| 最强人声与伴奏分离 Ultimate Vocal Remover 5.5.1简体中文汉化版使用教程 | 您所在的位置:网站首页 › teachingfelling24汉化 › 最强人声与伴奏分离 Ultimate Vocal Remover 5.5.1简体中文汉化版使用教程 |
最强人声与伴奏分离 Ultimate Vocal Remover 5.5.1简体中文汉化版使用教程
|
该程序采用了最先进的音源分离模型,以去除音频文件中的人声,同时核心开发人员还训练了该软件包中提供的所有模型(除了Demucs的辅助模型)。在使用UVR5时,您可以轻松地将歌曲转化为无人声伴奏版本,这对于歌曲制作和KTV歌曲演唱有着非常重要的作用。 此外,UVR5还支持处理高品质的音频文件,因此无论您是音乐爱好者还是专业人士,都可以在UVR5中找到适合自己需求的功能。总的来说,UVR5是一款强大、易于使用且高效的伴奏制作/人声提取工具,它在音频编辑领域的表现非常出色。 先决条件 建议使用至少有 8GB 显存的英伟达GPU 该应用程序只兼容 64 位平台 该应用程序依赖于Sox – Sound Exchange的降噪。 该应用程序依赖于FFmpeg来处理非wav格式的音频文件。 转换时间取决于你的硬件配置 该安装程序适用于 Windows 10 或更高版本 NVIDIA显卡的CUDA驱动安装最新版本 软件下载点击下载按钮,进入不限速网盘下载。
Ultimate Vocal Remover 下载 类型: exe 大小: 1.56GB 安装教程在安装之前请确定自己当前所使用的CUDA驱动为最新版本,关于CUDA的安装下载,可以参考如下文章: CUDA在安装之前请确定您已安装FFmpeg格式转换工具,关于FFmpeg的安装下载,可以参考如下文章: FFmpeg|媒体格式转换工具 安装过程
接受安装协议,然后点击Next按钮。
建议使用默认目录,然后点击Next按钮。
勾选创建桌面图标,然后点击Next按钮。
确认安装信息无误,然后点击Next按钮。
取消启动UVR,然后点击Finish按钮。 至此,Ultimate Vocal Remover的软件安装部分已经结束。 模型下载该模型可以让音频分离的效果更好,所以本站建议您一定要下载。 Ultimate Vocal Remover模型 下载 类型: RAR 大小: 559.83MB 模型安装将模型下载至本地,解压RAR文件之后将会得到两个文件夹,分别为Demucs_Models和VR_Models,将Demucs_Models和VR_Models文件夹移动至UVR5的安装目录。 完整目录为:C:\Users\用户名\AppData\Local\Programs\Ultimate Vocal Remover\models 如果您找不到这个文件夹,您可以复制如下内容,然后按键盘上的微软徽标键别松手+R键,此时将会弹出一个名为运行的窗口,然后粘贴下面的内容,按下回车将会自动打开模型路径,将两个模型文件夹移动至此目录内即可。 注意:移动模型时,如遇是否覆盖,点击确定覆盖。 %LocalAppData%\Programs\Ultimate Vocal Remover\models 使用教程 常用功能翻译
一般选项 VR 架构选项 MDX-Net 选项 Demucs v3 选项 合奏选项 手动合奏 干声提取什么是干声?从歌曲或音频中提取不包含背景音、伴奏、合声的纯人声数据,我们称之为干声。 【相思 – 仇志】原曲我们先准备一首歌曲做为案例来使用,音乐为仇志所演唱的相思,我们先将UVR的界面设置如下,然后点击Start Processing按钮。 经过短暂的等待之后,我们就可以在输出目录看到新增的文件啦,分别是伴奏1_相思 – 仇志_(Instrumental)和人声1_相思 – 仇志_(Vocals)两个音频文件,下面 相思 – 仇志 – 人声(人声从第17秒开始演唱,因为在17秒之前是伴奏,所以没有任何声音。) 相思 – 仇志 – 伴奏至此,我们已经将一首歌曲的人声和伴奏都提取完成啦。 合声剥离什么是合声?在中西方音乐中的定义有些许不同,但合声通常指的是多个人声部在一起演唱,包括合唱、重唱等形式。而和声则是指音乐中多个声部的和谐组合,包括和弦、旋律和伴奏等。 这次我们选择刚刚已经分离出来的人声文件1_相思 – 仇志_(Vocals),UVR的设置如下,然后点击Start Processing按钮。
经过短暂的等待,我们就可以得到已经去除合声的音频啦,因为采用的是最先进的AI人工智能技术,所以分离出来的音频和伴奏非常非常的干净,几乎和原版一模一样。
这个软件功能强大、模式众多,对于小白肯定无所适从,经笔者从7月以来几个月的测试使用经验,从效果质量以及同时考虑电脑性能运行消耗时间综合取舍,提出直接使用的设置方案,避免少走弯路,徒费时间和精力。
提取伴奏按上图设置 说明:经测试VR模型库中7_HP2为相对比较纯的伴奏,音质稍微好一点,但处理速度比第一代HP1慢很多,为此还是使用官方默认的2_HP,再混合MDX-Net 中最强的UVR-MDX-Net Main模式,再加上选项上勾选demucs模型加持,出来的是妥妥的优质伴奏。(此外,可自定义更多模式混合,多达5个,但这要花钱更多处理时间,综合取舍,此方案就采用够用的VR 2_HP+UVR-MDX-Net Main+demucs的三种模型组合) 如果你的电脑不济,出现内存分配等错误通常可以通过降低“Chunk Size” (分块大小)来解决,可将full改为使用Auto或比如5、10等值。 【提取的伴奏常见用途多作为直播伴奏、短视频贴唱混音等】 三、提取最优人声
按图中设置得到一个比较好的人声 说明:post-process 处理消除在人声输出后识别残留的乐器声,提取人声的话勾选。aggression setting 设置去除声音的力度。默认10,如果觉得人声损失多就选1-10范围。人声模型3_HP_3和4中,4_HP保留和人声混在一起乐器一些频率,3_HP消的更干净。windown size:320音质最好gpu conversion:gpu运算处理save vocals only:只保存人声TTA:测试时间增强提高分离质量
【提取的人声用途为贴唱混音修音时作为音高节奏参考等,当然还可直接拿该歌声通过升降调作为你的和声部,还可以用其音高节奏配上ACE studio、Synthesizer V studio以及国产的x studio虚拟歌手软件制作和声】 |
 AI人声伴奏音频分离软件Ultimate Vocal RemoverUVR5(Ultimate Vocal Remover)是一款功能强大的伴奏制作/人声提取工具,其表现不仅优于RX9、RipX和SpectraLayers 9等同类工具,而且它提取出来的伴奏已经无限接近原版立体声。
AI人声伴奏音频分离软件Ultimate Vocal RemoverUVR5(Ultimate Vocal Remover)是一款功能强大的伴奏制作/人声提取工具,其表现不仅优于RX9、RipX和SpectraLayers 9等同类工具,而且它提取出来的伴奏已经无限接近原版立体声。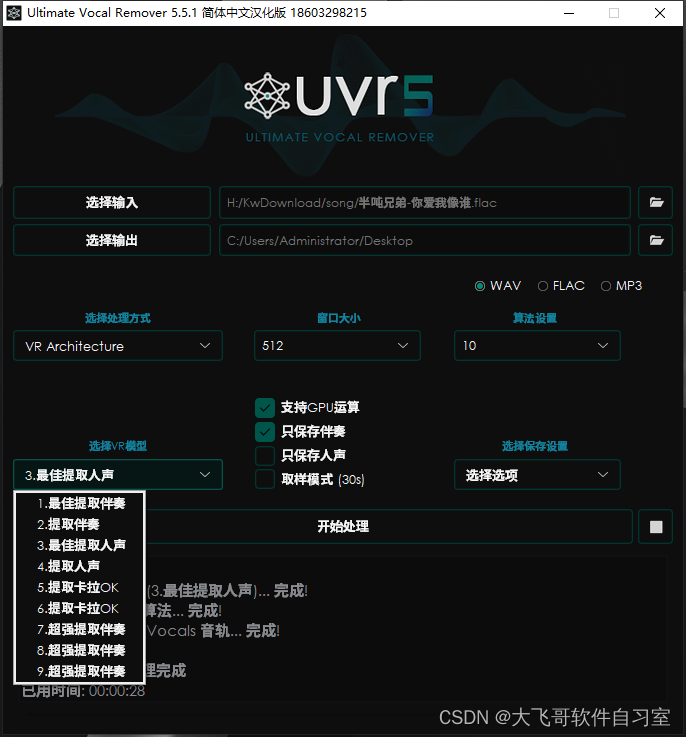
















【本文地址】