| 如何使用JavaScript,纯前端实现字符、字数统计? | 您所在的位置:网站首页 › word计算字数包含空格吗 › 如何使用JavaScript,纯前端实现字符、字数统计? |
如何使用JavaScript,纯前端实现字符、字数统计?
|
快速目录
统计字数/字符在线演示🖥
实现逻辑🤖判断规则⚖️正则表达式Unicode编码
代码实现✌️统计中文统计英文和数字
总结📝
统计字数/字符
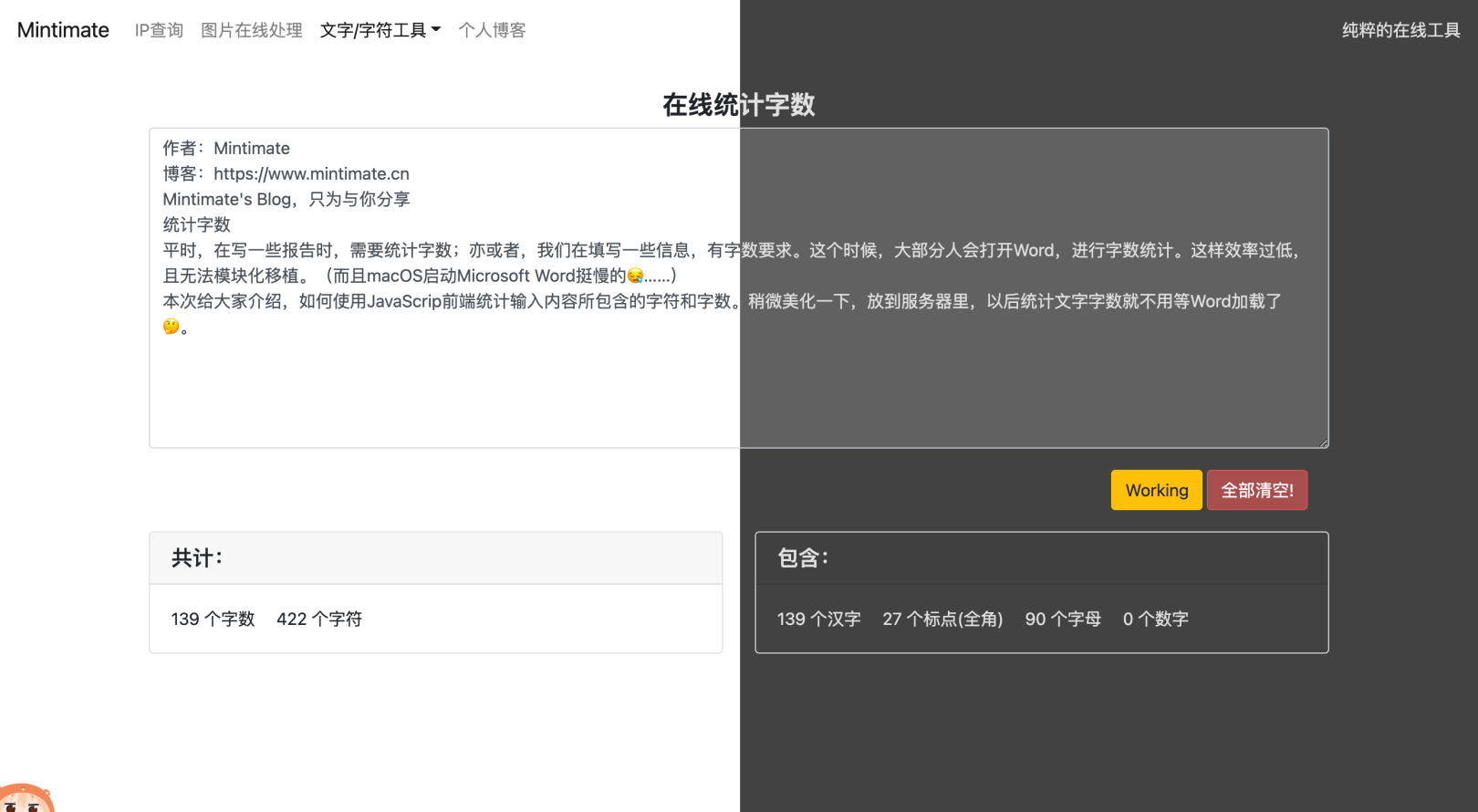
平时,在写一些报告时,需要统计字数;亦或者,我们在填写一些信息,有字数要求。这个时候,大部分人会打开Word,进行字数统计。这样效率过低,且无法模块化移植。(而且macOS启动Microsoft Word挺慢的😪……) 本次给大家介绍,如何使用JavaScrip前端统计输入内容所包含的字符和字数。稍微美化一下,放到服务器里,以后统计文字字数就不用等Word加载了🤔。
为了让大家更方便理解,什么是统计字数。我做了一个在线统计字数的网站。原理就是本篇文章: Mintimate-纯粹在线工具:https://www.flyinbug.cn本文章同步发布于: 腾讯云社区:如何使用JavaScript,纯前端实现字符、字数统计? Mintimate的知乎:如何使用JavaScript,纯前端实现字符、字数统计? 实现逻辑🤖首先,我们把段落才分成一个一个的字节,HTML里我们打一个ID:content,之后用JS用来获取用户输入的段落(标签我们使用textarea标签)。对于Javascript部分,我们引用jQuery: // 获取段落内容 Words = $('#content').val();对于拆分段落内容为字符,我们使用charAT方法即可将字符串转为字符数组,配合循环遍历即可完成统计: // 标点和中文 var sTotal = 0; // 中文字判断 var iTotal = 0; // 英文字母 var eTotal = 0; // 数字判断 var inum = 0; for (i = 0; i < Words.length; i++) { var c = Words.charAt(i); if (c.match(***)) { //判断 } }最后的判断,也是个难题,如何判断?主要有两个要点: 正则表达式Unicode编码判断 判断规则⚖️ 正则表达式可以看到,我们前面逻辑判断语句: var c = Words.charAt(i); if (c.match(***)) { //判断 }其中的match方法可能很多人平时没用,该方法是:可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配。 而正则表达式,是出自Unix,这注定正则表达式的泛用。使用正则表达式可以快速匹配目标内容。举个例子,如果你要匹配一段字符串,是否包含字符abc,只需要用正则表达式:/[abc]/即可。 Unicode编码常用的编码,一般为UTF-8、UTF-16等。至于什么是编码,其实就是我们使用的文字对应一个机械代码: # helloworld \u0068\u0065\u006c\u006c\u006f\u0077\u006f\u0072\u006c\u0064而Unicode上,不同国家的字集是分区块的,我们需要用到的: 字符集字数Unicode 编码基本汉字20902字4E00-9FA5基本汉字补充38字9FA6-9FCB扩展A6582字3400-4DB5扩展B42711字20000-2A6D6扩展C4149字2A700-2B734扩展D222字2B740-2B81D康熙部首214字2F00-2FD5部首扩展115字2E80-2EF3兼容汉字477字F900-FAD9兼容扩展542字2F800-2FA1DPUA(GBK)部件81字E815-E86F部件扩展452字E400-E5E8PUA增补207字E600-E6CF汉字笔画36字31C0-31E3汉字结构12字2FF0-2FFB汉语注音22字3105-3120注音扩展22字31A0-31BA〇1字3007数字0-910字30-39小写英文字母26字61-7a大写英文字母26字41-5a而汉字的Unicode范围为\u4E00-\u9FA5。这意味着:如果你要判断字是否为汉字,那么最基本只需要判断是否在这个区间即可。 代码实现✌️最后,终于讲到大家期待的代码实现部分了。不过,相信大家看了上诉分析,应该都用思路了~~ 统计中文按刚刚所说,我们使用Unicode编码配合正则表达式进行中文字节统计: \u4E00-\u9FA5为中文Unicode编码段,所以使用正则表达式,匹配每个字是否为中文: for (i = 0; i < Words.length; i++) { var c = Words.charAt(i); //基本汉字 if (c.match(/[\u4e00-\u9fa5]/)) { iTotal++; } //基本汉字补充 else if (c.match(/[\u9FA6-\u9fcb]/)){ iTotal++; } }所以: 中文字数=iTotal 统计英文和数字 for (i = 0; i < Words.length; i++) { var c = Words.charAt(i); if (c.match(/[^\x00-\xff]/)) { sTotal++; } else { eTotal++; } if (c.match(/[0-9]/)) { inum++; } }这边解释一下: /[^\x00-\xff]/:匹配所有非双字节的字符。/[0-9]/:匹配数字0到9理论上,sTotal包含:中文字、中文全角字符(如:?。、,等)。所以: 中文全角标点=iTotal-sTotal 数字=inum 字数=inum + iTotal 标点=sTotal - iTotal 字母=eTotal - inum 字符=iTotal * 2 + (sTotal - iTotal)* 2 + eTotal 换成JS+JQ代码: //汉字 $('#hanzi').text(iTotal); //字数 $('#zishu').text(inum + iTotal); //标点 $('#biaodian').text(sTotal - iTotal); //字母 $('#zimu').text(eTotal - inum); //数字 $('#shuzi').text(inum); //字符 $("#zifu").text(iTotal * 2 + (sTotal - iTotal) * 2 + eTotal);
使用JavaScript,轻松前端进行字符和字数的统计。减轻后端压力。并且,本方法使用正则表达和Unicode字符判断,理论上可以一直到任何平台。 作者:Mintimate 博客:https://www.mintimate.cn Mintimate’s Blog,只为与你分享 |

【本文地址】