| mysql 添加索引,ALTER TABLE和CREATE INDEX的区别 | 您所在的位置:网站首页 › table和desk有啥区别 › mysql 添加索引,ALTER TABLE和CREATE INDEX的区别 |
mysql 添加索引,ALTER TABLE和CREATE INDEX的区别
|
(1)使用ALTER TABLE语句创建索引,其中包括普通索引、UNIQUE索引和PRIMARY KEY索引3种创建索引的格式: PRIMARY KEY 主键索引:mysql>ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` ) NIQUE唯一索引:mysql>ALTER TABLE `table_name` ADD UNIQUE ( `column` ) INDEX普通索引 :mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column` ) FULLTEXT全文索引 :mysql>ALTER TABLE `table_name` ADD FULLTEXT ( `column`) INDEX多列索引:mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` ) 索引名index_name可选,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以同时创建多个索引。
(2)使用CREATE INDEX语句对表增加索引。能够增加普通索引和UNIQUE索引两种。其格式如下:create index index_name on table_name (column_list) ;create unique index index_name on table_name (column_list) ; #表中有primary Key后不能用uniq index。说明:table_name、index_name和column_list具有与ALTER TABLE语句中相同的含义,索引名不可选。另外,不能用CREATE INDEX语句创建PRIMARY KEY索引。 (3)删除索引。删除索引可以使用ALTER TABLE或DROP INDEX语句来实现。2881064151DROP INDEX可以在ALTER TABLE内部作为一条语句处理,其格式如下:drop index index_name on table_name ;alter table table_name drop index index_name ;alter table table_name drop primary key ;其中,在前面的两条语句中,都删除了table_name中的索引index_name。而在最后一条语句中,只在删除PRIMARY KEY索引中使用,因为一个表只可能有一个PRIMARY KEY索引,因此不需要指定索引名。如果没有创建PRIMARY KEY索引,但表具有一个或多个UNIQUE索引,则MySQL将删除第一个UNIQUE索引。如果从表中删除某列,则索引会受影响。对于多列组合的索引,如果删除其中的某列,则该列也会从索引中删除。如果删除组成索引的所有列,则整个索引将被删除。删除索引的操作,如下面的代码:mysql> drop index shili on tpsc ;Query OK, 2 rows affected (0.08 sec)Records: 2 Duplicates: 0 Warnings: 0该语句删除了前面创建的名称为“shili”的索引。
索引不一定是唯一所以,是可以加快查询速度的。 立索引原则:“如何查就如何建”。 索引的建立,唯一的原目的就是为了加快查询(广义的查询),实际上建立索引会使得数据存储所占空间变大,有时索引所占的空间会查过数据本身的空间。索引的建立也会使得数据插入时变慢,特殊情况下,慢的难以忍受,所以DBA的重要工作之一,就是检查索引层级并优化。 索引的目的就是希望尽可能的被索引的字段不重复,那么查找的效率就是1,如果完全重复,效率就是N,如果部分重复,那么效率会小于N,视重复量而定。mysql的索引算法是Btree。
为什么重复值高的字段不能建索引(比如性别字段等)
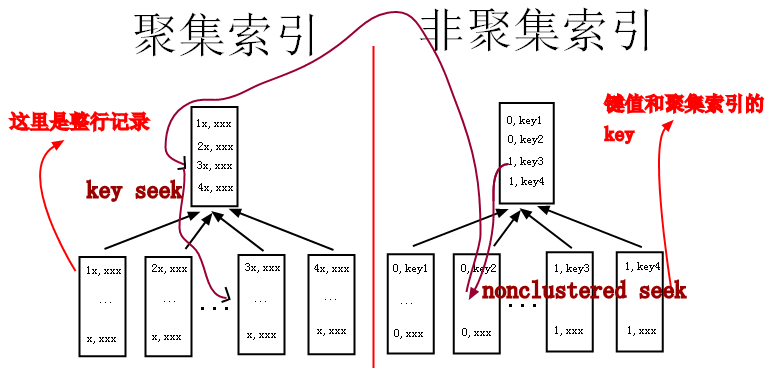
结论(以innodb为例) a、非聚簇索引存储了对主键的引用,如果select字段不在非聚簇索引内,就需要跳到主键索引(上图中从右边的索引树跳到左边的索引树),再获取select字段值 b、如果非聚簇索引值重复率高,那么查询时就会大量出现上图中从右边跳到左边的情况,导致整个流程很慢 c、如果where值重复率高的字段,select用了limit,只查较少数据,也就是跳的次数很少的情况下,还是可以建索引的(后来想想也没必要,limit限制了数量,全表扫描也很快,除非字段值是排序的,必须扫描完前面的所有值) d、如果没有3这个前提,则不建议在值重复率高的字段上建索引,因为查询效率低,还需要维护索引
SQL有三个类型的索引,唯一索引 不能有重复,但聚集索引,非聚集索引可以有重复 重要: (1) SQL如果创建时候,不指定类型那么默认是非聚集索引 (2) 聚集索引和非聚集索引都可以有重复记录,唯一索引不能有重复记录。 (3) 主键 默认是加了唯一约束的聚集索引,但是也可以在主键创建时,指定为唯一约束的非聚集索引,因此主键仅仅是默认加了唯一约束的聚集索引,不能说主键就是加了唯一约束的聚集索引 有点拗口,可以参考我的博客:主键就是聚集索引吗? 为列创建索引实际上就是为列进行排序,以方便查询.建立一个列的索引,就相当与建立一个列的排序。 主键是唯一的,所以创建了一个主键的同时,也就这个字段创建了一个唯一的索引, 唯一索引实际上就是要求指定的列中所有的数据必须不同。 主键一唯一索引的区别: 1 一个表的主键只能有一个,而唯一索引可以建多个。 2 主键可以作为其它表的外键。 3 主键不可为null,唯一索引可以为null。 聚集索引:将表内的数据按照一定的规则进行排列的目录。正因为如此,一个表中的聚焦索引只有一个。对此我们要注意“主键就是聚焦索引”这是极端错误的,是对聚焦索引的一种浪费。(虽然SQLServer默认主键就是聚焦索引)使用聚焦索引的最大好处就是按照查询要求,迅速缩小查询范围,避免进行全表扫描。其次让每个数目都不相同的字段作为聚焦索引也不符合“大数目不同情况下不应建立聚集索引的原则”。 一、索引的作用 1、帮助检索数据; 2、提高联接效率; 3、节省ORDER BY、GROUP BY的时间; 4、保证数据唯一性(仅限于唯一索引)。
二、索引的设计 在确定要建立一个索引时,首先我们要确定它是聚集还是非聚集、单列还是多列、唯一还是非唯一、列是升序还是降序、它的存储是如何的,比如:分区、填充因子等。下面逐条来看: 1、聚集索引 (1)首先指出一个误区,主键并不一定是聚集索引,只是在SQL SERVER中,未明确指出的情况下,默认将主键定义为聚集,而Oracle中则默认是非聚集,因为SQL SERVER中的ROWID未开放使用。 (2)聚集索引适合用于需要进行范围查找的列,因为聚集索引的叶子节点存放的是有序的数据行,查询引擎可根据WHERE中给出的范围,直接定位到两端的叶子节点,将这部分节点页的数据根据链表顺序取出即可; (3)聚集索引尽量建立在值不会发生变更的列上,否则会带来非聚集索引的维护; (4)尽量在建立非聚集索引之前建立聚集索引,否则会导致表上所有非聚集索引的重建; (5)聚集索引应该避免建立在数值单调的列上,否则可能会造成IO的竞争,以及B树的不平衡,从而导致数据库系统频繁的维护B树的平衡性。聚集索引的列值最好能够在表中均匀分布。 3、唯一索引 (1)再指出一个误区,聚集索引并不一定是唯一索引,由于SQL SERVER将主键默认定义为聚集索引,事实上,索引是否唯一与是否聚集是不相关的,聚集索引可以是唯一索引,也可以是非唯一索引; (2)将索引设置为唯一,对于等值查找是很有利的,当查到第一条符合条件的纪录时即可停止查找,返回数据,而非唯一索引则要继续查找,同样,由于需要保证唯一性,每一行数据的插入都会去检查重复性;
下面是一个简单的比较表
主键 聚集索引 用途 强制表的实体完整性 对数据行的排序,方便查询用 一个表多少个 一个表最多一个主键 一个表最多一个聚集索引 是否允许多个字段来定义 一个主键可以多个字段来定义 一个索引可以多个字段来定义 是否允许 null 数据行出现 如果要创建的数据列中数据存在null,无法建立主键。创建表时指定的 PRIMARY KEY 约束列隐式转换为 NOT NULL。 没有限制建立聚集索引的列一定必须 not null .也就是可以列的数据是 null参看最后一项比较 是否要求数据必须唯一 要求数据必须唯一 数据即可以唯一,也可以不唯一。看你定义这个索引的 UNIQUE 设置。(这一点需要看后面的一个比较,虽然你的数据列可能不唯一,但是系统会替你产生一个你看不到的唯一列) 创建的逻辑 数据库在创建主键同时,会自动建立一个唯一索引。如果这个表之前没有聚集索引,同时建立主键时候没有强制指定使用非聚集索引,则建立主键时候,同时建立一个唯一的聚集索引 如果未使用 UNIQUE 属性创建聚集索引,数据库引擎 将向表自动添加一个四字节 uniqueifier 列。必要时,数据库引擎 将向行自动添加一个 uniqueifier 值,使每个键唯一。此列和列值供内部使用,用户不能查看或访问。
下面是更加详细的方法 MySQL中可以使用alter table这个SQL语句来为表中的字段添加索引。 使用alter table语句来为表中的字段添加索引的基本语法是:ALTER TABLE ADD INDEX (); 我们来尝试为test中t_name字段添加一个索引。 mysql> alter table test add index(t_name);Query OK, 0 rows affected (0.17 sec)Records: 0 Duplicates: 0 Warnings: 0 执行成功后,我们来看看结果。 mysql> describe test;+------------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+------------+-------------+------+-----+---------+-------+| t_id | int(11) | YES | | NULL | || t_name | varchar(50) | NO | MUL | NULL | || t_password | char(32) | YES | | NULL | || t_birth | date | YES | | NULL | |+------------+-------------+------+-----+---------+-------+4 rows in set (0.00 sec) 结果可以看出,t_name字段的Key这一栏由原来的空白变成了MUL。这个MUL是什么意思呢?简单解释一下:如果Key是MUL,那么该列的值可以重复,该列是一个非唯一索引的前导列(第一列)或者是一个唯一性索引的组成部分但是可以含有空值NULL。
MySQL创建索引方法:ALTER TABLE和CREATE INDEX的区别 2017年05月16日 11:10:06 阅读数:2275 众所周知,MySQL创建索引有两种语法,即:ALTER TABLE HeadOfState ADD INDEX (LastName, FirstName);CREATE INDEX index_name HeadOfState (LastName, FirstName);那么,这两种语法有什么区别呢? 英文原句如下:With CREATE INDEX, we must provide a name for the index. With ALTER TABLE, MySQL creates an index name automatically if you don’t provide one.Unlike ALTER TABLE, the CREATE INDEX statement can create only a single index per statement. In addition, only ALTER TABLE supports the use of PRIMARY KEY. |
【本文地址】