| 详解带RLHF的类ChatGPT:从TRL、ChatLLaMA到ColossalChat、DSC | 您所在的位置:网站首页 › trl和tha › 详解带RLHF的类ChatGPT:从TRL、ChatLLaMA到ColossalChat、DSC |
详解带RLHF的类ChatGPT:从TRL、ChatLLaMA到ColossalChat、DSC
|
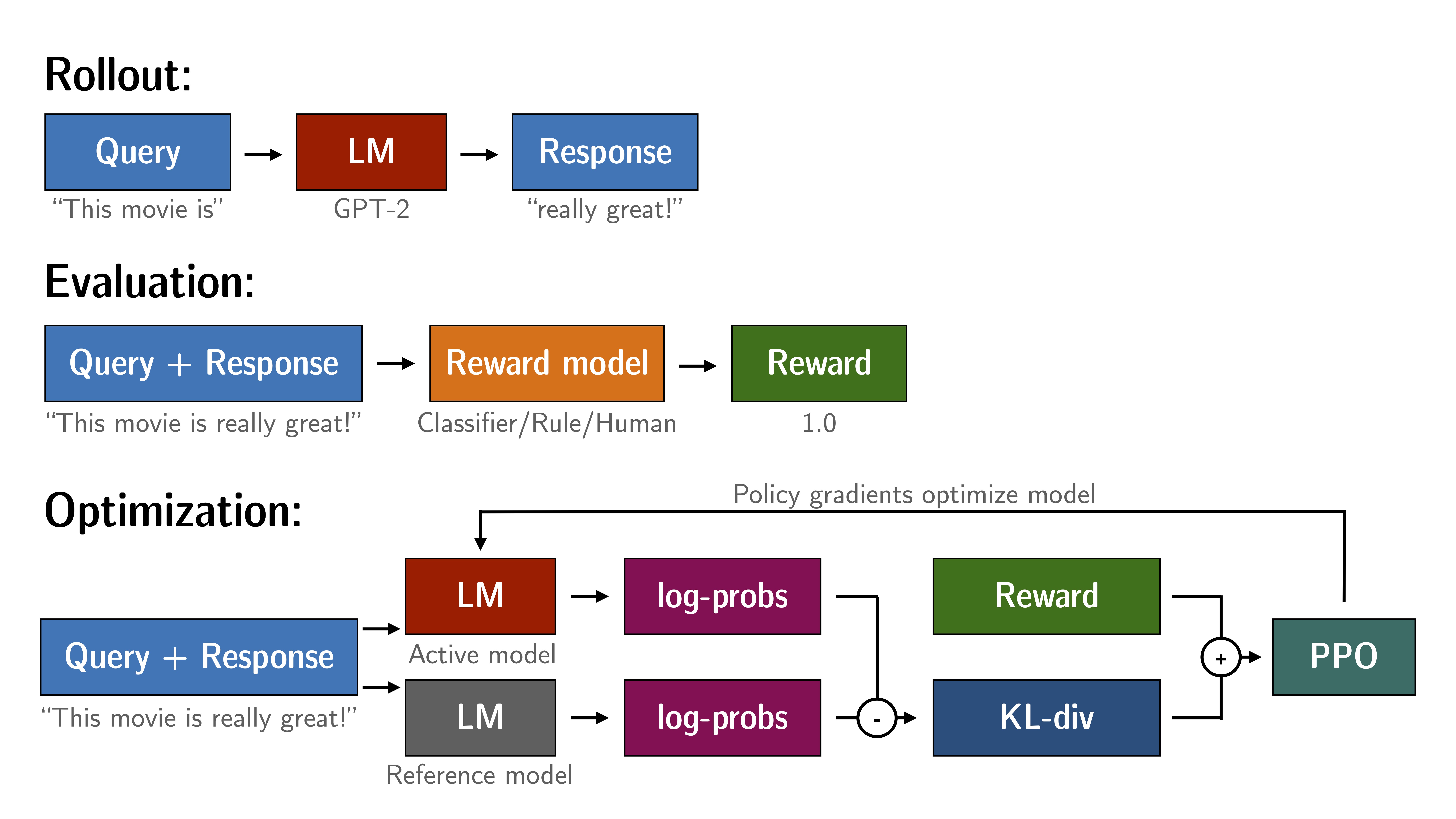
本文为《类ChatGPT逐行代码解读》系列的第二篇,上一篇是:从零实现Transformer、ChatGLM-6B:从位置编码/缩放点积注意力/多头注意力开始 本文模型的特点是都加了RLHF,对于这4个模型而言:TRL、ChatLLaMA、ColossalChat、DeepSpeed Chat 如果只关注两个 则可以更多关注下ColossalChat、DeepSpeed Chat,原因在于ColossalChat给的图示特别好,而DeepSpeed Chat的实现很清晰如果有读者说 就只想看一个,则推荐DeepSpeed Chat(简称DSC),特别是DSC会给你一个完整而通透的“PPO算法/RLHF”的代码实现全流程,好的资料可以让你事半功倍总之,微软这个DeepSpeed Chat实现的不错,抠完它的关键代码后,你会发现和之前本博客内另一篇写的原理部分都一一对应起来了(如果你还没看过原理,建议先看此文:ChatGPT技术原理解析,只有懂原理才能更好的理解实现或实际实现,特别是该文的第三部分 ),而把论文、原理/算法、公式、代码一一对应,可以让你的理解有个质变 本文最早的标题是:从零实现带RLHF的类ChatGPT:从TRL/ChatLLaMA/ColossalChat到DeepSpeed Chat,后来因为要不断扩展DSC的内容,为避免本文越写越长,故最终分出了两篇文章 本文侧重:TRL、ChatLLaMA、ColossalChat新文侧重:从零实现带RLHF的类ChatGPT:逐行解析微软DeepSpeed Chat 第一部分 PPO算法微调LM的TRL包 1.1 TRL包:类似ChatGPT训练阶段三的PPO方式微调语言模型通过《ChatGPT技术原理解析》一文,我们已经知道了ChatGPT的三阶段训练过程,其中,阶段三的本质其实就是通过PPO的方式去微调LM GitHub上有个TRL(Transformer Reinforcement Learning,基于『Hugging Face开发的Transformer库』),便是通过PPO的方式去微调LM,需要的数据便是三元组「query, response, reward」,具体如下图所示
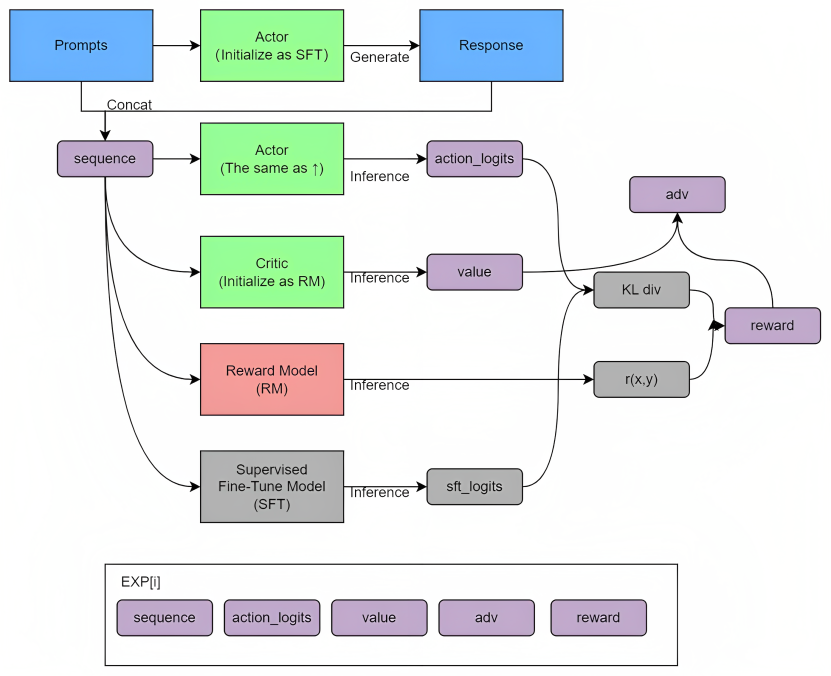
PPO算法是一种具体的Actor-Critic算法实现,比如在对话机器人中,输入的prompt是state,输出的response是action,想要得到的策略就是怎么从prompt生成action能够得到最大的reward,也就是拟合人类的偏好。具体实现时,可以按如下两大步骤实现 首先定义4个模型:Actor(action_logits)、SFT(sft_logits)、Critic(value)、RM「r(x, y)」,和kl_div、reward、优势函数adv 从prompt库中采样出来的prompt在经过SFT(微调过GPT3/GPT3.5的模型称之为SFT)做generate得到一个response,这个『prompt + response』定义为sequence(这个采样的过程是批量采样进行generate,得到一个sequence buffer),然后这个sequence buffer的内容做batched之后输入给4个模型做inference
以下是计算策略损失和价值损失的关键代码(来自trl/ppo_trainer.py at main · lvwerra/trl · GitHub的第971-1032行),且为方便大家阅读时一目了然,我特意给每一行的代码都加上了注释 def loss( self, old_logprobs: torch.FloatTensor, # 旧的对数概率,是前一步的策略输出 values: torch.FloatTensor, # 价值函数的输出 rewards: torch.FloatTensor, # 从环境中得到的奖励 logits: torch.FloatTensor, # 策略网络的原始输出(未经softmax) vpreds: torch.FloatTensor, # 价值函数的预测值 logprobs: torch.FloatTensor, # 当前策略输出的对数概率 mask: torch.LongTensor, # 用于忽略某些元素(如填充元素)的掩码 ): lastgaelam = 0 # 初始化lastgaelam,用于计算广义优势估计(GAE) advantages_reversed = [] # 初始化一个空列表,用于存储计算出的逆序优势值 gen_len = rewards.shape[-1] # 获取奖励的长度,即序列的长度 values = values * mask # 使用掩码对值进行过滤 rewards = rewards * mask # 使用掩码对奖励进行过滤 # 反向遍历时间步,计算每一步的优势值 for t in reversed(range(gen_len)): # 获取下一个状态的值 nextvalues = values[:, t + 1] if t < gen_len - 1 else 0.0 # 计算TD误差 delta = rewards[:, t] + self.config.gamma * nextvalues - values[:, t] # 更新lastgaelam lastgaelam = delta + self.config.gamma * self.config.lam * lastgaelam # 将计算出的优势值添加到列表中 advantages_reversed.append(lastgaelam) # 对逆序的优势值进行逆序,使其按照原始顺序,然后将其堆叠起来并进行转置,得到最终的优势值 advantages = torch.stack(advantages_reversed[::-1]).transpose(0, 1) # 计算回报,即优势值加上对应的value值 returns = advantages + values # 对优势值进行掩码白化,即只对掩码部分进行白化处理 advantages = masked_whiten(advantages, mask) # 从计算图中分离优势值,防止反向传播 advantages = advantages.detach() # 对预测值进行剪裁,防止预测值偏离真实值过远 vpredclipped = clip_by_value(vpreds, values - self.config.cliprange_value, values + self.config.cliprange_value) # 计算预测值与回报之间的平方损失 vf_losses1 = (vpreds - returns) ** 2 # 计算剪裁后的预测值与回报之间的平方损失 vf_losses2 = (vpredclipped - returns) ** 2 # 计算价值函数的损失,选择两种损失中的较大者,然后计算其平均值,并乘以0.5 vf_loss = 0.5 * masked_mean(torch.max(vf_losses1, vf_losses2), mask) # 计算剪裁损失比原始损失大的部分的平均值 vf_clipfrac = masked_mean(torch.gt(vf_losses2, vf_losses1).double(), mask) # 计算新旧策略的比例 ratio = torch.exp(logprobs - old_logprobs) # 计算策略梯度损失 pg_losses = -advantages * ratio # 计算剪裁后的策略梯度损失 pg_losses2 = -advantages * torch.clamp(ratio, 1.0 - self.config.cliprange, 1.0 + self.config.cliprange) # 计算策略损失,选择两种损失中的较大者,然后计算其平均值 pg_loss = masked_mean(torch.max(pg_losses, pg_losses2), mask) # 计算剪裁损失比原始损失大的部分的平均值 pg_clipfrac = masked_mean(torch.gt(pg_losses2, pg_losses).double(), mask) # 计算总损失,等于策略损失加上价值损失 loss = pg_loss + self.config.vf_coef * vf_loss上面代码中 有两点值得解释下 计算回报时,为何是优势值加上对应的value值 别忘了,根据本博客中另一篇文章《RL极简入门》可知 优势函数A(s,a)定义为Q(s,a) - V(s),其中Q(s,a)是动作价值函数,表示在状态s采取动作a所能获得的预期回报 而V(s)则是状态价值函数,表示在状态s下依据当前策略所能获得的预期回报 因此,当我们计算returns时,实际上是在计算Q(s,a)的估计值,即预期的动作价值 所以,returns = advantages + values = (Q(s,a) - V(s)) + V(s) = Q(s,a) 这样,returns就代表了我们预期能在状态s采取动作a获得的回报 为何计算策略损失和价值损失时,要先裁剪,然后对比裁剪前后的损失,最后取两者之中更大的值呢? 首先关于计算策略损失时,为何对比截断前后的值 这点可以回顾下本博客内的《ChatGPT技术原理解析一文》或RL极简入门由于LLaMA没有使用RLHF方法,初创公司 Nebuly AI开源了RLHF版的LLaMA,即ChatLLaMA 2.1 三套数据集:分别训练actor、reward、rlhf其训练过程类似 ChatGPT,而通过本博客内的《ChatGPT技术原理解析》3.1节,可知训练三个模型(SFT、RM、RL/PPO)得先准备三套数据集 2.1.1 actor_training_data,即用于微调GPT3所用的数据actor_training_data,即用于微调GPT3所用的数据,比如[ { "user_input": "here the input of the user", "completion": "here the model completion" } ] actor_training_data如何而来呢,有4项途径 使用 100% 合成数据,可以通过运行以下命令综合生成数据集:python artifacts/generate_actor_dataset.py,注:此命令需要订阅OpenAI,生成完整数据集的davinci-003成本约为 200 美元(当然 也有免费的途径)使用具有辅助交互的开源数据集之一,目前支持:Anthropic HH RLHF:这个数据集由结构化的 {question/answer pairs} 组成,包括机器人选择和拒绝的答案;Stanford Human Preferences Dataset (SHP):这个数据集是从选定的“提问”subreddits 中挑选出来的,并且包括基于最受支持的回答的范围广泛的 {question/answer pairs} 的问题 可以运行以下命令下载数据集: python artifacts/download_dataset.py --path --number_of_samples其中: 对于 StanfordNLP/SHP 数据集,可以是“SHP”或“ARLHF”,对于 Anthropic/hh-rlhf 数据集,可以分别是“SHP”或“ARLHF”; 是要创建数据集的文件夹路径; 是组成 reward_dataset.json 的样本数 使用 100% 个性化数据集 用户提供自己的个性化完整数据集,数据集必须是具有以下格式的 JSON 文件:[ { "user_input": "here the input of the user", "completion": "here the model completion" } ] 其中列表包含多个dictionaries,每个dictionary 对应一个数据样本,建议使用超过 1000 个数据样本来进行对actor的训练 创建完整的数据集,增加一些自定义数据样本,数据集可以从用户提供的一些提示+响应示例中综合生成(少数 => 10) 2.1.2 reward_training_data,用于训练一个奖励模型的数据reward_training_data,用于训练一个奖励模型的数据,包含三部分的数据: i) prompts, ii) completion iii) score of the completion assigned accordingly to the user feedback (the Human Feedback in RLHF,即对各个回答的评分score) 示例如下[{ "user_input": "...", "completion": "...", "score": 1 }, ... ] 同样的,奖励数据怎么来呢?有以下三种方式 be synthetically scored using a LLM as Human Feedback LLM 模型用于为每个entry计算分数 为此,LLM 需要一个提示模板,其中包含评估生成的文本的所有说明(比如奖励规则,什么情况下该奖 什么情况下不奖都得十分明确)。为此,您应该将key reward添加到文件中templates.json,比如:{ "reward": "Here is the template for the reward model. The rules are:\n\n1.Rule 1\n\n2. Rule 2" } 如果未提供模板,则使用默认模板artifacts/generate_rewards.py,注:所有模板都必须保存在一个名为 .json 的 JSON 文件中templates.json 获得unlabelled dataset后,您可以通过运行以下命令生成分数: python artifacts/generate_rewards.py --model --temperature --max_tokens --reward_template其中,要评分的reward dataset的路径; 用于奖励的模型,默认建议使用text-davinci-003 用于对模型进行评分的temperature,temperature =0.1; ,这是包含用于生成奖励的模板的文件的路径,如果未提供路径,将使用默认模版 这里值得注意的是,与instructGPT中的「人类通过对模型的输出进行排序,然后利用这些排序数据去训练一个RM」不同,ChatLLaMA直接训练一个RM对模型的输出进行打分 比如0-5分,且与人类的打分做MSE损失(减少RM打分与人类打分之间的差距) REWARD_TEMPLATE = dict( template=( "You have to evaluate the following chat with a score" "between 0 and 5"最后,可能你会问,从哪里看出来的用的MSE损失,答案是从另外一个文件里看出来的(具体是chatllama/rlhf/reward.py 文件的第282行) class RewardTrainer: """Class to train the reward model def __init__(self, config: ConfigReward) -> None: # save the config self.config = config # load the model self.reward = RewardModel(config) # optimizer self.optimizer = torch.optim.AdamW( self.reward.parameters(), lr=config.lr ) # loss function self.loss_function = torch.nn.MSELoss() // ...用户提供他们个性化的完整数据集(至少需要 100 个数据样本),但数据集必须是以下格式的 JSON 文件,取名为:reward_training_data.json [ { "user_input": "here type the user input", "completion": "here type the completion", "score": 4.0 }, { "user_input": "here type the user input", "completion": "random garbage", "score": 0.0 } ]用户提供的少量示例和使用 LLM 综合扩展的数据集(通过self-instruct的方式提示LLM产生更多所需要的指令数据) 2.1.3 rlhf_training_data,通过RL方法不断优化迭代最优策略的数据It can be provided in 2 different ways: Few examples provided by the user and dataset synthetically expanded using LLM(依然可以继续通过self-instruct的方式提示LLM产生更多所需要的指令数据) 需要将key rlhf添加到templates.json文件中,其中包含有关要执行的任务的信息以及 LLM 生成所需的额外上下文,这是模板的示例(所有模板必须保存在一个名为templates.json): { "rlhf": "Here is the template for the generating RLHF prompts. The task we want to perform is ..." } The user provides the full dataset with possible interactions with the model 数据集需要包含超过 1000 个提示示例(文件命名为rlhf_training_data.json): [ { "user_input": "here the example of user input" } ] 2.2 训练流程:SFT、RM、RL/PPO训练三步骤 2.2.1 RewardTrainer 类的 train 方法训练一个奖励函数chatllama/rlhf/reward.py中 首先定义了一个名为 Reward Model 的类,作为奖励模型或批评者模型(Critic Model)。Reward Model 是一个基于语言模型的模型,附加了一个头部head,用于预测给定的 token 序列的奖励(一个标量值),最后将CriticModel类设置为RewardModel类,以保持命名一致性 之后,定义类:RewardDatase用于训练奖励模型的数据集 RewardDataset 类是一个继承自 Dataset 的自定义数据集类,它的作用是从给定的 JSON 文件中读取数据,并将数据整理成适当的格式。JSON 文件应包含以下格式的数据: class RewardDataset(Dataset): """Dataset class for the reward model read a json file with the following format: [ { "user_input": "...", "completion": "...", "score": ... }, ... ] Where: user_input: the initial input of the user completion: the completion generated by the model score: the score given by the user to the completion (or by the LLM) """其中 user_input 是用户的初始输入,completion 是模型生成的补全,而 score 是用户或LLM给予补全的分数 再定义一个RewardTrainer 类用于训练奖励模型,它初始化奖励模型、优化器、损失函数(具体如上文所说,或如282行所述的MSE损失函数)、数据集和数据加载器等。此外,它还支持使用 DeepSpeed 或 Accelerate(两种高性能深度学习训练框架)进行训练 RewardTrainer 类的主要方法有: train:训练奖励模型。它执行训练循环,包括前向传播、计算损失、反向传播和优化器更新。在每个周期结束时,它还可以对模型进行验证(如果提供了验证数据集的话) 首先是初始化 # 定义构造函数 def __init__(self, config: ConfigReward) -> None: # 保存配置对象 self.config = config # 加载模型 self.reward = RewardModel(config) # 创建优化器 self.optimizer = torch.optim.AdamW( self.reward.parameters(), lr=config.lr ) # 定义损失函数,用的交叉熵损失 self.loss_function = torch.nn.MSELoss() # 检查验证数据集是否存在 self.validation_flag = False if config.validation_dataset_path is not None: self.validation_flag = True # 创建数据集和数据加载器 self.train_dataset = RewardDataset(config.train_dataset_path) self.train_dataloader = DataLoader( self.train_dataset, batch_size=config.batch_size ) # 如果有验证数据集,则创建验证数据集和数据加载器 if self.validation_flag: self.eval_dataset = RewardDataset(config.validation_dataset_path) self.validation_dataloader = DataLoader( self.eval_dataset, batch_size=config.batch_size ) # 初始化学习率调度器 - 学习率将下降到初始值的10% self.scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts( self.optimizer, T_0=len(self.train_dataset) // config.batch_size, T_mult=1, eta_min=config.lr * 0.1, last_epoch=-1, ) save_checkpoint:保存模型的检查点。在训练过程中,可以定期将模型的当前状态(包括模型参数、优化器状态和训练统计信息)保存为检查点,以便在需要时恢复训练load_checkpoint:从检查点恢复模型。如果在训练过程中找到检查点文件,则该方法将从检查点恢复模型状态,并返回从何处恢复训练的周期和步骤接下来,是具体的训练过程 def train( self, ) -> None: # 训练奖励模型 # # 打印开始训练奖励模型的消息 print("Start Training the Reward Model") # 如果启用了 DeepSpeed,从训练数据加载器获取批次大小 if self.config.deepspeed_enable: batch_size = self.train_dataloader.batch_size else: batch_size = self.config.batch_size # 从配置获取批次大小 epochs = self.config.epochs # 从配置获取训练轮次 device = self.config.device # 从配置获取设备 # 从配置获取每次打印的迭代次数 iteration_per_print = self.config.iteration_per_print # 从配置获取检查点步骤 checkpoint_steps = self.config.checkpoint_steps # 计算训练数据集的迭代次数 n_iter = int(len(self.train_dataset) / batch_size) # 加载检查点并获取开始轮次和开始步骤 start_epoch, start_step = self.load_checkpoint() # 初始化检查点计数器 cnt_checkpoints = 1 # 训练循环 for epoch in range(start_epoch, epochs): # 对于每个轮次 self.reward.train() # 将奖励模型设置为训练模式 # 遍历训练数据加载器中的每个输入 for i,inputs in enumerate(self.train_dataloader): # 如果从检查点恢复,则跳过步骤 if i < start_step: continue # 获取输入 input_text = inputs[0] # 获取输入文本 score = inputs[1] # 获取分数 # 对输入进行分词 with torch.no_grad(): # 禁用梯度计算 input_tokens = self.reward.tokenizer( input_text, return_tensors="pt", truncation=True, padding=True, ) output = torch.as_tensor( score, dtype=torch.float32, device=device ) # 将分数转换为张量 # 前向传播 if self.config.deepspeed_enable: # 如果启用了 DeepSpeed est_output = self.model_engine( input_tokens["input_ids"].to(device), input_tokens["attention_mask"].to(device), )[:, -1] # 使用模型引擎进行前向传播 else: est_output = self.reward.get_reward( input_tokens["input_ids"].to(device), input_tokens["attention_mask"].to(device), ) # 使用奖励模型进行前向传播 # 计算损失函数 loss = self.loss_function(est_output, output) # 将损失添加到训练统计数据中 self.training_stats.training_loss.append(loss.item()) # 反向传播 if self.config.deepspeed_enable: # 如果启用了 DeepSpeed self.model_engine.backward(loss) # 使用模型引擎进行反向传播 self.model_engine.step() # 更新模型参数 elif self.config.accelerate_enable: # 如果启用了加速 self.optimizer.zero_grad() # 将优化器的梯度归零 self.accelerator.backward(loss) # 使用加速器进行反向传播 self.optimizer.step() # 更新模型参数 self.scheduler.step() # 更新学习率调度器 else: self.optimizer.zero_grad() # 将优化器的梯度归零 loss.backward() # 进行反向传播 self.optimizer.step() # 更新模型参数 self.scheduler.step() # 更新学习率调度器 # 打印进度,如果当前迭代次数是打印间隔的整数倍 if i % iteration_per_print == 0: print( f"Epoch: {epoch+1}/{epochs}, " f"Iteration: {i+1}/{n_iter}, " f"Training Loss: {loss.item()}" ) printed_est_output = [ round(float(x), 1) for x in est_output.cpu().tolist() ] # 对估计输出进行四舍五入 print( "prediction", printed_est_output, "target", score.cpu().tolist(), ) # 打印预测值和目标值 # 保存检查点,如果检查点计数器是检查点步骤的整数倍 if cnt_checkpoints % checkpoint_steps == 0: self.save_checkpoint(epoch, i, epochs, n_iter) # 保存检查点 cnt_checkpoints = 1 # 重置检查点计数器 else: cnt_checkpoints += 1 # 检查点计数器加一 # 验证 if self.validation_flag: # 如果启用了验证 self.reward.eval() # 将奖励模型设置为评估模式 with torch.no_grad(): # 禁用梯度计算 for i, (text, score) in enumerate( self.validation_dataloader ): # 遍历验证数据加载器中的每个输入 # 对输入进行分词 input_tokens = self.reward.tokenizer( text, return_tensors="pt", padding=True ) # 对输入文本进行分词 input_tokens = input_tokens.to(device) # 将输入令牌移动到设备上 # TODO: 检查输入令牌的长度,如果过长可能会导致问题 output = torch.tensor(score, dtype=torch.float32).to( device ) # 将分数转换为张量并移动到设备上 # 前向传播 est_output = self.reward.get_reward( input_tokens["input_ids"], input_tokens["attention_mask"], ) # 使用奖励模型进行前向传播 # 计算损失函数 loss = self.loss_function(est_output, output) # 将损失添加到训练统计数据中 self.training_stats.validation_loss.append(loss.item()) # 打印进度,如果当前迭代次数是打印间隔的整数倍 if i % iteration_per_print == 0: print( f"Epoch: {epoch+1}/{epochs}, " f"Iteration: {i+1}/{n_iter}, " f"Validation Loss: {loss.item()}" ) # 打印验证进度 # 在恢复训练后重置 start_step start_step = 0 # 训练结束后保存模型 self.reward.save() # 保存奖励模型总之,在 RewardTrainer 类的 train 方法中 首先会尝试从检查点恢复模型(如果有的话); 然后,它会遍历数据加载器中的所有输入,对每个输入执行前向传播、计算损失、反向传播和优化器更新;在每个周期结束时,如果提供了验证数据集,还会对模型进行验证; 最后,在训练完成后,将保存模型 2.2.2 通过chatllama/rlhf/actor.py再训练一个actor此外,项目通过chatllama/rlhf/actor.py再训练一个actor,比如通过train方法训练一个基于transformer的模型,它包括了数据处理、模型训练、验证和模型保存等操作 定义train方法,它没有返回值。打印训练开始信息。获取配置参数,包括批量大小、训练轮数、设备和检查点步数。计算迭代次数。加载模型检查点并获取开始的轮数和步数。如果从头开始训练,清空训练统计。初始化检查点计数器。定义训练循环,其中包括: 设置模型为训练模式。遍历训练数据加载器。如果恢复训练,跳过已经完成的步数。对输入文本进行标记化处理。将输入文本分割成tokens和mask。添加结束符(EOS)。将输入文本分割成输入和输出。将输入文本移至设备。执行前向传播。计算损失。执行反向传播和优化。打印训练进度。定期保存检查点和训练统计。进行验证(如果启用验证的话):设置模型为评估模式。使用torch.no_grad()禁用梯度计算。遍历验证数据加载器。对输入文本进行标记化处理。将输入文本分割成验证输入和输出。执行前向传播。计算损失。更新验证损失统计。打印验证进度。在恢复训练后,将start_step重置为0。训练完成后,保存模型。打印训练结束信息 2.2.3 通过PPO算法优化强化学习任务中的策略(actor)和价值(critic)网络有了奖励函数和actor,便可以通过PPO算法优化强化学习任务中的策略(actor)和价值(critic)网络,具体如下图,设置内外两个循环 外层循环迭代训练轮次(epochs)内层循环遍历数据加载器(dataloader)中的批次(batches),在每次迭代中,它会处理一批数据,包括状态、动作、价值等,这些数据用于训练智能体-评论家模型
在内层循环中依次做如下处理(以下代码来源于:chatllama/chatllama/rlhf/trainer.py ): 首先是导入必须的库和模块,当然,主要是ActorCritic类 导入所需的库和模块。change_tokenization函数:用于在两个不同的分词器之间转换给定的tokens。check_model_family函数:检查两个配置是否属于相同的模型家族。ActorCritic类:包含了actor和critic模型,并用于在训练actor过程中为给定的序列生成动作和值。它包括以下方法: __init__:初始化actor和critic模型 def __init__(self, config: Config) -> None: super().__init__() self.config = config self.actor = ActorModel(config.actor) # check if critic must be initialized from reward model ModelLoader.init_critic_from_reward(config.critic) self.critic = CriticModel(config.critic) # if the actor and critic use the same tokenizer is set to True self.use_same_tokenizer = False # debug flag self.debug = config.actor. load:加载模型,但未实现。save:将模型保存到路径。forward:基于给定的整个序列,使用actor的forward方法获取序列中每个token的logits,并使用critic的forward方法获取每个生成步骤的值。这个代码主要用于强化学习训练自然语言生成模型。ActorCritic类是其中的核心部分,它包含了actor和critic模型。这两个模型在训练过程中相互协作,用于生成动作和值。 其次,主要是关于一个用于生成动作、动作逻辑、价值和序列的生成函数,以及用于存储训练数据和生成训练示例的类 首先定义了一个名为generate的函数,它使用了@torch.no_grad()和@beartype修饰器。这个函数接收四个参数,分别是states_actor、states_mask_actor和states_critic,并返回一个元组 这个函数的主要目的是从输入状态生成动作、动作逻辑、价值和序列。它首先从actor模型生成动作序列,然后创建一个用于actor序列的mask。接下来,它检查是否需要为critic使用不同的编码。如果需要,它将使用change_tokenization函数来更改序列的编码。接着,它生成动作逻辑和价值。如果处于调试模式,将打印一些调试信息。接下来,代码定义了一个名为Memory的namedtuple,用于存储每个经验的数据。Memory包含了11个字段,如states_actor、actions、values等。然后定义了一个名为ExperienceDataset的类,它继承自torch.utils.data.Dataset。这个类用于训练actor-critic模型。它接收一个memories参数和一个device参数。memories参数是一个包含Memory实例的双端队列。device参数表示要在哪个设备上进行计算。这个类实现了__len__和__getitem__方法,使其可以像普通的PyTorch数据集一样使用。最后,定义了一个名为ExamplesSampler的类,用于从JSON文件中读取示例并在需要时抽样。这个类接收一个表示文件路径的path参数。在初始化时,它从文件中读取数据,并将其存储在self.data中。它还实现了一个名为sample的方法,用于从数据中抽取指定数量的示例。再之后,定义了一个名为 RLTrainer 的类,用于使用强化学习训练一个Actor-Critic模型。该类具有多个属性和方法,用于训练过程中的各种操作。 在 __init__ 方法中,初始化了训练器的各个组件,包括Actor-Critic模型、actor和critic优化器、reward模型、用于存储训练统计数据和对话记录的类、以及示例采样器save_checkpoint 方法保存了当前状态的Actor-Critic模型的检查点,包括当前的训练轮数、actor和critic模型的状态字典,以及它们各自的优化器的状态字典。load_checkpoint 方法加载了Actor-Critic模型的检查点,包括训练轮数、actor和critic模型的状态字典,以及它们各自的优化器的状态字典。如果没有找到检查点,则返回轮数0。如果actor和critic的检查点存在差异,则从两者中最小的轮数开始训练。再之后,调用 learn 方法更新actor和critic模型,并保存训练统计数据和对话记录 使用智能体-评论家模型计算新的动作概率和价值 # get actor critic new probabilities and values actions_logits, values = self.actorcritic.forward( sequences_actor, sequences_mask_actor, sequences_critic, sequences_mask_critic, action_len_actor.item(), action_len_critic.item(), ) 计算动作的对数概率、熵和KL散度损失 # get action log prob actions_prob = ( torch.softmax(actions_logits, dim=-1).max(dim=-1).values ) actions_log_prob = torch.log(actions_prob + self.eps) # compute entropy,一般表示为-sum「p(x)logp(x)」 entropies = (actions_prob * actions_log_prob).sum(dim=-1) # compute KL divergence,一般表示为:-sum「p(x)log q(x)/p(x)」 kl_div_loss = ( (actions_prob * (old_actions_log_probs - actions_log_prob)) .sum(dim=-1) .mean() ) 计算重要性权重比率(ratios),即新旧策略的概率比 # compute ratios ratios = (actions_log_prob - old_actions_log_probs).exp() 计算PPO损失,包括优势函数的计算和PPO-clip算法的应用 首先我们回顾下强化学习极简入门一文里对『近端策略优化裁剪PPO-clip』的阐述对应的公式为 值得一提的是,这里确实容易引发疑惑,毕竟上面的policy loss已经对新旧策略的比值 ratios = (actions_log_prob - old_actions_log_probs).exp() 做了截断处理,而这里又加一个对新旧策略差值的KL散度约束,未免有多此一举之嫌,比如在instructGPT的原理中便只有两者其一:关于策略梯度的损失就一个policy loss 最终,总的损失函数为: 其中, 最后的最后,定义了一个 train() 方法,使用 actor-critic 算法训练强化学习模型。方法首先初始化各种设置,如训练的总 episode 数量、每个 episode 的最大步数、批次大小和训练设备等。然后检查要用于学习的记忆数量是否是批次大小的倍数,以及总步数是否是更新步数的倍数。 该方法初始化记忆,加载检查点(如果有的话),如果是从头开始的新训练,则清除会话记录。然后循环遍历 episode 和 timestep,从示例数据集中抽取样本,为 actor 和 critic 进行分词,生成动作和值的序列,计算动作日志概率,计算奖励。存储每个 episode/timestep 的记忆,并将完成(解码后的动作)记录在会话日志中。 在一定数量的 timestep 后,使用记忆进行学习,并计算平均奖励。该过程重复进行,直到训练完成。该方法在训练结束时保存模型和会话日志。 第三部分 ColossalChat:通过self-instruct技术指令微调LLaMA且加上RLHF 3.1 技术架构:通过self-instruct生成的中英双语数据集 + 三阶段训练方式据介绍(介绍页面,该页面的翻译之一,代码地址),Colossal-AI 开源了基于 LLaMA-7B 模型的包含完整 RLHF 流程的类 Chat 模型复现方案 ColossalChat 3.1.1 针对社交平台的种子数据且利用self-instruct 技术生成中英双语数据集ColossalChat 收集并清洗了社交平台上人们的真实提问场景作为种子数据集,然后利用 self-instruct 技术扩充数据(通过prompt OpenAI API,花费约 900 美元进行标注),最终生成了10.4万条问答的中、英双语数据集(这是数据的开源地址) 他们的说法是,对比其他 self-instruct 方法生成的数据集,该数据集的种子数据更加真实、丰富,生成的数据集涵盖的话题更多,该数据可以同时用于微调和 RLHF 训练,通过高质量的数据,ColossalChat 能进行更好地对话交互,同时支持中文
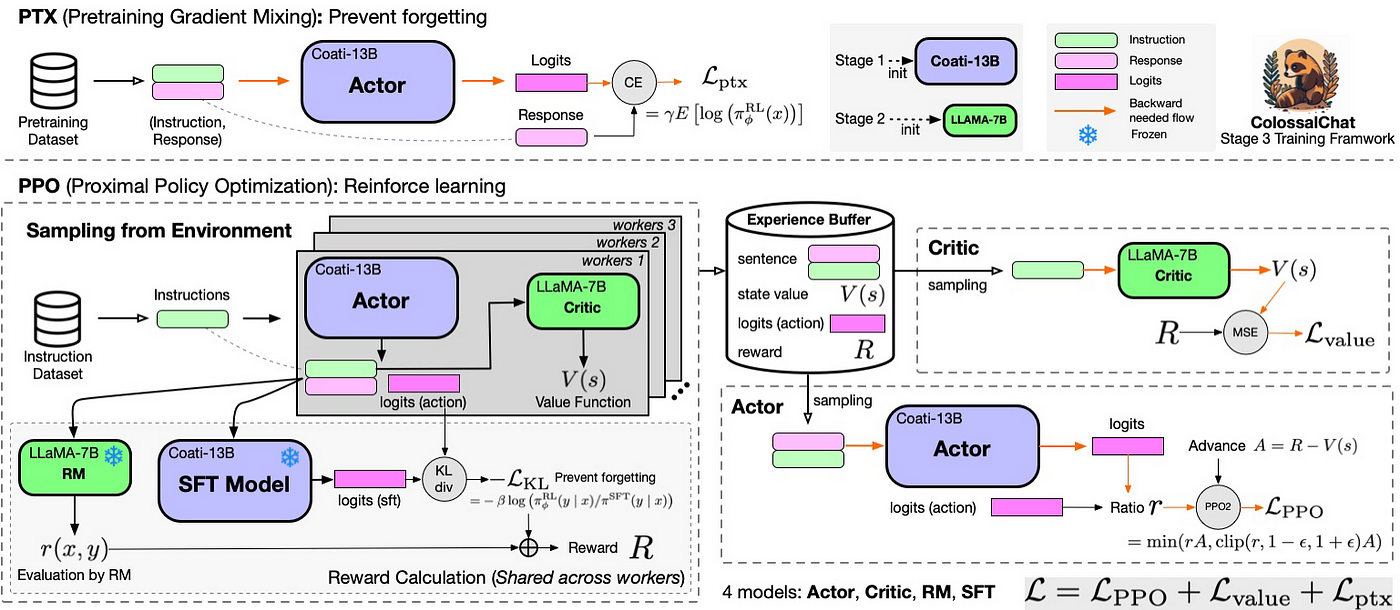
关于训练方式:类似instructGPT/ChatGPT的训练三步骤(如果忘了,务必复习下此文的3.1节) Stage1 是supervised-fintuning,即使用上文提到的数据集进行监督微调Stage2 训练一个奖励模型(初始化为阶段1的SFT模型),它通过模型对于同一个 prompt 的不同输出进行人工排序,根据排序结果监督训练出一个奖励模型Stage3 是通过阶段2训练出来的奖励函数微调出一个RL模型,微调过程中通过PPO算法限制RL模型的参数更新范围(以阶段1的SFT模型的策略为参考基准,PPO算法避免与基线模型SFT的策略偏离过远)具体而言,为两个阶段进行:
先看下整体的代码架构图
首先通过ColossalAI/applications/Chat/coati/trainer/sft.py,训练一个SFT模型 import math # 导入Python的数学库 import time # 导入Python的时间库 from abc import ABC # 从Python的抽象基类库中导入ABC基类 from typing import Optional # 导入Python类型注解库中的Optional, 表示某个类型值可能为空 import loralib as lora # 导入一个名为loralib的库并重命名为lora import torch # 导入PyTorch库 import torch.distributed as dist # 导入PyTorch分布式计算库 import wandb # 导入Weights & Biases库,一般用于实验跟踪和版本控制 from coati.models.loss import GPTLMLoss # 导入coati库中的GPTLMLoss模型 from torch import nn # 导入PyTorch的神经网络库 from torch.optim import Adam, Optimizer # 导入PyTorch优化器库中的Adam和Optimizer类 from torch.optim.lr_scheduler import LambdaLR # 导入PyTorch优化器库中的LambdaLR类,一般用于动态调整学习率 from torch.utils.data import DataLoader # 导入PyTorch数据处理库中的DataLoader类,用于加载数据 from torch.utils.data.distributed import DistributedSampler # 导入PyTorch分布式计算库中的DistributedSampler类,用于在分布式训练中采样数据 from tqdm import tqdm # 导入进度条库tqdm from transformers.tokenization_utils_base import PreTrainedTokenizerBase # 导入transformers库中的PreTrainedTokenizerBase类,用于处理预训练模型的令牌化 from transformers.trainer import get_scheduler # 导入transformers库中的get_scheduler函数,用于获取学习率调整策略 from colossalai.logging import get_dist_logger # 导入colossalai库中的分布式日志记录函数get_dist_logger from .strategies import Strategy # 导入当前目录下strategies文件中的Strategy类 from .utils import is_rank_0 # 导入当前目录下utils文件中的is_rank_0函数,用于检查当前进程是否为主进程 # 下面是定义一个名为SFTTrainer的类,该类继承自abc库的ABC抽象基类 class SFTTrainer(ABC): """ Trainer to use while training reward model. Args: model (torch.nn.Module): the model to train strategy (Strategy): the strategy to use for training optim(Optimizer): the optimizer to use for training train_dataloader: the dataloader to use for training eval_dataloader: the dataloader to use for evaluation batch_size (int, defaults to 1): the batch size while training max_epochs (int, defaults to 2): the number of epochs to train optim_kwargs (dict, defaults to {'lr':1e-4}): the kwargs to use while initializing optimizer """ # 下面是初始化函数,初始化SFTTrainer类的实例 def __init__( self, model, # 输入参数model,即将训练的模型 strategy: Strategy, # 输入参数strategy,即训练的策略 optim: Optimizer, # 输入参数optim,即训练的优化器 train_dataloader: DataLoader, # 输入参数train_dataloader,即训练的数据加载器 eval_dataloader: DataLoader = None, # 输入参数eval_dataloader,即评估的数据加载器,默认为None batch_size: int = 1, # 输入参数batch_size,即每批训练的样本数量,默认为1 max_epochs: int = 2, # 输入参数max_epochs,即训练的最大轮数,默认为2 accimulation_steps: int = 8, # 输入参数accimulation_steps,即梯度积累的步数,默认为8 ) -> None: # 初始化函数的返回值类型为None super().__init__() # 调用父类的初始化函数 self.strategy = strategy # 将输入参数strategy赋值给实例变量self.strategy self.epochs = max_epochs # 将输入参数max_epochs赋值给实例变量self.epochs self.train_dataloader = train_dataloader # 将输入参数train_dataloader赋值给实例变量self.train_dataloader self.eval_dataloader = eval_dataloader # 将输入参数eval_dataloader赋值给实例变量self.eval_dataloader # 调用策略的setup_model方法对模型进行设置,并将返回的模型赋值给实例变量self.model self.model = strategy.setup_model(model) if "DDP" in str(self.strategy): # 如果策略的字符串表示中包含"DDP" self.model = self.model.module # 将模型的module属性赋值给实例变量self.model # 调用策略的setup_optimizer方法对优化器进行设置,并将返回的优化器赋值给实例变量self.optimizer self.optimizer = strategy.setup_optimizer(optim, self.model) self.accimulation_steps = accimulation_steps # 将输入参数accimulation_steps赋值给实例变量self.accimulation_steps num_update_steps_per_epoch = len(train_dataloader) // self.accimulation_steps # 计算每个训练轮次的更新步数 max_steps = math.ceil(self.epochs * num_update_steps_per_epoch) # 计算最大更新步数 # 获取学习率调度器,并赋值给实例变量self.scheduler self.scheduler = get_scheduler("cosine", # 学习率调度策略为"cosine" self.optimizer, # 优化器为实例变量self.optimizer num_warmup_steps=math.ceil(max_steps * 0.03), # 预热步数为最大更新步数的3% num_training_steps=max_steps) # 训练步数为最大更新步数 # 下面是SFTTrainer类的fit方法,用于训练模型 def fit(self, logger, log_interval=10): # 输入参数为logger,即日志记录器,以及log_interval,即日志记录间隔,默认为10 # 初始化Weights & Biases的实验,并设置项目名为"Coati",实验名为当前时间 wandb.init(project="Coati", name=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) wandb.watch(self.model) # 开始监视实例变量self.model total_loss = 0 # 定义变量total_loss并初始化为0,用于记录总损失 # 定义一个进度条,长度为训练轮次数,描述信息为'Epochs',如果当前进程不是主进程则禁用进度条 # epoch_bar = tqdm(range(self.epochs), desc='Epochs', disable=not is_rank_0()) # 定义一个进度条,长度为训练步数,描述信息为'steps',如果当前进程不是主进程则禁用进度条 step_bar = tqdm(range(len(self.train_dataloader) // self.accimulation_steps * self.epochs), desc=f'steps', disable=not is_rank_0()) for epoch in range(self.epochs): # 遍历每一个训练轮次 # 定义一个进度条,长度为训练样本数,描述信息为'Train process for{epoch}',如果当前进程不是主进程则禁用进度条 # process_bar = tqdm(range(len(self.train_dataloader)), desc=f'Train process for{epoch}', disable=not is_rank_0()) # 训练模式 self.model.train() for batch_id, batch in enumerate(self.train_dataloader): # 遍历每一个训练样本 # 将样本中的"input_ids"字段送到当前设备上,并赋值给变量prompt_ids prompt_ids = batch["input_ids"].to(torch.cuda.current_device()) # 将样本中的"attention_mask"字段送到当前设备上,并赋值给变量p_mask p_mask = batch["attention_mask"].to(torch.cuda.current_device()) # 将样本中的"labels"字段送到当前设备上,并赋值给变量labels labels = batch["labels"].to(torch.cuda.current_device()) # prompt_ids = prompt_ids.squeeze(1).cuda() # p_mask = p_mask.squeeze(1).cuda() # prompt_logits = self.model(prompt_ids, attention_mask=p_mask, labels=labels) # 对模型进行前向传播,并将返回的结果赋值给变量outputs outputs = self.model(prompt_ids, attention_mask=p_mask, labels=labels) loss = outputs.loss # 获取outputs中的loss属性,并赋值给变量loss prompt_logits = outputs.logits # 获取outputs中的logits属性,并赋值给变量prompt_logits if loss >= 2.5: # 如果loss大于或等于2.5 logger.warning(f"batch_id:{batch_id}, abnormal loss: {loss}") # 在日志中记录警告信息 loss = loss / self.accimulation_steps # 将loss除以梯度积累步数 total_loss += loss.item() # 将loss加入到total_loss中 loss.backward() # 对loss进行反向传播 if (batch_id + 1) % self.accimulation_steps == 0: # 如果当前批次是梯度积累步数的整数倍 self.optimizer.step() # 对优化器执行一步优化 self.optimizer.zero_grad() # 清空优化器的梯度 self.scheduler.step() # 对学习率调度器执行一步调度 if is_rank_0(): # 如果当前进程是主进程 wandb.log({"train_loss": total_loss / self.accimulation_steps}) # 在Weights & Biases中记录训练损失 total_loss = 0 # 将total_loss重置为0 step_bar.update(1) # 更新步骤进度条 # process_bar.update(1) # 更新训练进度条 if (batch_id + 1) % (self.accimulation_steps * log_interval) == 0: # 如果当前批次是日志记录间隔的整数倍 self.evaluate(epoch, logger, log_interval) # 进行一次评估 if self.eval_dataloader: # 如果存在评估数据加载器 self.evaluate(epoch, logger) # 进行一次评估 if is_rank_0(): # 如果当前进程是主进程 torch.save(self.model.state_dict(), f"coati_checkpoints/epoch_{epoch}.pth") # 保存模型的状态字典 wandb.save(f"coati_checkpoints/epoch_{epoch}.pth") # 在Weights & Biases中保存模型的状态字典 # epoch_bar.update(1) # 更新轮次进度条 wandb.finish() # 结束Weights & Biases的实验 # 下面是SFTTrainer类的evaluate方法,用于评估模型 def evaluate(self, epoch, logger, log_interval=10): # 输入参数为epoch,即轮次,logger,即日志记录器,以及log_interval,即日志记录间隔,默认为10 # 打印一条日志信息,内容为"Start evaluation process..." logger.info("Start evaluation process...") self.model.eval() # 将模型切换到评估模式 total_loss = 0 # 定义变量total_loss并初始化为0,用于记录总损失 # 定义一个进度条,长度为评估样本数,描述信息为'Eval process',如果当前进程不是主进程则禁用进度条 # process_bar = tqdm(range(len(self.eval_dataloader)), desc='Eval process', disable=not is_rank_0()) with torch.no_grad(): # 禁止计算梯度 for batch_id, batch in enumerate(self.eval_dataloader): # 遍历每一个评估样本 # 将样本中的"input_ids"字段送到当前设备上,并赋值给变量prompt_ids prompt_ids = batch["input_ids"].to(torch.cuda.current_device()) # 将样本中的"attention_mask"字段送到当前设备上,并赋值给变量p_mask p_mask = batch["attention_mask"].to(torch.cuda.current_device()) # 将样本中的"labels"字段送到当前设备上,并赋值给变量labels labels = batch["labels"].to(torch.cuda.current_device()) # 对模型进行前向传播,并将返回的结果赋值给变量outputs outputs = self.model(prompt_ids, attention_mask=p_mask, labels=labels) loss = outputs.loss # 获取outputs中的loss属性,并赋值给变量loss if loss >= 2.5: # 如果loss大于或等于2.5 logger.warning(f"batch_id:{batch_id}, abnormal loss: {loss}") # 在日志中记录警告信息 total_loss += loss.item() # 将loss加入到total_loss中 if (batch_id + 1) % log_interval == 0: # 如果当前批次是日志记录间隔的整数倍 if is_rank_0(): # 如果当前进程是主进程 wandb.log({"eval_loss": total_loss / log_interval}) # 在Weights & Biases中记录评估损失 total_loss = 0 # 将total_loss重置为0 # process_bar.update(1) # 更新评估进度条 logger.info(f"Finish evaluation process for epoch {epoch}") # 打印一条日志信息,内容为"Finish evaluation process for epoch {epoch}" 3.2.2 训练一个奖励模型其次,通过ColossalAI/applications/Chat/coati/trainer/rm.py 训练一个奖励模型 from abc import ABC # 导入 abc 模块(抽象基类模块) from datetime import datetime # 导入 datetime 模块,用于处理日期和时间 from typing import Optional # 导入 typing 模块中的 Optional 类型,它表示一个类型可能是 None import pandas as pd # 导入 pandas 库,用于数据分析和操作 import torch # 导入 PyTorch 库,一个用于深度学习的开源库 import torch.distributed as dist # 导入 PyTorch 分布式计算模块 from torch.optim import Optimizer, lr_scheduler # 导入 PyTorch 中的优化器和学习率调度器 # 导入 PyTorch 的数据加载器和数据集模块 from torch.utils.data import DataLoader, Dataset, DistributedSampler from tqdm import tqdm # 导入 tqdm,一个用于打印进度条的库 # 导入 transformers 库的 tokenization_utils_base 模块中的 PreTrainedTokenizerBase 类,它用于处理预训练的 tokenizer from transformers.tokenization_utils_base import PreTrainedTokenizerBase from .strategies import Strategy # 从当前包的 strategies 模块中导入 Strategy 类 from .utils import is_rank_0 # 从当前包的 utils 模块中导入 is_rank_0 函数 # 定义 RewardModelTrainer 类,它继承自 ABC(抽象基类) class RewardModelTrainer(ABC): """ Trainer to use while training reward model. Args: 这个类继承了 ABC 抽象基类。它接受以下参数: model:待训练的模型 strategy:训练策略 optim:优化器 loss_fn:损失函数 train_dataset:训练数据集 valid_dataset:验证数据集 eval_dataset:评估数据集 batch_size:批次大小(默认为1) max_epochs:最大训练轮数(默认为2) """ # 初始化 RewardModelTrainer 类的实例 def __init__( self, model, strategy: Strategy, optim: Optimizer, loss_fn, train_dataset: Dataset, valid_dataset: Dataset, eval_dataset: Dataset, batch_size: int = 1, max_epochs: int = 1, ) -> None: # 调用父类(ABC)的初始化方法 super().__init__() # 将传入的训练策略保存到实例变量中 self.strategy = strategy # 将传入的最大训练轮数保存到实例变量中 self.epochs = max_epochs # 初始化训练采样器为 None train_sampler = None # 如果当前运行环境已经初始化了分布式计算,并且世界尺寸(即参与分布式计算的进程数)大于 1 if dist.is_initialized() and dist.get_world_size() > 1: # 创建一个分布式采样器 train_sampler = DistributedSampler(train_dataset, shuffle=True, seed=42, drop_last=True) # 创建一个用于训练的数据加载器,如果 train_sampler 为 None,则将 shuffle 设为 True self.train_dataloader = DataLoader(train_dataset, shuffle=(train_sampler is None), sampler=train_sampler, batch_size=batch_size) # 创建一个用于验证的数据加载器 self.valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=True) # 创建一个用于评估的数据加载器 self.eval_dataloader = DataLoader(eval_dataset, batch_size=batch_size, shuffle=True) # 调用策略的 setup_model 方法设置模型,并将结果保存到实例变量中 self.model = strategy.setup_model(model) # 将传入的损失函数保存到实例变量中 self.loss_fn = loss_fn # 调用策略的 setup_optimizer 方法设置优化器,并将结果保存到实例变量中 self.optimizer = strategy.setup_optimizer(optim, self.model) # 创建一个余弦退火学习率调度器,并将结果保存到实例变量中 self.scheduler = lr_scheduler.CosineAnnealingLR(self.optimizer, self.train_dataloader.__len__() // 100) # 定义一个方法,用于评估给定数据加载器上的准确率,并计算选定奖励和拒绝奖励之间的平均距离 def eval_acc(self, dataloader): # 初始化距离、计数器和准确率 dist = 0 on = 0 cnt = 0 # 将模型设置为评估模式 self.model.eval() # 禁用梯度计算,以节省计算资源 with torch.no_grad(): # 遍历数据加载器中的每一批数据 for chosen_ids, c_mask, reject_ids, r_mask in dataloader: # 将 chosen_ids,c_mask,reject_ids 和 r_mask 移动到当前设备上,并去掉第一个维度 chosen_ids = chosen_ids.squeeze(1).to(torch.cuda.current_device()) c_mask = c_mask.squeeze(1).to(torch.cuda.current_device()) reject_ids = reject_ids.squeeze(1).to(torch.cuda.current_device()) r_mask = r_mask.squeeze(1).to(torch.cuda.current_device()) # 将 chosen_ids 和 c_mask 传入模型,计算 chosen_reward chosen_reward = self.model(chosen_ids, attention_mask=c_mask) # 将 reject_ids 和 r_mask 传入模型,计算 reject_reward reject_reward = self.model(reject_ids, attention_mask=r_mask) # 遍历 chosen_reward 的每个元素 for i in range(len(chosen_reward)): # 计数器加一 cnt += 1 # 如果 chosen_reward 大于 reject_reward,那么准确率加一 if chosen_reward[i] > reject_reward[i]: on += 1 # 更新距离 dist += (chosen_reward - reject_reward).mean().item() # 计算距离的平均值 dist_mean = dist / len(dataloader) # 计算准确率 acc = on / cnt # 将模型设置为训练模式 self.model.train() # 返回平均距离和准确率 return dist_mean, acc # 定义一个方法,用于训练模型 def fit(self): # 获取当前的日期和时间 time = datetime.now() # 创建一个进度条,表示训练轮数 epoch_bar = tqdm(range(self.epochs), desc='Train epoch', disable=not is_rank_0()) # 遍历每一个训练轮 for epoch in range(self.epochs): # 创建一个进度条,表示当前训练轮的训练步数 step_bar = tqdm(range(self.train_dataloader.__len__()), desc='Train step of epoch %d' % epoch, disable=not is_rank_0()) # 将模型设置为训练模式 self.model.train() # 初始化计数器、准确率和距离 cnt = 0 acc = 0 dist = 0 # 遍历训练数据加载器中的每一批数据 for chosen_ids, c_mask, reject_ids, r_mask in self.train_dataloader: # 将 chosen_ids,c_mask,reject_ids 和 r_mask 移动到当前设备上,并去掉第一个维度 chosen_ids = chosen_ids.squeeze(1).to(torch.cuda.current_device()) c_mask = c_mask.squeeze(1).to(torch.cuda.current_device()) reject_ids = reject_ids.squeeze(1).to(torch.cuda.current_device()) r_mask = r_mask.squeeze(1).to(torch.cuda.current_device()) # 将 chosen_ids 和 c_mask 传入模型,计算 chosen_reward chosen_reward = self.model(chosen_ids, attention_mask=c_mask) # 将 reject_ids 和 r_mask 传入模型,计算 reject_reward reject_reward = self.model(reject_ids, attention_mask=r_mask) # 调用损失函数,计算损失 loss = self.loss_fn(chosen_reward, reject_reward) # 调用策略的 backward 方法,计算梯度 self.strategy.backward(loss, self.model, self.optimizer) # 调用策略的 optimizer_step 方法,更新模型参数 self.strategy.optimizer_step(self.optimizer) # 将优化器的梯度缓存清零 self.optimizer.zero_grad() # 计数器加一 cnt += 1 # 如果计数器达到 100 if cnt == 100: # 调用学习率调度器的 step 方法,更新学习率 self.scheduler.step() # 计算验证数据加载器上的平均距离和准确率 dist, acc = self.eval_acc(self.valid_dataloader) # 重置计数器 cnt = 0 # 如果当前进程是 rank 0 if is_rank_0(): # 创建一个 DataFrame 来存储步数、损失、距离和准确率 log = pd.DataFrame([[step_bar.n, loss.item(), dist, acc]], columns=['Step', 'Loss', 'Distance', 'Accuracy']) # 将 DataFrame 保存到 CSV 文件中 log.to_csv(str(time) + '.csv', mode='a', header=False) # 更新进度条 step_bar.update(100) # 更新进度条 epoch_bar.update(1) # 如果当前进程是 rank 0 if is_rank_0(): # 打印训练结束的消息 print('Training finished!') # 计算评估数据加载器上的平均距离和准确率 dist, acc = self.eval_acc(self.eval_dataloader) # 创建一个 DataFrame 来存储损失、距离和准确率 log = pd.DataFrame([[self.train_dataloader.__len__(), 'N/A', dist, acc]], columns=['Step', 'Loss', 'Distance', 'Accuracy']) # 将 DataFrame 保存到 CSV 文件中 log.to_csv(str(time) + '.csv', mode='a', header=False) 3.2.3 通过trainer/ppo.py to start PPO training最后,通过ColossalAI/applications/Chat/coati/trainer/ppo.py to start PPO training from typing import Any, Callable, Dict, List, Optional # 导入一些类型别名,用于类型注解 import torch # 导入PyTorch库,这是一个机器学习库,广泛用于深度学习模型的建立和训练 import torch.nn as nn # 导入PyTorch的神经网络模块 from coati.experience_maker import Experience, NaiveExperienceMaker # 导入Experience和NaiveExperienceMaker,前者用于保存Agent的经验,后者用于创建Experience对象 from coati.models.base import Actor, Critic # 导入Actor和Critic,他们是PPO算法中的关键组成部分 from coati.models.generation_utils import update_model_kwargs_fn # 导入函数update_model_kwargs_fn,用于更新模型的参数 from coati.models.loss import PolicyLoss, ValueLoss # 导入PolicyLoss和ValueLoss,分别计算策略损失和价值损失 from coati.replay_buffer import NaiveReplayBuffer # 导入NaiveReplayBuffer,用于保存和回放经验 from torch.optim import Optimizer # 导入Optimizer,这是优化算法的基类 from transformers.tokenization_utils_base import PreTrainedTokenizerBase # 导入预训练的tokenizer基类,用于处理文本数据 from .base import Trainer # 导入Trainer类,这是训练循环的基类 from .callbacks import Callback # 导入Callback类,用于在训练过程中的某些阶段执行特定的函数 from .strategies import Strategy # 导入Strategy类,它定义了模型参数更新的策略 # PPOTrainer类的定义,继承自Trainer class PPOTrainer(Trainer): # 类的初始化函数,接受许多参数 def __init__(self, strategy: Strategy, # 用于更新模型参数的策略 actor: Actor, # 用于选择动作的模型 critic: Critic, # 用于评估动作的模型 reward_model: nn.Module, # 用于计算奖励的模型 initial_model: Actor, # 用于生成初始策略的模型 actor_optim: Optimizer, # 用于优化actor的优化器 critic_optim: Optimizer, # 用于优化critic的优化器 kl_coef: float = 0.1, # kl散度系数 ptx_coef: float = 0.9, # ptx系数 train_batch_size: int = 8, # 训练批大小 buffer_limit: int = 0, # 缓冲区大小限制 buffer_cpu_offload: bool = True, # 是否在cpu上处理缓冲区 eps_clip: float = 0.2, # epsilon剪裁值 value_clip: float = 0.4, # 价值剪裁值 experience_batch_size: int = 8, # 经验批大小 max_epochs: int = 1, # 最大训练周期数 tokenizer: Optional[Callable[[Any], dict]] = None, # 用于文本处理的tokenizer sample_replay_buffer: bool = False, # 是否从回放缓冲区中抽样 dataloader_pin_memory: bool = True, # 数据加载器是否针对内存 callbacks: List[Callback] = [], # 在训练过程中的某些阶段执行的函数列表 **generate_kwargs) -> None: # 其他生成参数 # 创造经验生成器 experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model, kl_coef) # 创造经验回放缓冲区 replay_buffer = NaiveReplayBuffer(train_batch_size, buffer_limit, buffer_cpu_offload) # 根据策略和actor设置默认的生成参数 generate_kwargs = _set_default_generate_kwargs(strategy, generate_kwargs, actor) # 调用父类的初始化函数 super().__init__(strategy, experience_maker, replay_buffer, experience_batch_size, max_epochs, tokenizer, sample_replay_buffer, dataloader_pin_memory, callbacks, **generate_kwargs) # 初始化actor和critic self.actor = actor self.critic = critic # 初始化损失函数 self.actor_loss_fn = PolicyLoss(eps_clip) self.critic_loss_fn = ValueLoss(value_clip) self.ptx_loss_fn = nn.CrossEntropyLoss(ignore_index=-100) self.ptx_coef = ptx_coef # 初始化优化器 self.actor_optim = actor_optim self.critic_optim = critic_optim # 训练步骤函数,根据经验对象计算actor和critic的损失,并使用策略进行反向传播和优化器更新 def training_step(self, experience: Experience) -> Dict[str, float]: self.actor.train() # 将actor设置为训练模式 self.critic.train() # 将critic设置为训练模式 # 计算策略损失 num_actions = experience.action_mask.size(1) action_log_probs = self.actor(experience.sequences, num_actions, attention_mask=experience.attention_mask) actor_loss = self.actor_loss_fn(action_log_probs, experience.action_log_probs, experience.advantages, action_mask=experience.action_mask) # 计算ptx损失 if self.ptx_coef != 0: ptx = next(iter(self.pretrain_dataloader))['input_ids'].to(torch.cuda.current_device()) label = next(iter(self.pretrain_dataloader))['labels'].to(torch.cuda.current_device())[:, 1:] attention_mask = next(iter(self.pretrain_dataloader))['attention_mask'].to(torch.cuda.current_device()) ptx_log_probs = self.actor.get_base_model()(ptx, attention_mask=attention_mask)['logits'][..., :-1, :] ptx_loss = self.ptx_loss_fn(ptx_log_probs.view(-1, ptx_log_probs.size(-1)), label.view(-1)) actor_loss = ptx_loss * self.ptx_coef + actor_loss * (1 - self.ptx_coef) self.strategy.backward(actor_loss, self.actor, self.actor_optim) # 使用策略进行反向传播 self.strategy.optimizer_step(self.actor_optim) # 使用策略进行优化器步进 self.actor_optim.zero_grad() # 清零优化器的梯度 # 计算价值损失 values = self.critic(experience.sequences, action_mask=experience.action_mask, attention_mask=experience.attention_mask) critic_loss = self.critic_loss_fn(values, experience.values, experience.reward, action_mask=experience.action_mask) self.strategy.backward(critic_loss, self.critic, self.critic_optim) # 使用策略进行反向传播 self.strategy.optimizer_step(self.critic_optim) # 使用策略进行优化器步进 self.critic_optim.zero_grad() # 清零优化器的梯度 return {'reward': experience.reward.mean().item()} # 返回平均奖励 # 根据策略和actor设置默认的生成参数 def _set_default_generate_kwargs(strategy: Strategy, generate_kwargs: dict, actor: Actor) -> None: origin_model = strategy._unwrap_actor(actor) new_kwargs = {**generate_kwargs} # 使用huggingface模型的方法直接生成输入 if 'prepare_inputs_fn' not in generate_kwargs and hasattr(origin_model, 'prepare_inputs_for_generation'): new_kwargs['prepare_inputs_fn'] = origin_model.prepare_inputs_for_generation if 'update_model_kwargs_fn' not in generate_kwargs: new_kwargs['update_model_kwargs_fn'] = update_model_kwargs_fn return new_kwargs # 保存模型的函数 def save_model(self, path: str, only_rank0: bool = False, tokenizer: Optional[PreTrainedTokenizerBase] = None) -> None: self.strategy.save_model(model=self.actor, path=path, only_rank0=only_rank0, tokenizer=tokenizer) # 使用策略保存模型在获得最终模型权重后,还可通过量化降低推理硬件成本,并启动在线推理服务,仅需单张约 4GB 显存的 GPU 即可完成 70 亿参数模型推理服务部署 更多请参见另一篇文章:从零实现带RLHF的类ChatGPT:逐行解析微软DeepSpeed Chat |




 接下来,我们看下一些关键实现
接下来,我们看下一些关键实现【本文地址】