| 【Linux】进程概念 | 您所在的位置:网站首页 › struct里面加一个新的变量为什么就输不出来了 › 【Linux】进程概念 |
【Linux】进程概念
|
进程概念
讲进程前的知识冯诺依曼体系结构操作系统(Operator System)
进程概念介绍上下文数据详解另一种查看进程的方式通过系统调用创建进程 - fork()
进程状态僵尸进程孤儿进程
进程优先级进程的其他概念环境变量概念环境变量PATH的引出常见环境变量与环境变量相关的命令环境变量的组织方式main函数的参数通过代码获取环境变量环境变量通常是具有全局属性的
程序地址空间进程地址空间
有的同学可能早已听闻冯诺依曼这个大佬的名字了,但并不知道冯诺依曼体系结构是什么,这里就先介绍下这个体系结构。 我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系结构。也就是当代计算机所遵守的硬件结构。 看图: 输入设备 键盘、磁盘、网卡、显卡、话筒、摄像头等等 输出设备 显示器、磁盘、网卡、显卡、音响、打印机等等 存储器 内存 中央处理器(运算器 + 控制器) CPU 要强调一点,磁盘不是在存储器范围中的,存储器只有内存,磁盘是外设。 外设可以简单的理解为输入设备和输出设备。 根据上面的图我们可以看到,任何外设在数据层面都基本要先和存储器打交道,CPU在数据层面上也直接和内存打交道。而为什么CPU不直接和外设打交道呢,根本原因就是CPU太快了,而外设太慢了。但是有了内存CPU就不需要和外设打交道了。 也就可以说,内存是整个体系结构中的核心设备。 输入设备将数据输入到内存当中进行缓存,然后再让CPU再将内存中的数据进行加工,最后再将数据刷新到外设当中。 相对于内存而言的 input 和 output 合起来就是IO,IO又可分为本地IO和网络IO等等,这些分类都是取决去输入和输出设备的。 最后强调几点: 这里的存储器指的是内存。 不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(输入或输出设备)。 外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取。 一句话,所有设备都只能直接和内存打交道。 操作系统(Operator System)任何计算机系统都包含一个基本的程序集合,称为操作系统(OS)。笼统的理解,操作系统包括: 内核(进程管理,内存管理,文件管理,驱动管理) 其他程序(例如函数库,shell程序等等) 上面的理解起来太难了。 通俗的来讲,操作系统就是一款专门针对软硬件资源进行管理工作的软件 OS对下要管理好软硬件资源。 OS对上要给用户提供稳定、高效、安全的运行环境。 怎么管理呢? 举个栗子:我们平时在学校时,学校有我们的档案,档案中保存着我们的数据信息,校长是学校的头,也就是管理者。管理者是专门发出某些决策的,比如说要开除某个学生,或者给某些学生发奖学金等等,但是校长不会亲自去干这些事情,干事的是辅导员,也就是执行者。而我们这些同学就是被管理者。 那么这个例子类比到计算机当中: 校长就是操作系统(管理者),辅导员就是驱动程序(执行者),学生就是底层硬件。 就先讲这些硬件部分的。 如何管理这些硬件呢?和上面的例子一样,校长管理每个学生需要有每个学生对应的档案,而操作系统需要每个硬件有其对应的数据信息。 而Linux操作系统是用C语言、汇编语言写的,但主要是C。我们在学C语言的时候,想要描述一个物体的某些特征,会用到struct结构体,这里想要描述硬件的特征,也是用struct来实现的。这就是用结构体先描述一下硬件的基本信息。 如何将每个硬件对应的特征数据聚合起来呢,用的就是数据结构。还拿那个例子来说,如果校长要对某些学生发奖学金,就会有一个预发放奖学金的学生的名单,名单上本来是空白的,看有的同学学习好就把这些学生的名字增加到名单中;误操作了或者看到名单中有的学生参与打架斗殴事件了就给他从名单中剥离,是不是很像对数据进行增删查改的工作,所以这个名单对应到计算机当中其实就相当于一些数据结构。比如说链表。 当操作系统想要对等待处理的硬件挨个操作时,前面已经产生了每个硬件基本信息的结构体,就可以搞一个双向循环链表来将这些结构体连接到一块。然后对软硬件的管理工作就变成了这里对链表的增删查改的工作。 这一工作就将被管理对象使用特性的数据结构组织起来了。 而上面的两部简单来讲就是先描述,再组织(如果没看懂这六个字就回头再看一遍)。 对上的用户部分是这样的: 首先OS不信任任何用户,但是操作系统还是要为用户提供服务,此时就需要用到系统调用接口来帮忙。 生活中也有类似的场景,比如说我们去银行取钱的时候,银行门口有保安,银行柜台有很厚的防弹玻璃,只留了一个很小的口来让我们和工作人员进行对话、输密码等操作,如果银行信任我们的话,就不会搞这些麻烦东西了,直接让我们进金库里面取钱就行了,但是并不是这样。银行并不信任我们,但是还要为我们提供服务,就搞了柜台、工作人员等等来帮助我们走流程。这里的柜台对应到上面的图就是所谓的系统调用接口,银行就是操作系统。 系统调用接口其实就是一些C函数,但是是一些比较复杂的C函数。通过这些C函数来实现某些操作。这里的C函数并不是我们平时用的C库函数。而是非常底层的C函数。 C库函数、C++库函数、Java、python等等,都是一些大佬对系统调用接口进行了封装,并以第三方库(直接用语言)的形式呈现给了我们,比如说printf()这样的函数,调用了这样的函数在底层中会有对应的系统调用接口。当然不是所有的系统调用接口都被封装了,不同语言的支持力度是不一样的。 上面的不同语言的库函数和系统调用接口是上下层的关系,系统调用接口是下层,各种库函数是上层。 系统调用接口再往上的用户操作接口就是操作系统为了让用户操作方便而提供的一些软件层,比方说一些图形化界面、lib库、指令等等;再往上就是用户的行为了,比如说你图形化界面的点击操作,输入指令的时候的操作等等。 前面的铺垫知识就这么些,基本上都说的是硬件,接下来就说点软件的,开始讲进程。 进程 概念介绍各位应该打小就对任务管理器很熟悉,当你们打游戏卡了的时候按住三个键就能蹦出来个任务管理器,然后直接选中那个卡住的游戏,点击结束任务,然后重新开游戏就OK了。但是各位应该和我一样没有仔细观察过任务管理器,我先截个图看看: 啥是进程? 有的课本上是这样讲的:加载到内存中的程序,就叫做进程。但是这样的说法是不严谨的。至于为什么等会再说。 首先,说几个问题。 系统中可不可能出现多个进程? 完全有可能 操作系统来管理进程吗? 正确的 操作系统是如何管理进程的? 先描述,在组织。 第三点刚刚讲硬件的地方也说了,先描述再组织。 那么对软件怎么描述呢?一样的。 任何进程在形成时,操作系统要为该进程创建PCB(process control block),翻译过来就是进程控制块。 PCB是什么? OS上面,PCB叫做进程控制块,就是一个结构体类型。 也就是: struct PCB { //进程的所有属性 };在Linux系统中,PCB具体下来就是: struct test_struct { //进程的所有属性 };类似的关系还有:shell -> bash task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含着进程的信息。 曾经我们所有启动程序的过程,本质都是在系统上面创建进程。 看图: 所以有了PCB后,所有的进程管理任务与进程对应的程序毫无关系,与进程对应的内核(操作系统)创建的该进程的PCB强相关。 听起来有点蒙,看图: task_ struct内容分类(下面的我只挑部分重点讲讲): 标示符(pid): 描述本进程的唯一标示符,用来区别其他进程。 获取pid:getpid(),该函数头文件为:sys/types.h和unistd.h
状态: 任务状态,退出代码,退出信号等。 我们平时写C语言的时候main函数返回值给了谁? 我把test.cpp改一下: 优先级: 相对于其他进程的优先级。 这里要提一下权限和优先级的区别。 权限是决定能不能; 优先级是已经能了,而谁先谁后的问题。 等会再详谈 程序计数器: 程序中即将被执行的下一条指令的地址。 PC指针:Program Counter,是通用寄存器,但是有特殊用途,用来指向当前运行指令的下一条指令。 程序能够不断的运行,从当前语句处运行到下一条语句,是通过pc指针来进行下一条代码和数据的读取,来执行下一条语句的操作,然后不断改变pc指针就可以不断地往下运行。 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针 我们可以通过task_struct中的内存指针找到其对应进程的代码和数据。 上下文数据: 进程执行时处理器的寄存器中的数据 待会详谈。 I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。 IO是对内存而言的,而进程就在内存中。 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。 os的调度模块,可以让进程较为均衡的获得CPU资源。 而调度进程的时候就是通过记账信息来调度的。 其他信息 上下文数据详解
进程在运行期间是有切换的,意思就是图上第一个进程到cpu中跑一会,达到规定时间后,如果当前进程的代码没有跑完,或者代码在规定时间内已经跑完了,就停止当前进程,将该进程的task_struct转到队尾,再跑下一个进程。而进程可能存在大量的临时数据暂时存在CPU的寄存器中。 上面的这段话有几点要强调一下: 进程的代码可能不是很短时间就能运行完毕的。规定每个进程单次运行的时间片,比如10ms在单个CPU的情况下, 用户感受到的多个进程同时在运行,本质上是通过CPU的快速切换完成的,实际上每次只运行一个进程。CPU的寄存器中存储了当前正在运行的进程的临时数据。对于第三点,当有两个CPU的时候,可能出现两个进程同时运行的情况。 对于第四点,一个CPU只有一套寄存器,当进程被强制停止转到队尾的时候,操作系统是怎么保存进程当前执行到哪里的数据信息的呢?换言之就是,当再次执行到这个进程,怎么续上前一次进程执行的进度的呢? 虽然寄存器硬件只有一份,但是寄存器里的数据是当前进程的。 所以当进程执行时间超过时间片时,就将寄存器中的核心数据存到当前进程的task_struct中,然后中断当前进程并切换到下一个进程。 这就叫做保护上下文,然后下次执行到该进程的时候就能续着原来的进度走了,后面的这句话就叫做回复上下文。 通过上下文,我们能感受到进程是被切换的。 所以上下文信息就是寄存器中与进程强相关的临时数据。 另一种查看进程的方式ls /proc查看当前所有的进程 ls /proc/PID 进该目录下看看: 当这个进程退出了之后,就不能再看这个进程的信息了,因为根本就没有这个进程了。 通过系统调用创建进程 - fork()上面所有创建进程的方法都是用命令来创建的,如何用代码来创建进程呢? fork()函数就可以做到。
看个例子:
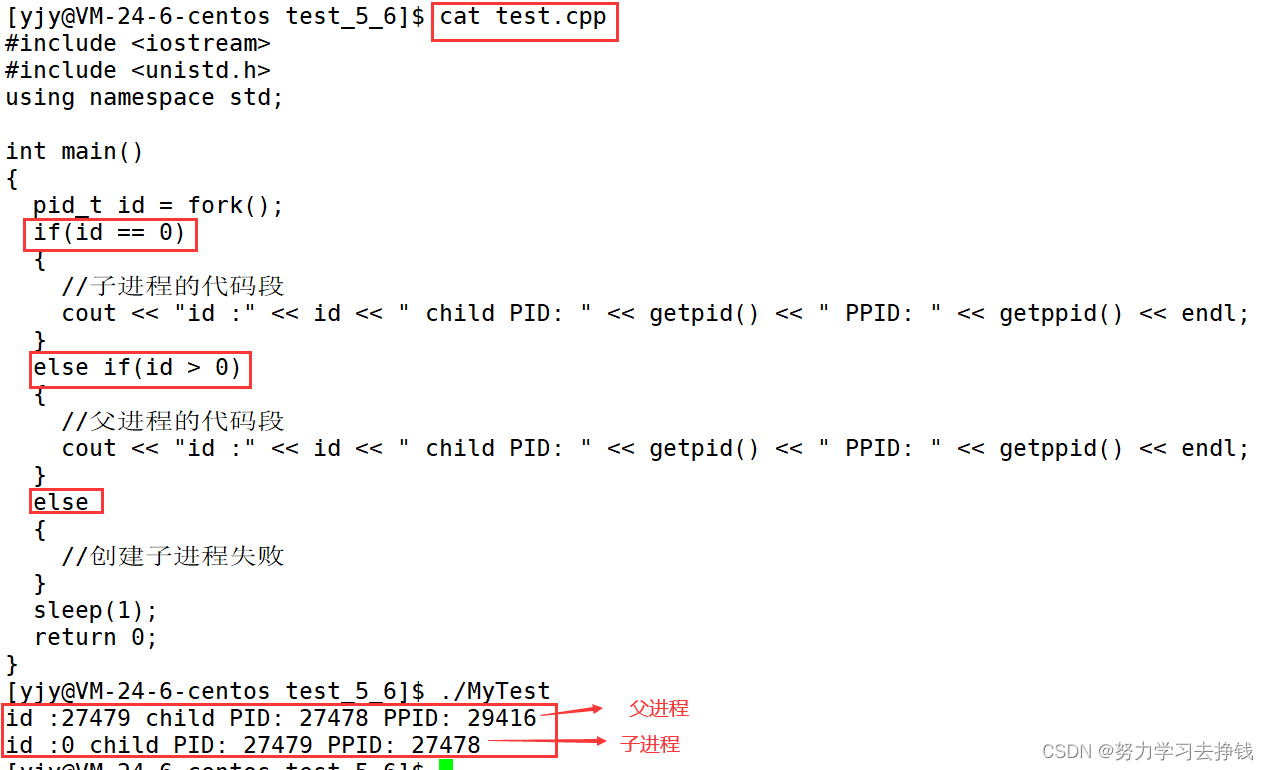
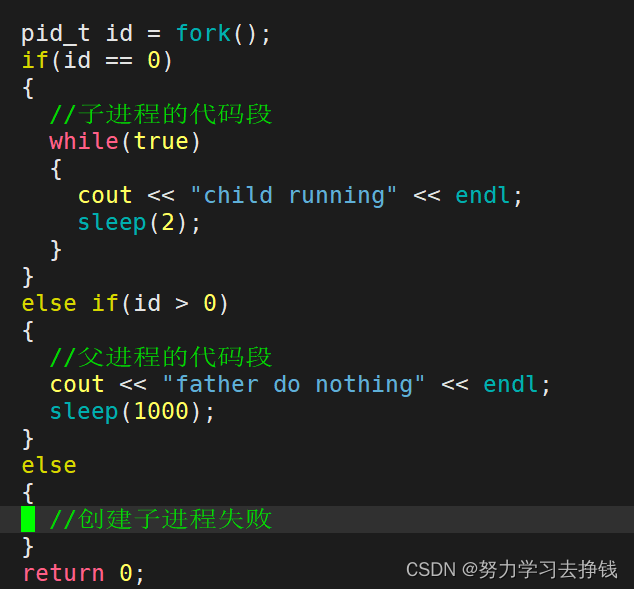
再看一个: 看: 上面两个例子中,每个打印的时候,都有两个进程在打印,一个子一个父。 原因就是fork创建了一个子进程。 如何理解fork创建子进程? 首先,不管是在命令行上执行命令创建了一个进程,还是fork创建了一个进程,在操作系统角度,二者没有什么差别,都是创建了一个进程。fork本质是创建进程 ——>系统里多了一个进程——>与进程相关的内核数据结构(task_struct)+进程代码和数据在系统里多了一份。我们只是fork创建了子进程,但是子进程对应的代码和数据在默认情况下会“继承”父进程的代码和数据。内核数据结构task_struct也会以父进程为模板初始化子进程的task_struct。就像子承父业一样。fork之后父子进程的代码是共享的。 进程是具有独立性的,父子间要做到相互不影响,共享的代码就不能被修改。 默认情况下,数据也是“共享的”,不过需要考虑修改的情况,就要用到“写时拷贝”来完成进程数据的独立性。 如果这里看不懂,没关系,后面还会讲写时拷贝的。 写时拷贝是一种可以推迟甚至避免拷贝数据的技术。内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间。只用在需要写入的时候才会复制地址空间,从而使各个进程拥有各自的地址空间。也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候。 ———————————————— 版权声明:本文为CSDN博主「「已注销」」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/zztingfeng/article/details/83351718 我们创建子进程,就是为了和父进程干同样的事情的话是没有意义的。一般要让子进程做不一样的事,这时候就要用到 fork返回值 和 if else 语句配合来完成。 fork的返回值: fork创建子进程失败时会返回小于0的数。成功时会给父进程返回子进程的PID,给子进程返回0。这样搭配 if else 语句就能做到让两个进程做不一样的事情了。 fork函数的返回值类型是pid_t pid_t是一个typedef定义类型。 用它来表示进程id类型。 用的时候要引头文件: 具体的细节大家自己可以搜一下,我搜了一下,但是内容都不相同,有的说pid_t等同于与int,有的说pid_t等同于short,婆说婆有理,公说公有理。谁有理咱也不知道,咱就知道这是个fork返回值的类型,用的时候要引头文件就行了。 如何理解fork有两个返回值? 如果一个函数已经开始执行return了,函数的核心功能已经执行完了。 pid_t fork() { //创建子进程的逻辑 return xxx; }返回值是数据,return时会发生写时拷贝。 我还是刚入门的,具体的我也讲不清,想要深入了解一下可以看这篇博客:详解fork()函数的两个返回值 如何理解两个返回值的设定? 一个父可能有多个子,但是子一定只有一个父,想要在父进程中分清楚每个子,就要通过子的PID来找, 所以要把子进程的PID返回给父进程;而子进程不需要父进程的PID,可以直接通过getppid()就可以得到PPID来找到父进程。
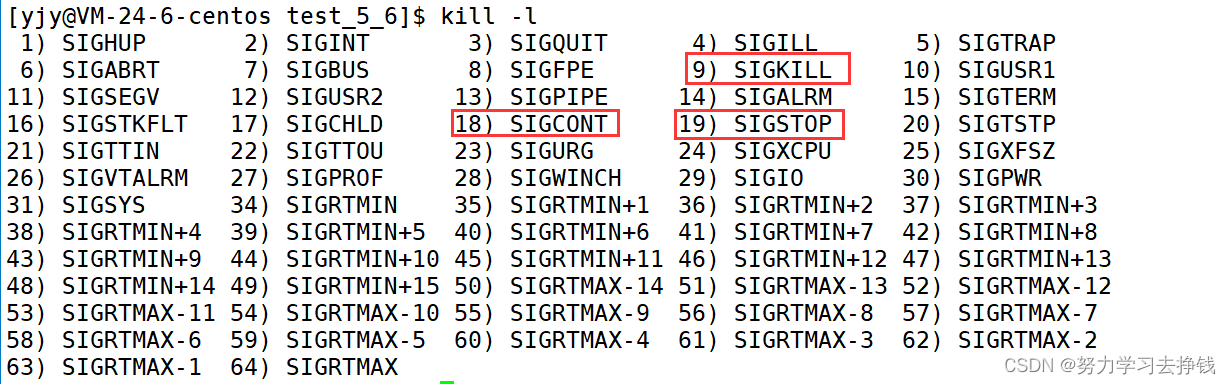
fork之后父子谁先跑是不确定的,二者都是进程,由调度器来决定。 进程状态进程状态是存在进程对应的PCB中的。 其意义在于方便操作系统快速判断进程,来完成特定的功能。比如调度器调度进程,需要根据进程的状态来调度,其本质是一种分类。 具体状态有: R运行状态(running): 并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里。 S睡眠状态(sleeping): 意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠(interruptible sleep))。 来个例子: 虽然屏幕上以肉眼可见的飞速打印着hello world,但是仅是肉眼。 CPU说:肉眼可见的速度并不是我的极限,屏幕拖慢了我的速度。在CPU眼里,这个打印速度太慢了,每次都让这个进程要等屏幕的资源加载,放在run_queue中太浪费时间了,就让这个进程去wait_queue中等屏幕资源加载完成了之后再让这个进程回到run_queue中,然后再让进程用CPU资源,才打印出来我们所看到的那个速度。 屏幕拉满了,CPU可没有拉满,甚至觉得太慢了,还让进程转到等待队列里面歇会再来运行队列里跑。 上面的进程在wait_queue中的状态就是S状态(下面有图解)。 D磁盘休眠状态(Disk sleep)有时候也叫不可中断睡眠状态(uninterruptible sleep),在这个状态的进程通常会等待IO的结束。 这个没法演示,只能讲个例子: 比如说现在内存中有一个进程想要往磁盘中写数据,数据量还不小,但是磁盘速度比较慢,磁盘开始工作时,进程是没有事情做的,但是操作系统看到的是进程在偷懒,如果操作系统此时杀死了进程,等磁盘写完后,将是否写入成功的信息带回来时,进程找不到了,这时候就出问题了,所以本来进程是不能被杀掉的,进程在等待磁盘写数据的时候的状态就叫做D状态,也就是不可中断状态。 S和D状态都是当我们完成某种任务的时候,任务条件不具备,需要进程进行某种等待。 有运行队列。也有等待队列,也可以是阻塞、挂起。 看图: T停止状态(stopped): 可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行。 先说一条命令,kill -l 可以显示所有的kill信号。 这里就用到三个 比如说我们kill -9 PID就可以以命令行的方式杀掉对应的进程。 下面就说T状态的例子: 原因是进程本来是在前台跑的,对应的就是带+的,此时我们按下ctrl + c进程可以终止,但是我们输入别的命令没有作用。 但是放在后台跑的话,我们按下ctrl + c没有用,只能用kill命令来结束进程,但是们可以在该进程在后台运行的时候输入其他命令,比如说创建一个文件。 X死亡状态(dead):这个状态只是一个返回状态,你不会在任务列表里看到这个状态。 这个我不知道咋演示。 就是回收进程资源,也就是回收进程相关的内核数据结构+代码和数据。
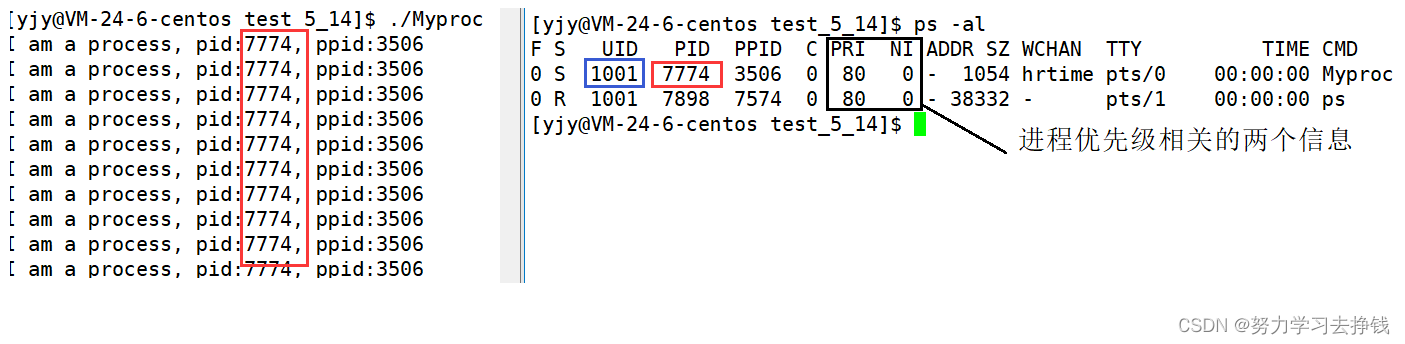
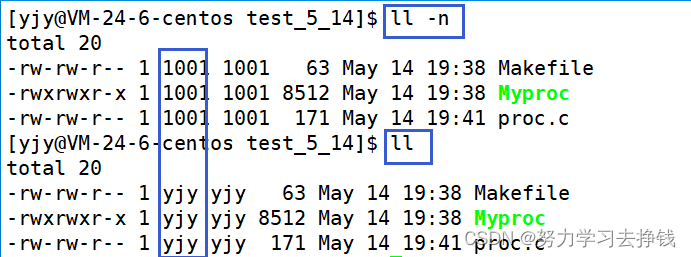
提到死亡状态就要说一说僵尸状态了。 僵尸进程僵死状态(Zombies)是一个比较特殊的状态。当某个进程退出并且其父进程没有读取到该进程退出的返回代码时这个进程就变成了僵死(尸)进程。 僵死进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码。 所以,只要子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入Z状态。 举一个生活中很形象的例子: 一个精神小伙骑着鬼火闯红灯的时候被车创了,这个精神小伙被创的躺在地上一动不动,此时有人打电话报警,警察来了,叫法医,法医一检查,人似了,然后法医认定这个人已经似了的状态就叫死亡状态。僵尸状态就是这个人被创了之后到法医检查之前的状态,法医还没鉴定的时候还不确定这个人是否似了,这样的状态对应到进程中的状态就叫做僵尸状态。此时该进程就是僵尸进程。 来个例子: 代码如下: 然后运行代码: 查看进程状态,看到父子进程都为S,然后杀掉子进程,父进程未结束,子进程已经结束,子进程变为僵尸进程。 总结一下:僵尸进程就是没有人检测或者回收进程(这个工作由父进程来做),该进程退出就进入了僵尸进程。 父进程如何检测和回收现在先不讲,以后再说这,这里只需要知道僵尸进程是啥就行了。 正常的进程退出时,所有的资源并不是立即释放的,而是先让其进入僵尸状态,将退出信息放入task_struct中,然后再进入死亡状态。 进程的退出状态必须被维持下去,因为他要告诉关心它的进程(父进程):你交给我的任务,我办的怎么样了。 可父进程如果一直不读取,那子进程就一直处于Z状态。 维护退出状态本身就是要用数据维护,也属于进程基本信息,所以保存在task_struct(PCB)中,换句话说,Z状态一直不退出,PCB一直都要维护。 那一个父进程创建了很多子进程,就是不回收,是不是就会造成内存资源的浪费?是的!因为数据结构对象本身就要占用内存,想想C中定义一个结构体变量(对象),是要在内存的某个位置进行开辟空间! 内存泄漏?正确的。 如何避免?后面讲 ok,上面僵尸进程是子进程先退而父进程未退,子进程就变成了僵尸进程。 那如果父进程先退,子进程未退呢? 这种情况子进程就变成了孤儿进程。 孤儿进程长什么样子? 先把代码给出来: 然后再运行,就长这样: 仔细观察的话,可以发现父进程挂掉了之后子进程的PPID变成了1。PID为1的是啥进程? 答案是操作系统。 首先说一点:进程为什么要有优先级? 前面说到了运行队列,队列里面有不同的进程排队。我们来类比一下。 假如我们此刻在学校食堂某一个窗口排队,然后我们前后都有人,这样每个人都在排队,谁在队头,谁就能打到饭,谁不在队头,就要等,这就是优先级。那么排队就是因为这个档口的饭泰香辣,这一队的人都想吃这个档口的饭,但是就只有这一个档口,档口开多点就好,那么用专业的术语来说就是资源太少,类比到进程中就是进程在排队等待cpu资源。 优先级本质上就是资源分配的一种方式。 怎么查看进程的优先级呢? 不急,先写个C程序: 运行起来后再开一个对话框: ps -al 命令可以查看优先级相关信息。 UID : 代表执行者的身份 PID : 代表这个进程的代号 PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号 PRI :代表这个进程可被执行的优先级,其值越小越早被执行 NI :代表这个进程的nice值 先说UID,也叫用户ID,我们ll查看文件信息时加上-n选项,可看到文件拥有者和所属组的UID 然后再说优先级有关的PRI和NI。 PRI :代表这个进程可被执行的优先级,其值越小越早被执行 NI :代表这个进程的nice值 PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高,上面的第一张例图就有PRI的值为80。 那NI呢?就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值 PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice 这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行,所以,调整进程优先级,在Linux下,就是调整进程nice值,nice其取值范围是-20至19,一共40个级别。 PIR和NI是可以手动调整的,但不建议,这里把例子给出来: 在进程运行期间,右侧输入top,然后按下r,输入左侧进程的PID,然后输入10,就可以将PID对应进程的NI值改为10。 然后再改一下: 再改成-5看看: 这就说明 PRI(new) = PRI(old) + NI 中的 PRI(old) 一般都是80。是龟腚的。 再来验证下NI的范围: 将NI改为-100: 可以看到NI改的幅度再大,最终跑不出-20~19这个范围。 将nice值设置为一个较小的范围可以保证优先级再怎么设置,也只能是一种相对的优先级,不能出现绝对的优先级,否则会出现严重的进程“饥饿问题” 饥饿问题指的是某进程长时间得不到cpu资源,当等到资源了,进程其对应的任务已经没有意义时,就称改进程被饿死。 如果不理解上述的饥饿问题的话,就再类比一下刚刚的例子: 当你在排队等饭的时候,前面有人插你的队(这里对应到进程中就是:插队的进程NI值修改了一下),然后你选择忍气吞声继续耐心等待,然后又陆续有人插你的队,如果没有人主动干预这种现象的话,前面一直有人插你的队,并且你一直呆在当前队列当中,你会一直打不到饭,直到活活饿死。虽然有点极端,但我觉得这样讲就比较好理解了。进程修改NI值就可能会导致有别的进程“插队”的问题,也就是饥饿问题。 那么绝对不能发生上述的事情啊,所以我上初中的时候食堂会有专门的大叔(或者学生会)管插队这种事情。那么也有关进程插队的,叫做调度器,前面也提到过了,其作用呢就是较为均衡的让每个进程享受到CPU资源。不让出现旱的旱死,涝的涝死的情况。这也是NI值不能修改的太大的原因。 需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进程的优先级变化。可以理解nice值是进程优先级的修正修正数据。 优先级就讲到这。 进程的其他概念竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级 独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰 并行: 多个进程在多个CPU下分别,同时进行运行,这称之为并行 并发: 多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发 竞争性和独立性就不解释了,前面也涉及到了。 说一下并行和并发。 并行,是指同一时刻在 多个CPU 下有 多个进程 正在 运行。 并发,是指一个CPU下,在一个时间段内,多个进程都得以运行。 其实这两个概念可以对应到最开始讲的那个运行队列中的。 举一个并发的例子:一个cpu中设定时间片为10ms,然后有三个进程在跑,一秒钟之内,所有的进程加起来一共跑了100次,第一个进程占了30次,第二个进程占了35次,第三个进程也占了35次。这样这三个进程在这一秒钟内都跑了,在我们眼里是都在运行,但是在当前这个cpu眼里是一次只跑一个的,但是对我们来说太快了,看起来就是一秒钟这三个进程都在运行,这就叫做并发。 在实际的多CPU场景中,并行和并发可能同时存在。 这个前面也说到了,再强调一下。 这个就讲到这,下面讲一下环境变量。 环境变量 概念环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数。 说起来有点晦涩,我把Windows下的给出来,兴许你们见过: 如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关 环境变量帮助编译器进行查找。 看不懂没关系,先看下面的。 环境变量PATH的引出环境变量通常具有某些特殊用途,还有在系统当中通常具有全局特性。 我在我前面的博客中也说过:命令,程序,工具…本质上都是一个可以执行的文件。ls 也是个命令,那么也就是说这也是个文件,在哪放着呢? 在 /usr/bin 路径下放着: 有的同学可能会说是因为路径可以帮系统确定对应程序在哪里放着。 但是ls这些系统命令可以不用加路径就能直接执行呢? 是因为环境变量PATH。 echo $环境变量名 就可以查看环境变量的信息。
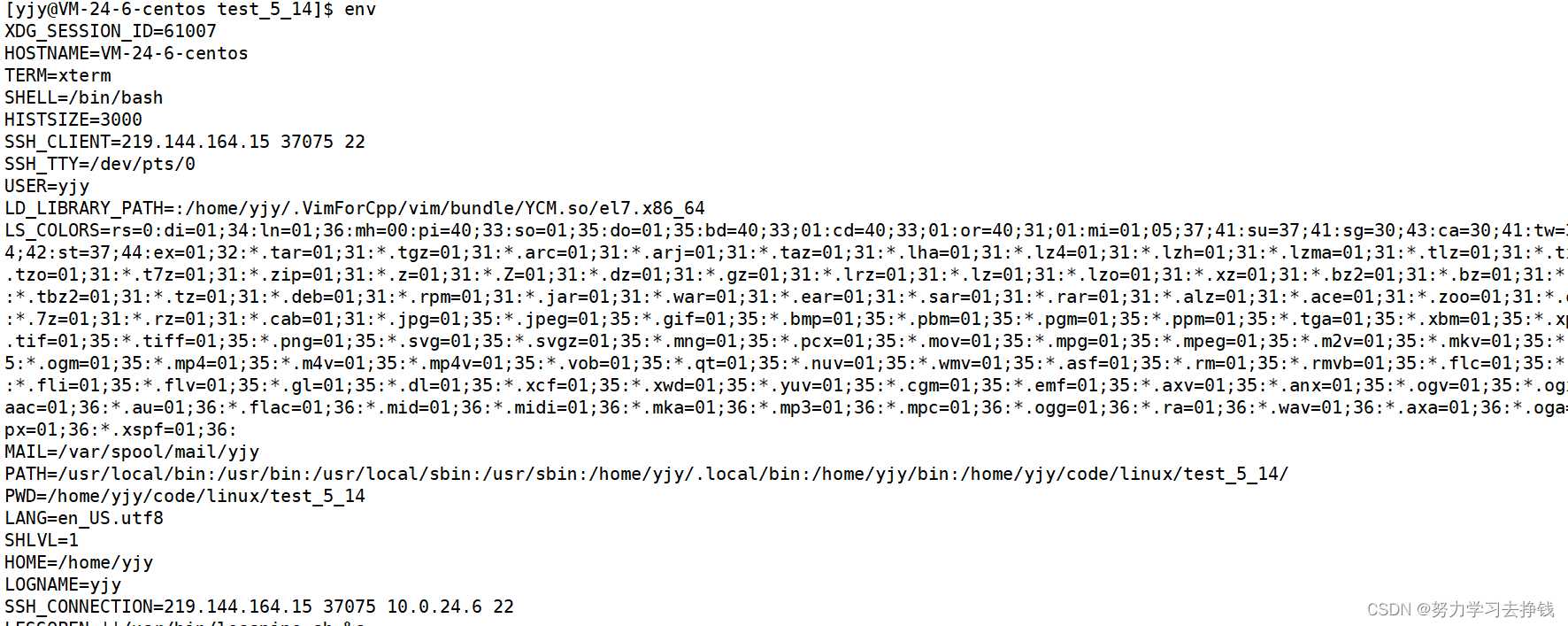
这就是 ls 不用 路径/ls 这样用的原因。 当执行了一个不带路径的命令时,系统会在PATH的所有路径中挨个查找,找到了就不再往下一个路径找了,直接进入该路径执行所需命令,如果到最后都没找到就会输出一句:command not found 这句话。 若你想让自己写的可执行程序也能不加路径就直接运行的话,有两种方法。 法一: 将该命令拷贝到PATH中的任意路径下即可,但是这样会污染命令池,就是当你后期随便执行了一条命令时,你发现怎么多打印了一条信息,可能就是命令池污染了。 法二: 将可执行程序对应的绝对路径添加到PATH中。 这里把例子给出来: 也是两种做法: 第一种做法:直接export PATH=绝对路径,这样会将所有的路径直接覆盖掉,但是仅在当此会话中有效。退出后重新登录还是原样。 再登陆就恢复了: 下面讲第二种方法: export PATH=$PATH:绝对路径 这也是在本次会话中有效。 不建议改环境变量,真有必要改了再改也不迟,没那么麻烦,小心前期改了后期忘了,结果执行某条命令出问题。 常见环境变量PATH : 指定命令的搜索路径 HOME : 指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录) SHELL : 当前Shell,它的值通常是/bin/bash 查看某一环境变量的命令: echo $环境变量名 刚刚PATH演示过了,这里就给HOME和SHELL 查看所有的环境变量: env
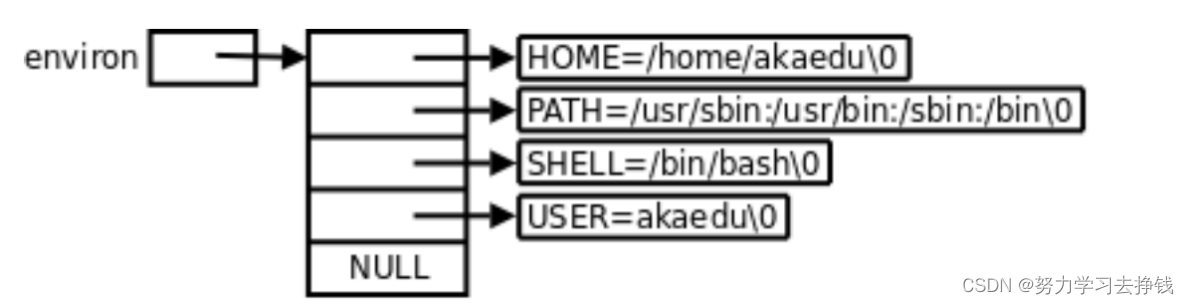
刚刚的三个也在里面: 环境变量也是变量,有变量名,有变量的内容,是在操作系统中维护的。 变量名 + 变量内容。 比如说 C语言中 int a = 10; 变量名就是a,变量的内容就是10 而环境变量中HOME = /home/yjy 变量名就是HOME,变量内容就是/home/yjy 语言上定义变量的本质是在内存中开辟空间,环境变量本质是os在内存/磁盘(os为自身开的)上开辟的空间,用来保存系统的相关数据。 与环境变量相关的命令 echo: 显示某个环境变量值export: 设置一个新的环境变量env: 显示所有环境变量unset: 清除环境变量set: 显示本地定义的shell变量和环境变量123点都展示过了。 说45。 系统上还存在一种变量,是与本次登录有关的变量,只在本次登陆有效,叫本地变量。 展示: 定义一个myval: 但是都仅在本次对话中有效,退出了就没了。 unset 环境变量名 可以取消环境变量:
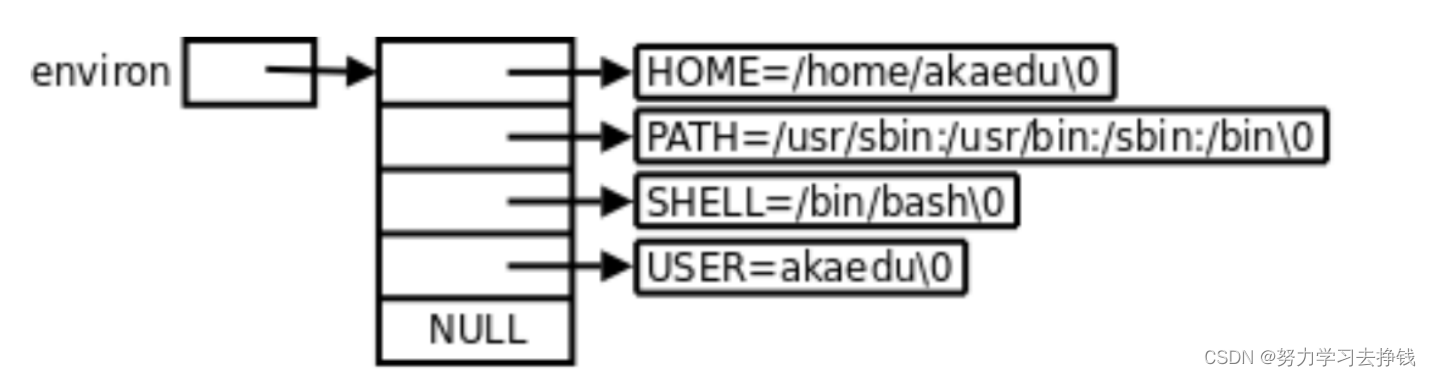
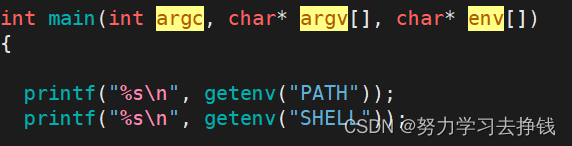
每个进程都会收到一张环境表,环境表是一个字符指针数组,每个指针指向一个以’\0’结尾的环境字符串。 main函数的参数我们日常写C代码的时候,main函数中是不带参数的。 但是main函数其实是可以带参数的。
比如说我编译链接好了proc.c文件(编译不过去的话在命令后面加上 -std=c99就可以了),生成了Myproc这个可执行的文件。 我在命令行上输入 ./Myproc ,这就是一条命令。 而对应到上面的argv数组中,数组中的第一个指针指向的就是 ./Myproc 这个字符串,第二个指针指向的是NULL。argc的值就是1。 我上面main函数中做的事情就是打印argv的各个元素。 看例子: 但是好像argc没体现出它的作用,这个例子中我们可以直接将 argv[i] 是否为空来作为终止条件。像这样: 但是我们可以通过argc来控制命令行参数的个数: 方法一: mian的第三个参数 第二种方法: 但是上面两种都不是很好用,每次搞的太多了。 还有一种比上面的更好用的方法,getenv(“环境变量名”),可以显示: 其实都是这张图: 环境变量再怎么用也是不常用的东西,重在理解。 环境变量通常是具有全局属性的怎么理解这个标题? 首先演示个东西: 前面我们也讲了一点关于fork的知识,知道了子进程和父进程。 再看下这个运行结果: 前面也说了,子进程会继承父进程的很多东西,那么环境变量也是,子进程会继承父进程的。 来证明一下: 先在bash(父进程)中搞一个本地变量,然后再看子进程中是否有这个变量。 子进程中的代码: 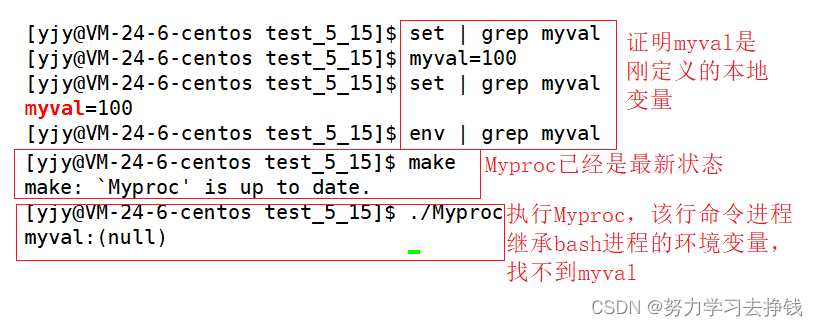
明显看到本地变量无法继承。 再将bash中的本地变量改为环境变量,然后再看子进程中是否有这个环境变量。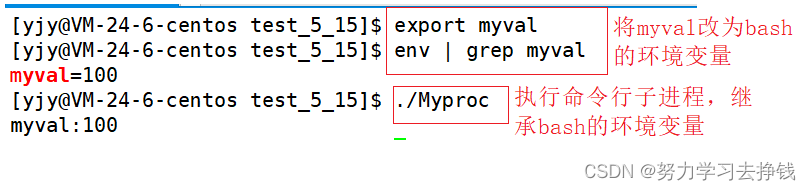 那么这就能说明一点了,就是标题了。 那么这就能说明一点了,就是标题了。
这样理解:环境变量具有“全局属性”本质是环境变量可以被子进程继承下去。 bash不断往上找父进程就可以找到操作系统 所以说像我们的gcc,gdb这些能够编译调试等功能都是通过环境变量的帮助查找对应的头文件/库的位置的。可能很多同学都跟我一样,刚学编译链接细节的时候很懵,想着这些命令是怎么做到的,其实就有环境变更量的帮助。 环境变量就讲到这,我已经拉满了,再往下就不会了。 下面讲一个更重要的知识:程序地址空间 程序地址空间大家学语言阶段的时候肯定是听说过内存四区这个概念的,像下面这张图: 但是这样的说法其实是不准确的。 一个问题,上面的这张图代表的是内存吗? 答案是:不是的。 这只是虚拟地址。不是真正内存的物理空间。 不信的话看代码: 下面用fork创建了子进程,有一个父与子都能用的变量val = 10,三秒后子将val改为50,然后父进程不做变化。 我们来看一下结果:
怎么可能? 如果子进程和父进程使用的val的物理空间地址一样的话,是绝对不可能存在两个值的情况的。但是为什么出现了这样的结果?? 这里就变相证明了我最初说的那一点: 进程中的地址是虚拟地址。不是真正内存的物理空间。 如果是物理空间的话,上面的例子是绝对不可能出现的。 说几点: 变量内容不一样,所以父子进程输出的变量绝对不是同一个变量但地址值是一样的,说明,该地址绝对不是物理地址!在Linux地址下,这种地址叫做 虚拟地址我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理。OS负责将 虚拟地址 转化成 物理地址 。 所以之前标题说‘程序的地址空间’是不准确的,准确的应该说成 进程地址空间。 进程地址空间怎么说呢? 拟人化一下,在每个进程的眼里,它们都是“独占”物理空间的。还是下面这张图:
每个进程都有一个地址空间,都认为自己在独占物理内存。 还是那六个字:先描述,再组织。 这个地址空间,在内核中是一个数据类型,是具体的进程的地址空间变量。 也是个结构体:struct mm_struct 如果我们想用C语言将地址空间划分小区间的话,可以像下面这样: 上面最开始给的那个例子,二者的地址相同,为何值不同,现在就能开始解释了。 就是因为父子进程地址中的地址都是虚拟地址,二者在显示上是相同的,但是换到物理内存中,二者val的地址是不一样的。 二者物理内存不同,是通过页表来实现的。 我们看一下数学层面上函数的定义 函数(function),数学术语。其定义通常分为传统定义和近代定义,函数的两个定义本质是相同的,只是叙述概念的出发点不同,传统定义是从运动变化的观点出发,而近代定义是从集合、映射的观点出发。函数的近代定义是给定一个数集A,假设其中的元素为x,对A中的元素x施加对应法则f,记作f(x),得到另一数集B,假设B中的元素为y,则y与x之间的等量关系可以用y=f(x)表示,函数概念含有三个要素:定义域A、值域B和对应法则f。其中核心是对应法则f,它是函数关系的本质特征。 上面的定义我加粗了一部分。 其实放在这里说挺合适的,进程的虚拟地址通过页表映射到物理内存中,就是其实际的物理内存地址。虚拟地址对应到上面数学定义中数集A,实际物理内存中的地址对应数集B,页表就是对应法则f。 每个进程都会有对应的页表。 然后看下面这张图: 上面的图就说名了val的问题,同一个变量,地址相同,其实是虚拟地址相同,内容不同其实是被映射到了不同的物理地址! 那为什么要多加一层虚拟地址才行呢?不能直接访问物理内存吗? 这样设计肯定是有好处的: 通过添加一层软件层,完成有效的对进程操作内存进行风险管理(权限管理),本质目的是为了,保护物理内存以及各个进程的数据安全!也就是进程自己管自己的空间,不要把手伸到别的进程所属的空间当中。 比如说,为什么代码中修改不了字符常量,本质就是操作系统给你的权限只有读权限,没有写权限。 将内存申请和内存使用的概念在时间上划分清楚,通过虚拟地址空间,来屏蔽地层申请内存的过程,达到进程读写内存和0S进行内存管理操作,进行软件上面的分离。举个例子: 当你想要开辟1000个字节时,我们能立马使用吗? 答案是不一定,这1000个字节中,可能有很多你是暂时不用的。在操作系统的角度:如果将1000个字节全部给你可能意味着这些空间中的一部分空间本来是可以给别的进程来立即使用的,但是现在被你闲置了。 此时操作系统就进程说:先在你的虚拟地址中把你想要的地址给你开好,等你真正要用某块空间了再给你。相当于是打欠条了。 说完这个就能说写时拷贝了 写时拷贝,意思就是当你在代码中写了你要用某块空间的时候,操作系统先答应你,然后在你进程虚拟地址开那块空间,如果你对这块空间只是读的话,不需要修改,那么当物理地址中有一份就可以了,进程可以通过页表映射后找到这一份读取。当进程需要对虚拟地址中的内容进行修改时操作系统才会在物理内存中再开一份空间来供进程修改,这就是写时拷贝。 不管你是否要对数据进行修改,操作系统都会先讲虚拟地址中的空间给你,物理内存先不给你(如果已经有一份了的话),如果从头到尾都不修改那个值,就不会给你开辟物理内存,如果某一时刻需要修改了,这时才会在物理内存中开辟空间。 站在CPU和应用层的角度,进程统–可以看做统一使用4GB空间,而且每个空间区域的相对位置,是比较确定的。OS最终这样设计的目的,达到一个目标:每个进程都认为自己是独占系统资源的。比如说CPU每次在跑进程的时候,如果没有虚拟地址,CPU就还得跑到物理地址中找到代码里main函数的位置才能开始。这样就大大降低了效率,所以虚拟地址就派上用场了,操作系统会直接将main函数的地址通过页表映射到物理内存中,然后就可以直接找到代码中main的位置。 进程的概念讲到这里,就差不多了。 前面说到了课本中讲进程的概念是代码和数据加载到内存中就叫进程。到这里也就能理解为什么我说这个说法不严谨了。 加载到内存中的,不止代码和数据,加上上面讲的还有进程控制块(task_struct),进程地址空间(mm_strcut),页表。我不知道还有没有其他的。反正不止代码和数据。 到此结束。。。 |

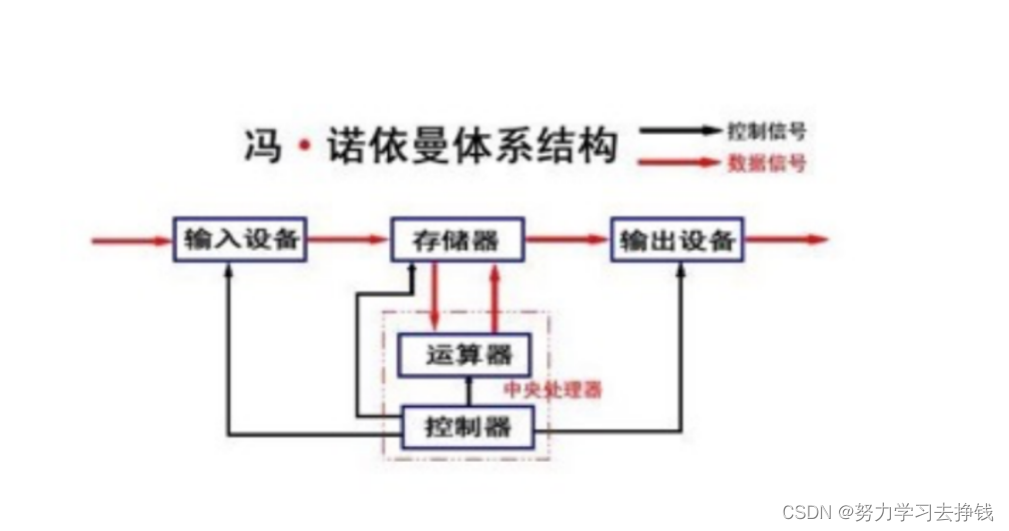 截至目前,我们所认识的计算机,都是有一个个的硬件组件组成,挨个说图上的:
截至目前,我们所认识的计算机,都是有一个个的硬件组件组成,挨个说图上的: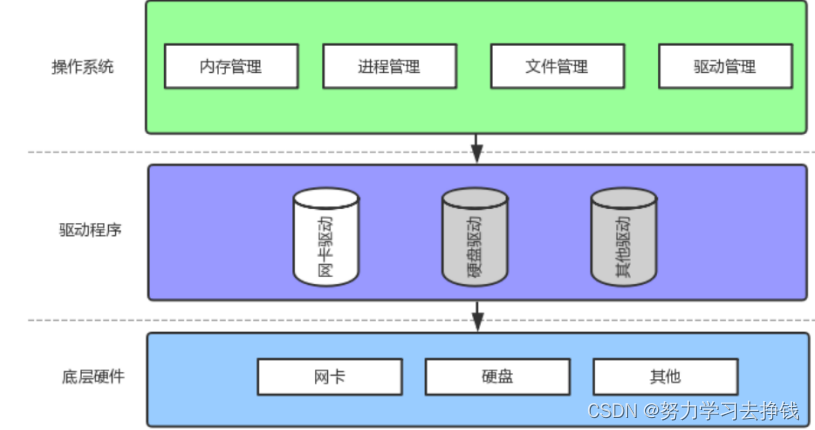 上面的图并不够完整,只是操作系统对下的硬件部分。
上面的图并不够完整,只是操作系统对下的硬件部分。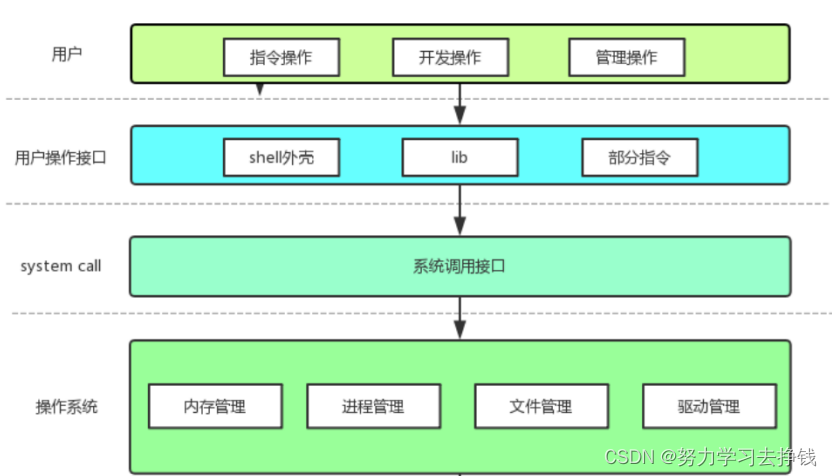 为什么对用户有这么多层呢?
为什么对用户有这么多层呢? 可以看到左上角有两个字:进程。
可以看到左上角有两个字:进程。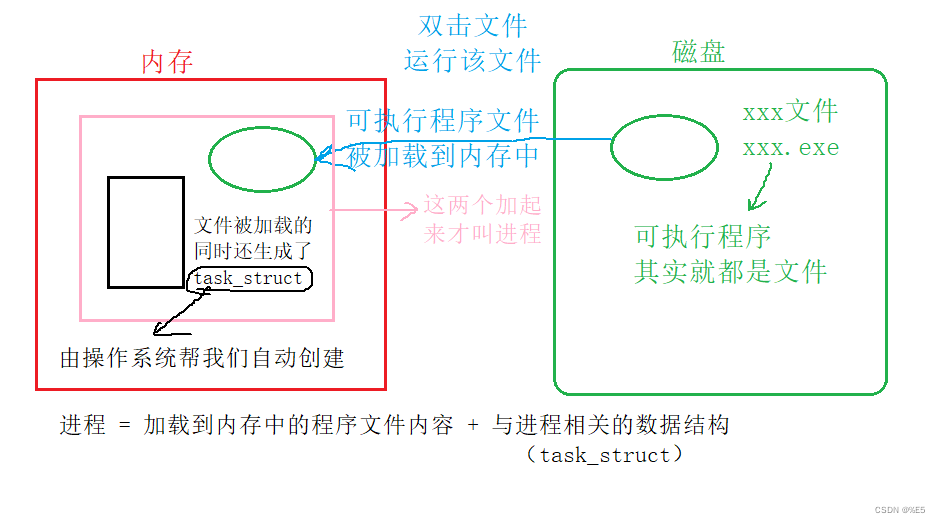 task_struct包含了进程内部的所有属性信息。其实task_struct将文件的精华信息提炼出来,而且可以通过task_struct找到其对应的文件。
task_struct包含了进程内部的所有属性信息。其实task_struct将文件的精华信息提炼出来,而且可以通过task_struct找到其对应的文件。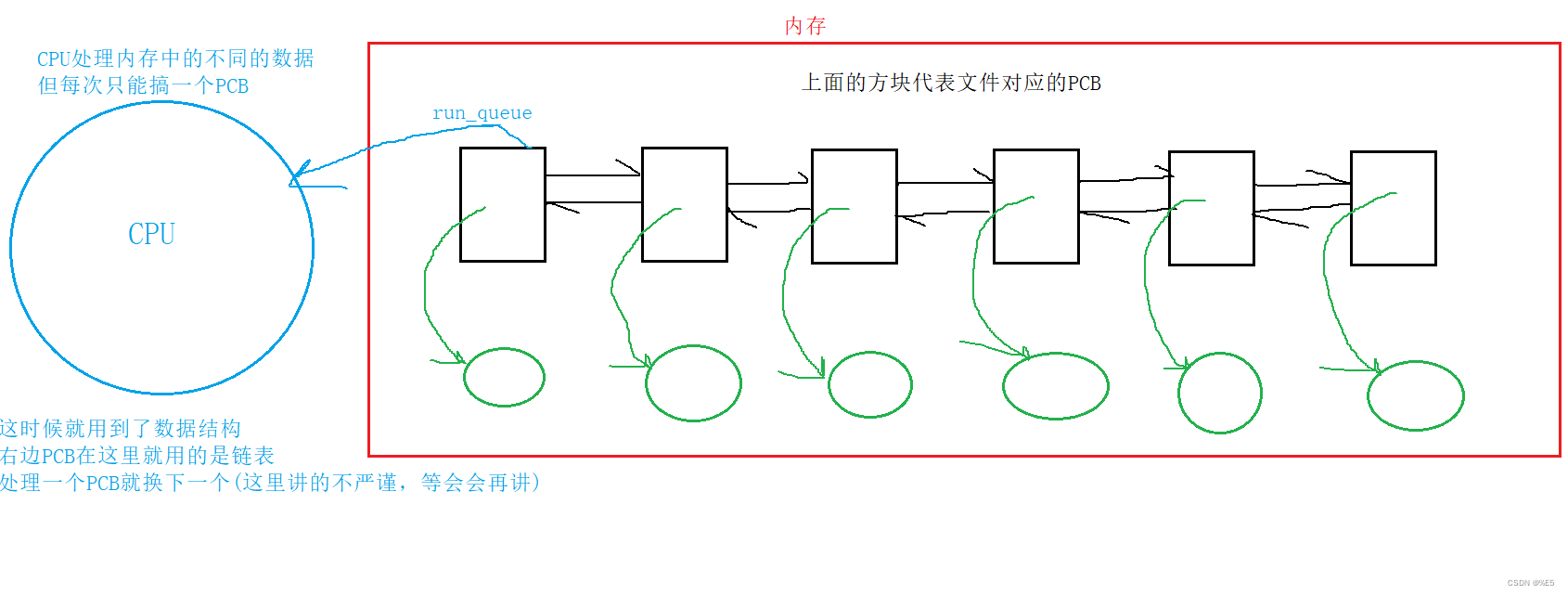 上面的图里,内存中有好多的PCB,这些是怎么被区分开来的。
上面的图里,内存中有好多的PCB,这些是怎么被区分开来的。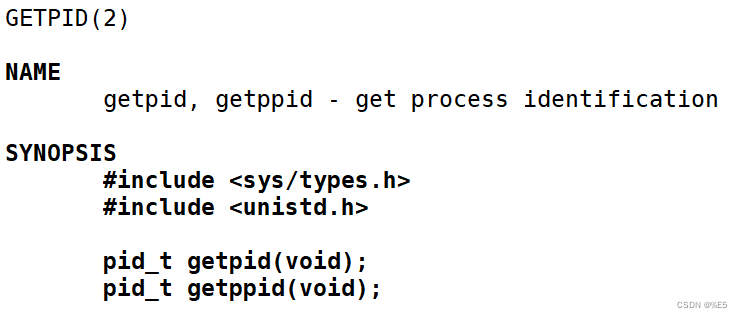 然后我来写一个简单的代码,跑一下看看pid
然后我来写一个简单的代码,跑一下看看pid 
 PID左边的PPID为父进程的PID这里./MyTest的PPID其实就是bash
PID左边的PPID为父进程的PID这里./MyTest的PPID其实就是bash 在命令行上运行的命令,基本上父进程都是bash。 当我把运行的进程停止后,就找不到pid了
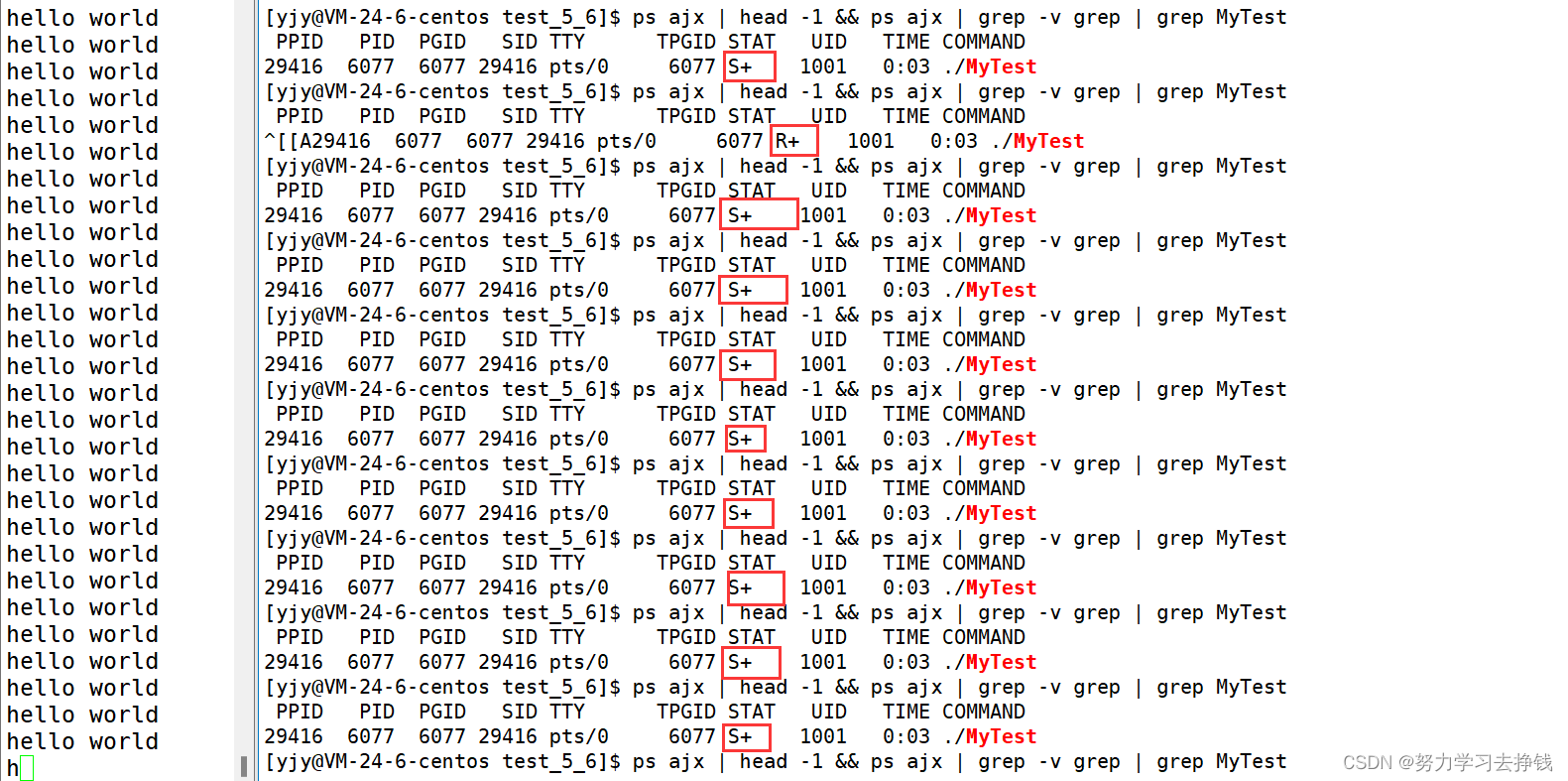
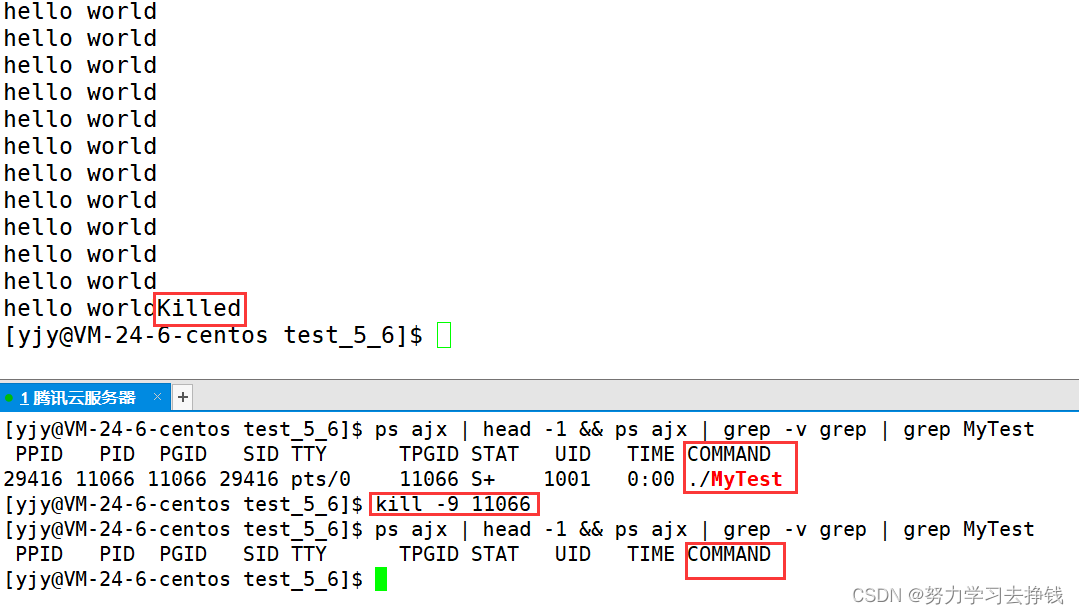
在命令行上运行的命令,基本上父进程都是bash。 当我把运行的进程停止后,就找不到pid了 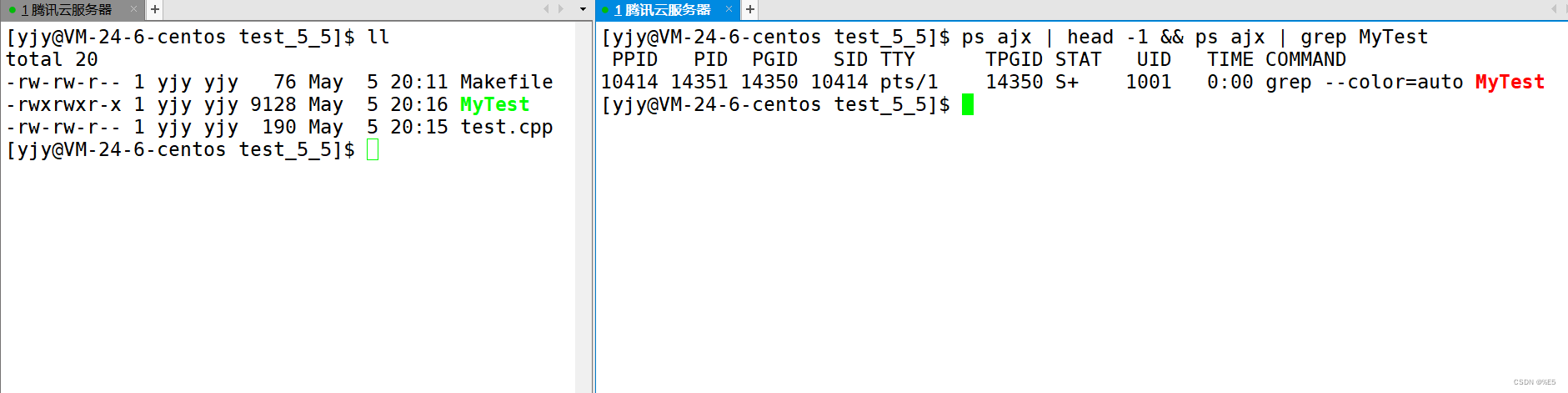 上面查出来的只是ps ajx | head -1 && ps ajx | grep MyTest那行命令的进程,因为这行命令是为了找MyTest的,而这行命令也是包含MyTest的,如果想要不显示这个进程,可以加上grep -v grep
上面查出来的只是ps ajx | head -1 && ps ajx | grep MyTest那行命令的进程,因为这行命令是为了找MyTest的,而这行命令也是包含MyTest的,如果想要不显示这个进程,可以加上grep -v grep 
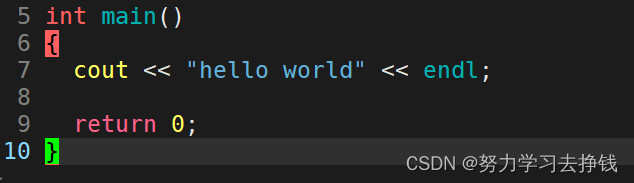 这里main函数返回值是0,也就是./MyTest进程的退出码。 我们可以用 echo $? 来查看上一条命令的退出码:
这里main函数返回值是0,也就是./MyTest进程的退出码。 我们可以用 echo $? 来查看上一条命令的退出码:  我这里再改一下main的返回值:
我这里再改一下main的返回值: 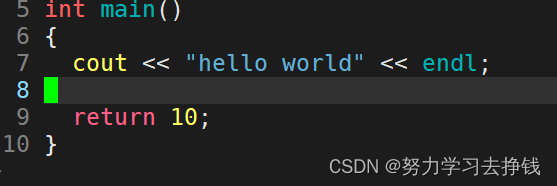 再运行:
再运行:  再用几次echo $?:
再用几次echo $?: 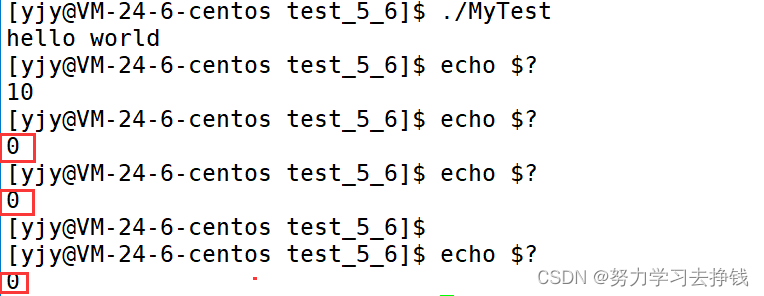 发现变成0了,因为echo $? 也是一条命令,这个进程也有对应的退出码。 main函数返回值给了test_struct中的exit_code,每条命令的退出码由这条命令决定。 除了上面的这点,还有状态这个东西,比如说运行状态,阻塞状态,死亡状态,僵尸状态等等,但现在讲不了,等会才能讲。
发现变成0了,因为echo $? 也是一条命令,这个进程也有对应的退出码。 main函数返回值给了test_struct中的exit_code,每条命令的退出码由这条命令决定。 除了上面的这点,还有状态这个东西,比如说运行状态,阻塞状态,死亡状态,僵尸状态等等,但现在讲不了,等会才能讲。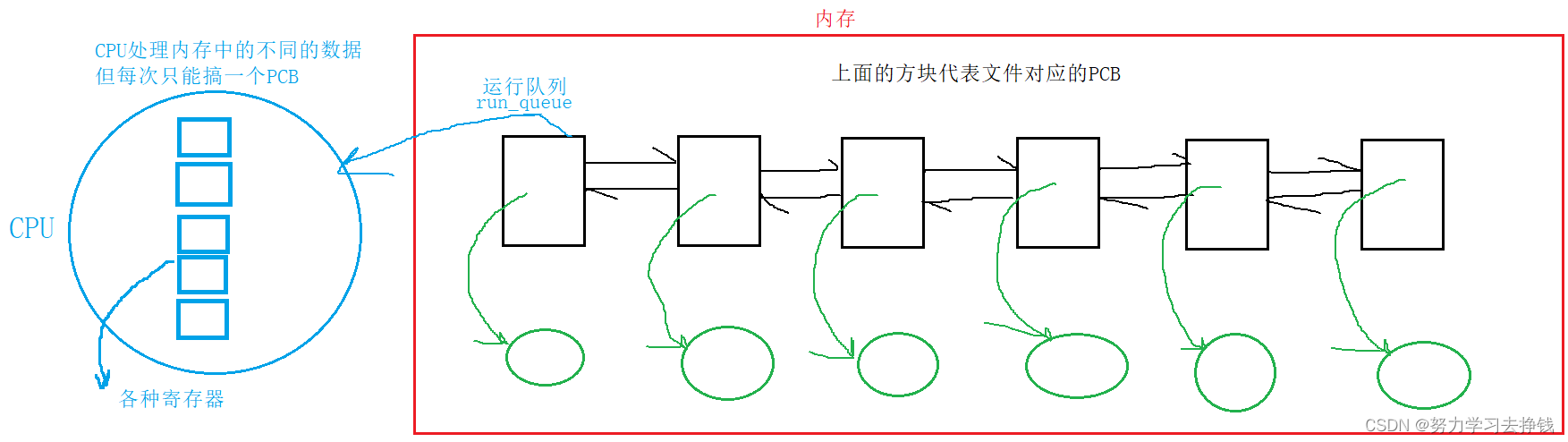 还是这张图,需要解释点东西。
还是这张图,需要解释点东西。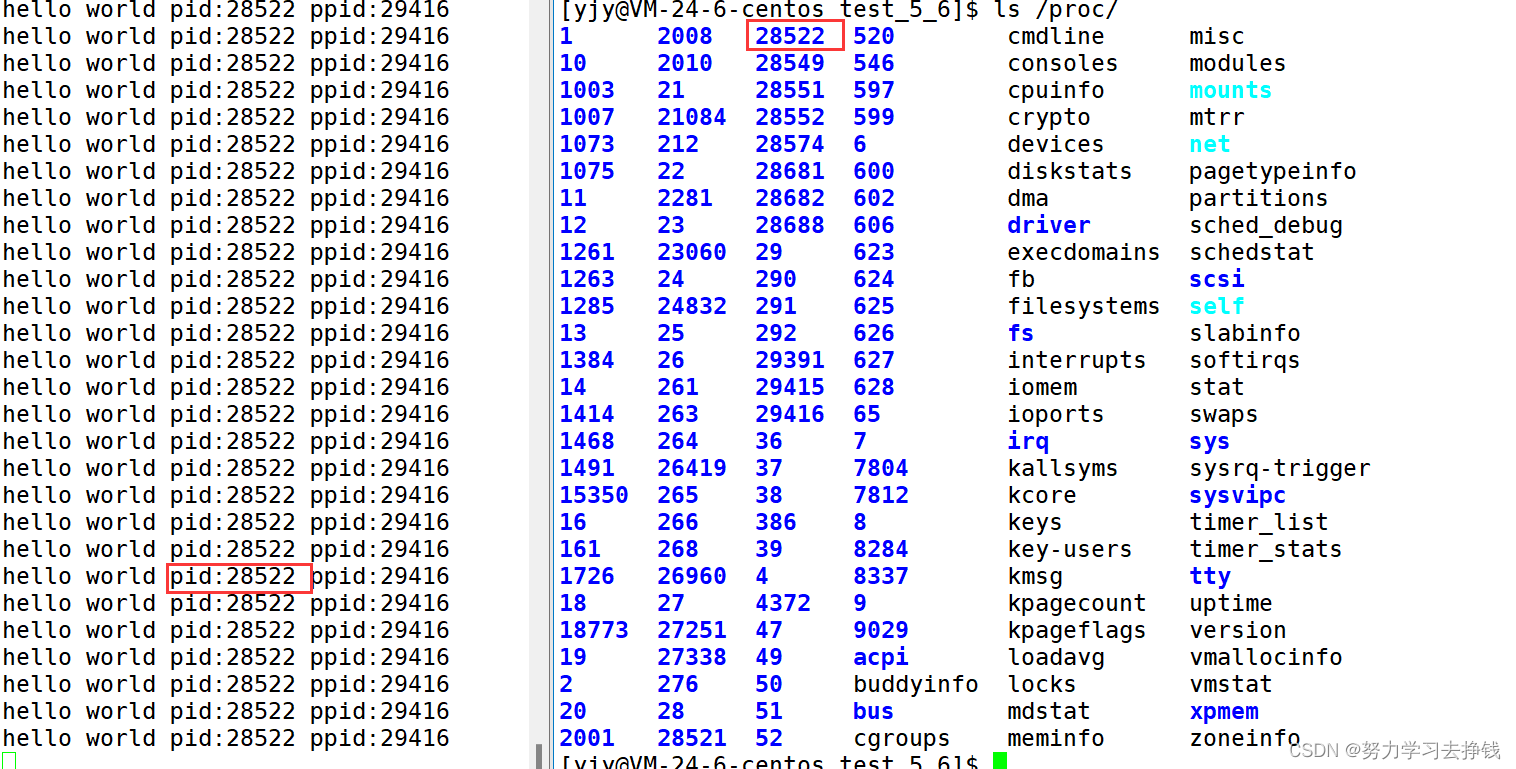 我当前运行了一个进程,不断在打印,pid为28522,/proc目录下也有以该进程PID创建的目录。
我当前运行了一个进程,不断在打印,pid为28522,/proc目录下也有以该进程PID创建的目录。 都不认识。 但要介绍两个,看的详细点:
都不认识。 但要介绍两个,看的详细点: 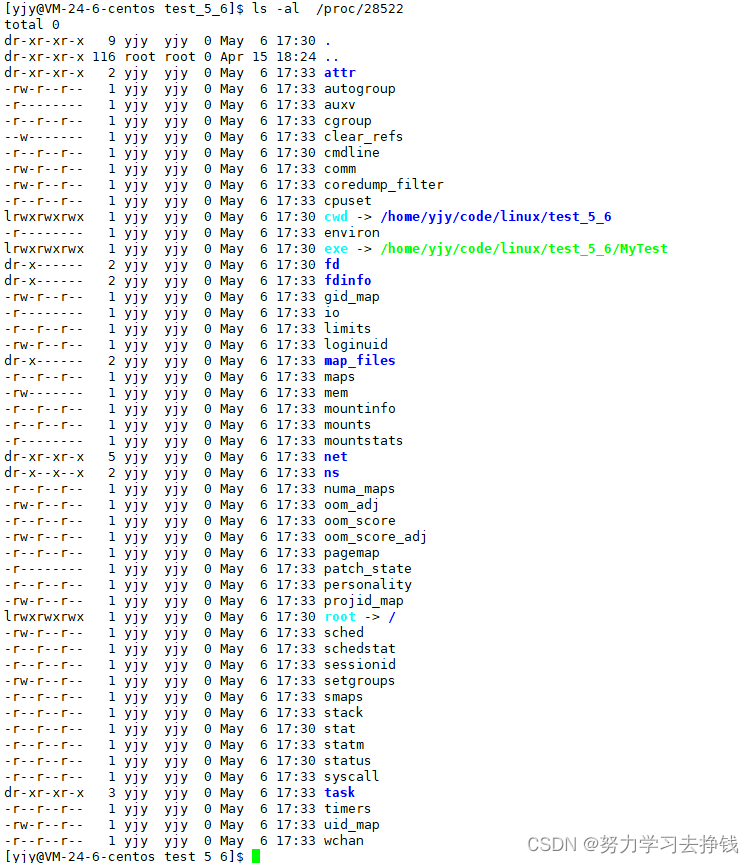 就说两个:
就说两个: 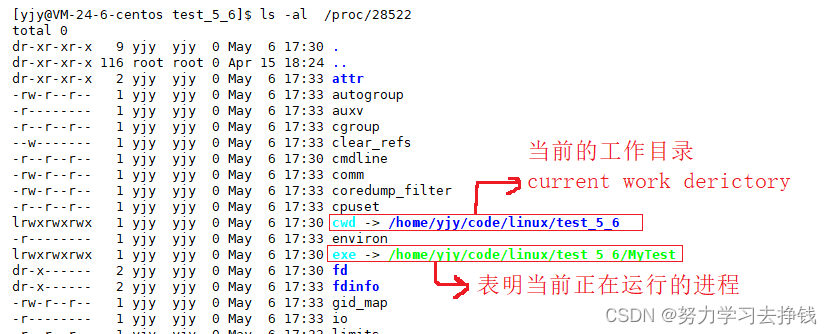 说下cwd,我们在学C语言时,文件操作fopen打开一个文件但当前工作目录不存在这个文件时,就会通过cwd在当前工作目录下创建该文件。
说下cwd,我们在学C语言时,文件操作fopen打开一个文件但当前工作目录不存在这个文件时,就会通过cwd在当前工作目录下创建该文件。 fork函数可以创建一个子进程。
fork函数可以创建一个子进程。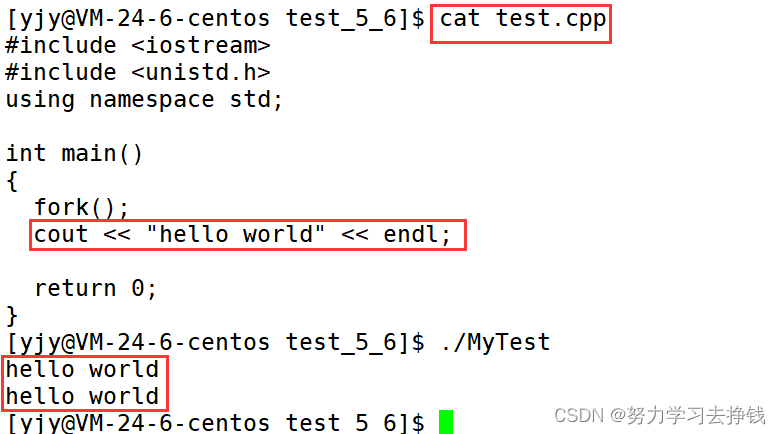 为什么打印了两次? 看:
为什么打印了两次? 看: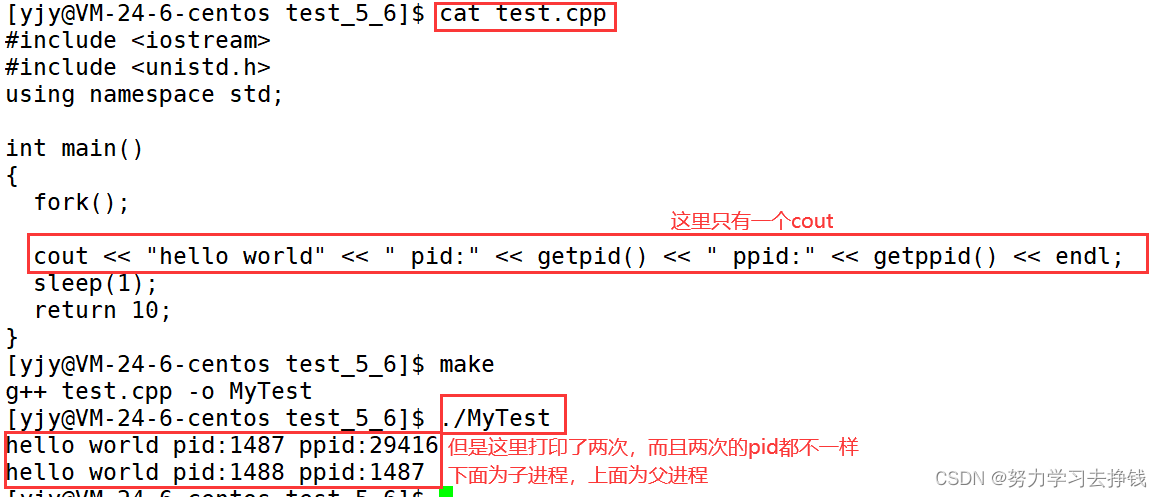
 为什么打印了两次?
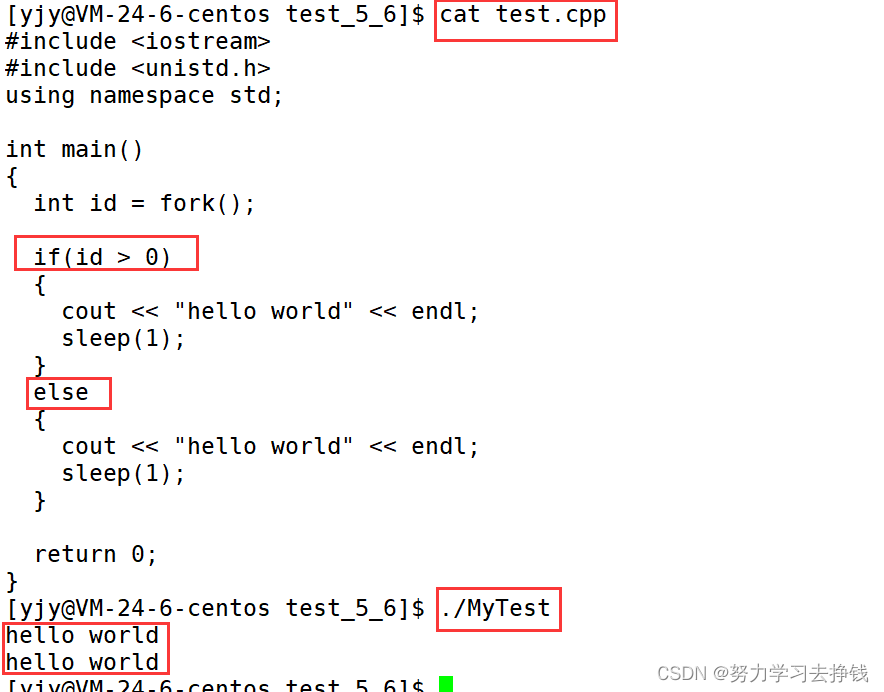
为什么打印了两次?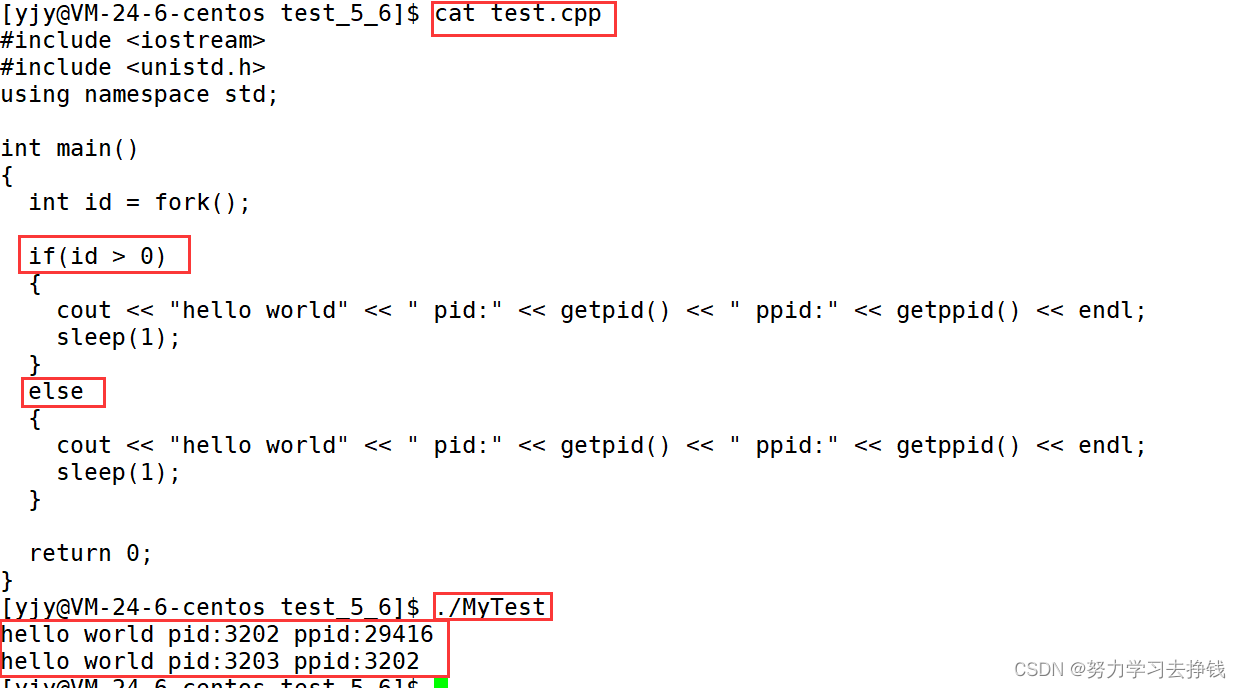
 就是这样的方式来使得父子进程实现不同功能。
就是这样的方式来使得父子进程实现不同功能。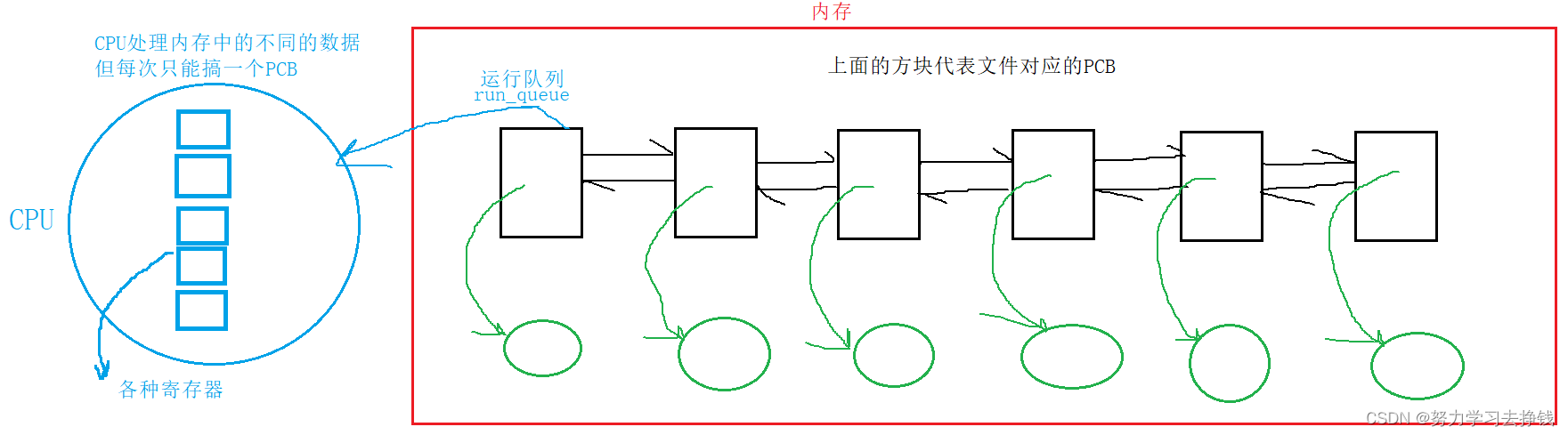 还是这张图,右面的运行队列,就是这里要讲的,现在内存中的六个进程都处于R状态,就是都被放到了运行队列中,第一个在占用CPU资源,后面的在等待CPU资源。 来个例子: 代码这样:
还是这张图,右面的运行队列,就是这里要讲的,现在内存中的六个进程都处于R状态,就是都被放到了运行队列中,第一个在占用CPU资源,后面的在等待CPU资源。 来个例子: 代码这样: 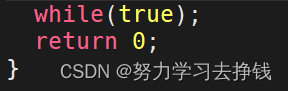 啥都不用干,光让他循环
啥都不用干,光让他循环  此时就是R状态,R后面的+等会讲。
此时就是R状态,R后面的+等会讲。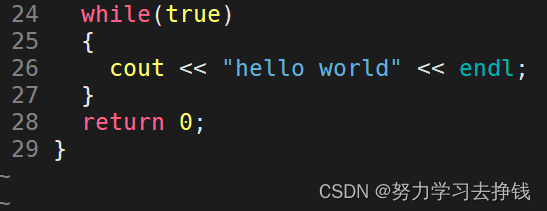
 找半天才找到了R状态,基本上都是S状态,但有的同学认为这不是在一直打印着的吗?
找半天才找到了R状态,基本上都是S状态,但有的同学认为这不是在一直打印着的吗?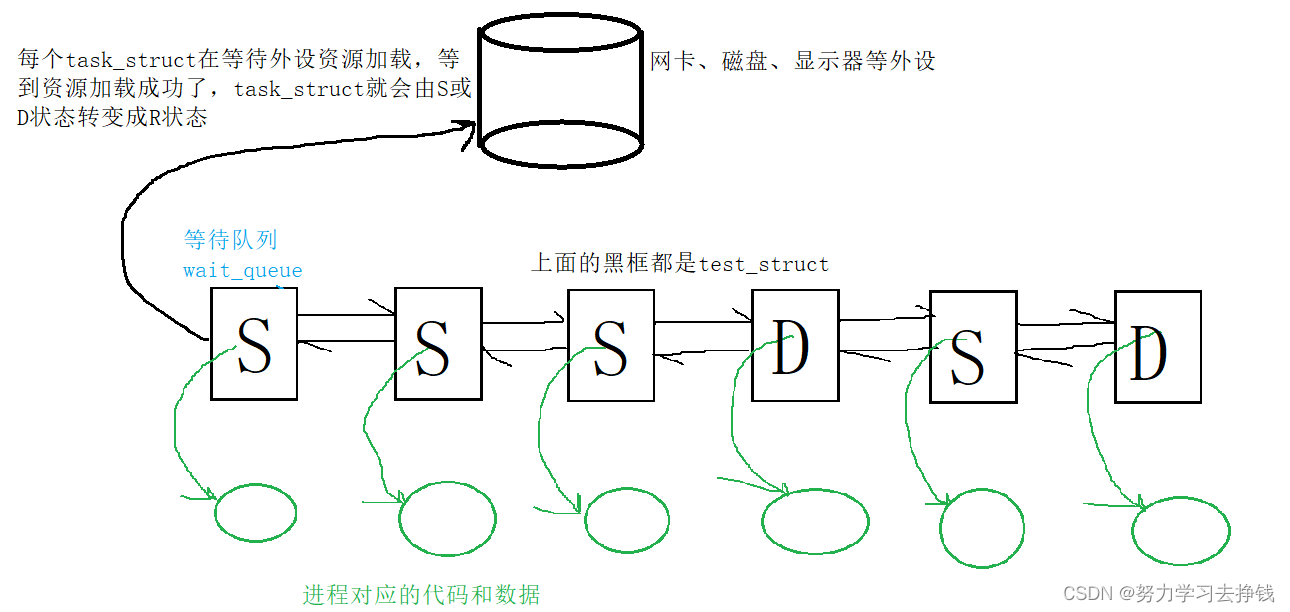
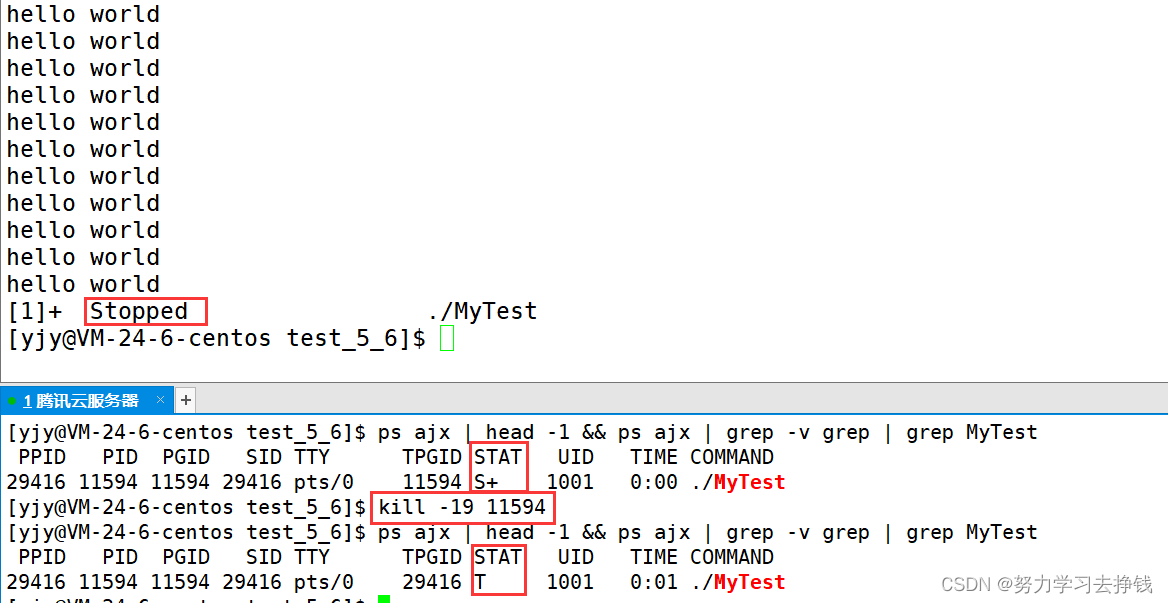 先让进程暂停。 kill -19 PID 进程就从S状态变成了T状态 然后再让进程继续运行: kill -18 PID
先让进程暂停。 kill -19 PID 进程就从S状态变成了T状态 然后再让进程继续运行: kill -18 PID 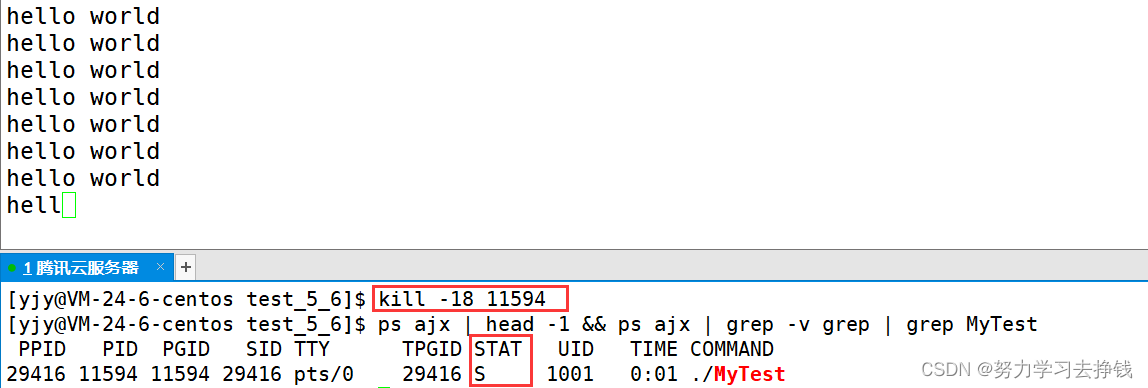 此时又从T状态变成了S状态。 但是这里的S和前面的S不太一样,这里S后面的+没了。
此时又从T状态变成了S状态。 但是这里的S和前面的S不太一样,这里S后面的+没了。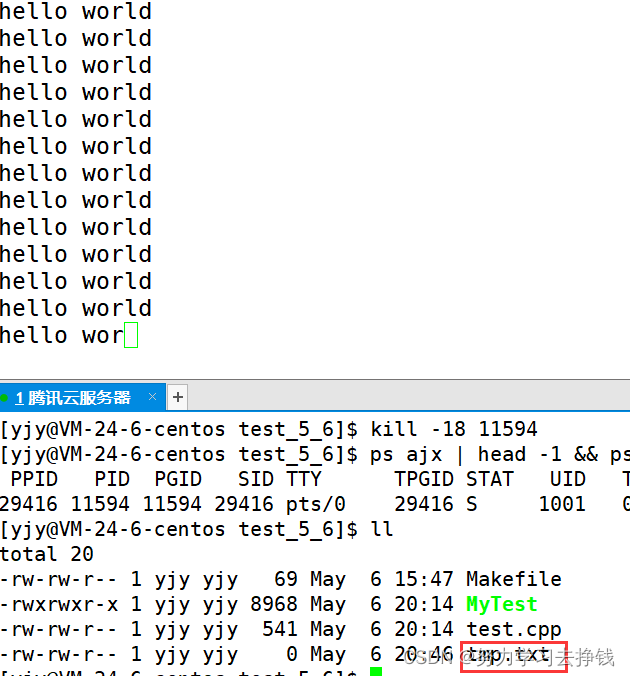 上面的进程还是在跑着的,而且我是在上面的对话框中创建的文件,而不是下面的对话框,只是刷屏了看不见命令而已。 后台跑的就是状态不带+的,前台跑的就是状态带+。
上面的进程还是在跑着的,而且我是在上面的对话框中创建的文件,而不是下面的对话框,只是刷屏了看不见命令而已。 后台跑的就是状态不带+的,前台跑的就是状态带+。
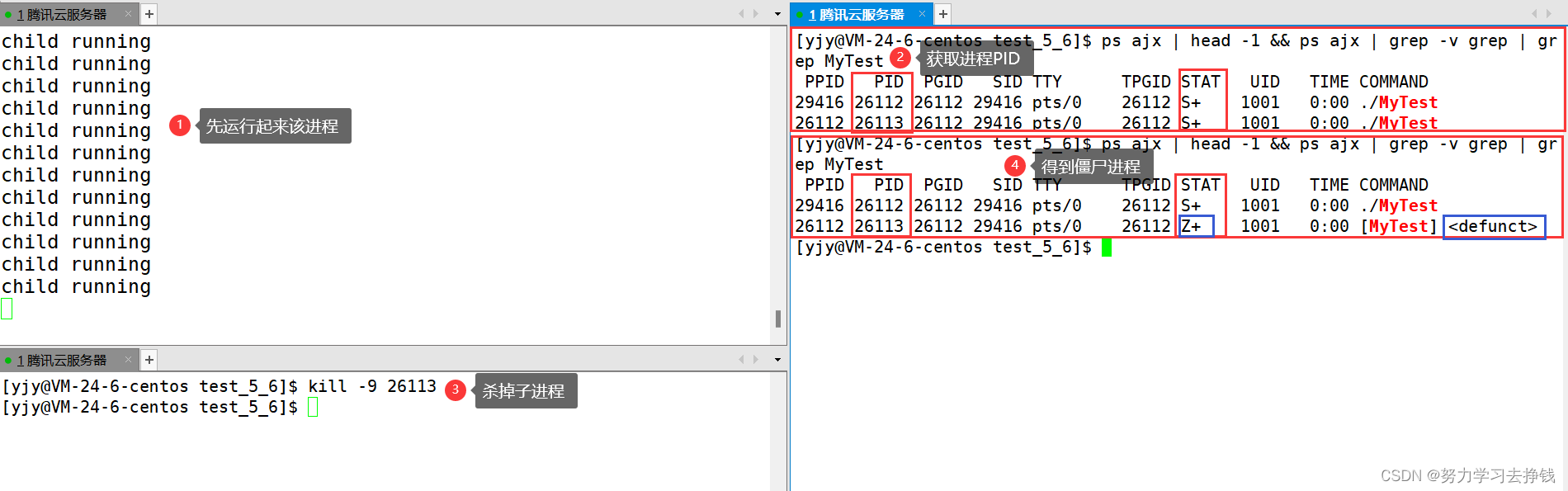
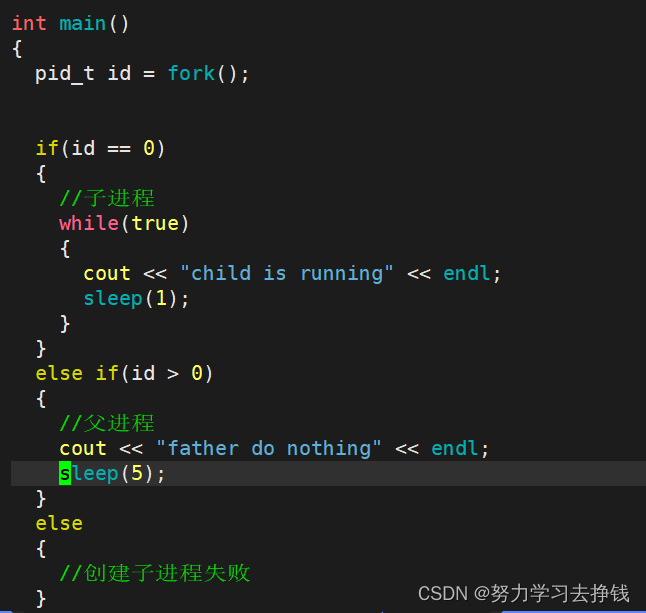 上面的代码中,跑起来的话,父进程只运行了5秒,子进程一直在运行。
上面的代码中,跑起来的话,父进程只运行了5秒,子进程一直在运行。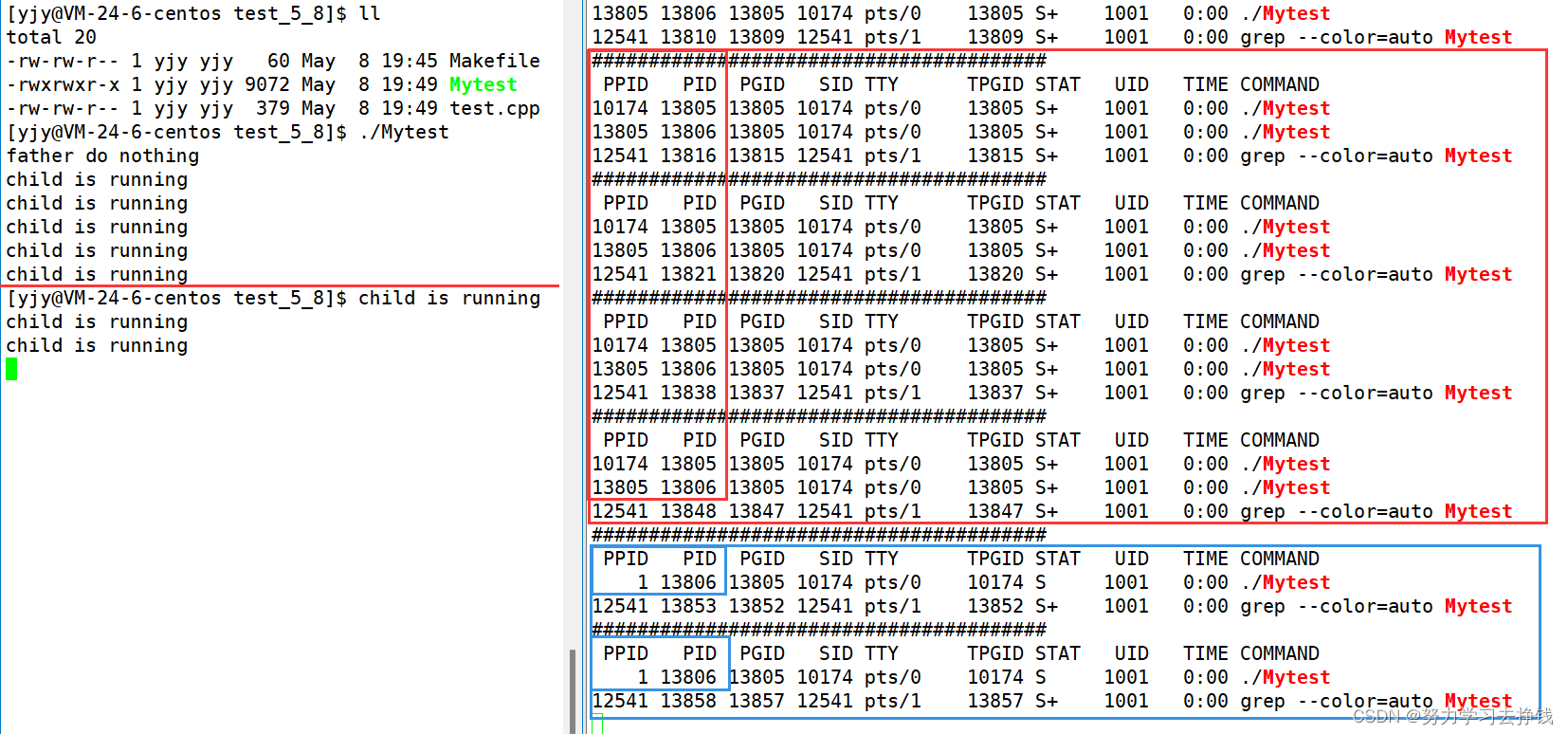 可以看到,父进程的PID为13805,右侧我红色框中圈的是父进程还没结束的时候,左侧划红线的地方就是父进程挂掉的地方。右侧蓝色框是父进程已经结束了,子进程还在跑。
可以看到,父进程的PID为13805,右侧我红色框中圈的是父进程还没结束的时候,左侧划红线的地方就是父进程挂掉的地方。右侧蓝色框是父进程已经结束了,子进程还在跑。 也就是说父进程挂掉了,子进程会被操作系统领养,那么子进程挂掉的了就由操作系统来回收。
也就是说父进程挂掉了,子进程会被操作系统领养,那么子进程挂掉的了就由操作系统来回收。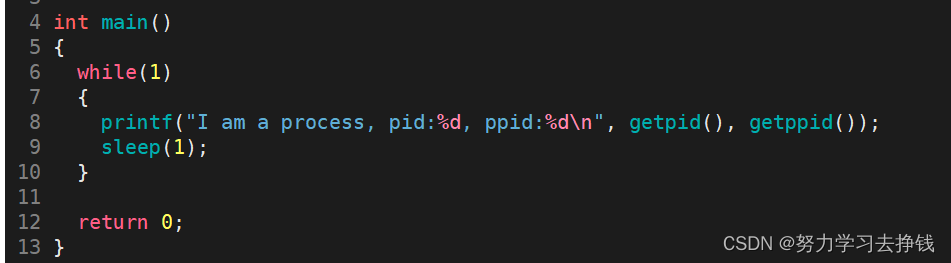
 然后就可以看到NI改为了10,PRI改为了90。
然后就可以看到NI改为了10,PRI改为了90。 发现并不是变为了95,而是在原先80的基础上变为了85。
发现并不是变为了95,而是在原先80的基础上变为了85。
 将NI改为-100:
将NI改为-100: 
 但是为什么我们写了一个可执行文件后,当该文件所在目录下执行该文件需要加上./才能执行该文件呢?或者是加上绝对路径或相对路径才能执行?
但是为什么我们写了一个可执行文件后,当该文件所在目录下执行该文件需要加上./才能执行该文件呢?或者是加上绝对路径或相对路径才能执行?
 可以看到 PATH 这个环境变量中有好几个路径。而且每个路径以 : 分隔。 还可以看到第二个路径中就有 /usr/bin 这个路径,也就是 ls 所在的路径。
可以看到 PATH 这个环境变量中有好几个路径。而且每个路径以 : 分隔。 还可以看到第二个路径中就有 /usr/bin 这个路径,也就是 ls 所在的路径。
 这时候再执行Myproc就不需要再加路径了。
这时候再执行Myproc就不需要再加路径了。  但是 ls 就不管用了。
但是 ls 就不管用了。 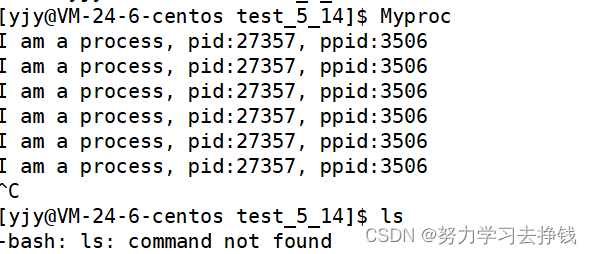 所以我们赶紧退出当前会话。
所以我们赶紧退出当前会话。
 这时候就将路径添加到PATH中了。 再执行Myproc就跟上面一样了:
这时候就将路径添加到PATH中了。 再执行Myproc就跟上面一样了:  再ls也没事:
再ls也没事: 
 跑出来一堆
跑出来一堆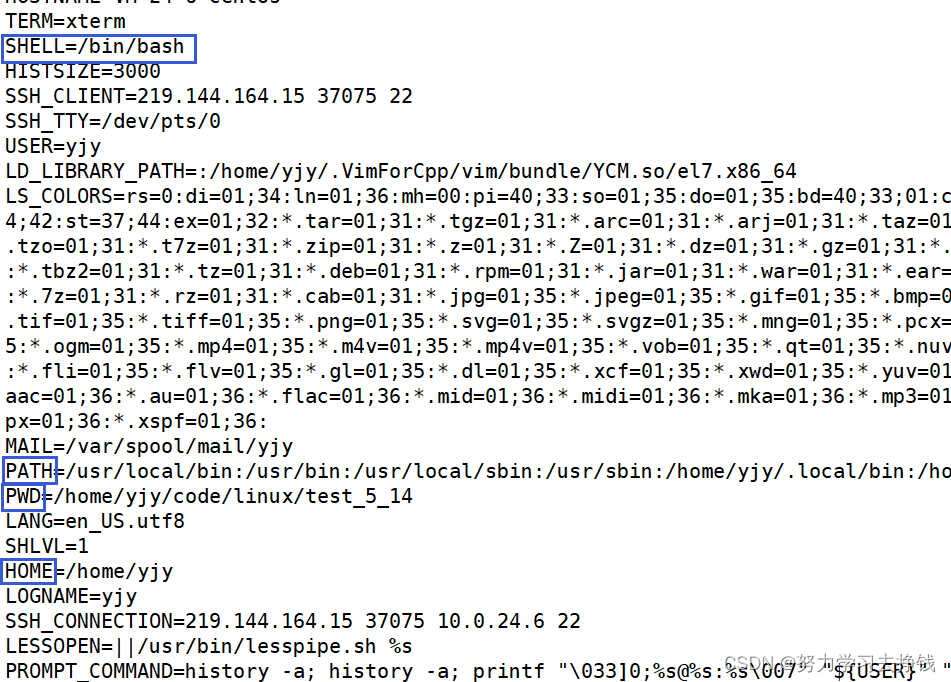
 echo $myval显示值为20 set | grep myval 显示 myval=20 但是这个只是在本地定义的,不在环境变量中。
echo $myval显示值为20 set | grep myval 显示 myval=20 但是这个只是在本地定义的,不在环境变量中。  但是可以导成环境变量:export 变量名
但是可以导成环境变量:export 变量名  再在环境变量中查找就找到了。
再在环境变量中查找就找到了。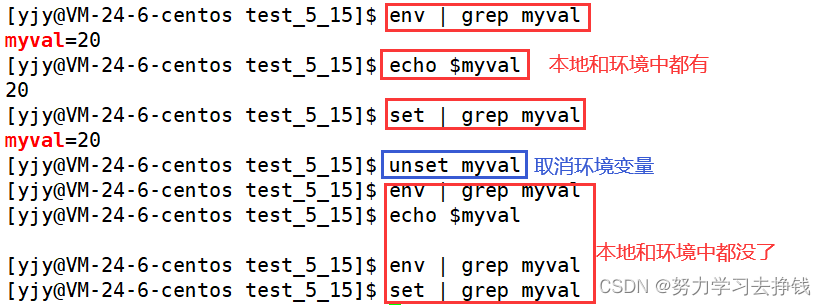
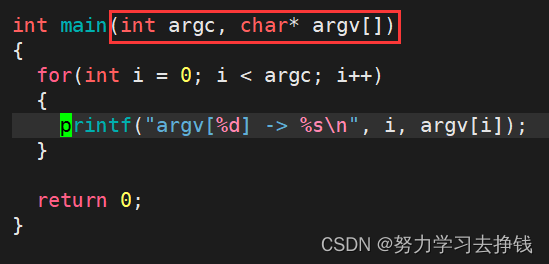 上面的argc代表一条有效命令中以空格分隔的字符串有几个。 指针学的比较扎实的同学应该能看出来argv代表的是指针数组,里面的每个元素就是命令中从左往右挨个的被分割开的字符串。
上面的argc代表一条有效命令中以空格分隔的字符串有几个。 指针学的比较扎实的同学应该能看出来argv代表的是指针数组,里面的每个元素就是命令中从左往右挨个的被分割开的字符串。 下面的那个是我有添加了几个字符串,是不是很类似于我们之前一些系统命令的格式? 我再画一下第二个例子的图解:
下面的那个是我有添加了几个字符串,是不是很类似于我们之前一些系统命令的格式? 我再画一下第二个例子的图解: 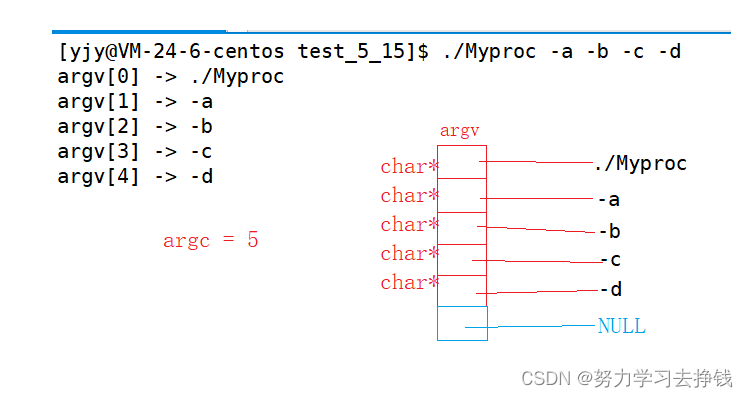
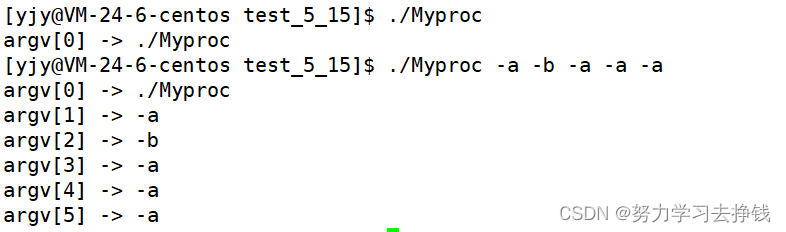 跑起来一样的功能。
跑起来一样的功能。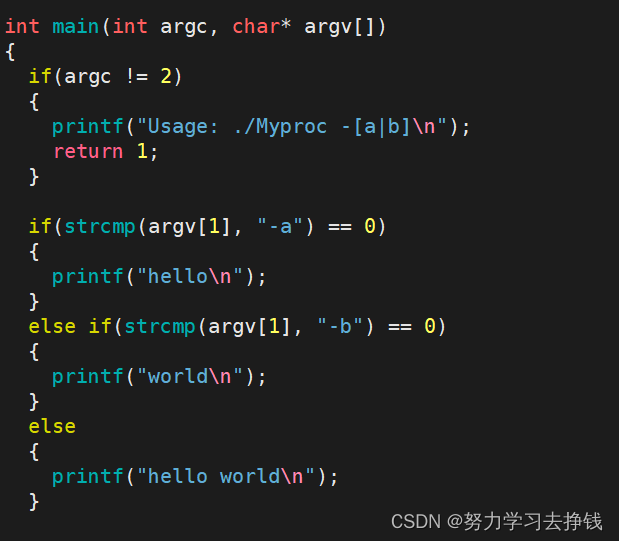
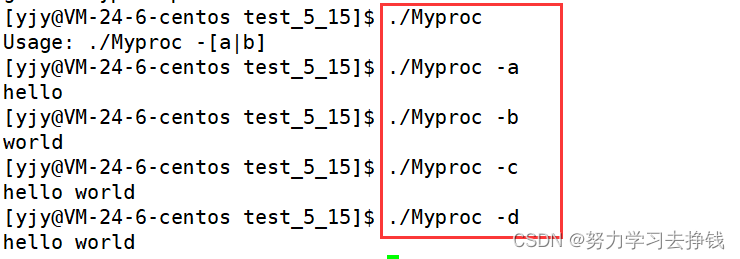 这一点就可以看到:指令有很多选项,用来完成同一个命令的不同子功能选项底层使用的就是我们的命令行参数。
这一点就可以看到:指令有很多选项,用来完成同一个命令的不同子功能选项底层使用的就是我们的命令行参数。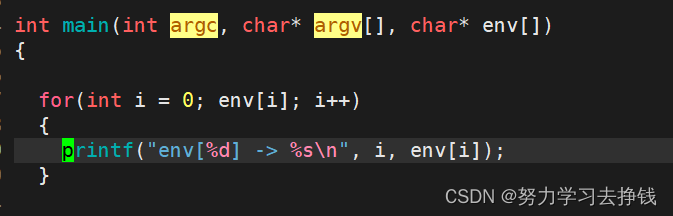
 其中env数组元素的个数是不能够确定的。由父进程来决定。 env跟argv很像,只不过存放的不一样。env放的是环境变量,argv存放的是命令中以空格间隔的各个字符串。两个数组最后都有一个指针来指向NULL。
其中env数组元素的个数是不能够确定的。由父进程来决定。 env跟argv很像,只不过存放的不一样。env放的是环境变量,argv存放的是命令中以空格间隔的各个字符串。两个数组最后都有一个指针来指向NULL。
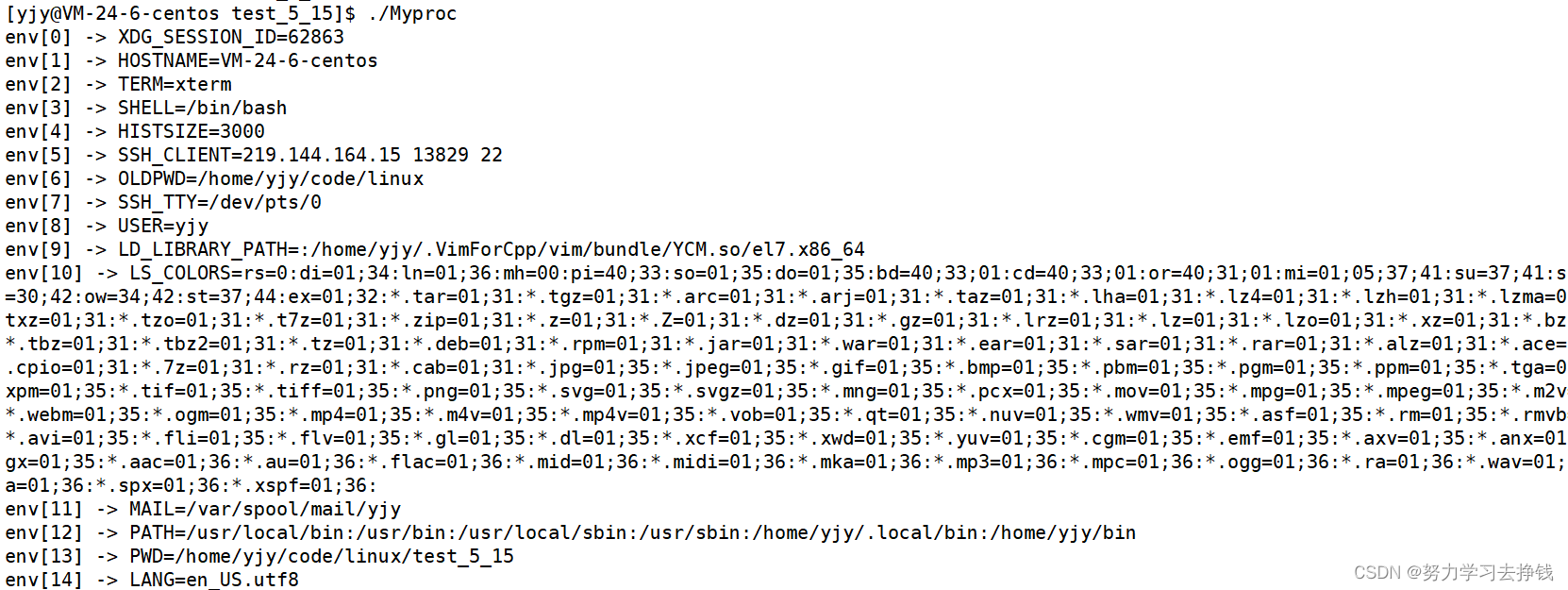
 结果是这样的:
结果是这样的: 
 然后问题来了,其实也不是问题,我在前面的博客中也讲过了。为什么每次运行这个文件,pid都会改变,但ppid不变? 因为所有在命令行上执行的命令,父进程基本都是bash,所以ppid不变。但每次执行进程,进程都是在不断被创建的,每次都是一次新的开始。
然后问题来了,其实也不是问题,我在前面的博客中也讲过了。为什么每次运行这个文件,pid都会改变,但ppid不变? 因为所有在命令行上执行的命令,父进程基本都是bash,所以ppid不变。但每次执行进程,进程都是在不断被创建的,每次都是一次新的开始。 也就是可以说bash继承了操作系统的环境变量,再由命令行创建子进程,就可以将环境变量不断的延续下去,影响了整个“用户”系统,这就导致了全局属性。
也就是可以说bash继承了操作系统的环境变量,再由命令行创建子进程,就可以将环境变量不断的延续下去,影响了整个“用户”系统,这就导致了全局属性。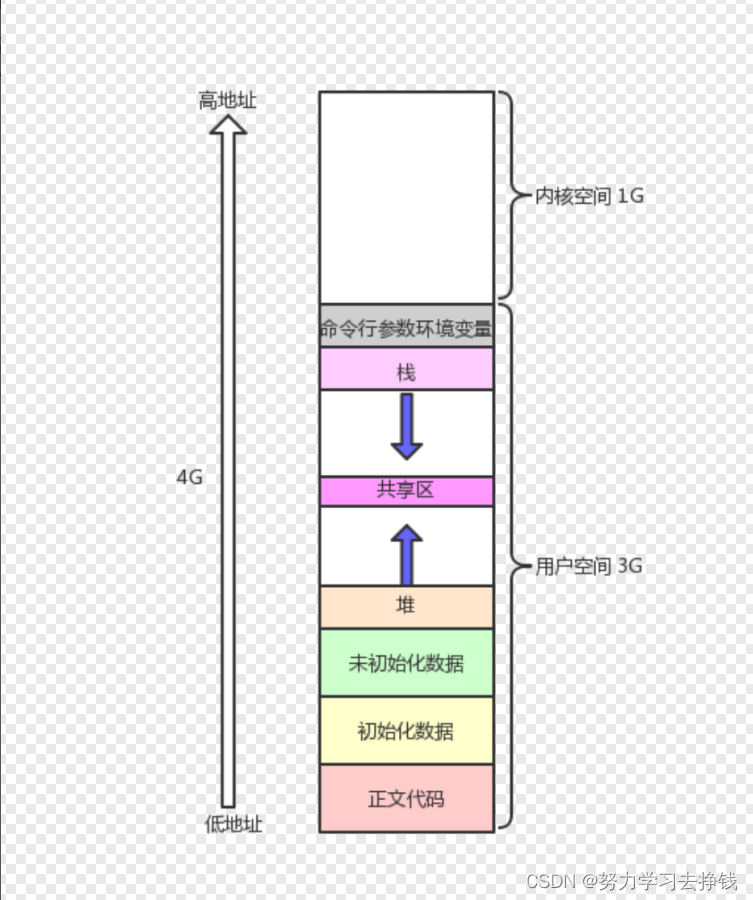
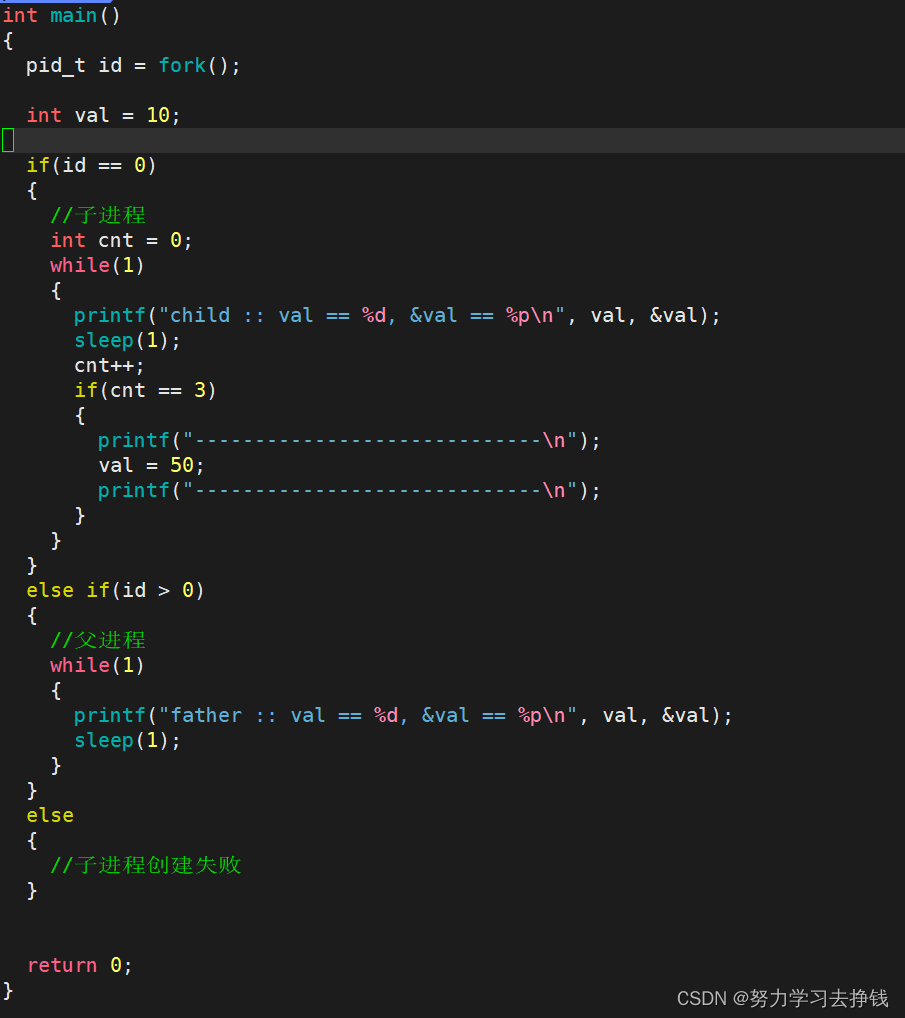
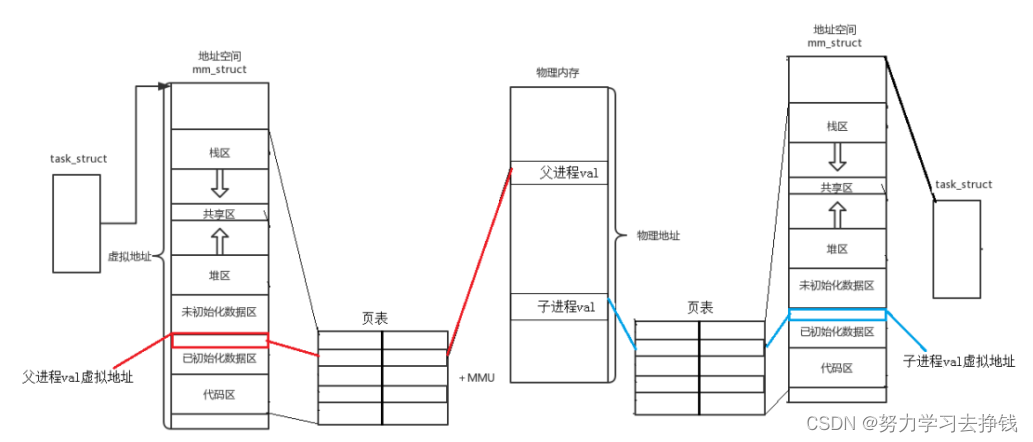
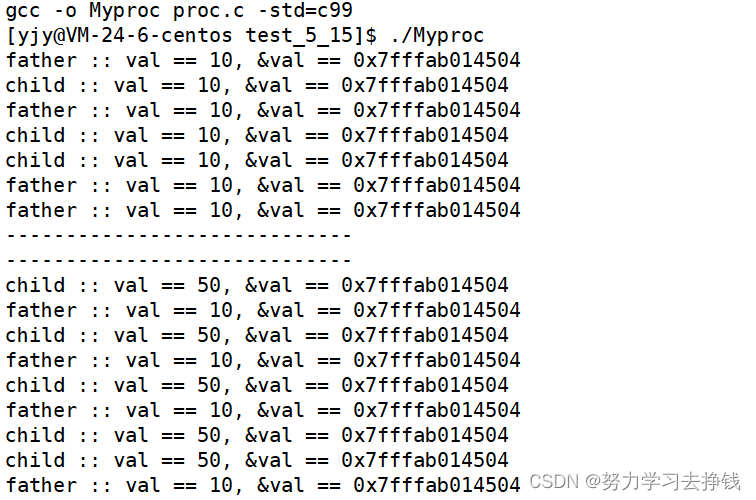 各位仔细看,父和子的val的地址是一样的。 但是睁大眼睛:当子将val改变的时候,父中的val没有改变,但是二者的地址还是一样的。
各位仔细看,父和子的val的地址是一样的。 但是睁大眼睛:当子将val改变的时候,父中的val没有改变,但是二者的地址还是一样的。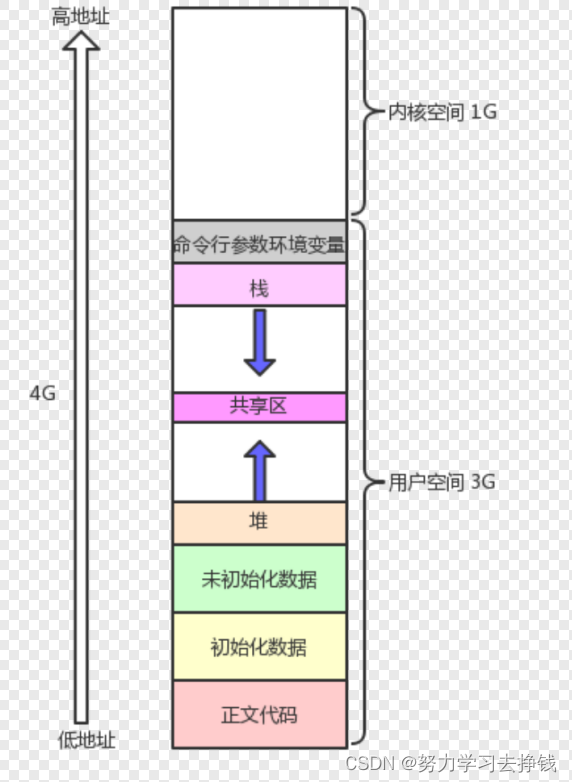 其实最下面不太准确,正文代码应该分成代码区和字符常量区。 我来写一份代码演示一下上图中的地址分布: 下面的代码需要各位C语言功底比较扎实,我这里就认为大家能看懂了。
其实最下面不太准确,正文代码应该分成代码区和字符常量区。 我来写一份代码演示一下上图中的地址分布: 下面的代码需要各位C语言功底比较扎实,我这里就认为大家能看懂了。 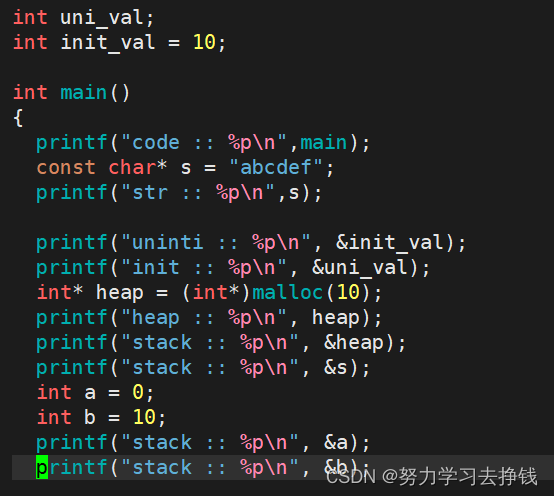
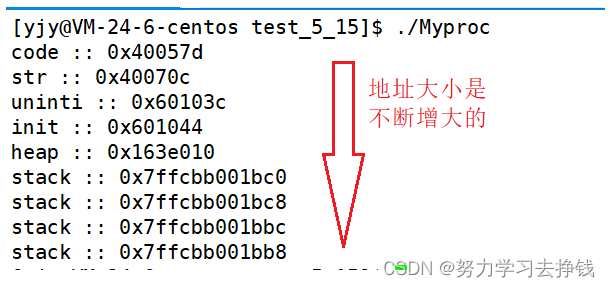 那么这些地址不是实际内存地址的话,这些地址都代表的是什么呢?
那么这些地址不是实际内存地址的话,这些地址都代表的是什么呢? 也就是说,每个进程对认为自己是有内存四区的。我们前面讲到了task_struct这个结构体,其中也是有一个指针指向进程的虚拟地址的。 像这样:
也就是说,每个进程对认为自己是有内存四区的。我们前面讲到了task_struct这个结构体,其中也是有一个指针指向进程的虚拟地址的。 像这样: 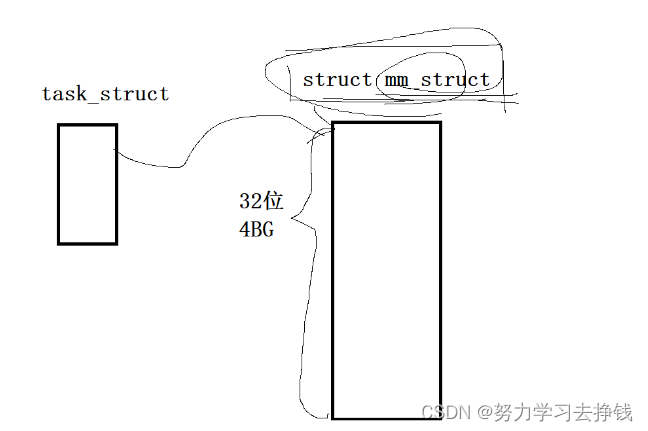
【本文地址】