| XGboost参数、案例 | 您所在的位置:网站首页 › xgbtrain参数 › XGboost参数、案例 |
XGboost参数、案例
|
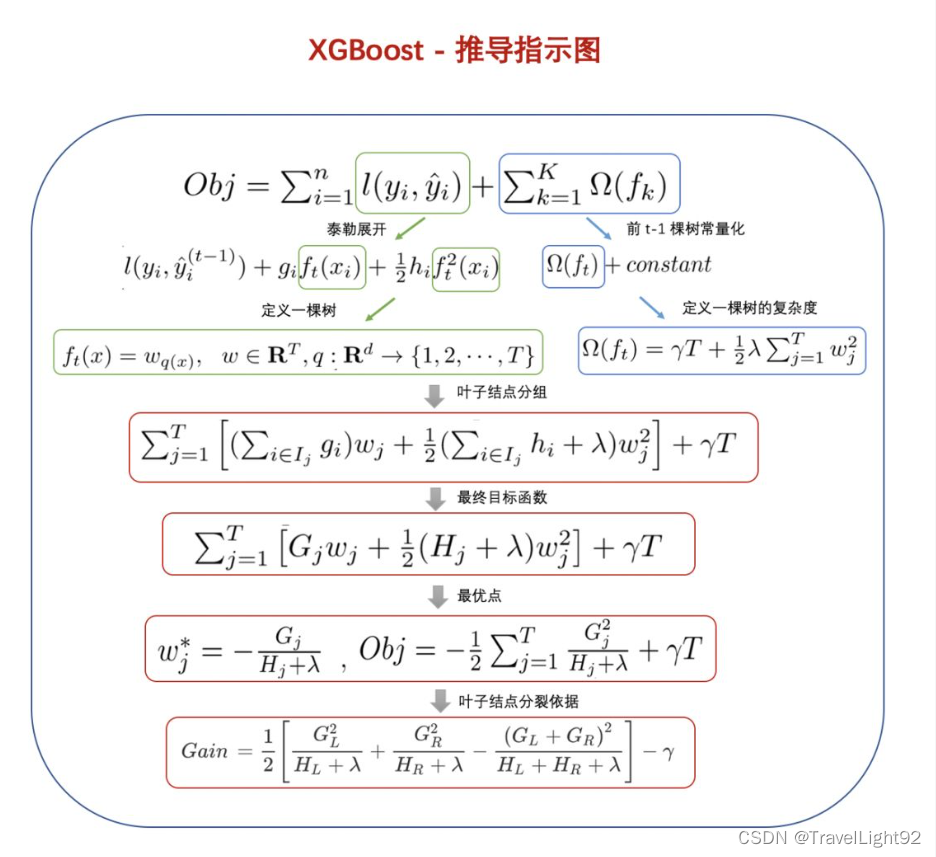
本文不含XGboost的Loss定义、分裂原理,但会讲一下比较难理解的,需要对原理非常清楚,不然你可能不知道我要表达的意思--->主要写一些难懂的参数解释和实际应用,顺便做个小笔记,自己忘了也可以来抄一下,因参数很多,挑一些主要的说: 内容: 1.原生接口案例,参数解释 2.sklearn接口GridSearchCv 3.原生接口调参与sklearn调参对比,xgboost.cv方法 首先还是要牢记几个公式:
摘自:XGBoost超详细推导,终于讲明白了!-CSDN博客 一、Xgboost原生API:1.1二分类例子主要代码: # 完整例子:直接复制可用 import xgboost as xgb from sklearn import datasets import numpy as np np.set_printoptions(suppress=True) # 取消科学计数法显示 # 1.随便找个分类数据集,乳腺癌数据 # 友情提示,多次运行结果有差异,因为你划分数据集没设random_state x,y = datasets.load_breast_cancer(return_X_y=1) from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(x,y,shuffle=True,stratify=y) # stratify平衡划分 # 2.纯演示,自定个简单评估函数,其实eval_metric里面也有 # 演示分类问题是因为分类往往复杂一些,这个自定义评估函数就是RMSE,只是演示如何自定义 def my_feval(y,yhat): return 'rmspe',np.sqrt(np.mean((y - yhat.get_label()) / y) ** 2) # 3.提前写好模型参数 param_dict = {'booster': 'gbtree', # 可选gbtree\gblinear\dart # 'device':''cpu' # 默认使用CPU计算 'objective': 'binary:logistic', # 返回概率值,非标签 'eval_metric': ['auc','error'] # 默认是objective的损失函数,可自己加一些进去 'max_depth': 5, #最大深度 'alpha':0.1, # L1正则化系数 'lambda': 10, # L2正则化系数 'subsample': 0.8, # 样本不放回抽样比例 'colsample_bytree': 0.8, # 特征列抽样比例 'min_child_weight': 1, # 见下图 'eta': 0.025, # 原生接口中eta为学习率 'seed': 1024, # 指定随机种子,在行、列抽样中有用 'nthread': -1, # 'num_class':5 # 仅在多分类时,指定类别个数,此时'objective': 'multi:softmax' 'gamma': 0.1, # XGBOOST loss中的树结点个数,子节点分裂否与gamma相关 'silent': 1 # 为0则打输出过程信息,为1则不输出过程信息, # 实测该参数与train 中的verbose_eval冲突,建议直接忽略 } # 4.将训练、测试(验证)数据转为DMatrix dtrain = xgb.DMatrix(x_train, label=y_train) dtest = xgb.DMatrix(x_test, label=y_test) # 5.用列表包元组的方式,把评估数据放进去 evals_list = [(dtrain, 'train'), (dtest, 'eval')] #很多人喜欢叫watchlist # 6.原生接口所有参数: # xgboost.train(params, dtrain, num_boost_round=10, evals=[()], # obj=None, feval=None, maximize=Fals[e, # early_stopping_rounds=None, evals_result=None, # verbose_eval=True, xgb_model=None, callbacks=None) # # ———————————————— # 7.常用参数 model = xgb.train(param_dict , dtrain, num_boost_round=1000, evals=evals_list , early_stopping_rounds=50, # feval=my_feval, # 自定义的评估函数 verbose_eval=20, # xgb_model='d:/xgboost_saved.json' ) # 8.保存模型,以后可以继续训练或者增量学习,用其方法保存都行 # model.save_model('d:/xgboost_saved.json') # 9. 获取结果 y_ = model.predict(dtest) # 返回每个样本的预测结果 # 如果有early_stop,predict的时候默认会用最佳成绩,不需特别指定 # 硬要指定,如下 # y_ = model.predict(dtest,iteration_range=(0,model.best_iteration+1)) # 左闭右开,正好带上最后最佳的一个迭代成绩 print(y_) # 10.转为标签值 y_2 = (y_ >0.5)*1 #通过小技巧转为标签值 print(y_2) print((y_2 ==y_test).mean()) # 准确率 # 11.特征重要性 from xgboost import plot_importance import matplotlib.pyplot as plt plot_importance(model) plt.show()
1.2 objective常用,如果找不到要用的,先去官网看,不行自己定义一个损失函数。 objective:用于指定学习任务及相应的学习目标,常用的可选参数值如下: “reg:linear”,线性回归(默认值)。 “reg:logistic”,逻辑回归。 “binary:logistic”,二分类的逻辑回归问题,输出为概率。 “binary:logitraw”,二分类的逻辑回归问题,输出为w.Tx。 “multi:softmax”,需设置参数num_class用于指定类别个数,返回类别标签 “multi:softprob”,与softmax一样,但是输出为ndata*nclass的向量, 可将其转化为ndata行nclass列的矩阵,每行数据表示属于每个类别的概率 'count:poisson':计数问题的poisson回归,输出结果为poisson分布1.3 min_child_weight的个人理解
1.3.2 Gamma的解释: 一个父亲结点是否分裂,取决于分裂后是否有gain,如果Gamma太大,可能很多结点就不分裂了,可能会欠拟合,很多文章解释为:模型保守,一个模型有GAMMA和gamma=0。
1.4 原生Train接口对比SKlearn.fit接口 优势: 可以使用专门的DMatrix,将数据变为块,速度快,虽然实际测试并没见快很多,也可能是数据必须极大的时候才体现出来,可在训练中输出各种LOSS值。 劣势: 参数字典要自己写出来,谁会一直记得每个参数叫什么名字,要时不时抄一抄; 基本上只能手动调参,无法用GridSearchCV之类的调参。 1.5 train的主要参数 xgb.train:( import xgboost as xgb 1.params: 字典形式,传入基本参数,例如: param_dict = {'booster': 'gbtree', 'objective': 'binary:logistic', 'eval-metric': 'auc', 'max_depth': 5, 'lambda': 10, 'subsample': 0.75, 'colsample_bytree': 0.75, 'min_child_weight': 2, 'eta': 0.025, 'seed': 0, 'nthread': 6, 'gamma': 0.15, 'learning_rate': 0.01, 'scale_pos_weight':100, # 二分类的话,0:1样本比例 'tree_method':'auto', 'base_score':0.2 # 初始值,可手动设 }2.dtrain: DMatrix, 得提前将x_trian,y_trian,x_test,y_test转为DMatrix,DMatrix还有其他参数可自行研究 dtrain = xgb.DMatrix(train_x, label=train_y) dtest = xgb.DMatrix(test_x, test_y)3.num_boost_round: int = 10(default),多少棵树 4.evals: 想要看到训练、测试集中的损失函数、评估函数减少情况,可以两个都写上去,对数据很熟,只写test\valid的,没有测试数据,只写train的就行。 evals = [(dtrain, 'train'), (dtest, 'eval')] # 这样可以显示训练、测试的损失结果5.obj: (ndarray, DMatrix) -> tuple[ndarray, ndarray] | None = None自定义目标(损失函数),必须二阶可导,先看看官网,没有再自己写。 # 自定义目标|损失函数 # 一般回归、分类等常规情况不需要用,看说明,应该是跟自定义评估函数差不多的形式 def my_loss(y_true,y_pred): return ((y_true-50)-(y_pred.get_label()-50))**26.eval_metric使用自带的评估函数,feval:自定义评估函数,如果显示地指定了评估函数,evals必须要有,不然报错,默认会用objective里面的目标函数的损失作为评估函数,比如回归就是MSE不停下降,分类就是logloss不停减少,feval可以和自带的eval_metric一起存在,不影响; 因为eval_metric太多,并且和sklearn的scoring不同,建议看官网: XGBoost Parameters — xgboost 2.0.3 documentation 这个页面搜索 eval_metric 按照说明文档的顺序,同参数13,自定义评估函数。 13.custom_metric: (ndarray, DMatrix) -> tuple[str, float] | None = None 可以看到,feval现在不建议用,换名字了,不过也就报个警告。 # UserWarning: `feval` is deprecated, use `custom_metric` instead # 简单示例 #自定义评估函数: def my_metic(y_true,y_pred): return 'meme',(np.log(y_true)-np.log(y_pred.get_label())**27.maximize: bool | None = None(default False) 评估函数是否最大化,比如feval=auc,accuracy之类的,可以设为True,回归一般都是MSE相关的,好像这参数不需要用,模型会自动判断任务类型,比如eval_metric有个error(1-accuracy)和auc,这就不好搞了,干脆不写算了。 8.early_stopping_rounds: int | None = None 损失函数多少次迭代没有变化,则停止训练,可以将num_boost_round 设置大点, 可以提前终止不必要的训练; 需要有evals,如果有多个数值,会用evals最后一个tuple的数值, 会用eval_metric最后一个自定义的评估函数计算 如果设置了early_stopping_rounds=50, 则xgb.best_score , xgb.best_iteration,best_ntree_limit属性可用 # 1.xgb.best_score:经过实际测试,如果设置了评估函数metric或者feval, 则best_score是评估函数、数据集中最后一个的最好成绩 如果没有评估函数,则用损失函数最后一个数据集的最佳值(分类回归等一般情况都是最小值啦) # 2.best_iteration 最佳迭代次数,根据目标(if have评估函数最后一个)计算的 # 3.best_ntree_limit,数值是最佳迭代次数+1,因为一开始会搞出一棵树9.evals_result: dict[str, dict[str, list[float] | list[tuple[float, float]]]] | None = None, 提前建一个空字典,存储训练、自定义损失函数的结果,train的时候,指定结果传给这个个空字典就行了。 10.verbose_eval: bool | int | None = True 需要有自定义评估函数: 设置为0则不输出任何信息, 设为1则每次迭代输出train loss,train eval_loss,test loss,test_eval_loss 如果迭代几千上万次的话,比较建议设个50,100,200。 11.xgb_model: str | PathLike | Booster | bytearray | None = None 比如之前已经训练好了一个模型,将其保存了下来,下次可直接用, 一般都是先把模型训练好,直接保存,predict的时候, 在之前的参数中,加上这个路径。 12.callbacks: 可以在训练了调整学习率、early_stopping _round等参数,没太研究过,感觉不太需要用! 13.colsample_bylevel,colsample_bynode,每一级分裂,每次叶节点分裂时,对列的采样比例,如果特征列很多,可以尝试加colsample_bylevel,注意三个列采样参数,是会n_cols乘by_tree乘by_level乘by_node的,如果乘太多,深度稍大的结点,特征列可能会少很多。XGBOOST列采样,是在要生成这棵树的时候,比如总共100个特征,colsample_tree=0.6,则先随机选60个特征,其他40个特征在这棵树中绝对不会出现,这点跟随机森林不同! 14.tree_method:默认auto,模型看到你的数据量小,会选择贪婪的分裂方法exact,数据量中变成approx,即分位数quantile,数据量较大,变成直方图hist,就是划分很多bins啦。速度上来讲越精确越慢,准确度(广义上的)来说,肯定越慢越高。(仅限用CPU算的情况) 15:base_score:全局偏差 样本不均衡时可以使用,分类问题中它就是分类的先验概率 如有1000个样本,300个正样本和700个负样本,则base_score就是0.3 对于回归来说这个分数默认为0.5,但是理论上而言这个分数应该设置为标签的均值更好,但在多次迭代的情况下。 # 由于懒得再打字,上述文字摘抄自 url = https://www.cnblogs.com/achai222/p/14649420.html 实测初始值没影响,最终都会走向同样的结果。 等等、、、 16.勘误更新一下,xgboost在predict(x_test)的时候,可以选择用多少次迭代,如果有early_stop,则会默认使用最佳成绩,并不需要特别地指定iteration_range=(0,model.best_iteration+1)(左闭右开,可取左边取不到右边的值) 如果要显式指定,用iteration_range=(0,model.best_ntree_limit)或(0,model.best_iteration+1) 其中model.best_ntree_limit = model.best_iteration+1 模型总迭代次数= best_iteration+early_stop次数 比如earl_stop=5,模型best_iteration是迭代10次,那么模型总共迭代了0+10+5次,带个0是因为一开始默认会生成一个树,所以best_ntree_limit 是1+10棵树,iteration_range = (0,11),意味着用[0,10]这11次迭代,正好对上。 其实压根就不需要设,经过参考官网和自行实验,train和sklearn方法,只要有early_stop,自动用最佳,直接predict就行。 当然可能不同版本有差异,如果不确定,多敲几个字也无妨。 17.scale_pos_weight 样本权重,比如说一个二分类数据,0样本是1样本的十倍,那么可以尝试将scale_pos_weight设为10,从损失函数的数学公式来讲,相当于在0样本的-[p*log(p^hat)+(1-p)log(1-p^hat)]前面,乘了一个十一分之一,而1样本前面就乘一个十一分之十,这样模型会更关注损失函数前面系数大的那个;如果用了该参数,发生顾此失彼之现象,请尝试关闭或调到很小试试。 18.importance_type="weight",特征重要性 xgb_model.get_score(fmap='', importance_type='weight') ‘weight’: the number of times a feature is used to split the data across all trees. ‘gain’: the average gain across all splits the feature is used in. ‘cover’: the average coverage across all splits the feature is used in. ‘total_gain’: the total gain across all splits the feature is used in. ‘total_cover’: the total coverage across all splits the feature is used in.19. xgboost原生接口,在predict的时候,如果训练数据和预测数据,列的顺序不同,则会报错,需要调整一下: x_test = x_test.loc[:,x_train.columns] 20.用GPU需要先设置好CUDA相关内容,请查看其他文章,同时需要设置 'tree_method':'gpu_hist 'predictor':'gpu_predictor' 二、 sklearn的xgboost参数的名称、用法有一些差异,要自行打开参数说明,基本一眼秒懂... 用SKlearn接口,主要是配合GridSearchCV调参,一般先把学习率搞大点,比如0.1,0.2之类,先调n_estimators,再试max_depth,min_child_weight,再试gamma,正则化系数等,建议一次最多调2个参数,数据稍微大点,速度会很慢,因为没有用Dmatrix。 其参数,与原生接口略有不同,这里就不展开了... 原生train接口,只有predict,二分类中返回的是为1的概率值,要转为标签要手动操作一番,sklearn接口中有predict_prob这个属性。 # SKlearn接口演示,直接复制可用 from sklearn import datasets from sklearn.model_selection import train_test_split x, y = datasets.load_wine(return_X_y=True) x_train, x_test, y_train, y_test = train_test_split(x, y, shuffle=True, test_size=0.2) from sklearn.model_selection import GridSearchCV from xgboost import XGBClassifier grid_paras = {'n_estimators':[1000,2000,4000],'learning_rate':[0.1,0.05,0.01]} # 先随便设点参数 model = XGBClassifier(learning_rate=0.1 , n_estimators=100 , max_depth=6 , num_class=3 # , min_child_weight=1 # 限制叶子结点权重,值越大越容易欠拟合,越小容易过拟合 , gamma=0 # 惩罚项,叶节点分裂所需的最小损失函数下降值 , subsample=0.8 # 样本抽样比例 , colsample_bytree=0.8 # 特征抽样比例 , objective='multi:softmax' # 多分类 , eval_metric=['merror'] # 验证模型效果评判标准,merror即为多分类 , njobs=-1 # 并行线程数 ,verbosity=0 ,early_stopping_rounds=50 ) gs = GridSearchCV(model,grid_paras,cv=5) gs.fit(x_train,y_train,eval_set=[(x_test,y_test)]) gs.best_params_,gs.best_score_
XGBOOST在数据比较大的时候,调参过程还是比较漫长的,如果觉得顶不住,可以使用拟坐标轴下降法,先定好其他参数,调一个,找到最佳值,再定住,再调第二个...虽然不一定是最佳解,但在这种情况下,比运行很久或者随便写参数要强不少,属于没得办法的办法,当然可以换其他模型; 3.1硬要用.train调参也可以,不过要手动写个代码,如果常用可以写一个方法甚至搞个类. # 还是用乳腺癌二分类例子 # 导包 import xgboost as xgb from sklearn import datasets import numpy as np from sklearn.model_selection import train_test_split import pandas as pd import time from sklearn.metrics import auc,accuracy_score,roc_auc_score # 开干 x,y = datasets.load_breast_cancer(return_X_y=1) from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(x,y,shuffle=True,stratify=y) t1 = time.time() # 要调的参数 eta = [0.1,0.05,0.01] gamma = [0.01,0.05,0.1] lambda_para = [0.01,0.05,0.1] max_depth = [5,6,7] result_temp = {} result_dict = {} for a in eta: for b in gamma: for c in lambda_para: for d in max_depth: param_dict = {'booster': 'gbtree', 'objective': 'binary:logistic', # 返回概率值,非标签 # 'eval_metric': ['auc','error'], 'eval_metric': 'error', 'max_depth': d, #最大深度 # 'alpha':0.1, # L1正则化系数 'lambda': c, # L2正则化系数 'subsample': 0.8, # 样本不放回抽样比例 'colsample_bytree': 0.8, # 特征列抽样比例 # 'min_child_weight': 1, # 见下图 'eta': a, # 原生接口中eta为学习率 'seed': 1024, 'nthread': -1, 'gamma': b, } # 4.将训练、测试(验证)数据转为DMatrix dtrain = xgb.DMatrix(x_train, label=y_train) dtest = xgb.DMatrix(x_test, label=y_test) evals_list = [(dtrain, 'train'), (dtest, 'eval')] # train model = xgb.train(param_dict , dtrain, num_boost_round=1000, evals=evals_list , early_stopping_rounds=50, verbose_eval=100,evals_result=result_temp ) y_pred = model.predict(dtest) y_lable = (y_pred >0.5)*1 # max_auc = result_temp['eval']['auc'][-1] min_error = result_temp['eval']['error'][-1] # 用的最后一个 # min_error = min(result_temp['eval']['error']) # 用的最小的 accuracy = accuracy_score(y_test,y_lable) result_dict.setdefault('Accuracy',[]).append(accuracy) result_dict.setdefault('Error',[]).append(min_error) result_dict.setdefault('Eta',[]).append(a) result_dict.setdefault('Gamma',[]).append(b) result_dict.setdefault('Lambda',[]).append(c) result_dict.setdefault('Max_Depth',[]).append(d) t2 = time.time() print('cost_time',t2-t1) # cost_time 2.782684326171875 # 当然此代码存在很多细节上的问题,没有CV,但是方向大概是这样子 # 反正就是循环结果,都存在result_dict 里面了,可以转为DataFrame,方便看 df = pd.DataFrame(result_dict) print(df) index = df['Accuracy'].argmax() print('besst_para:',df.iloc[index])
metric我想了一下,只用一个算了,毕竟有early_stopping_rounds的话,也只会用最后一个metric和eval_set,分类问题alpha,beta也不可得兼 besst_para: Accuracy 0.958042 Error 0.041958 Eta 0.100000 Gamma 0.010000 Lambda 0.010000 Max_Depth 5.000000 Name: 0, dtype: float64如下,后面验证了一下,果然应该选best而不是last!
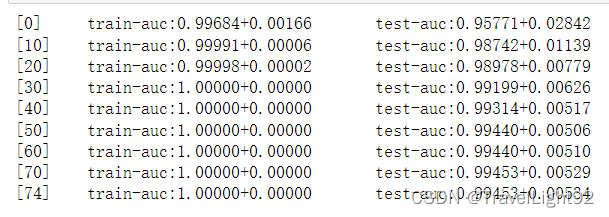
此处需要注意:sklearn中使用自定义评估函数,不需要.get_label(),不要return name,value直接return value; 在gridsearch之类的接口中,最后直接在XGBRegressor之中设置eval_metric=custom_eval_metric,不在GridSearchCV中传scoring,这样省一点麻烦和代码! # 对比GridSearch调参 from xgboost import XGBClassifier from sklearn.model_selection import GridSearchCV t3 = time.time() search = {'learning_rate':[0.1,0.05,0.01] ,'gamma':[0.01,0.05,0.1] ,'reg_lambda':[0.01,0.05,0.1] ,'max_depth':[5,6,7] } model2 = XGBClassifier(n_estimators=1000,verbosity=1,objective='binary:logistic' ,n_jobs=-1,subsample=0.8,colsample_bytree=0.8,eval_metric='error', early_stopping_rounds=50,booster='gbtree') grid_s = GridSearchCV(model2,search,n_jobs=-1,scoring='accuracy') grid_s.fit(x_train,y_train,eval_set=[(x_test,y_test)]) t4 = time.time() print('cost:',t4-t3) # cost: 4.548938035964966 # 复制运行结果会有差异,很可能是小数点精度的问题 # 原生接口是2.7秒,这里是4.5秒 # 果然是要快一些,基本两倍,不过本数据很小,没那么明显,其实应该更快 3.3 xgb.cv 调参xgboost自带了一个cv方法,其实有很多其他方法完全可以代替,这个方法个人认为主要有2个作用: (1)在既定参数下,寻找最佳的迭代次数; import pandas as pd import numpy as np from sklearn.model_selection import train_test_split,StratifiedKFold,train_test_split,GridSearchCV,KFold from sklearn.metrics import accuracy_score, confusion_matrix, mean_squared_error,roc_auc_score,accuracy_score,recall_score from xgboost import plot_importance from matplotlib import pyplot as plt import xgboost as xgb from sklearn import datasets pd.options.display.max_columns=35 x,y = datasets.load_breast_cancer(return_X_y=True,as_frame=True) df = pd.concat((x,y),axis=1) # print(df) x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,stratify=y,random_state=1) # 先将数据转为DMatrix dtrain = xgb.DMatrix(data=x_train,label=y_train) dtest = xgb.DMatrix(data=x_test,label=y_test) dfull = xgb.DMatrix(data=x,label=y) # 这一步主要是写好主要参数,方便get clf = xgb.XGBClassifier(max_depth = 7, n_estimators=100, learning_rate=0.1, reg_lambda = 0.1, nthread=-1, subsample=1.0, colsample_bytree=0.8, seed=1) paras = clf.get_xgb_params() cvresult = xgb.cv(paras,dfull,num_boost_round=100,nfold=5, stratified=True,metrics=['auc'],early_stopping_rounds=10,verbose_eval=10) print('CV验证最佳迭代次数:',cvresult.shape[0]) # CV验证最佳迭代次数: 66 # 这个自带的方法,有个early_stop,通过交叉验证,找到最佳的迭代次数 clf.set_params(n_estimators=cvresult.shape[0]) clf.fit(x_train,y_train,eval_metric='auc') y_pred1 = clf.predict_proba(x_train) # predict_proba # 是样本为0,1的概率,shape[nsamples,2] print('训练集上的AUC',roc_auc_score(y_train,clf.predict(x_train))) # 训练集上的AUC 1.0 pred2 = clf.predict_proba(x_test,ntree_limit=cvresult.shape[0]) # 该模型下的测试集预测结果 print('测试集上的AUC',roc_auc_score(y_test,pred2[:,-1])) # 测试集上的AUC 0.99239417989418
(2)是针对一个参数,手动调整大小寻找最佳值,比如说lambda,通过2组实验,实验中其他参数不变,就这个参数是不同的数值,对比train_metric,test_metric,查看哪个更好; 这个就属于精修了,理想状态是train、test效果都棒棒,但是经常出现train很好、test不太好,就是过拟合了,此时针对一个参数,经常是对lambda、gamma、max_depth、min_child_weight等控制过拟合的参数进行精修,不过此项工作费时费力劳神伤财,精修的目的是在保证训练不会变差很多,但是测试效果提高不少,但最终还是取决于模型评价指标。(有点写不动了,可以看看下面这个链接)xgboost2 以及使用XGB.CV来进行调参-CSDN博客
|
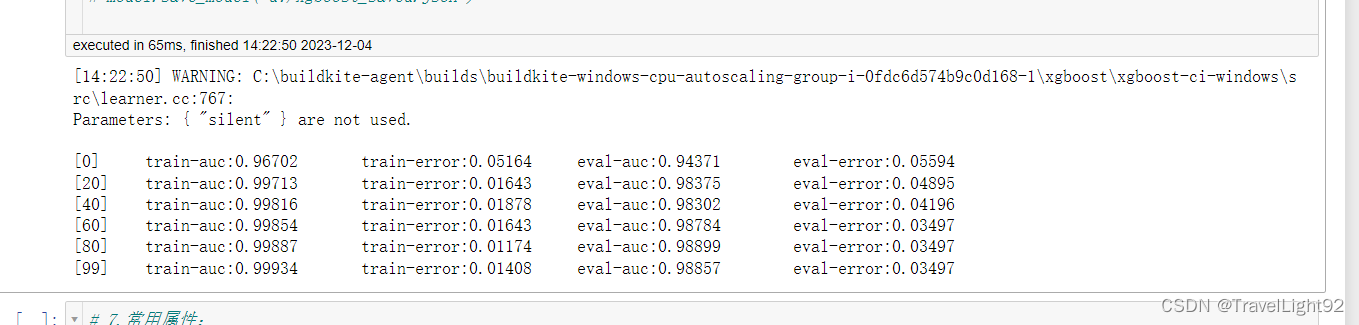 由于这个数据集量少、且简单,其实很多参数设置不合理,很多参数得设置小点。
由于这个数据集量少、且简单,其实很多参数设置不合理,很多参数得设置小点。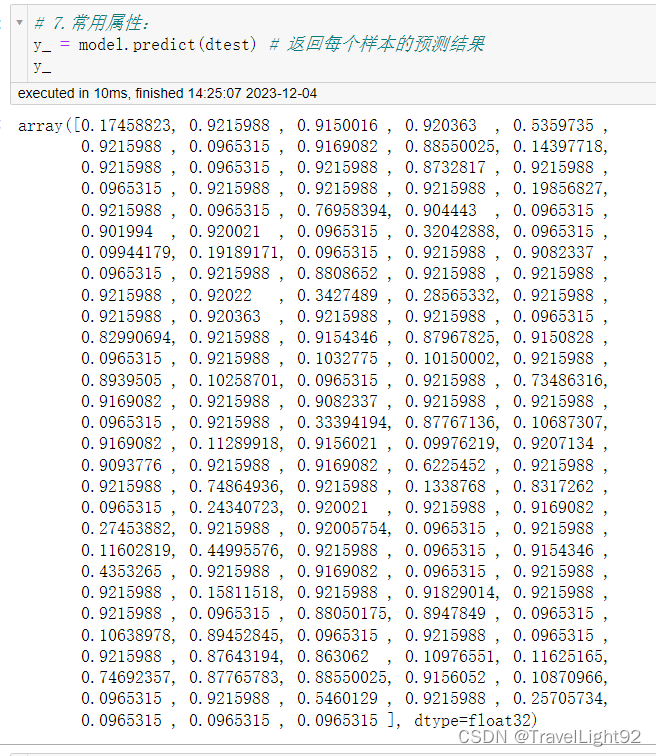
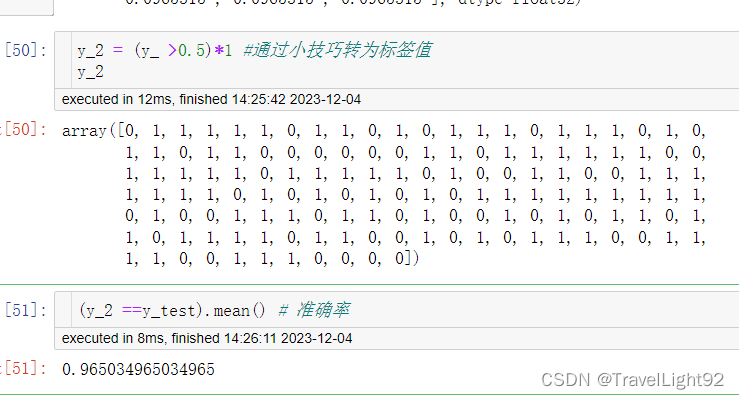 y_2 = [1 if p >= 0.5 else 0 for p in y_] 推导式写法亦可
y_2 = [1 if p >= 0.5 else 0 for p in y_] 推导式写法亦可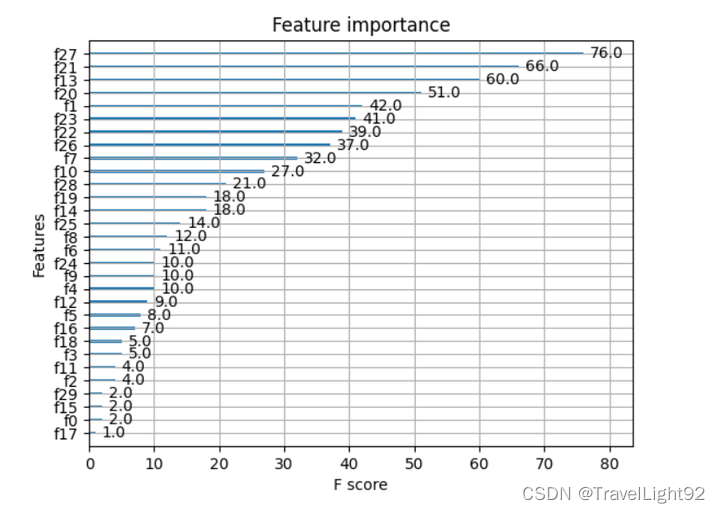

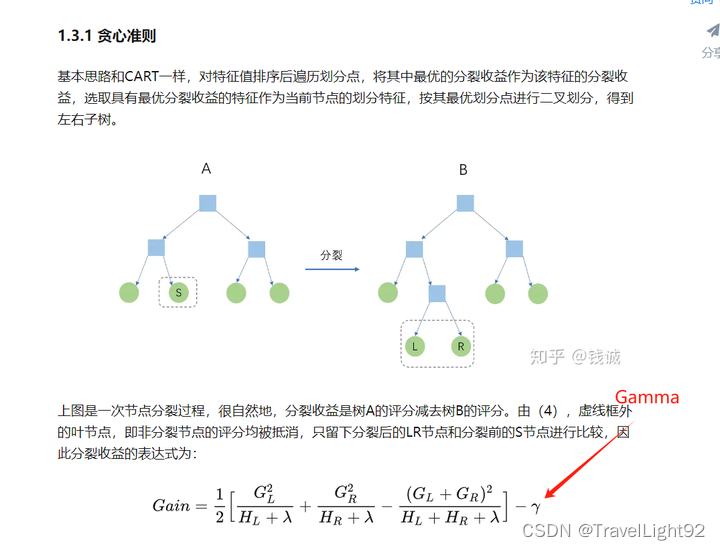 图来源:https://zhuanlan.zhihu.com/p/142413825
图来源:https://zhuanlan.zhihu.com/p/142413825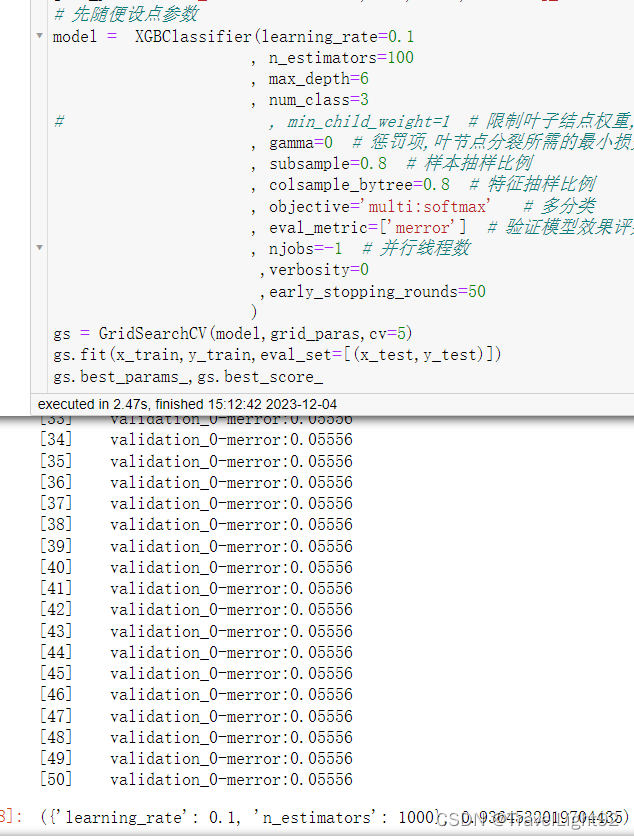

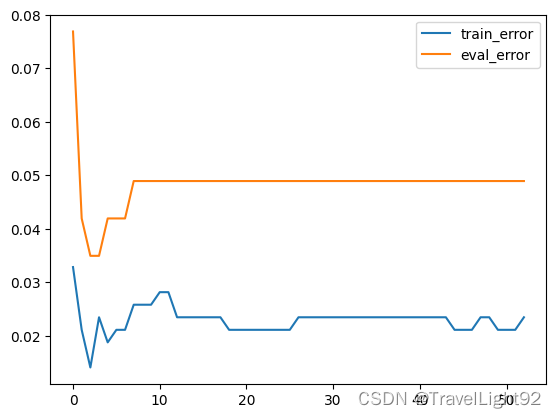

【本文地址】