| 教程:超详细从零开始yolov5模型训练 | 您所在的位置:网站首页 › wificmcc192168101怎么详细步骤 › 教程:超详细从零开始yolov5模型训练 |
教程:超详细从零开始yolov5模型训练
|
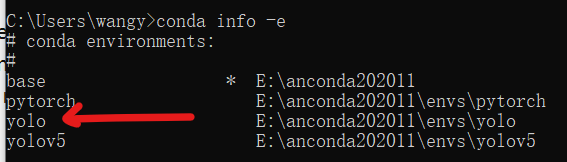
本文将介绍yolov5从环境搭建到模型训练的整个过程。最后训练识别哆啦A梦的模型。 1.anconda环境搭建 2.yolov5下载 3.素材整理 4.模型训练 5.效果预测 - Anconda环境搭建提醒:所有操作都是在anconda的yolo的环境下进行的,在创建yolo环境后,之后每次进入CMD都需要切换到yolo环境中去(否则进入默认的base环境中) https://www.anaconda.com/products/individual#Downloads 下载对应版本anconda即可,这里就不介绍anconda安装过程了。 anconda安装好后,conda可以创建多个运行环境,默认是base环境。这里我们为yolo创建一个环境。 打开CMD命令行,为yolov5创建一个环境,注意这里用的python版本是3.8,版本过低后面可能会报错 conda create -n yolo python=3.8执行 conda info -e即可看到我们刚刚创建的yolo环境 即可切换到我们的yolo环境下了。记住退出CMD或者切换CMD窗口之后,如果想要进入我们的yolo环境,都需要运行activate yolo指令。不然默认是在base环境下。 除此之外,我们进行yolo模型训练代码的编写需要用到jupyter notebook,所以我们需要在yolo环境下进行安装 conda install jupyter notebook安装完成之后,我们只需要在yolo环境下输入 jupyter notebook就会打开notebook,自动跳转到浏览器,打开notebook界面,之后我们会在notebook里进行训练yolo模型 https://github.com/ultralytics/yolov5 下载yolov5源码,解压,可以看到里面有requirements.txt文件,里面记录了需要安装的包,这个txt文件可以帮助我们一键下载这些依赖包。 接着上面的requirement.txt,介绍如何安装里面需要安装的依赖。我们首先打开我们下载好的yolov5_master 文件夹,在上面输入cmd回车,可以直接在该文件夹目录下打开命令行。 在cmd命令行打开之后,大家千万记得要切换到我们的yolo环境下,不然就安装到base环境中去了。 activate yolo然后运行 pip install -r requirements.txt就会自动帮我们把这些依赖安装好了。接下来我们就要开始训练yolo模型了。 -整理yolov5模型 为了完成训练工作,我们需要将训练的图片按照指定的格式进行整理, 详细参照yolov5官方指南: https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data我这里也简要介绍一遍过程,然后也为大家避坑,我们在训练前首先需要采集图片样本,然后再对图片中的待识别物体进行标注。 我们首先需要建立如下的文件夹: 我这次测试的检测哆啦A梦的头像,我采集了50张哆啦A梦的样本,放到images文件夹下: 然后在labelImg-master文件夹下打开cmd,进入我们的yolo环境中,然后我们还需要在yolo环境中安装一些labelimg运行需要的依赖,依次输入 conda install pyqt=5 conda install -c anaconda lxml pyrcc5 -o libs/resources.py resources.qrc现在,我们已经在yolo环境中安装好labelimg的依赖环境了,输入 python labelimg.py即可进入我们的界面中来。进入之后,首先我们先把一些选项勾上,便于我们标记。然后,最重要的是把标记模式改为yolo。 然后软件右上角我们打开这个选项,当我们标记图片后,就会自动帮我们归类到A了 现在我们就可以开始进行标记了,常用的快捷键,用主要wad三个键 Ctrl + u Load all of the images from a directory Ctrl + r Change the default annotation target dir Ctrl + s Save Ctrl + d Copy the current label and rect box Ctrl + Shift + d Delete the current image Space Flag the current image as verified w Create a rect box d Next image a Previous image del Delete the selected rect box Ctrl++ Zoom in Ctrl-- Zoom out ↑→↓← | Keyboard arrows to move selected rect box通过鼠标拖拽框选即可标注: 所有图片标注好之后,我们再来看我们的labels文件夹,可以看到很多txt文件。每个文件都对应着我们标记的类别和框的位置: 到目前,我们的训练的材料就已经准备好了。 -yolov5模型训练现在我们开始训练模型,由于电脑的配置过低,我采用的是谷歌colab平台进行训练,使用方法和notebook完全一样。使用云端colab会比使用本地的notebook多一些文件上传的操作。大家注意区分差异 首先进行模块的导入,由于云端的colab还没有下载yolov5和他的依赖,所以加上前面两行。如果是本地notebook的用户,则注释掉前面三句: !git clone https://github.com/ultralytics/yolov5 # clone repo %cd yolov5 %pip install -qr requirements.txt # install dependencies import torch from IPython.display import Image, clear_output # to display images clear_output() print('Setup complete. Using torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))之后我把我们的的素材yolo_A文件夹压缩上传到colab,然后在colab上解压(本地notebook不需要这不操作) !unrar x ../yolo_A ../然后一下代码可以测试能否正常工作,顺带会下载yolov5s.pt文件,这个文件后面训练的时候会用到 !python detect.py --weights yolov5s.pt --img 640 --conf 0.25 --source data/images/ Image(filename='runs/detect/exp/zidane.jpg', width=600)如果一切正常会显示如下图 训练完成后,我们可以看到训练结果保存的位置: 现在我们用训练出来的结果找一张网图做测试(文件名和导出预测文件地址不一定相同,但是相似,大家自行寻找) !python detect.py --weights /content/yolov5/runs/train/exp2/weights/best.pt --img 640 --conf 0.25 --source ../test2.jpg Image(filename='runs/detect/exp4/test2.jpg', width=600)
好了,基本上就完成了。接下来为了提高识别的精确度还需要继续学习yolov5的实现原理和相关参数的设定技巧。大家有问题欢迎评论区提问。 |
 执行
执行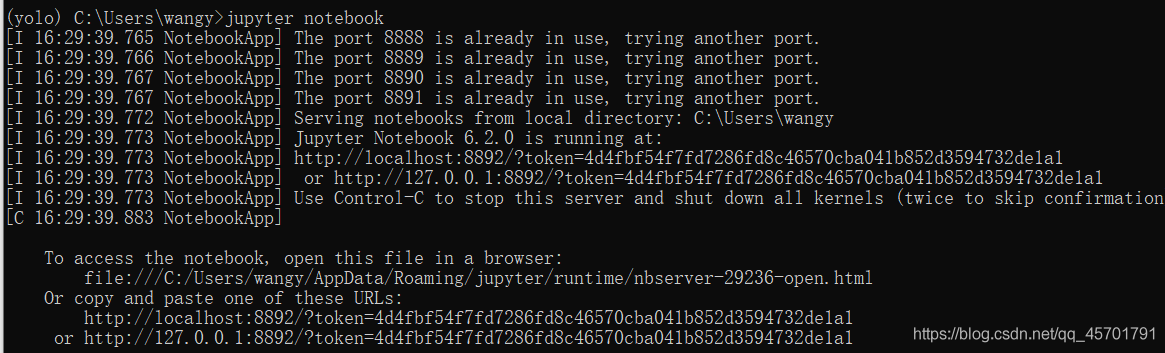
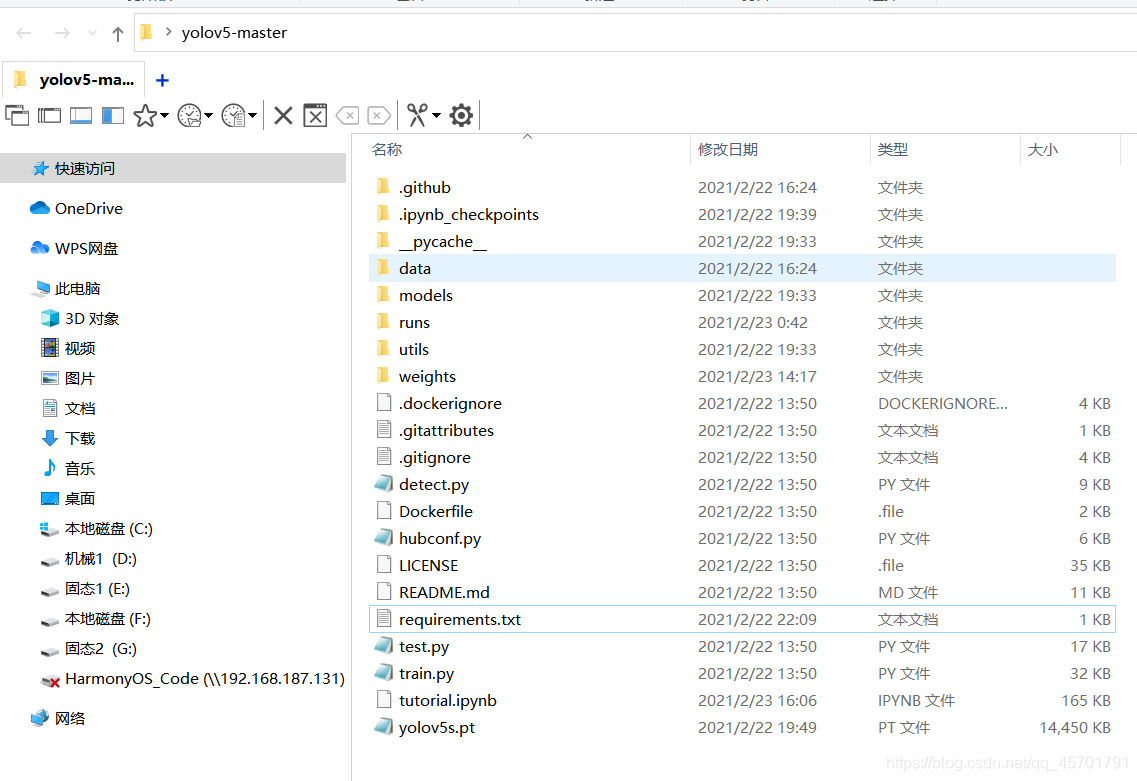 文件夹里也包含了train.py文件,这个也是我们接下来训练yolo模型需要用到的启动文件。(大家看到的文件夹内容会和我的有点不一样,因为我的下载下来后又添加了一些文件)
文件夹里也包含了train.py文件,这个也是我们接下来训练yolo模型需要用到的启动文件。(大家看到的文件夹内容会和我的有点不一样,因为我的下载下来后又添加了一些文件)
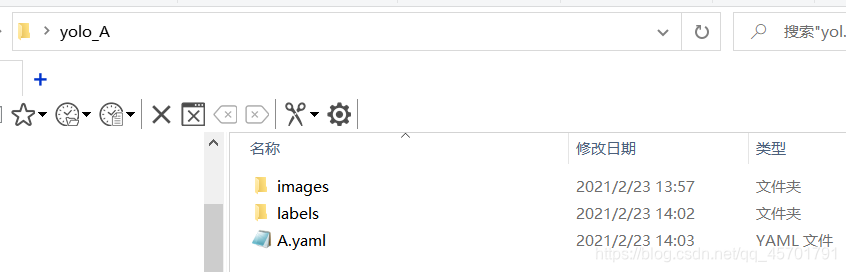 所有文件放在yolo_A文件夹下,子文件夹images用来存放样本图片,labels文件夹用来存储标注信息。A.yaml文件用来存放一些目录信息和标志物分类。
所有文件放在yolo_A文件夹下,子文件夹images用来存放样本图片,labels文件夹用来存储标注信息。A.yaml文件用来存放一些目录信息和标志物分类。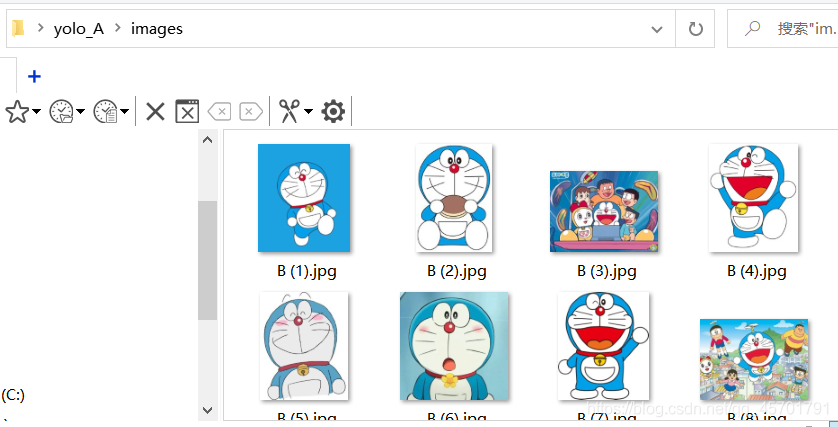 接下来我们就要进行图片的标注工作了,图片标注我们用到了一个名为labelimg的工具:https://github.com/tzutalin/labelImg 大家下载解压之后,首先要做的是删除 labelImg-master\data\predefined_classes.txt txt文件中的内容,不然等会标记的时候会自动添加一些奇怪的类别。
接下来我们就要进行图片的标注工作了,图片标注我们用到了一个名为labelimg的工具:https://github.com/tzutalin/labelImg 大家下载解压之后,首先要做的是删除 labelImg-master\data\predefined_classes.txt txt文件中的内容,不然等会标记的时候会自动添加一些奇怪的类别。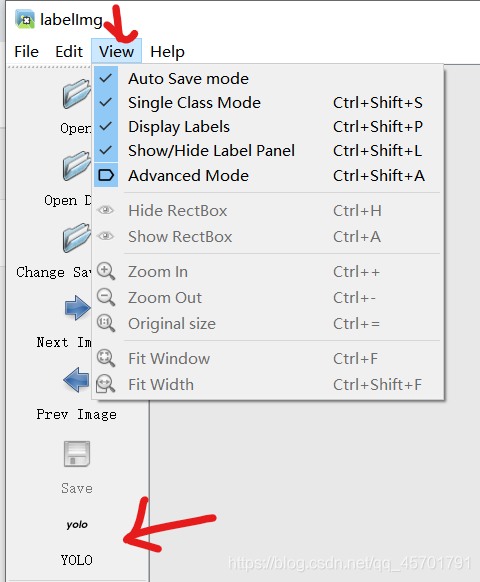 之后我们点击Open dir选择我们图片所在的images文件夹,选择之后会弹窗让你选择labels所在的文件夹。当然如果选错了,也可以点change save dir进行修改。
之后我们点击Open dir选择我们图片所在的images文件夹,选择之后会弹窗让你选择labels所在的文件夹。当然如果选错了,也可以点change save dir进行修改。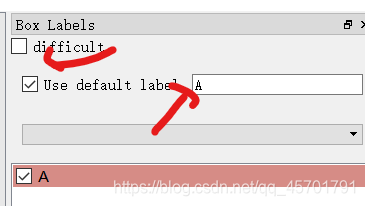

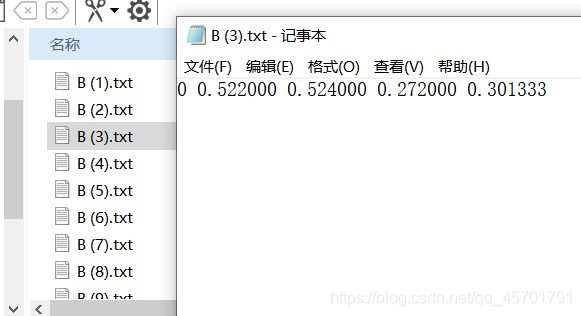 最后还要做的是建立yaml文件,文件的位置也不要放错:
最后还要做的是建立yaml文件,文件的位置也不要放错: 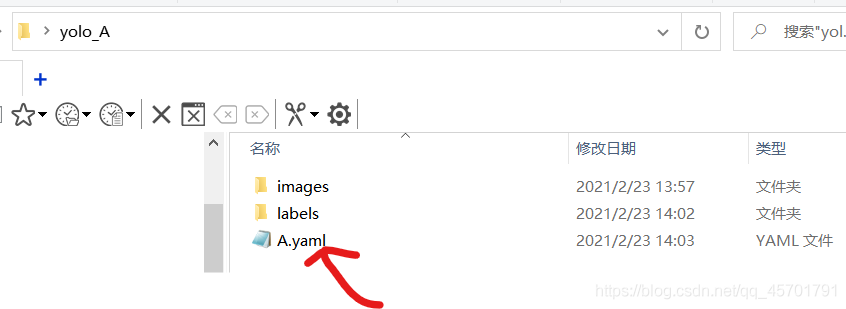 文件里面内容如下,其中train和val都是我们images的目录,labels的目录不用写进去,会自动识别。nc代表识别物体的种类数目,names代表种类名称,如果多个物体种类识别的话,可以自行增加。
文件里面内容如下,其中train和val都是我们images的目录,labels的目录不用写进去,会自动识别。nc代表识别物体的种类数目,names代表种类名称,如果多个物体种类识别的话,可以自行增加。 接下来就要开始训练模型了:
接下来就要开始训练模型了: 在对应exp文件下可以看到用训练集做预测的结果:
在对应exp文件下可以看到用训练集做预测的结果: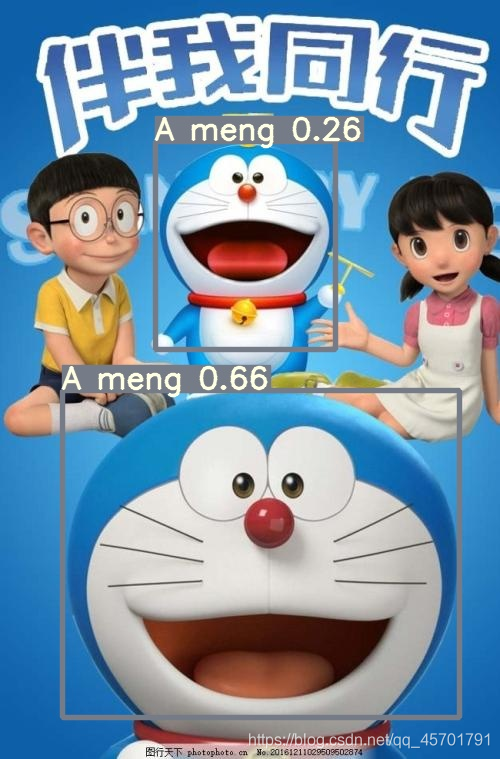
【本文地址】