| 【精选】『词向量』用Word2Vec训练中文词向量(一) | 您所在的位置:网站首页 › word2vec算法Python实现 › 【精选】『词向量』用Word2Vec训练中文词向量(一) |
【精选】『词向量』用Word2Vec训练中文词向量(一)
|
用搜狗新闻数据集来训练中文词向量(Word2Vec),自己做的时候踩了很多的坑,希望分享出来让大家少走弯路。 在学习完这篇后,您可以点击 维基百科训练词向量,来进一步完善自己的词向量模型! 参考文章:搜狗语料库word2vec获取词向量 自然语言处理入门(一)------搜狗新闻语料处理和word2vec词向量的训练 word2vec使用方法小结 目录 数据集下载数据集处理(一)文档解压(二)文档提取(三)文档分词 用gensim训练词向量写在最后参考文章 数据集下载此次用的是搜狗实验室的新闻数据集下载地址 有迷你版和完整版可供选择。我下载的是完整版的 tar.gz 格式。 打开 Windows命令提示符 (cmd),转到该文件所在文档,输入: tar -zvxf news_sohusite_xml.full.tar.gz即可将下载下的文件 news_sohusite_xml.full.tar.gz 解压为 news_sohusite_xml.dat (二)文档提取 我们看一下解压后的数据(由于数据太大,我用 Pycharm 打开) 利用 cmd ,在转码处理的同时再提取 “content” 中的内容: type news_sohusite_xml.dat | iconv -f gbk -t utf-8 -c | findstr "" > corpus.txt这时候可能会报错,原因是缺少 iconv.exe ,需要下载 win_iconv - 编码转换工具 ,下载后解压,复制 iconv.exe 到 C:\Windows\System32,即可使用。 保存在文档 corpus.txt 中,效果如图所示。 建立 corpusSegDone.txt 文件,作为分词后的结果保存文件。输入以下代码进行分词,每处理100行就打印一次,可以看到进度。 import jieba import re filePath = 'corpus.txt' fileSegWordDonePath = 'corpusSegDone.txt' # 将每一行文本依次存放到一个列表 fileTrainRead = [] with open(filePath, encoding='utf-8') as fileTrainRaw: for line in fileTrainRaw: fileTrainRead.append(line) # 去除标点符号 fileTrainClean = [] remove_chars = '[·’!"#$%&\'()*+,-./:;?@,。?★、…【】《》?“”‘’![\\]^_`{|}~]+' for i in range(len(fileTrainRead)): string = re.sub(remove_chars, "", fileTrainRead[i]) fileTrainClean.append(string) # 用jieba进行分词 fileTrainSeg = [] file_userDict = 'dict.txt' # 自定义的词典 jieba.load_userdict(file_userDict) for i in range(len(fileTrainClean)): fileTrainSeg.append([' '.join(jieba.cut(fileTrainClean[i][7:-7], cut_all=False))]) # 7和-7作用是过滤掉标签,可能要根据自己的做出调整 if i % 100 == 0: # 每处理100个就打印一次 print(i) with open(fileSegWordDonePath, 'wb') as fW: for i in range(len(fileTrainSeg)): fW.write(fileTrainSeg[i][0].encode('utf-8')) fW.write('\n'.encode("utf-8")) 分词过程如下图所示,我的总共 140w 行,用时 45 min。 解释一下训练语句model = word2vec.Word2Vec(sentences, size=100, sg=1, window=6, min_count=0, workers=4, iter=5)的参数,避免踩坑: sentences:传入的句子集合size:是指训练的词向量的维度sg:为 0 表示训练采用 CBOW 算法,1 表示采用 skip-gram 算法window:窗口数,即当前词与预测词的最大距离min_count:舍弃掉那些词频比该值小的词。注意,我在这里踩了很大的坑,一定要想清楚是否要过滤掉频率较小的词!如果你还希望做句子相似性的时候,如果舍弃了一部分单词,有可能会出现句子中的词不在词汇表中的情况!!!worker:线程数,使用多线程来训练模型iter:迭代次数如果想了解一下输出信息logging,请点击 logging模块、Logger类,也可以自己添加想要的信息! 剩余的大部分做了注释,直接贴代码: import logging import sys import gensim.models as word2vec from gensim.models.word2vec import LineSentence, logger def train_word2vec(dataset_path, out_vector): # 设置输出日志 logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) logger.info("running %s" % ' '.join(sys.argv)) # 把语料变成句子集合 sentences = LineSentence(dataset_path) # 训练word2vec模型(size为向量维度,window为词向量上下文最大距离,min_count需要计算词向量的最小词频) model = word2vec.Word2Vec(sentences, size=100, sg=1, window=5, min_count=5, workers=4, iter=5) # (iter随机梯度下降法中迭代的最大次数,sg为1是Skip-Gram模型) # 保存word2vec模型(创建临时文件以便以后增量训练) model.save("word2vec.model") model.wv.save_word2vec_format(out_vector, binary=False) # 加载模型 def load_word2vec_model(w2v_path): model = word2vec.KeyedVectors.load_word2vec_format(w2v_path, binary=True) return model # 计算词语的相似词 def calculate_most_similar(model, word): similar_words = model.most_similar(word) print(word) for term in similar_words: print(term[0], term[1]) if __name__ == '__main__': dataset_path = "corpusSegDone.txt" out_vector = 'corpusSegDone.vector' train_word2vec(dataset_path, out_vector) 但是我知道,绝不会那么简单。我出现了第一个警告: UserWarning: C extension not loaded, training will be slow. 我刚开始没看到,结果到后面一个 EPOCH 只能处理 160 词/s ,而一般是几十万,我整整训练了10个小时都没有结果!!!果然很 slow ::>_ |

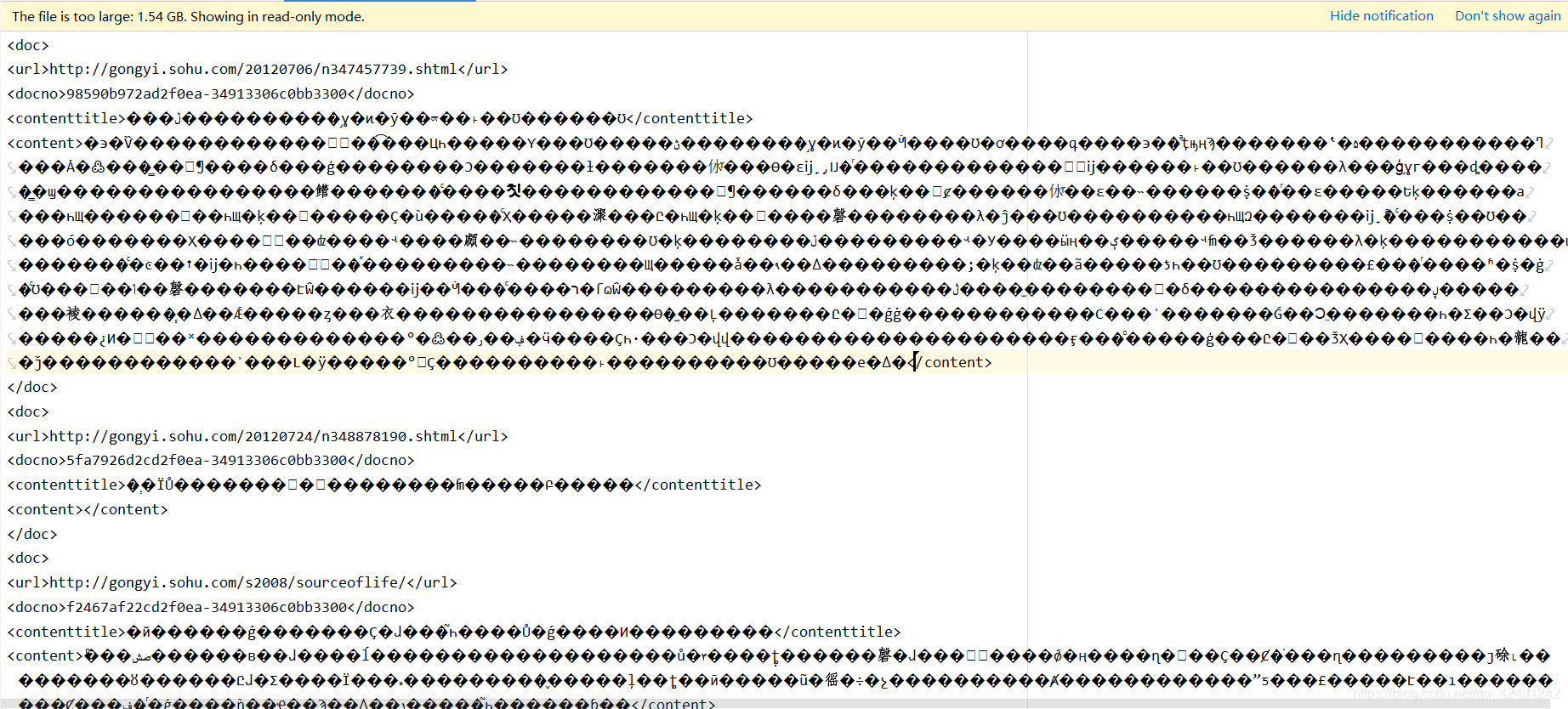 发现两个Key Point:(1) 文档编码有问题,我们需要对它进行转码 (2) 文档存储格式是 uml ,url 是页面链接,contenttitle 是页面标题,content 是页面内容,可以根据自己需要来获取信息。
发现两个Key Point:(1) 文档编码有问题,我们需要对它进行转码 (2) 文档存储格式是 uml ,url 是页面链接,contenttitle 是页面标题,content 是页面内容,可以根据自己需要来获取信息。
 分词结果如图所示:
分词结果如图所示: 

【本文地址】