| 使用Python批量处理Excel的内容 | 您所在的位置:网站首页 › vba读取文件夹及子文件夹下所有文件名 › 使用Python批量处理Excel的内容 |
使用Python批量处理Excel的内容
|
正文共:1500 字 10 图,预估阅读时间:1 分钟 在前面的文章中(如何使用Python提取Excel中固定单元格的内容),我们介绍了如何安装Python环境和PyCharm工具,还利用搭好的环境简单测试了一下ChatGPT提供的脚本程序。 简单回顾一下上次的操作过程: 首先,我们创建了一个记事本新文件;然后,将ChatGPT提供的示例代码复制粘贴到了文件中;接着,保存文件并将文件名后缀改为了.py,并直接双击运行此文件;接下来,在打开的PyCharm工具中,我们尝试执行了脚本,主要报错是缺少对应的Python库和依赖关系。
对于缺少的组件,我们在PyCharm的顶部菜单中,选择“File”下的“Settings”打开设置对话框;然后选择“Project”下的“Project Interpreter”,单击项目解释器列表上方的 “+”按钮来添加新的Python包,在弹出的对话框中,搜索“pandas”和“openpyxl”,单击“Install Package”按钮,等待安装完成。 Pandas是一个用于数据分析的强大Python库,它提供了各种数据结构和数据操作工具,可以轻松地进行数据处理、清洗和分析等任务。它有一个依赖包,那就是openpyxl,主要用于读写Excel文件,有了openpyxl,我们就可以使用Pandas库来读取和比较Excel文件了。 最后,我们终于执行成功,读取到了Excel中的单元格数据。
当然,在上个脚本中,我有点不满意的地方,那就是设置单元格的行号和列号有点不符合常规逻辑。 # 设置需要提取的单元格行号和列号row_index = 1col_index = 1
当我们需要读取B2的数据时,需要将行号设置为1、列号设置为1。同时,输出的数据格式也稍微有点简单,今天我们来对脚本做一个简单升级。 我们可以使用cell_positions来选择多个不连续的单元格,像下面这样: # 定义要提取的单元格位置cell_positions = { 'name': 'B2', 'phone': 'B3', 'address': 'B4', 'serv': 'B5'}注意,这里的单元格可以使用我们所熟悉的单元格格式B2;不同单元格之间的逗号不能省略。 然后就是路径问题,Windows的中文环境中经常会包含一些特殊字符,比如汉字、数字或者空格等,经常会出现识别错误。
这里我们用了一个1月份来命名文件夹,但是这里做了一个转义,转换成了特殊字符,导致操作系统无法正确解析文件路径,进而导致读取文件失败。
虽然没有报错,但是我们可以看到它没有读到任何文件。 对于这类不合法的文件路径,可能是包含了Windows不支持的特殊字符或者非法字符,还有可能是路径名过长等原因。该问题一般有以下几种方法解决方案: 1、修正文件路径:检查您的文件路径是否包含了非法字符或者过长的路径名,如果有,将其修改为合法的路径; 2、使用原始字符串表示法:将文件路径使用原始字符串表示法(在字符串前面加上r或R)来避免转义字符和特殊字符的影响。 3、使用os.path.join函数构造文件路径:该函数会自动处理不同操作系统的路径分隔符,并确保生成的路径是合法的。 这里我是用了最常用的第2种解决方案,在在字符串前面加上r之后,检查就没有错误了。
对于该目录下的子目录,我们可以使用os.walk()函数来遍历指定文件夹下的所有文件和子文件夹,并逐个读取Excel文件。这里可以直接指定,也可以使用前面通过folder_path定义的文件夹路径变量。
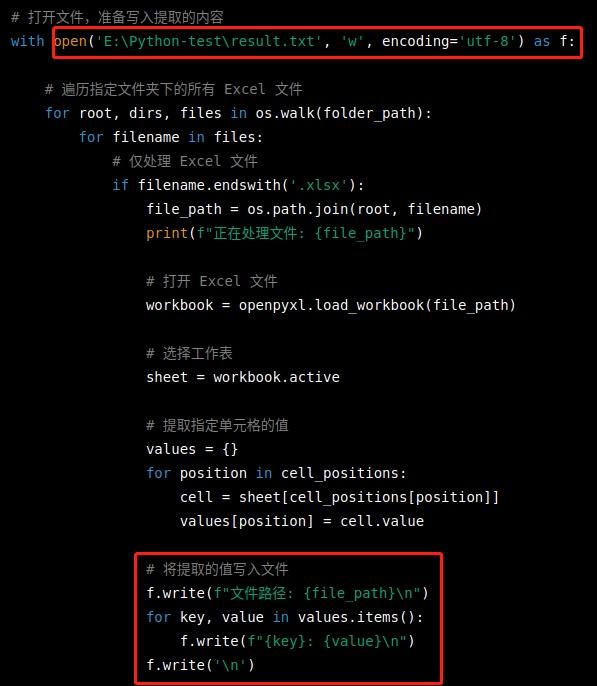
最后,如果我们要将提取的内容保存到一个文本文件中,也可以使用Python的文件操作来打开指定文件并写入。
在上面的代码中,我们首先使用with open()语句打开要写入的文件,并使用'w'参数将打开文件的模式指定为写入模式。然后,在遍历文件夹和读取Excel文件时,我们将提取的内容写入到该文件中。具体来说,我们在遍历每个Excel文件时,将文件路径和提取的值写入到文件中,并在每个Excel文件处理完后,在文件中添加一个空行。 最后,整合一下,我们就得到了完整的脚本。 import osimport openpyxl# 定义要提取的单元格位置cell_positions = { 'name': 'B2', 'phone': 'B3', 'address': 'B4', 'serv': 'B5'}# 定义要处理的文件夹路径folder_path = 'C:\python-test'# 打开文件,准备写入提取的内容with open(r'C:\python-test\result.txt', 'w', encoding='utf-8') as f: # 遍历指定文件夹下的所有 Excel 文件 for root, dirs, files in os.walk(folder_path): for filename in files: # 仅处理 Excel 文件 if filename.endswith('.xlsx'): file_path = os.path.join(root, filename) print(f"正在处理文件: {file_path}") # 打开 Excel 文件 workbook = openpyxl.load_workbook(file_path) # 选择工作表 sheet = workbook.active # 提取指定单元格的值 values = {} for position in cell_positions: cell = sheet[cell_positions[position]] values[position] = cell.value # 将提取的值写入文件 f.write(f"文件路径: {file_path}\n")forkey,valueinvalues.items():f.write(f"{key}:{value}\n")f.write('\n')运行看一下效果。
因为print()函数中我们没有再显示结果数据,所以仅显示了文件信息。然后我们打开记事本文件看一下。
OK,达到测试目的。
长按二维码关注我们吧
如何使用Python提取Excel中固定单元格的内容 配置openVPN使用用户名密码认证 解决openVPN的递归路问题还是要从服务器端下手 openVPN客户端连接指南 Ubuntu系统如何连接或断开openVPN 在SD-WAN网络中应用OpenVPN,chatGPT是这样想的 基于CentOS部署SmartDNS chatGPT又火了,用openAI写文章到底靠不靠谱? DDNS配置详解 DDNS如何应用到SD-WAN网络中? 家庭宽带的公网IPv4地址到底封了多少端口? 用SNMP模仿Zabbix读取设备接口流量 CentOS 7多网卡配置(最小化安装) |












【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |