| 翻译模型(一)(TransE、TransH、TransR) | 您所在的位置:网站首页 › transf翻译 › 翻译模型(一)(TransE、TransH、TransR) |
翻译模型(一)(TransE、TransH、TransR)
|
目录TransE论文代码TransH论文主体方法负采样方法实验代码TransR论文空间投影实验代码
只要开始,任何时候都不算晚。最近打算把 KGE 的模型从头到尾梳理一遍。即使很多人都建议直接看顶会最新文章,但我还是没办法没有能力那么做。万丈高楼平地起,我仍然坚持认为打好基础是最重要的。决心进入这个领域,不把它的前因后果、历史脉络搞清楚,就没办法构建自己的知识体系,有了知识体系,去看任意一篇新的论文,都可以对应到知识体系中的位置,轻而易举地融汇贯通,否则看论文就是狗熊掰棒子。克强总理说要青年学生要加强基础知识的学习,深以为然。 这篇整理 TransE、TransH 和 TransR,后续持续更新,希望博客园尽快完成整改,让我好发博文。 TransEpaper: Translating Embeddings for Modeling Multi-relational Data 论文大家都非常熟悉的 TransE 是知识图谱表示学习的开山之作。由 Antoine Bordes 发表于 2013 年的 NIPS(现 NeurIPS)上。TransE 中的 E 代表 embedding。论文的主体思想是:将关系视为低维向量空间中的头实体到尾实体的翻译操作,即 \(h+r \approx t\)。因为比较简单,直接贴公式了。 三元组打分函数: 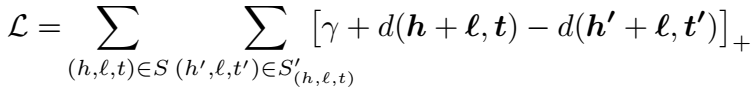

其中,\(d(\cdot)\) 函数定义为: 
由于归一化的约束,上式可以简化为: 
文章中也说了,与 NTN 殊途同归。 训练算法如下,使用 SGD 优化: 
实验的话,只进行了 Link Prediction 和尾实体预测的 case study,没有三元组分类。 
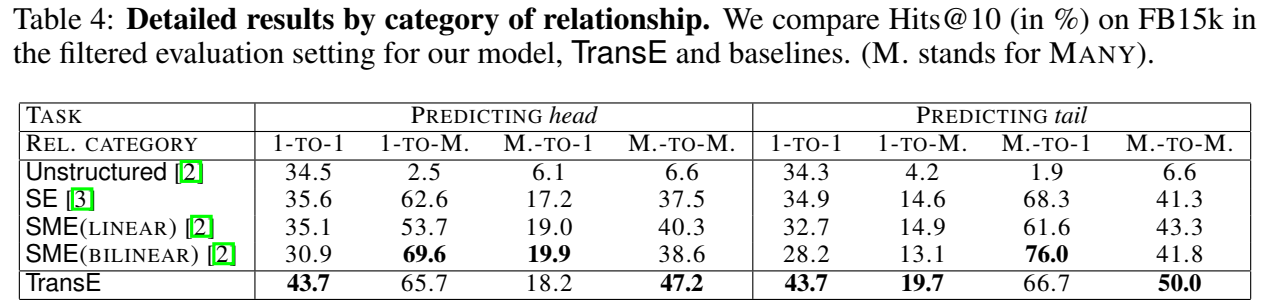
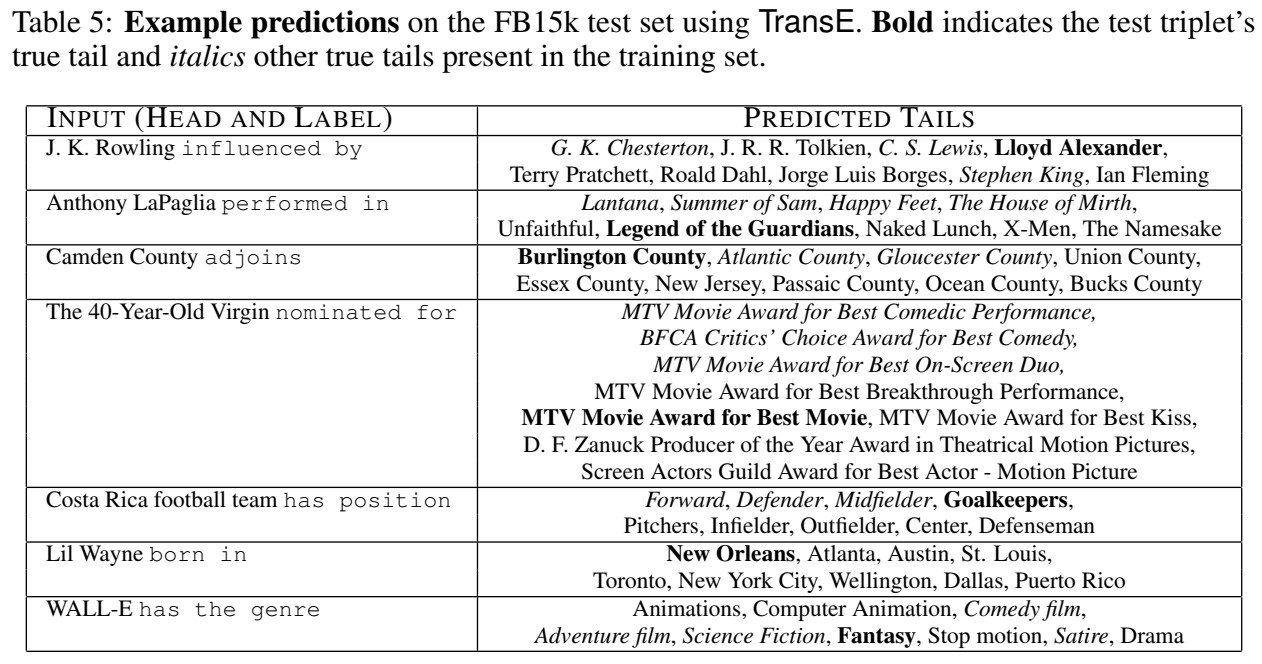 代码
代码
\(Pykg2vec\) 用 PyTorch 实现了很多 KGE 模型,学习一下它的源码。统共就三个函数,还是比较简单的。 class TransE(PairwiseModel): def __init__(self, **kwargs): super(TransE, self).__init__(self.__class__.__name__.lower()) param_list = ["tot_entity", "tot_relation", "hidden_size", "l1_flag"] param_dict = self.load_params(param_list, kwargs) self.__dict__.update(param_dict) self.ent_embeddings = NamedEmbedding("ent_embedding", self.tot_entity, self.hidden_size) self.rel_embeddings = NamedEmbedding("rel_embedding", self.tot_relation, self.hidden_size) nn.init.xavier_uniform_(self.ent_embeddings.weight) nn.init.xavier_uniform_(self.rel_embeddings.weight) self.parameter_list = [ self.ent_embeddings, self.rel_embeddings, ] self.loss = Criterion.pairwise_hinge def forward(self, h, r, t): """Function to get the embedding value. Args: h (Tensor): Head entities ids. r (Tensor): Relation ids. t (Tensor): Tail entity ids. Returns: Tensors: the scores of evaluationReturns head, relation and tail embedding Tensors. """ h_e, r_e, t_e = self.embed(h, r, t) norm_h_e = F.normalize(h_e, p=2, dim=-1) norm_r_e = F.normalize(r_e, p=2, dim=-1) norm_t_e = F.normalize(t_e, p=2, dim=-1) if self.l1_flag: return torch.norm(norm_h_e + norm_r_e - norm_t_e, p=1, dim=-1) return torch.norm(norm_h_e + norm_r_e - norm_t_e, p=2, dim=-1) def embed(self, h, r, t): """Function to get the embedding value. Args: h (Tensor): Head entities ids. r (Tensor): Relation ids. t (Tensor): Tail entity ids. Returns: Tensors: Returns a tuple of head, relation and tail embedding Tensors. """ h_e = self.ent_embeddings(h) r_e = self.rel_embeddings(r) t_e = self.ent_embeddings(t) return h_e, r_e, t_eTransE 虽然简单,但是很有效,计算复杂度低,参数少,Mean Rank 能降到一二百已经很不错了,所以感觉后面的模型似乎都是在蹭它的热度,本身的效果提升感觉并不是很大,我自己在训练模型时也总感觉 TransE 很难超越,这就是经典吧。 TransHpaper: Knowledge Graph Embedding by Translating on Hyperplanes 论文文章由中山大学与微软的研究者发表在 AAAI 2014 上。文章的主要卖点是解决 TransE 不能很好地处理 1-n、n-1 及 n-n 这样的复杂关系的问题,因此在整体数据集上 Link Prediction 的提升并不大,而在 relation category 的预测准确率有清一色的提升。TransH 中的 H 代表 Hyperplane(超平面)。 主体方法方法的本质是: \(h\) 和 \(r\) 还是用一个向量表示,而 \(r\) 用两个向量表示。文章最先提出 \(unif\) 和 \(bern\) 的负采样方法。 
TransH 将 \(h\) 和 \(t\) 投影到 \(r\) 所在的超平面上,投影操作通过下式计算: 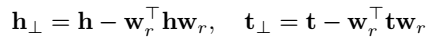
然后用投影后的头尾实体计算三元组得分: 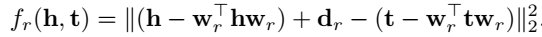
\(d_r\) 为关系 \(r\) 的 translation vector,即其本身的 embedding, \(w_r\) 为 normal vector,用于确定 hyperplane,即用于头尾实体的投影。 TransH 对实体和关系的向量加了很多的约束,因此 Loss 略显臃肿,有的实现中说正交约束作用并不大,可以不加。训练同样使用 SGD。  负采样方法
负采样方法
文章另一个创新点是提出了新的采样方法 \(bern\)。原始的负采样方法是从实体集中随机抽取一个实体替换到 golden triplet 中生成负样本,但是这样做有可能会得到假阳(false negative)的负样本。对于这种情况,文章的解决策略是:对于 1-N 的关系,赋予更高的概率替换头实体,而对于 N-1 的关系,赋予更高的概率替换尾实体。具体地,对每个关系计算其 \(tph\) (每个头实体平均对应几个尾实体)和 \(hpt\) (每个尾实体平均对应几个头实体)。对于 \(\frac{tph}{tph+hpt}\) 越大的,说明是一对多的关系,在负采样时替换头实体,更容易获得 true negative。我曾经思考过这个问题,如果在普通的 \(unif\) 采样时,加一个检验,看下生成的负样本是否存在于 KG 中,这样是不是就可以避免生成 false negative?但是这样的策略默认遵从了一个假设,即 KG 之外的知识全都是错误的(即封闭世界假定 Closed World Assumption),即使生成的负样本不存在于训练集中,也不代表它就是 negative 的,而一般 KG 训练的时候遵循的是开放世界假定(Open World Assumption, OWA),对于未知的命题不知道正确与否,所以 \(bern\) 通过局部推测整体,一对多关系在整个知识体系中也更可能是一对多关系,增大替换头实体的概率确实更易得到 negateive,因此 \(bern\) 策略是有意义的。 实验训练同样采用 SGD,进行了链接预测、三元组分类和关系抽取三项实验。  代码
代码
还是 \(Pykg2vec\) 实现的代码: class TransH(PairwiseModel): def __init__(self, **kwargs): super(TransH, self).__init__(self.__class__.__name__.lower()) param_list = ["tot_entity", "tot_relation", "hidden_size", "l1_flag"] param_dict = self.load_params(param_list, kwargs) self.__dict__.update(param_dict) self.ent_embeddings = NamedEmbedding("ent_embedding", self.tot_entity, self.hidden_size) self.rel_embeddings = NamedEmbedding("rel_embedding", self.tot_relation, self.hidden_size) self.w = NamedEmbedding("w", self.tot_relation, self.hidden_size) nn.init.xavier_uniform_(self.ent_embeddings.weight) nn.init.xavier_uniform_(self.rel_embeddings.weight) nn.init.xavier_uniform_(self.w.weight) self.parameter_list = [ self.ent_embeddings, self.rel_embeddings, self.w, ] self.loss = Criterion.pairwise_hinge def forward(self, h, r, t): h_e, r_e, t_e = self.embed(h, r, t) norm_h_e = F.normalize(h_e, p=2, dim=-1) norm_r_e = F.normalize(r_e, p=2, dim=-1) norm_t_e = F.normalize(t_e, p=2, dim=-1) if self.l1_flag: return torch.norm(norm_h_e + norm_r_e - norm_t_e, p=1, dim=-1) return torch.norm(norm_h_e + norm_r_e - norm_t_e, p=2, dim=-1) def embed(self, h, r, t): """Function to get the embedding value. Args: h (Tensor): Head entities ids. r (Tensor): Relation ids of the triple. t (Tensor): Tail entity ids of the triple. Returns: Tensors: Returns head, relation and tail embedding Tensors. """ emb_h = self.ent_embeddings(h) emb_r = self.rel_embeddings(r) emb_t = self.ent_embeddings(t) proj_vec = self.w(r) emb_h = self._projection(emb_h, proj_vec) emb_t = self._projection(emb_t, proj_vec) return emb_h, emb_r, emb_t @staticmethod def _projection(emb_e, proj_vec): """Calculates the projection of entities""" proj_vec = F.normalize(proj_vec, p=2, dim=-1) # [b, k], [b, k] return emb_e - torch.sum(emb_e * proj_vec, dim=-1, keepdims=True) * proj_vecTransH 解决了 TransE 难以表示自反/一对多/多对一/多对多的复杂关系类型的问题,还是非常有效的。 TransRpaper: Learning Entity and Relation Embeddings for Knowledge Graph Completion 论文 空间投影TransR 是清华大学刘知远、孙茂松老师团队提出来的,发表在 2015 年的 AAAI 上。创新点是将 TransH 的投影到超平面更进一步——投影到空间,本质是将投影向量换为投影矩阵,实体还是用一个向量表示,关系用一个向量和一个矩阵表示。效果提升并不大,但计算量显著增大。TransR 的 R 代表 relation space。 
每个关系有自己一个独立的空间,如果要计算三元组 \((h,r,t)\) 的得分,首先要将 \(h\) 和 \(t\) 投影到 \(r\) 所在的空间中来。 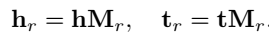

将投影操作的头尾实体带入到打分函数中,会发现似曾相识,没错,SE 模型的打分函数就跟它很像,不过 SE 长这样: Loss 都是一样的,训练也是采用 SGD。
文章还提出了 CTransR (Cluster-based TransR),对每个关系下的头尾实体进行聚类,并为每一个类别分配一个向量来表示,以挖掘细粒度的关系语义。 实验和 TransH 一样,TransR 也进行了链接预测、三元组分类和关系抽取三项实验。 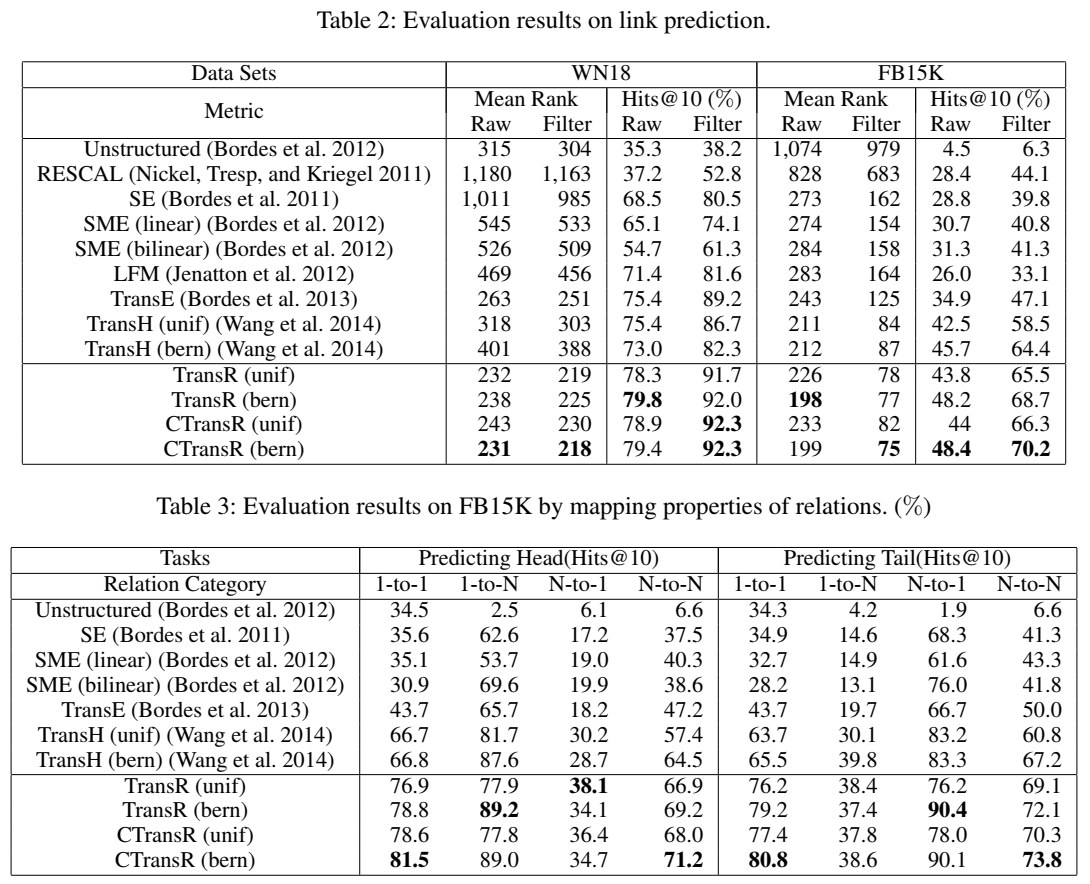
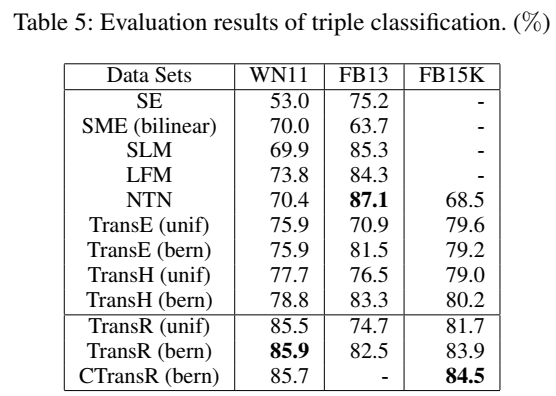
可以看到,无论是整体的链接预测,还是不同类型关系下的链接预测,TransR 及其变体都达到了最优,但这是以巨大的计算量复杂度换来的。根据原文的说法,TransR 的训练时间约是 TransE 的 36 倍、是 TransH 的 6 倍。我自己在训练 TransR 的过程中也明显感觉到比其他模型更为耗时。 代码直接上 \(Pykg2vec\) 的代码: class TransR(PairwiseModel): def __init__(self, **kwargs): super(TransR, self).__init__(self.__class__.__name__.lower()) param_list = ["tot_entity", "tot_relation", "rel_hidden_size", "ent_hidden_size", "l1_flag"] param_dict = self.load_params(param_list, kwargs) self.__dict__.update(param_dict) self.ent_embeddings = NamedEmbedding("ent_embedding", self.tot_entity, self.ent_hidden_size) self.rel_embeddings = NamedEmbedding("rel_embedding", self.tot_relation, self.rel_hidden_size) self.rel_matrix = NamedEmbedding("rel_matrix", self.tot_relation, self.ent_hidden_size * self.rel_hidden_size) nn.init.xavier_uniform_(self.ent_embeddings.weight) nn.init.xavier_uniform_(self.rel_embeddings.weight) nn.init.xavier_uniform_(self.rel_matrix.weight) self.parameter_list = [ self.ent_embeddings, self.rel_embeddings, self.rel_matrix, ] self.loss = Criterion.pairwise_hinge def transform(self, e, matrix): matrix = matrix.view(-1, self.ent_hidden_size, self.rel_hidden_size) if e.shape[0] != matrix.shape[0]: e = e.view(-1, matrix.shape[0], self.ent_hidden_size).permute(1, 0, 2) e = torch.matmul(e, matrix).permute(1, 0, 2) else: e = e.view(-1, 1, self.ent_hidden_size) e = torch.matmul(e, matrix) return e.view(-1, self.rel_hidden_size) def embed(self, h, r, t): """Function to get the embedding value. Args: h (Tensor): Head entities ids. r (Tensor): Relation ids of the triple. t (Tensor): Tail entity ids of the triple. Returns: Tensors: Returns head, relation and tail embedding Tensors. """ h_e = self.ent_embeddings(h) r_e = self.rel_embeddings(r) t_e = self.ent_embeddings(t) h_e = F.normalize(h_e, p=2, dim=-1) r_e = F.normalize(r_e, p=2, dim=-1) t_e = F.normalize(t_e, p=2, dim=-1) h_e = torch.unsqueeze(h_e, 1) t_e = torch.unsqueeze(t_e, 1) # [b, 1, k] matrix = self.rel_matrix(r) # [b, k, d] transform_h_e = self.transform(h_e, matrix) transform_t_e = self.transform(t_e, matrix) # [b, 1, d] = [b, 1, k] * [b, k, d] h_e = torch.squeeze(transform_h_e, axis=1) t_e = torch.squeeze(transform_t_e, axis=1) # [b, d] return h_e, r_e, t_e def forward(self, h, r, t): """Function to get the embedding value. Args: h (Tensor): Head entities ids. r (Tensor): Relation ids. t (Tensor): Tail entity ids. Returns: Tensors: the scores of evaluationReturns head, relation and tail embedding Tensors. """ h_e, r_e, t_e = self.embed(h, r, t) norm_h_e = F.normalize(h_e, p=2, dim=-1) norm_r_e = F.normalize(r_e, p=2, dim=-1) norm_t_e = F.normalize(t_e, p=2, dim=-1) if self.l1_flag: return torch.norm(norm_h_e + norm_r_e - norm_t_e, p=1, dim=-1) return torch.norm(norm_h_e + norm_r_e - norm_t_e, p=2, dim=-1)个人感觉就这些模型本身并没有什么高明的地方,无非是改了一下打分函数的样式(KGE 最核心的部分就是打分函数),只是因为给这些打分函数赋予了一些物理意义去解释(投影操作之类),使得其看起来 plausible,这些解释撑起了一篇又一篇的论文。让我想起那句话:知识本身并不难,其本身是一个个定理并不难,只是因为被包装了,所以才看起来难。 下篇更新 TransD、TransA、TranSparse,敬请期待!_ |

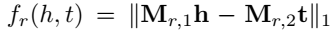 ,它的每个关系 \(r\) 对应两个矩阵 \(M_{r,1}\) 和 \(M_{r,2}\),没有对于 \(r\) 自身的 embedding 向量,而 TransR 有一个关系本身的嵌入 \(r\) 以及一个用于空间投影的矩阵 \(M_r\)。
,它的每个关系 \(r\) 对应两个矩阵 \(M_{r,1}\) 和 \(M_{r,2}\),没有对于 \(r\) 自身的 embedding 向量,而 TransR 有一个关系本身的嵌入 \(r\) 以及一个用于空间投影的矩阵 \(M_r\)。
【本文地址】