| python爬虫之爬取时光网电影影评 | 您所在的位置:网站首页 › vip时光电影网 › python爬虫之爬取时光网电影影评 |
python爬虫之爬取时光网电影影评
|
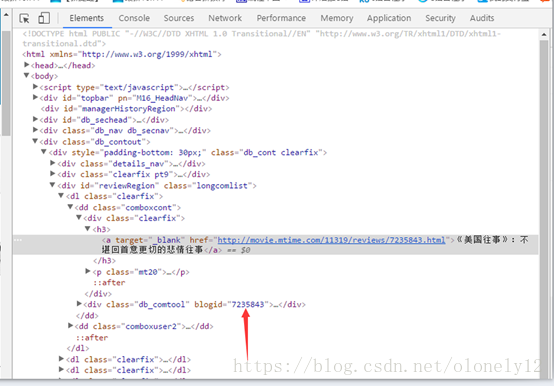
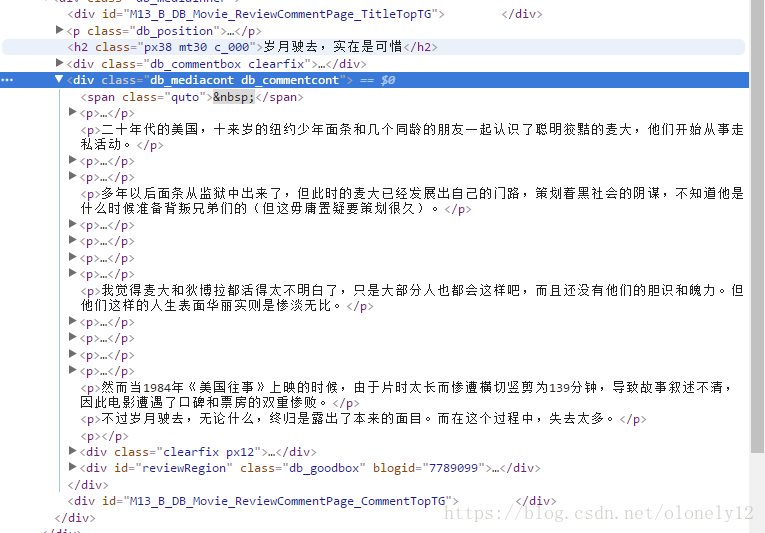
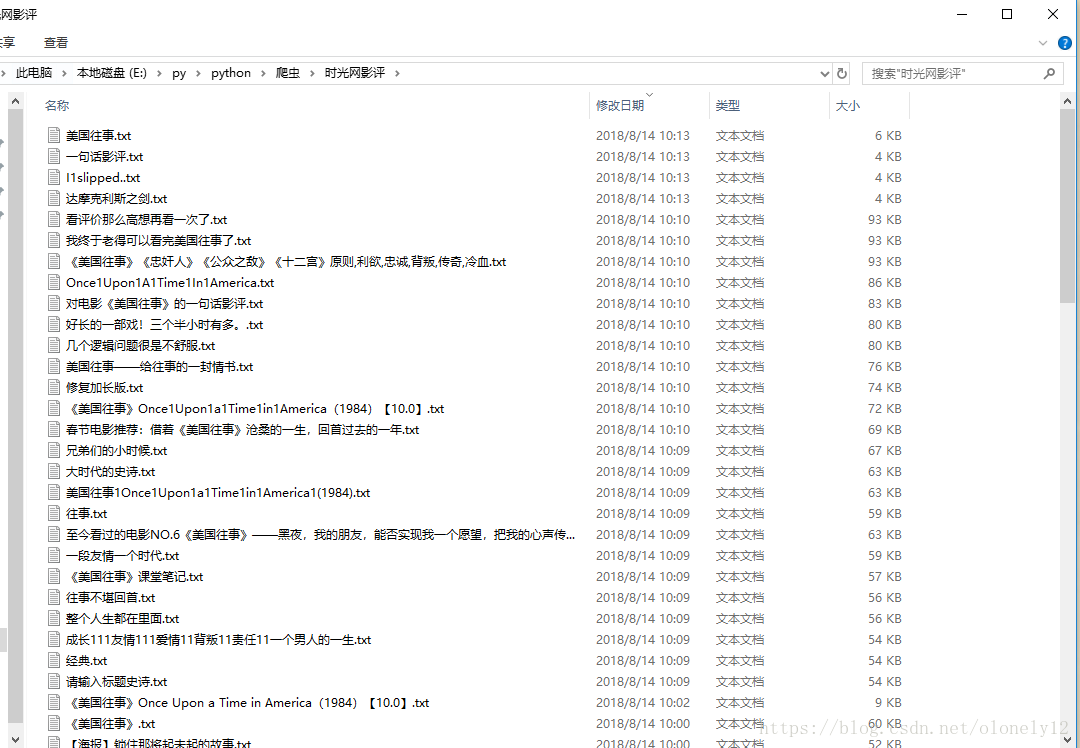
最近看了美国往事这部电影。于是就想到最近刚学的爬虫,就像试试把时光网影评爬取下来,并按照影评的名字存放在本地文件夹。 在长影评页面可以看到每篇文章的标题对应都有一个blogid,并且这个id对应该影评正文页的后缀 那么我们便可以通过这个id来实现获取当前页所有影评的地址 首先定义一个方法 id = []#存储电影id text = []#存储文本 name = ''#存储文章名字 def getUrl(url): response = requests.get(ur) html = response.text soup = BeautifulSoup(html, 'html.parser') main = soup.find_all(class_ = 'db_comtool')#找到所有标签为db_comtool的div里面内容 for i in main: id.append(i.get('blogid'))#将所有blogid的内容添加到id这个列表中 这个时候我们就得到了当前页所有的id 然后打开任意一篇文章查看源代码分析可以得出正文文本所在的 标签在一个class为db_mediacont db_commentcont的div里面文章的标题在一个class为px38 mt30 c_000的标签中 def getArticle(url): global text response = requests.get(url)#访问网站 html = response.text#保存网站源代码 bf = BeautifulSoup(html,'html.parser')#解析网址 a1 = bf.find_all(class_='db_mediacont db_commentcont')#获取正文文本 a2 = bf.find_all(class_='px38 mt30 c_000')#获取文章标题 for each in a1: text.append(re.sub('[\t\n]', "", re.sub(r']+>', "", str(each))))#利用正则表达式过滤掉无用内容 for each in a2: name = (re.sub('[\t\n]', "", re.sub(r']+>', "", str(each)))) f = open('时光网影评/%s.txt'%name, 'w') # 首先先创建一个文件对象,打开方式为w,名字为刚才得到的name for each in text: f.writelines(each.encode("gbk", 'ignore').decode("gbk", "ignore")) # 用readlines()方法写入文件 text = []#清空text 然后将网址放入函数中打开 for i in range(1,15): ur = 'http://movie.mtime.com/11319/comment-{}.html'.format(i)#自动翻页 getUrl(ur) for i in id: url = 'http://movie.mtime.com/11319/reviews/{}.html'.format(i)#自动访问每篇影评的对应地址 getTitle(url) 最后可以看到已经成功的将影评保存在本地了。 |
【本文地址】