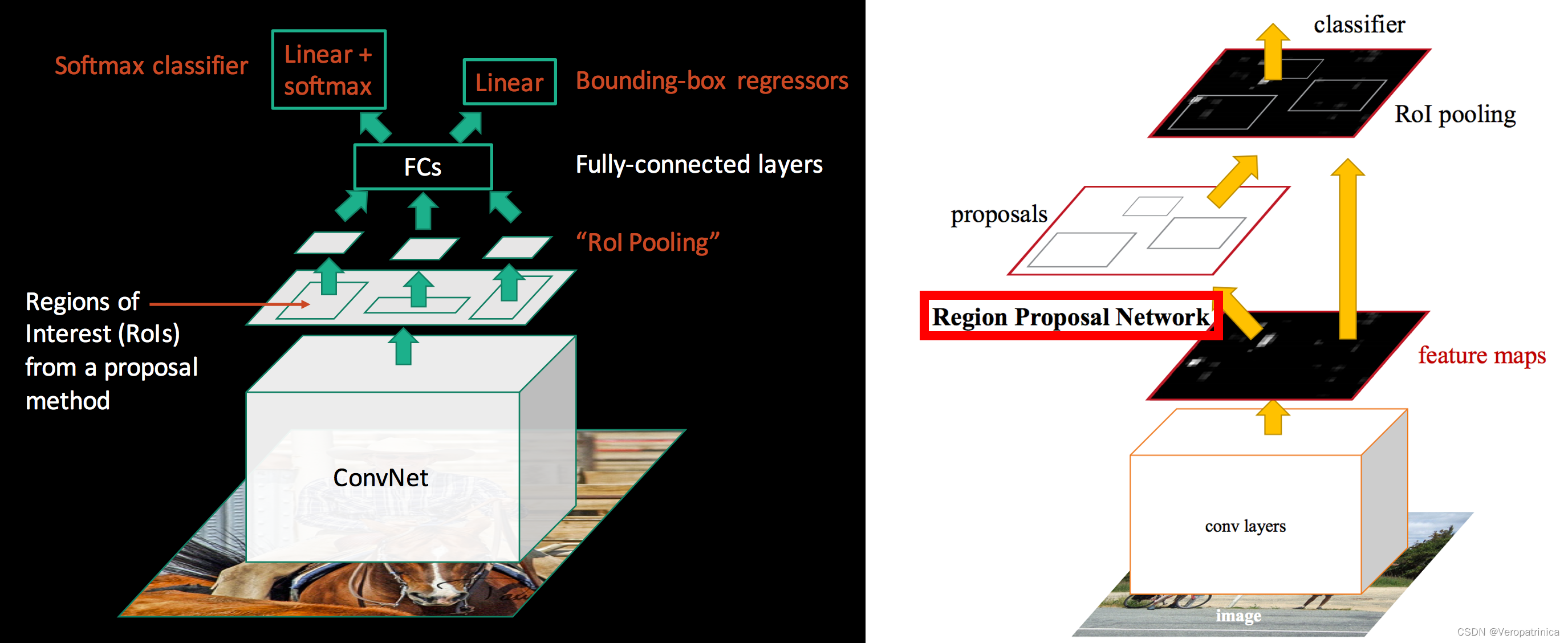
网上关于两阶段目标检测(two-stage object detection)的几个经典工作R-CNN,SPPNet,Fast R-CNN,Faster R-CNN的发展,各自的优缺点缺乏一个比较清楚的描述,大部分文章讲的比较细节,虽然有助于更为详细地了解文章,但是让读者在短时间内对各个文章有一个详细的理解。本文主要对网上的资料进行整合,希望让读者能较快地理解几篇文章的优劣。 R-CNN本节会介绍R-CNN基本流程以及文章的缺点。最后对其中几个重要步骤进行补充说明 基本流程R-CNN的基本流程如下,主要的步骤如下: 提取区域候选(extract region proposals):使用selective search方法提取2000个候选目标 对每个候选目标warp到一个固定的大小(例如224x224),主要包括直接对图像进行resize,或者是进行crop,然后对空白部分进行填充。 CNN本身实际上是能适应不同大小的图片输入,但是特征最后要过fc,因此需要固定的大小。这一点之后在SPPNet中进行解决 计算CNN特征(compute CNN features):用神经网络计算经过warp的区域候选的特征图分类(classify regions):对提取到的特征输入到SVM中进行分类可能会产生疑问:直接在网络最后接softmax输出分类概率不行吗?为什么需要重新训练一个SVM进行分类呢?回答:论文中说加SVM效果好!(但是实际上在Fast-RCNN之后都用不上嘞!啊哈哈) 非极大值抑制(NMS,non-maximum suppression):删除重复的候选框 位置精修(bounding box regression):使用一个回归器(几层fc)来修正候选框的位置 为什么直接使用selective search得到的region proposals的结果作为最终的bounding box呢?当然是因为结果不准确啦,拿个网络来精细调整一下位置肯定不亏,嘿嘿 以上就讲完了RCNN整体的流程,最后用一张更直观的图来展示: 这部分介绍第一个步骤中使用的提取region proposals的方法——selective search,其属于传统算法,速度很慢,这一个部分在Faster-RCNN中被替换成神经网络。下面是其具体步骤: 对图像进行oversegmented 的图像分割计算邻近区域的相似性,包括颜色、纹理等等合并相似性高的区域,得到更大的区域并假如到区域集合中重复2、3过程直到图片变成一个区域。至此得到的区域集合就是我们要的region proposals详细过程可以参考: https://www.jianshu.com/p/99e121c3beb8 这一部分介绍第五步用到的非极大值抑制方法。selective search之后得到的候选框有2000多个!可以上一张图看出很多框圈着同一个物体,而NMS的思想就是想保留置信度最高的框,把周围重叠度高(交并比IoU高)的其他框给删除,从而大大减少候选数量 详细过程参考:https://blog.csdn.net/zouxiaolv/article/details/107400193 观察RCNN的整体流程我们可以看出其具有以下几个缺点: 提取proposals用的selective search,速度慢且很多无用的proposals重复计算特征:每一个proposals都需要通过CNN提取特征,速度会大大减慢需要resize操作:proposals在输入的时候需要经过warp操作,可能会丢失原有的结构信息串行结构:先对特征进行分类,然后再对bounding box位置进行回归。这个问题本质上是因为分类的时候需要重新训练一个SVM,而回归bounding box坐标是使用fc,二者不能共用,导致速度比较慢 SPPNet(修改CNN特征提取过程)RCNN最主要的时间开销实际上都花在了对2000个proposals进行特征提取的地方。而SPPNet主要解决这个问题。 主要流程SPPNet的主要流程如下: 可以看到相较于RCNN,其主要的修改部分有两个: 从原来需要多次特征提取变成一次特征提取为了解决上一点带来的“不同感兴趣区域(RoI,region of interest)对应特征的维度不同,而不能使用同一个fc”的问题,提出了spatial pyramid pooling(SPP)具体的流程从下图中第二行(RCNN)变成了第三行(SPPNet),也就是从“warp→特征提取”变成了“特征提取→SPP”。 上述主要修改的两点中,第一点将多次CNN提取特征变为一次这个过程比较直观,不再详述。因此主要对第二点:SPP层进行讲解。SPP层的目标是为了将不同分辨率的特征都能映射到相同的维度上以供后续fc进行分类。它的思路如下图: 下图展示了一个例子: SSPNet有以下两个优点: 让最后的分类器能适应任何尺寸的proposals:避免裁剪导致的信息丢失,或者是变形导致的位置信息扭曲只需要对图像特征提取一次,大大加速提出spp,将不同分辨率的特征都映射到相同维度上 缺点缺点实际上就是针对RCNN未解决的部分: 提取proposals速度慢串行结构:先对特征进行分类,然后再对bounding box位置进行回归。 Fast-RCNN(改版spp+分类与回归二合一)Fast-RCNN主要整合了proposals的分类和bounding box的回归这两个过程,整体进行了加速。 主要流程论文中给出的图如下: 我们主要介绍第一点修改,第二点修改比较直观,不做详述。RoI pooling听着是新提出的网络层,实际上就是spp的简化版(经典改一张就是原创卡组) !本质上是取了一个尺度的spp,见下图应该就很清楚了 Fast-RCNN有以下两个优点: 最后分类和回归两个步骤变成multi-task提出RoI pooling,解决proposals分辨率不同影响最后fc求解的问题(感觉SPPNet已经解决过了捏?科研人的辛酸是这样的) 缺点缺点实际上就是针对RCNN未解决的部分(又能少一个了): 提取proposals速度慢 Faster-RCNN(修改提取区域候选的过程)Faster-RCNN就是解决最后一个问题:提取proposals速度慢的问题了!前面的网络使用的都是seletive search作为候选提取算法,而这个地方就是想采用神经网络来代替这个过程。 主要流程Faster-RCNN和之前方法的对比如下图: 因为之前的方法画图的时候实际上没有把提取region proposals的过程画出来,他们都是在使用selective search之后将proposals映射到特征图上(也就是左图的RoI区域),而右图是Faster-RCNN完整的过程。可以看到和之前方法相比的改变的地方就只有一点: 用RPN代替传统的selective search方法来进行候选区域提取 RPNRPN是为了从图像中提取多个候选区域,其基本思想是模式匹配的方法。对每种模式去回归这个模式下是否包含物体的概率以及对bounding box的修正。下图是一个概览图。 假设特征提取之后的特征图维度为40x60x512,分成两个分支,分别得到 分类分数,维度为40x60x9x2,代表原图上40x60个点上,这9个anchor分类为前背景的概率(下分支)对bounding box的坐标进行修正的参数。维度为,40x60x9x4,代表原图上40x60个点上,这9个anchor的bounding box的偏移量(上分支)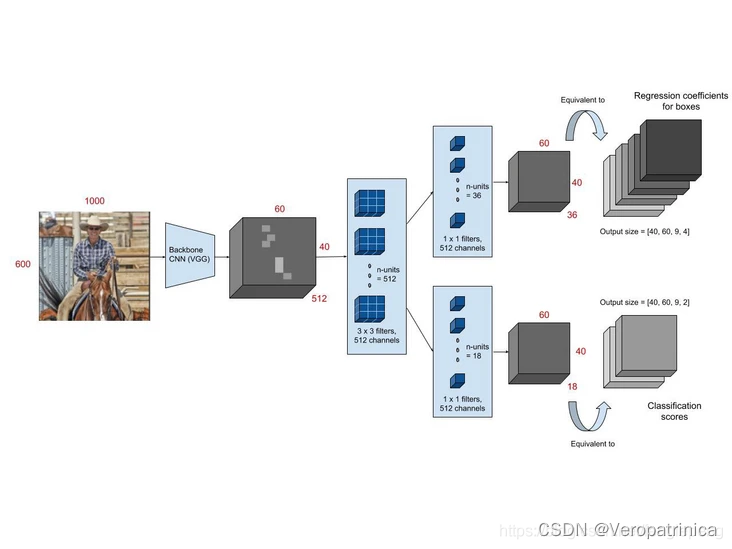
之后用bounding box修正参数进行修正就能得到region proposals啦!以上就是RPN的全过程 优点Faster-RCNN的优点就主要体现在用RPN替代了传统提取区域候选算法,大大加速! 缺点虽然看来已经解决了RCNN的四个缺点。但是这不代表Faster-RCNN就是完美的了,后续也有很多工作在这上面进行改进,这些就超出本文的范围啦! 最后感谢各位看到最后! 参考资料 https://jhui.github.io/2017/03/15/Fast-R-CNN-and-Faster-R-CNN/https://analyticsindiamag.com/r-cnn-vs-fast-r-cnn-vs-faster-r-cnn-a-comparative-guide/https://zhuanlan.zhihu.com/p/370407951https://blog.csdn.net/weixin_43624538/article/details/87966601https://blog.csdn.net/qq_35586657/article/details/97885290https://www.cnblogs.com/kk17/p/9748378.html#25-%E5%AF%B9%E6%96%87%E7%AB%A0%E7%9A%84%E4%B8%80%E4%BA%9B%E6%80%9D%E8%80%83https://blog.csdn.net/fenglepeng/article/details/117898968 |

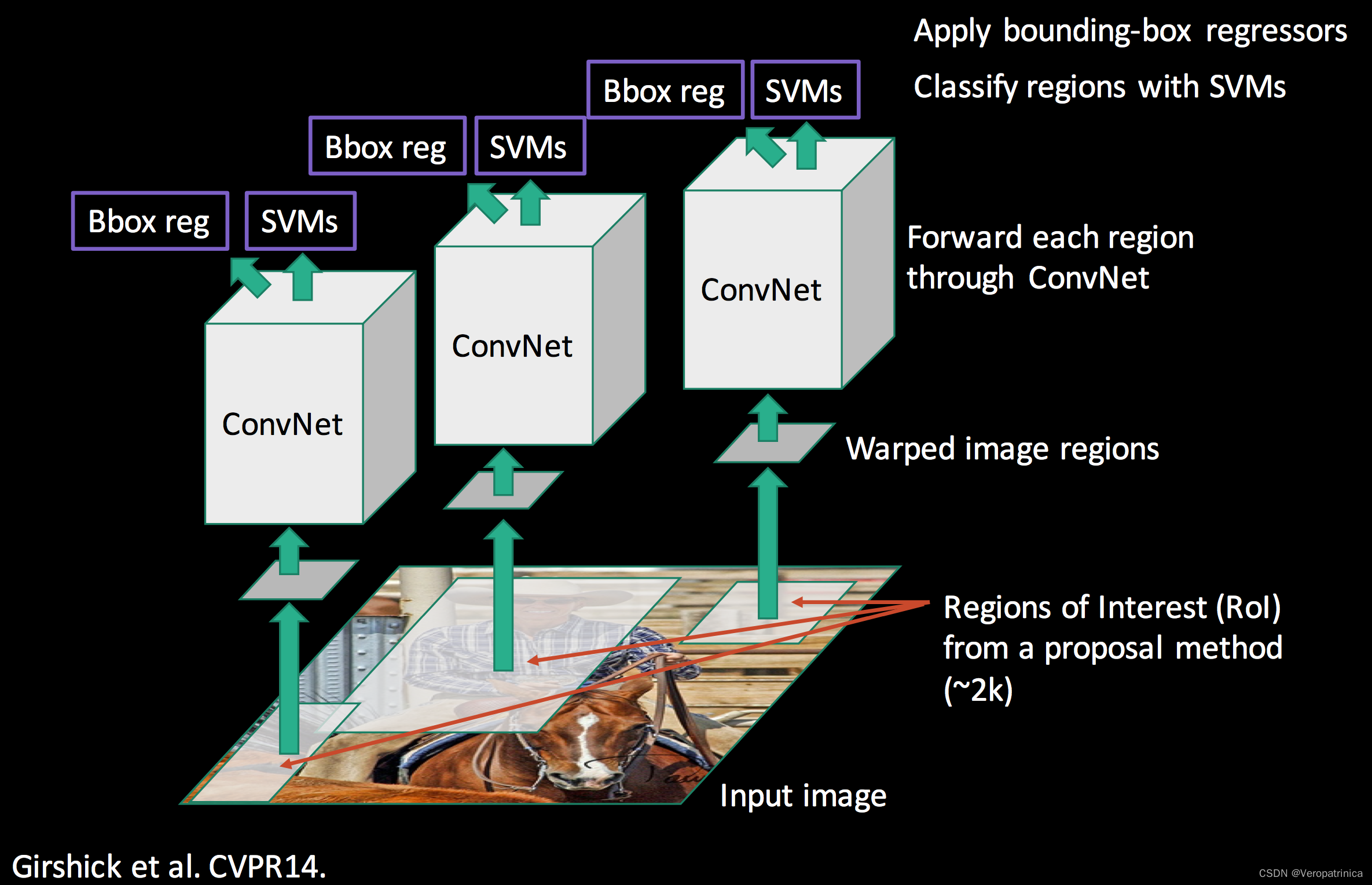


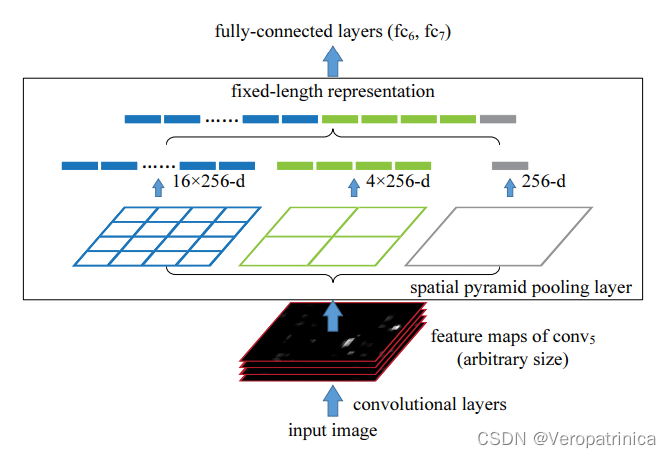 提出了多个尺度的池化层,来提取不同粒度的特征。对于任意分辨率的特征,会将它们划分成相同数目的小块进行max pooling。例如图中所示,不管特征图大小怎样,都会划分成16、4、1个小块,于是输出是恒定为(16+4+1)*256维的特征,并将其送到fc中进行分类。
提出了多个尺度的池化层,来提取不同粒度的特征。对于任意分辨率的特征,会将它们划分成相同数目的小块进行max pooling。例如图中所示,不管特征图大小怎样,都会划分成16、4、1个小块,于是输出是恒定为(16+4+1)*256维的特征,并将其送到fc中进行分类。 左图是输入图片和对应的经过selective search选择出来的一个region proposal,右图是将这个proposal映射到特征图上的位置。
左图是输入图片和对应的经过selective search选择出来的一个region proposal,右图是将这个proposal映射到特征图上的位置。 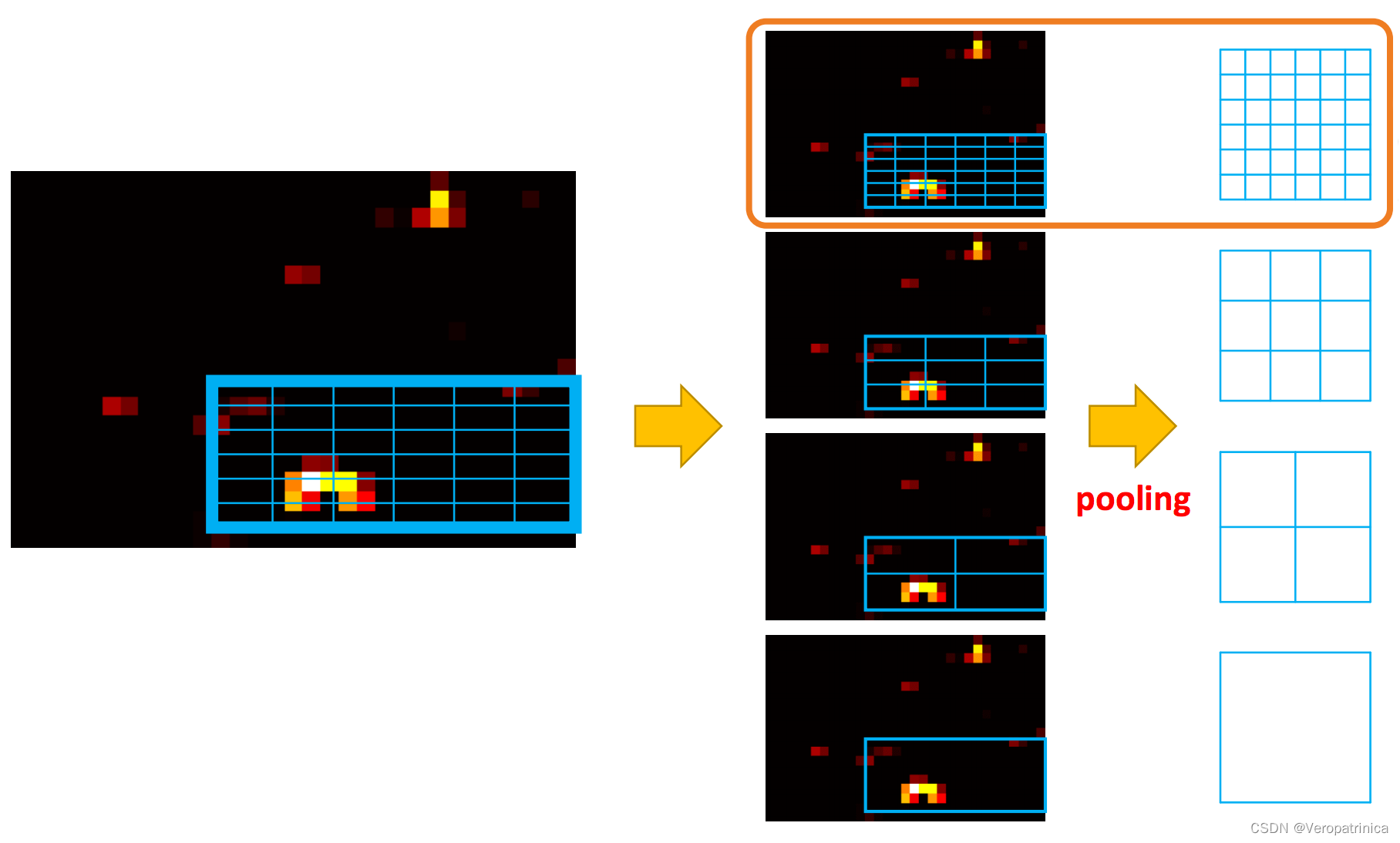 上图就是对其按照不同的区域划分进行spp的结果,得到特征之后会把这些特征concat之后送到最后的fc中(最后这一步图中没画出来)。
上图就是对其按照不同的区域划分进行spp的结果,得到特征之后会把这些特征concat之后送到最后的fc中(最后这一步图中没画出来)。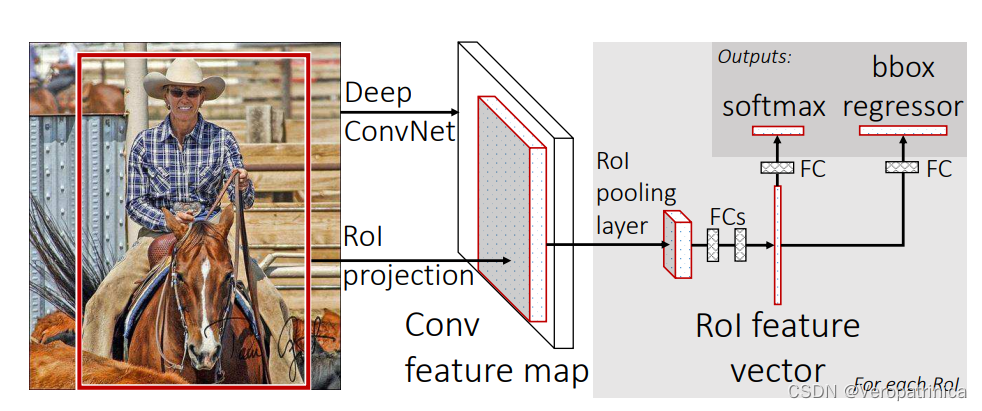 这个图其实把前面提取region proposals的过程给省略了。要主要的是Fast RCNN仍然使用的是selective search来生成proposals的。如果光看上面的图可能不好看出来和之前工作的区别,可以将它展示成我们都比较熟悉的样子:
这个图其实把前面提取region proposals的过程给省略了。要主要的是Fast RCNN仍然使用的是selective search来生成proposals的。如果光看上面的图可能不好看出来和之前工作的区别,可以将它展示成我们都比较熟悉的样子: 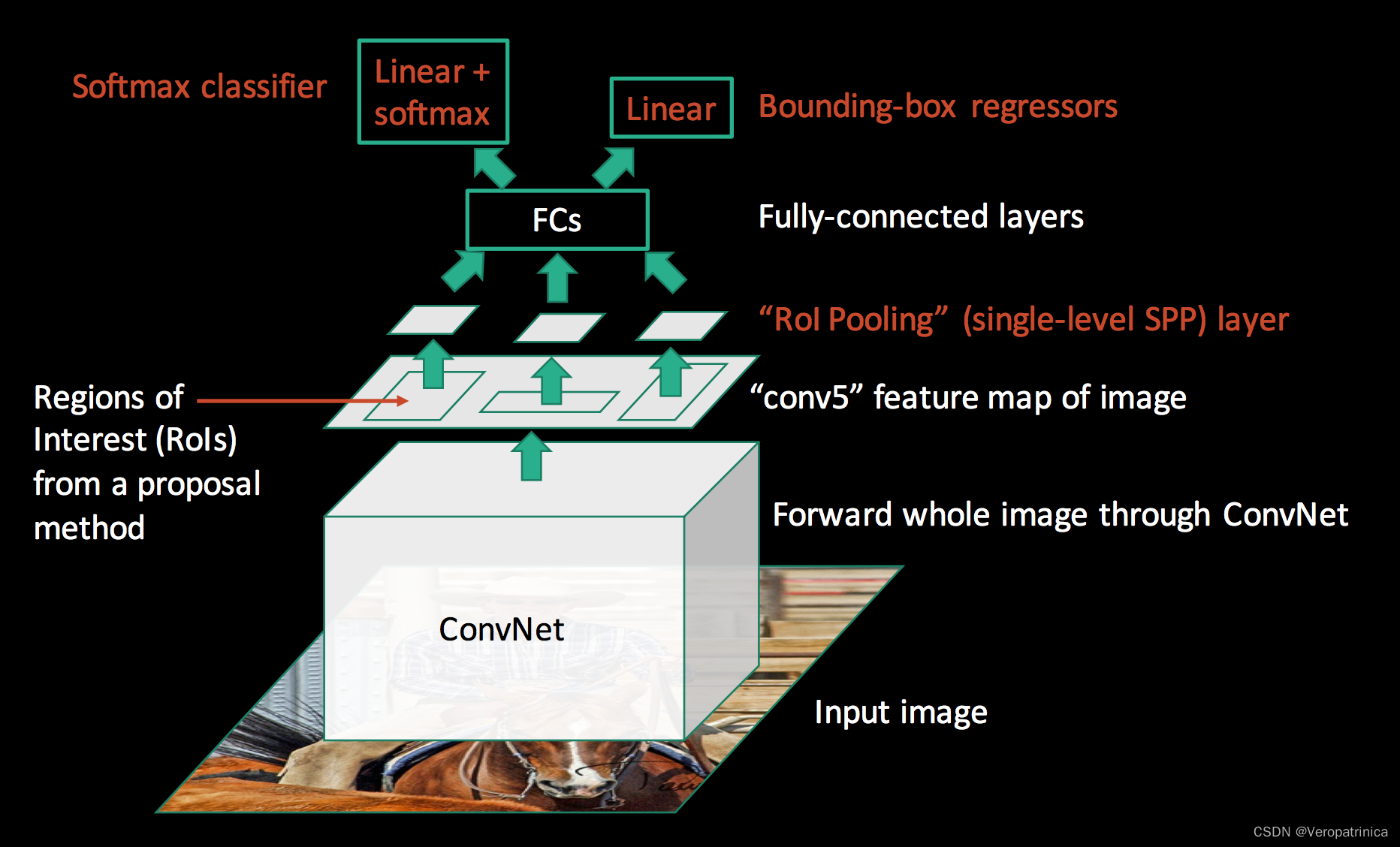 在转化之后,我们可以很明显看出Fast-RCNN和SPPNet的区别。Fast_RCNN主要的修改有以下两点:
在转化之后,我们可以很明显看出Fast-RCNN和SPPNet的区别。Fast_RCNN主要的修改有以下两点: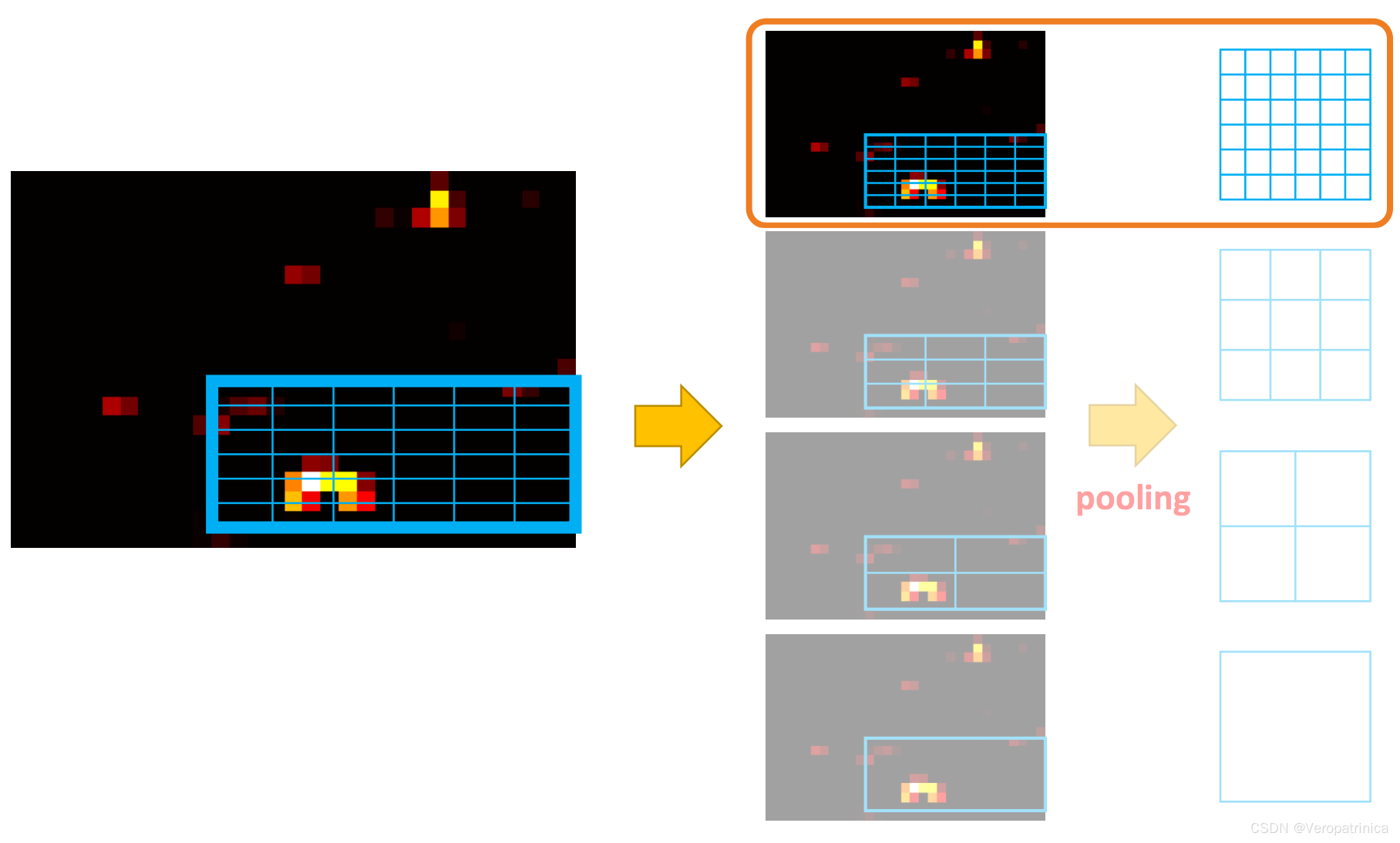 下面这个过程给出了一个具体计算的例子(其实这也是spp中其中一个尺度的计算过程):
下面这个过程给出了一个具体计算的例子(其实这也是spp中其中一个尺度的计算过程): 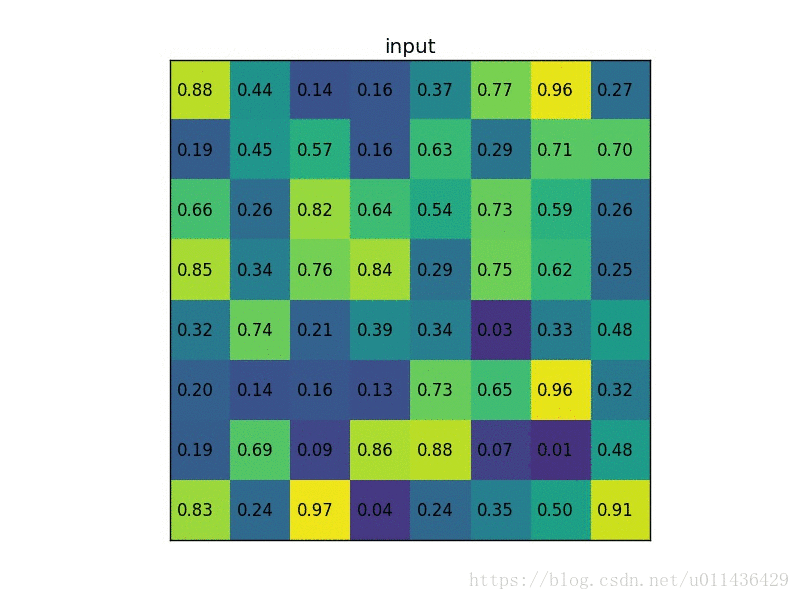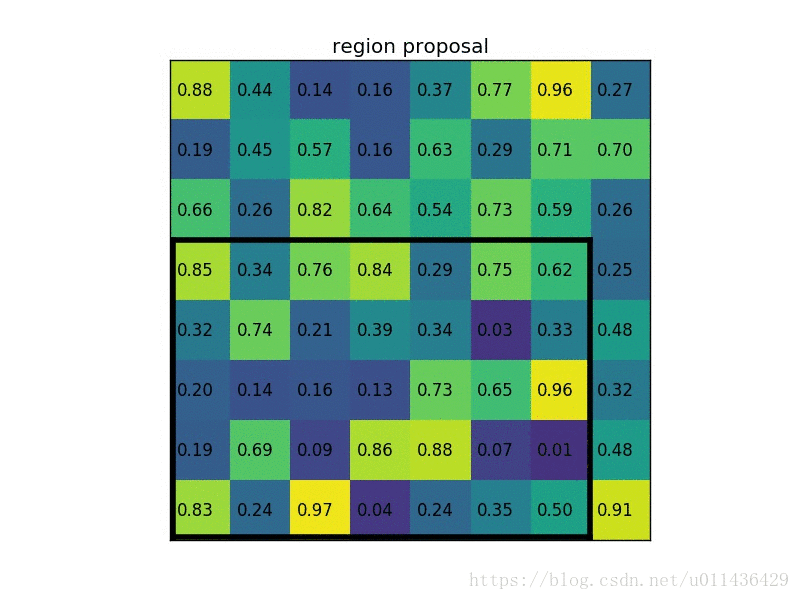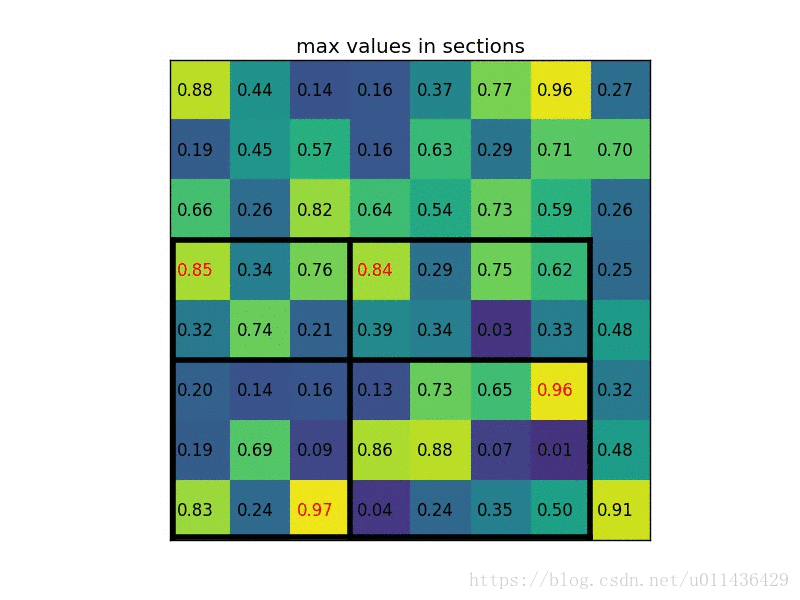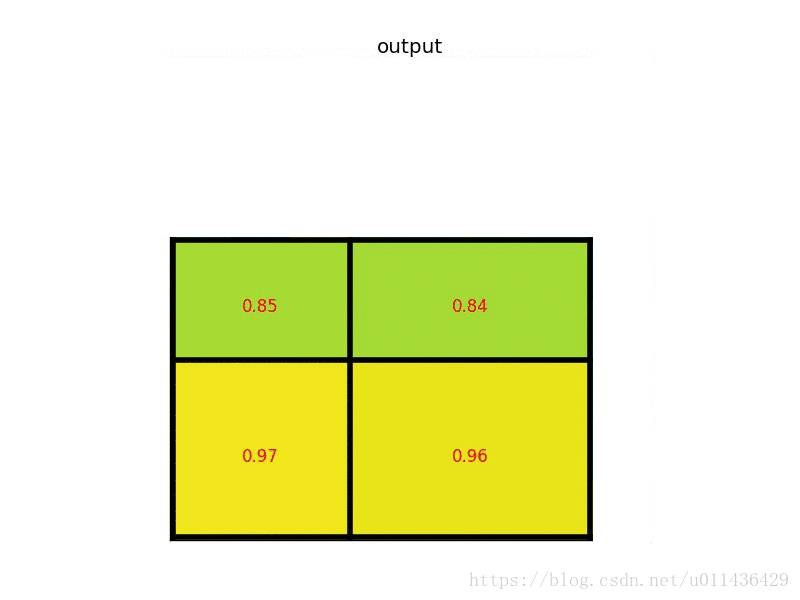
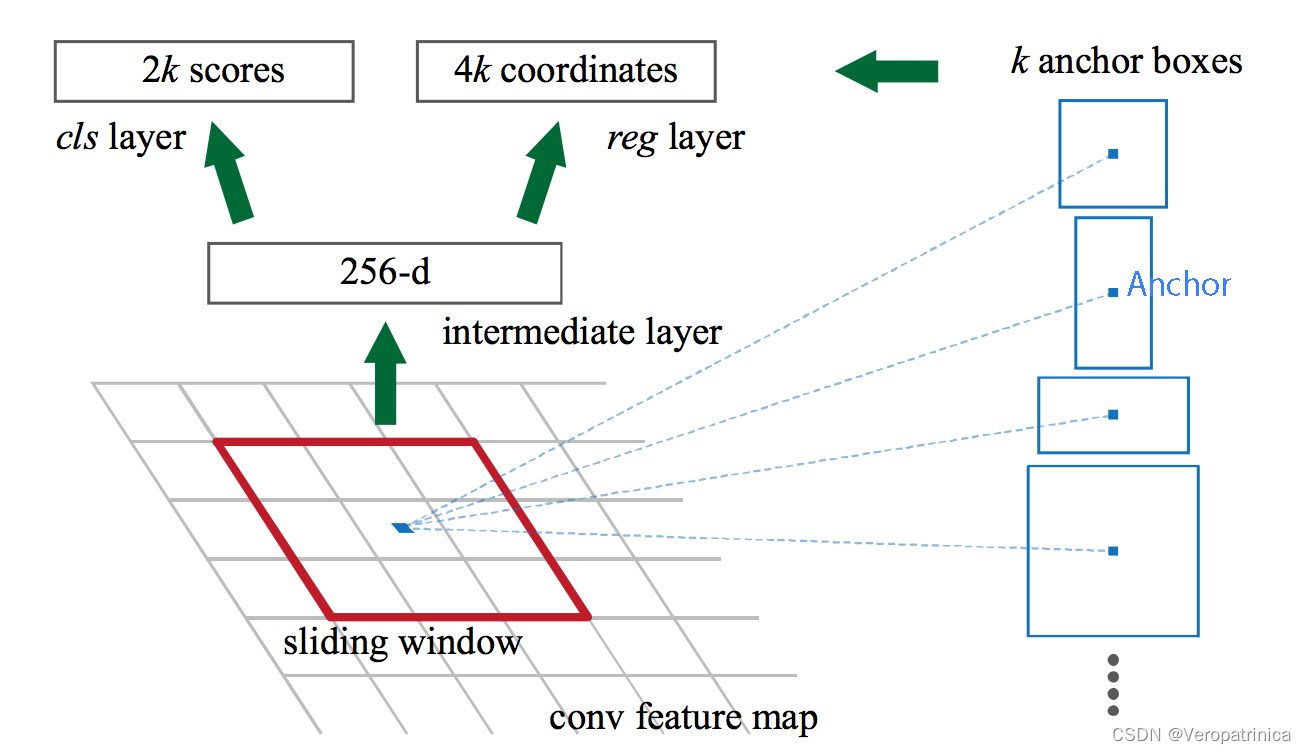 下面来举一个例子会更加清楚一点:对每一个像素,以这个像素为中心,预先设定九种候选框(在这里叫anchor)。这样在经过特征提取之后,特征图上的一个点可以理解成对应原图中一个像素位置的9种anchor
下面来举一个例子会更加清楚一点:对每一个像素,以这个像素为中心,预先设定九种候选框(在这里叫anchor)。这样在经过特征提取之后,特征图上的一个点可以理解成对应原图中一个像素位置的9种anchor 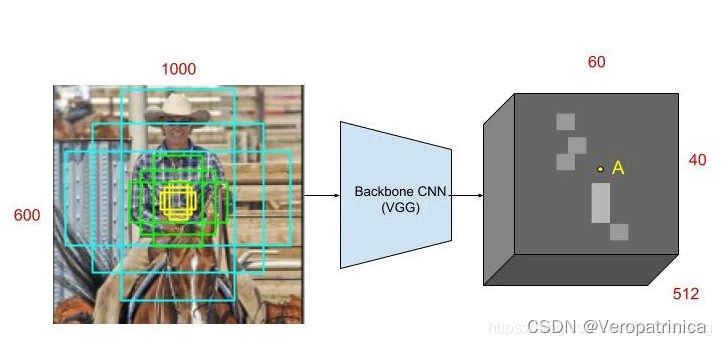 下面这个图展示地更清楚一点,上图中灰色的特征图上每一个点会对应下图上红色点的位置(每个位置会有9个anchor)。
下面这个图展示地更清楚一点,上图中灰色的特征图上每一个点会对应下图上红色点的位置(每个位置会有9个anchor)。 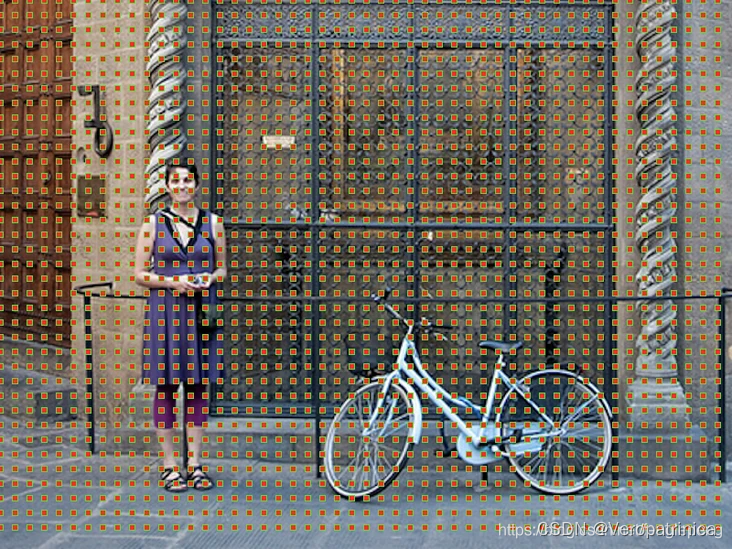
【本文地址】