| 【精选】支持向量机SVM的原理、算法、应用超详述 | 您所在的位置:网站首页 › svm的应用领域 › 【精选】支持向量机SVM的原理、算法、应用超详述 |
【精选】支持向量机SVM的原理、算法、应用超详述
|
1.引言 2.原理(线性可分、线性不可分、核函数) 一.引言1.支持向量机[1-2](support vector machines,SVM)是建立在统计学习理论[3-4]VC维理论和结构风险最小化原理基础上的机器学习方法。用于解决数据挖掘或模式 识别领域中数据分类问题它在解决小样本、非线性和高维模式识别问题中表现出许多特有的优势,并在很大程度上克服了“维数灾难”和“过学习”等问题。此外,它具有坚实的理论基础,简单明了的数学模型,因此,在模式识别、回归分析、函数估计、时间序列预测等领域都得到了长足的发展,并被广泛应用于文本识别[5]、手写字体识别[6]、人脸图像识别[7]、基因分类[8]及时间序列预测[9]等。 二、基本原理它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。它基于结构风险最小化理论之上在特征空间中构建最优超平面,使得学习器得到全局最优化,并且在整个样本空间的期望以某个概率满足一定上界。 1.线性可分 首先,对于SVM来说,它用于二分类问题,也就是通过寻找一个分类线(二维是直线,三维是平面,多维是超平面)可以将数据分为两类。 并用线性函数f(x)=w*x+b来构造这个分类器(如下图是一个二维分类线) |
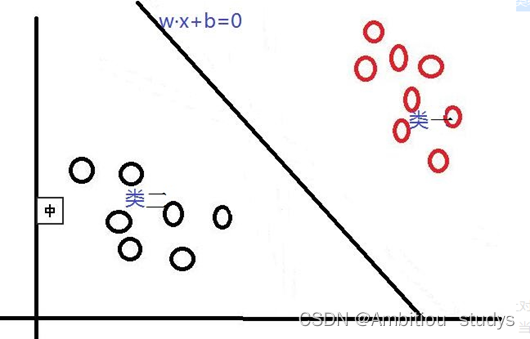 其中,w是权重向量,x为训练元组(X=(X1,X2…Xn),n为特征个数,Xi为每个X在属性i上对应的值),b为偏置,w•x是w和x的点积。当某数据被分类时,就会代入此函数,通过计算f(x)的值来确定所属的类别,当f(x)>0时,此数据被分为类一,当f(x)
其中,w是权重向量,x为训练元组(X=(X1,X2…Xn),n为特征个数,Xi为每个X在属性i上对应的值),b为偏置,w•x是w和x的点积。当某数据被分类时,就会代入此函数,通过计算f(x)的值来确定所属的类别,当f(x)>0时,此数据被分为类一,当f(x)【本文地址】
公司简介
联系我们