| 刘博谈 | 您所在的位置:网站首页 › surfacepro7性能模式 › 刘博谈 |
刘博谈
 大家好,我是刘博,在上一篇文章当中,我们介绍了如何使用ROC曲线来对诊断试剂的灵敏度和特异性进行划分和比较,在这篇文章当中,我们给大家介绍如何使用ROC曲线的曲线下面积(AUC)来对诊断试剂的性能进行评价和比较。 用一个数字来量化实验室检测的诊断准确度的一个常用措施是AUC。数值范围从1.0(两组检测值的完美分离,没有错误分类)到0(理论上,至少;完美分离但100%错误分类)。当完全没有诊断信息时(即两组人群的检测结果具有相同的分布,ROC曲线沿对角线运行),那么面积为0.5。所有具有实用价值的检测的面积都远高于此。面积计算的主要吸引力在于它不关注曲线的某一特定部分,如最接近左上角的区域或某个选定特异性的灵敏度,而是反映整个曲线。 测量曲线下面积 如果你对统计学有所认识,那么就很容易认识到ROC曲线是化学家Frank Wilcoxon引入的非参数双样本统计学的Mann-Whitney版本[1, 2]。例如,面积为0.8,意味着从受影响组中随机选择的人的实验室检测值比从未受影响组中随机选择的人的检测值高(当受影响组的检测值往往比未受影响组高)或低(当受影响组的检测值往往比未受影响组低)的时间占80%。我们将在后续文章中讨论了ROC曲线的AUC与秩和统计之间的关系。 当受影响组和未受影响组之间没有联系时,这个面积很容易从曲线上计算出来,即这个图形下的矩形面积之和。计算面积的分析公式出现在Bamber[1]和Hanley和McNeil[2]的报告中。另外,面积可以从Wilcoxon秩和统计学中获得[3]。 对于参数方法,其面积如何计算也已经有了很多的方法(例如,采用一些模型来拟合曲线的方法),而且,在已发表的评论中,讨论并比较了参数和非参数方法[4, 5]。 当使用AUC、灵敏度或特异性等总结性指标时,会有信息的损失。因此,人们也应该经常直观地检查ROC曲线本身。示例1(见表1)已被用于生成ROC曲线(见图1)和确定临界值水平(见图2)。从示例1测得的AUC见表2。 表1 | 示例1:X检测项目的临床表现措施的计算 X检测(临界浓度,ng/mL)TPTNFPFN灵敏度特异性1-特异性临界点 24.804040%100%0%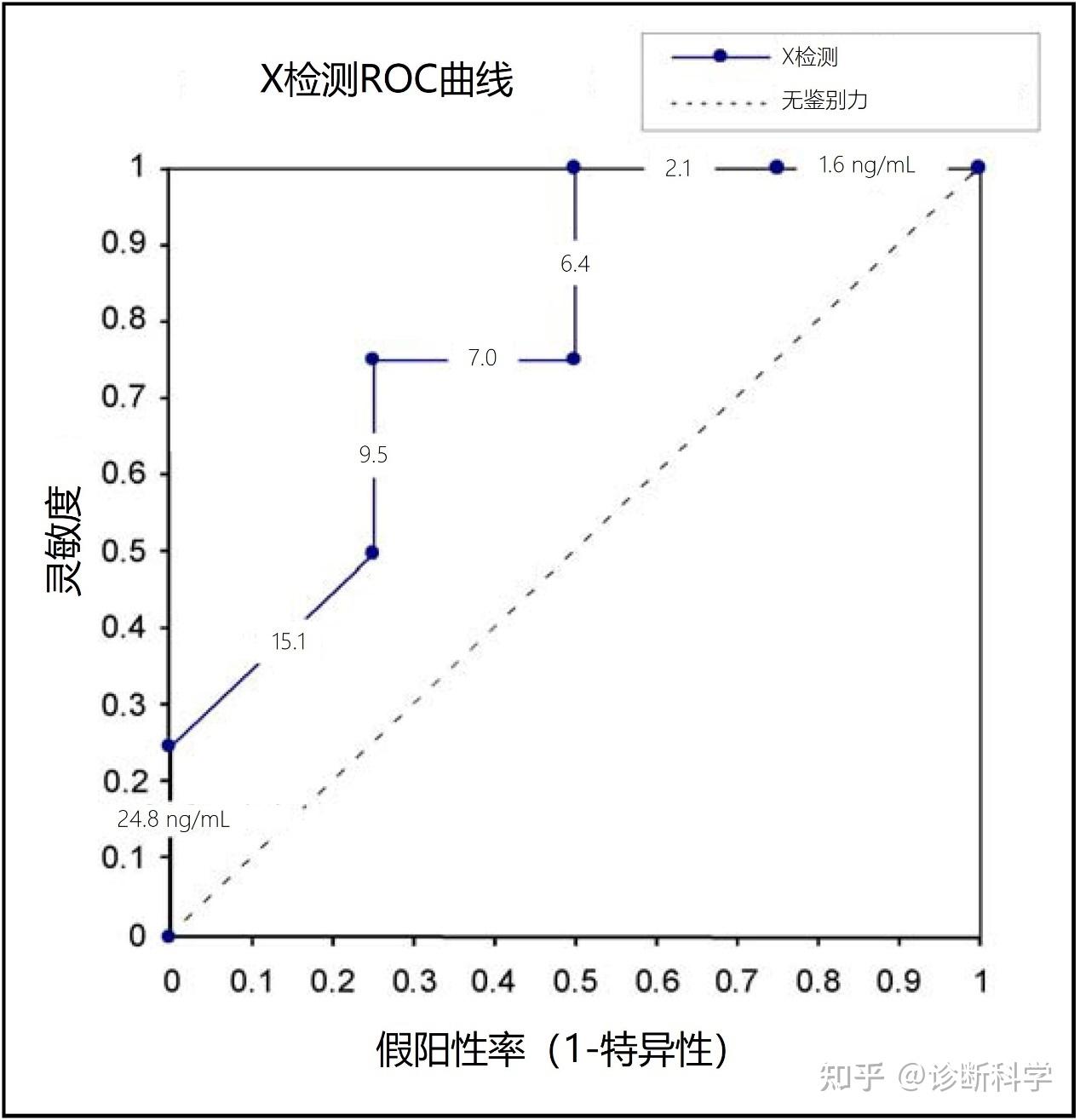 图1 | 使用表1中的数据集构建ROC曲线(每一步都标有基本测量值) 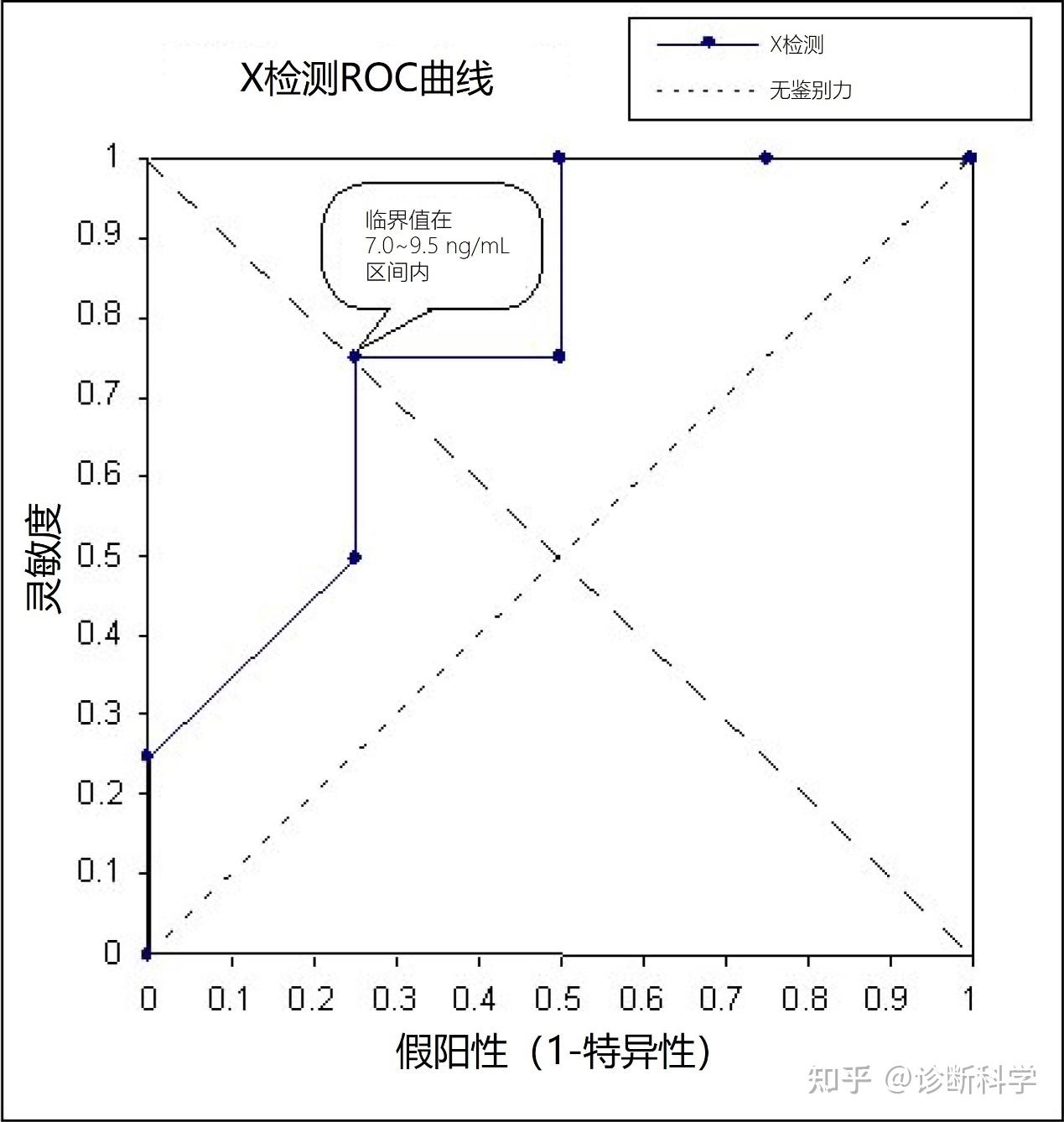 图2 | 构建ROC图的示例 表2 | 示例1中的曲线下面积评估 X检测AUC95%CISEzp患者诊断 = 存在浓度(ng/mL)0.780.42至1.000.1821.540.0614数值较高H0:AUC ≤ 0.5;H1:AUC > 0.5在表2中,不仅列出了AUC(0.78),而且还给出了近似的95%CI(0.42至1.00)。由于样本量小,这个范围相当宽,包括了0.5。因此,不能排除X检测不优于机会(0.5)的可能性(单侧近似P = 0.06)。 AUC的测量也可以看作是所有特异性的平均灵敏度(特异性的范围是0-1.0)或所有灵敏度的平均特异性(灵敏度的范围是0-1.0)。如图3所示,通过计算部分AUC并除以该特异性区间的宽度,也可以确定在一个确定的特异性区间内的平均灵敏度。以类似的方式,平均特异性可以在定义的灵敏度范围内确定,如图4所示。  图3 | 在0.5至0.75特异性区间内的平均灵敏度  图4 | 在0.5到1.0灵敏度区间内的平均特异性 如果我们能确定准确度(灵敏度或特异性)的范围是临床可接受的,那么就可以采用这种平均测量的方法。 比较两项检测的曲线下面积 多个诊断检测的直接统计比较在临床实验室中很常见。通常,两个(或更多)检测是在相同的受试者(或标本)上进行的,如将标本均分后进行比较,这通常被称为「配对设计」。 一个全面的方法是通过使用一个整体的措施,如AUC,来比较整个ROC曲线。这可以通过非参数化或参数化的方式进行,即有或没有一个提供和限制测量物分布形状的模型。这对实验室特别有吸引力,因为这种比较不依赖于选择一个特定的临界值。然而,在比较检测时,用户应该总是直观地检查ROC图,而不是仅仅依靠将所有信息浓缩为一个数字的总结性措施。图5就是一个很好的示例。在这个示例中,两个检测有相似的AUC,但一个向右倾斜,而另一个向左倾斜,这使得A测试在高特异性程度上比B测试更敏感。  图5 | 只有在要求高特异性的情况下,A测试才优于B测试 比较两个AUC的统计量的一个看似自然的选择是AUC的差异除以差异的标准误差(SE)。无效假设H0:AUC1 = AUC2,通过比较z的值(见下文公式1)与标准正态分布[6, 7]来检验,因为z统计量近似于标准正态分布。如果|z| > 1.96,那么这两个AUC在α = 0.05的显著性水平下有明显不同。 (1) 计算测试统计数据 AUC以及它的SE可以用参数方法或非参数方法计算。一种参数方法是基于二态假设[8],非参数方法是基于Mann-Whitney U统计[2]。 双正态假设指出,当用合适的尺度表示时(在某些情况下有变换),被测量具有以下性质:在两个总体(有病、无病)中的每一个,其分布都是正态的(高斯);均值和方差都允许有差异。如果用于生成两条ROC曲线的样本是独立的,那么分母可以通过取两个方差之和的平方根得到。然而,如果样本不被认为是独立的,例如在配对设计中,差异的SE应该包括一个额外的相关项,因为两个AUCs将是相关的。 比较相关的曲线下面积 Hanley和McNeil[7]讨论了在配对设计中比较两个AUC的方法(即检验是否相等)。这种方法使用Dorfman和Alf[1]的方法来计算AUC以及它的SE。也有一种非参数方法来比较配对设计中的两个AUC(DeLong等人)[9]。 成对设计的检测统计量有一个额外的项,包括相关系数,r。 (2) 表3列出了平均相关和平均面积不同值的相关系数r。行值是通过取两个相关性的平均值得到的,(rN + rA)/2。这里,rN是通过两个不同的检测从未受影响的受试者得到的相关系数,而rA是从受影响的受试者得到的。列值是两个AUC的平均值,(A1+A2)/2。相关程度取决于诊断检测的类型。然而,由于标本是从同一受试者身上采集的,因此相关关系很可能是正的。两种诊断检测之间的相关性越大,统计比较就越有力(灵敏),就越有可能宣布差异具有统计学意义。Hanley和McNeil[7]从样本量和统计能力的角度讨论了这个问题,并提出了一个合理的r值表(即表3)。我们将在后续的文章中给出了一个涉及真实数据的计算实例。 表3 | 两个ROC区域之间的相关系数[*] 评级之间的平均相关性[†]平均面积[‡]0.7000.7250.7500.7750.8000.8250.8500.8750.9000.9250.9500.9750.020.020.020.020.020.020.020.020.010.010.010.010.010.040.040.040.030.030.030.030.030.030.030.020.020.020.060.050.050.050.050.050.050.050.040.040.040.030.020.080.070.070.070.070.070.060.060.060.060.050.040.030.100.090.090.090.090.080.080.080.070.070.060.060.040.120.110.110.110.100.100.100.090.090.080.080.070.050.140.130.120.120.120.120.110.110.110.100.090.080.060.160.140.140.140.140.130.130.130.120.110.110.090.070.180.160.160.160.160.150.150.140.140.130.120.110.090.200.180.180.180.170.170.170.160.150.150.140.120.100.220.200.200.190.190.190.180.180.170.160.150.140.110.240.220.220.210.210.210.200.190.190.180.170.150.120.260.240.230.230.230.220.220.210.200.190.180.160.130.280.260.250.250.250.240.240.230.220.210.200.180.150.300.270.270.270.260.260.250.250.240.230.210.190.160.320.290.290.290.280.280.270.260.260.240.230.210.180.340.310.310.310.300.300.290.280.270.260.250.230.190.360.330.330.320.320.310.310.300.290.280.260.240.210.380.350.350.340.340.330.330.320.310.300.280.260.220.400.370.370.360.360.350.350.340.330.320.300.280.240.420.390.390.380.380.370.360.360.350.330.320.290.250.440.410.400.400.400.390.380.380.370.350.340.310.270.460.430.420.420.420.410.400.390.380.370.350.330.290.480.450.440.440.430.430.420.410.400.390.370.350.300.500.470.460.460.450.450.440.430.420.410.390.370.320.520.490.480.480.470.470.460.450.440.430.410.390.340.540.510.500.500.490.490.480.470.460.450.430.410.360.560.530.520.520.510.510.500.490.480.470.450.430.380.580.550.540.540.530.530.520.510.500.490.470.450.400.600.570.560.560.550.550.540.530.520.510.490.470.420.620.590.580.580.570.570.560.550.540.530.510.490.450.640.610.600.600.590.590.580.580.570.550.540.510.470.660.630.620.620.620.610.600.600.590.570.560.530.490.680.650.640.640.640.630.620.620.610.600.580.560.510.700.670.660.660.660.650.650.640.630.620.600.580.540.720.690.690.680.680.670.670.660.650.640.630.600.560.740.710.710.700.700.690.690.680.670.660.650.630.590.760.730.730.720.720.720.710.710.700.690.670.650.610.780.750.750.750.740.740.730.730.720.710.700.680.640.800.770.770.770.760.760.760.750.740.730.720.700.670.820.790.790.790.790.780.780.770.770.760.750.730.700.840.820.810.810.810.810.800.800.790.780.770.760.730.860.840.840.830.830.830.820.820.810.810.800.780.750.880.860.860.860.850.850.850.840.840.830.820.810.790.900.880.880.880.880.870.870.870.860.860.850.840.82来自Hanley JA, McNeil BJ.比较来自相同病例的接收者操作特征曲线下的区域的方法。 [*] 两个ROC区域A1和A2之间的相关系数r是评级(行)和平均区域(列)之间的平均相关的函数。 [†] (rN + rA)/2,其中rN = 未受影响受试者通过两个测试的相关系数;rA=受影响受试者通过两个测试的相关系数。 [‡] (A1+A2)/2 比较平均灵敏度或特异度:曲线下的部分面积方法 当人们想比较两条曲线时,AUC并不总是一个有用的汇总统计。最明显的示例是当两条ROC曲线交叉但AUC相等时,如图5所示。曲线交叉的事实告诉我们,在某些临床环境下,一个检测比另一个检测表现更好,而在其他临床环境下反之亦然。在这样的情况下,临床要求应该影响检测的比较方式。例如,如果我们必须在两种检测中做出选择,而且它们的ROC曲线有交叉,但AUCs几乎相等,我们可以考虑只在高特异性水平上比较检测的灵敏度。一种方法是决定什么水平的特异性是可以接受的,然后比较限制在该特异性(或FP)区间的检测的平均灵敏度。 因此,两个检测的平均灵敏度可以进行比较,但只能在相同的FPF区间内进行,如图3所示。反之,可以通过在选定的灵敏度区间内使用平均特异性来比较两个检测,如图4所示。在任何一种情况下(见图5的示例),两个检测的排名都可能不同,这取决于哪个区间作为其比较的基础。 评估曲线下面积的样本量 确定ROC分析的样本量要求的两个经典参考文献是Hanley和McNeil的论文[2, 7]。这些论文中描述的技术涵盖了三种不同的情况:单样本情况、独立样本的双样本情况、以及对同一受试者进行两次测量的双样本情况(如成对设计)。 单样本案例 当研究者只对单一设备的诊断准确度感兴趣时,可以采取两种方法来确定样本量。一种是确定AUC的CI上的特定宽度所需的样本量。或者,在检测的初步评估中,人们可能想确定获得统计学意义所需的样本量,以检验AUC是否 > 0.50。 首先将讨论指定CI宽度的情况。假设: nA = 受影响受试者的数量,以及 nN = 未受影响受试者的数量。 使用AUC的预期值,可以得到数量Q1和Q2,如下所示: (3) (4) 现在,AUC的SE由一下公式给出[3]: (5) 使用两个n的现实试验值,人们可以改变n,直到获得可接受的CI宽度。如果有已经分析过的试验研究的数据,一个更简单的方法是认识到SEs与样本量的平方根成反比,所以如果: n1 = 试点研究的总样本量, SE(AUC1) = 试点研究的AUC的SE, n2 = 拟议研究的总样本量, SE(AUC2) = 拟议研究的AUC的理想SE。 那么,在试点研究人群和拟议研究人群的患病率保持不变的条件下,n2可以通过解决以下问题简单计算出来。 (6) (7) 在确定样本量的第二种方法中,调查者的重点是证明诊断性检测功效的假设检验。一个非信息性检验(即与随机选择无差异的检验)的AUC为0.50。因此,要检测的假设是AUC = 0.50,与单方选择AUC > 0.50。为满足上述条件,必须满足的条件如下: (8) 其中: n为受试者总人数; δ为AUC与0.50之间规定(希望)的差异; Zα = G(1 - α),为显著性水平α下(单边)假设检验的临界值,以及 Zβ = G(1 - β),为所需功率水平定义的常数:80%、90%或95%的功率分别为0.84、1.28或1.645[10]。这里的G代表标准高斯(正态)累积分布函数,见公式(9)和(10)。 (9) 和 (10) 双样本案例 两个检测的准确度可以通过检测两个AUC的差异进行比较。在下面的示例中,比较将确定任何一个检测的AUC是否比另一个大,因此是一个双侧比较。在McNeil和Hanley的论文中可以找到一个使用单边比较的类似示例[11]。 其中: AUC1 = 测试1的曲线下面积,测试1是测试2的前提或标准,要与之进行比较。 AUC2 = 测试2的曲线下面积。 Zα = G(1 - α/2),为显著性水平α下(双侧)假设检验的临界值,以及 Zβ = G(1 - β),为所需功率水平定义的常数:80%、90%或95%的功率分别为0.84、1.28或1.645。这里的G代表标准高斯(正常)累积分布函数,见公式(9)和(10)。 为了计算所需的样本量,我们首先为两个AUC选择现实的暂定值,这两个AUC相差一个量,即δ,我们希望能够记录它是否存在。然后计算出中间量V1和V2,如下所示,即: (11) (12) 现在,两个检测和两个状态(未受影响,受影响)中的每一个的显著性检测所需的样本量是n1 = n2 = (13) 如果用测试1和测试2检测相同的受试者,就可以节省样本量。节省的数量与两个AUC之间的相关程度有关。更确切地说, 其中: nunpaired为使用两个独立样本所需的受试者总数。 npaired为使用配对样本所需的受试者总数,以及 r为两个AUC的相关性,可从表3中插值[7]。 尽管用于初步估计的研究可能与最终研究的最终方案不完全一致,但它们仍然为手头的问题提供了近似的估计。产生样本量要求的过程总是充满了风险,因为我们需要提供未知的参数估计,而这正是委托研究的目的。因此,我们应该准备在收集到验证或反驳计算中使用的假设值的数据时修改这些估计值。关于适用于样本量计算的非参数化方差估计方法,见DeLong等人[9]。 诊断科学编辑团队收集、整理和编撰,如需更多资讯,请关注公众号诊断科学(DiagnosticsScience)。 参考文献 Bamber D. The area above the ordinal dominance graph and the area below the receiver operating characteristic graph. J Math Psychol. 1975;12(4):387-415. Hanley JA, McNeil BJ. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology. 1982;143(1):29-36. Hollander M, Wolfe DA. Nonparametric Statistical Methods. New York, NY: John Wiley; 1973:67-78. Zweig MH, Campbell G. Receiver-operating characteristic (ROC) plots: a fundamental evaluation tool in clinical medicine. Clin Chem. 1993;39(4):561-577. Hanley JA. Receiver operating characteristic (ROC) methodology: the state of the art. Crit Rev Diagn Imaging. 1989;29(3):307-335. Pepe MS. The Statistical Evaluation of Medical Tests for Classification and Prediction. New York, NY: Oxford University Press; 2003:218-220. Hanley JA, McNeil BJ. A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology. 1983;148(3):839-843. Dorfman DD, Alf E. Maximum likelihood estimation of parameters of signal detection theory and determination of confidence intervals— rating method data. J Math Psychol. 1969;6:487-496. DeLong ER, DeLong DM, Clarke-Pearson DL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics. 1988;44(3):837-845. Kahn HA, Sempos CT. Statistical Methods in Epidemiology. New York, NY: Oxford University Press; 1989:34-35. McNeil BJ, Hanley JA. Statistical approaches to the analysis of receiver operating characteristic (ROC) curves. Med Decis Making. 1984;4(2):137-150.(广告分割线) 本文的内容都出自《接受者操作特征曲线(ROC)使用手册》,相关资料在我们微信线上商店有售,购买链接请见下方~ 如果想选购其他IVD方面的开发、验证和使用相关技术资料,也可以直接访问我们的微信商店,具体链接请见下方~ 另外,我们的仓储式知识星球也开张啦,最大的特点就是资料全面且在不断快速更新,这其中包括国内法规和指南,我们公众号当中收费的国外法规翻译、市场研报和线上商店中39元价位的技术手册等等,只需要298元即可成为星球会员,欢迎大家加入,具体链接请见下方~ *** |
【本文地址】