| 【NLP】使用混合精度技术加速大型语言模型 | 您所在的位置:网站首页 › stm32双精度浮点数速度 › 【NLP】使用混合精度技术加速大型语言模型 |
【NLP】使用混合精度技术加速大型语言模型
|
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎 📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃 🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝 📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
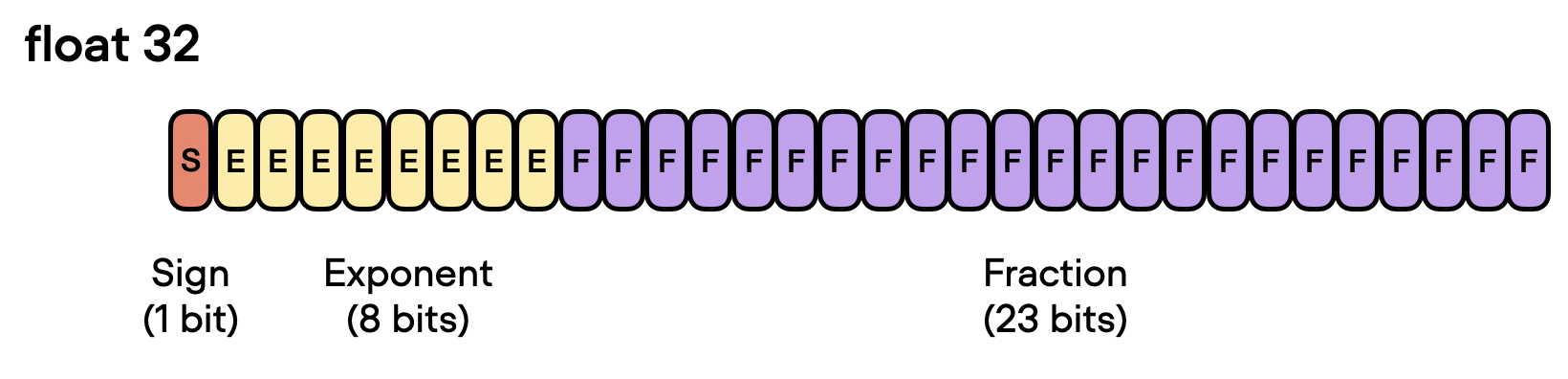
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。 如果你对这个系列感兴趣的话,可以关注订阅哟👋 文章目录 了解混合精度训练 使用 32 位精度 从 32 位精度到 16 位精度 混合精度训练机制 混合精度代码示例 微调基准 张量核和矩阵乘法精度 Brain浮点数 高效的低精度推理和 LLaMA 量化 结论 由于大型语言模型 (LLM) 的计算要求和内存占用量大,因此训练和使用它们的成本很高。本文将探讨如何利用低精度格式将训练和推理速度提高 3 倍,同时不影响模型精度。 尽管我们主要关注大型语言模型示例,但这些技术中的大多数都是通用的,也适用于其他深度学习架构。 了解混合精度训练混合精度训练是使我们能够显着提高现代 GPU 训练速度的基本技术之一。有时,这会带来 2 到 3 倍的加速!让我们看看这是如何工作的。 使用 32 位精度在 GPU 上训练深度神经网络时,我们通常使用低于最大精度的精度,即 32 位浮点运算(事实上,PyTorch 默认使用 32 位浮点数)。 相反,在传统的科学计算中,我们通常使用 64 位浮点数。通常,更多的位数对应于更高的精度,这降低了计算过程中错误累积的机会。因此,64 位浮点数(也称为双精度)长期以来一直是科学计算的标准,因为它们能够以更高的精度表示范围广泛的数字。 然而,在深度学习中,使用 64 位浮点运算被认为是不必要的并且计算量大,因为 64 位运算通常成本更高,而且 GPU 硬件也没有针对 64 位精度进行优化。因此,32 位浮点运算(也称为单精度)已成为在 GPU 上训练深度神经网络的标准。 在浮点数的上下文中,“位”是指用于表示计算机内存中数字的二进制数字。用于表示数字的位数越多,精度越高,可以表示的数值范围也越大。在浮点表示法中,数字存储在三部分的组合中:符号、指数和有效数字(或尾数)。
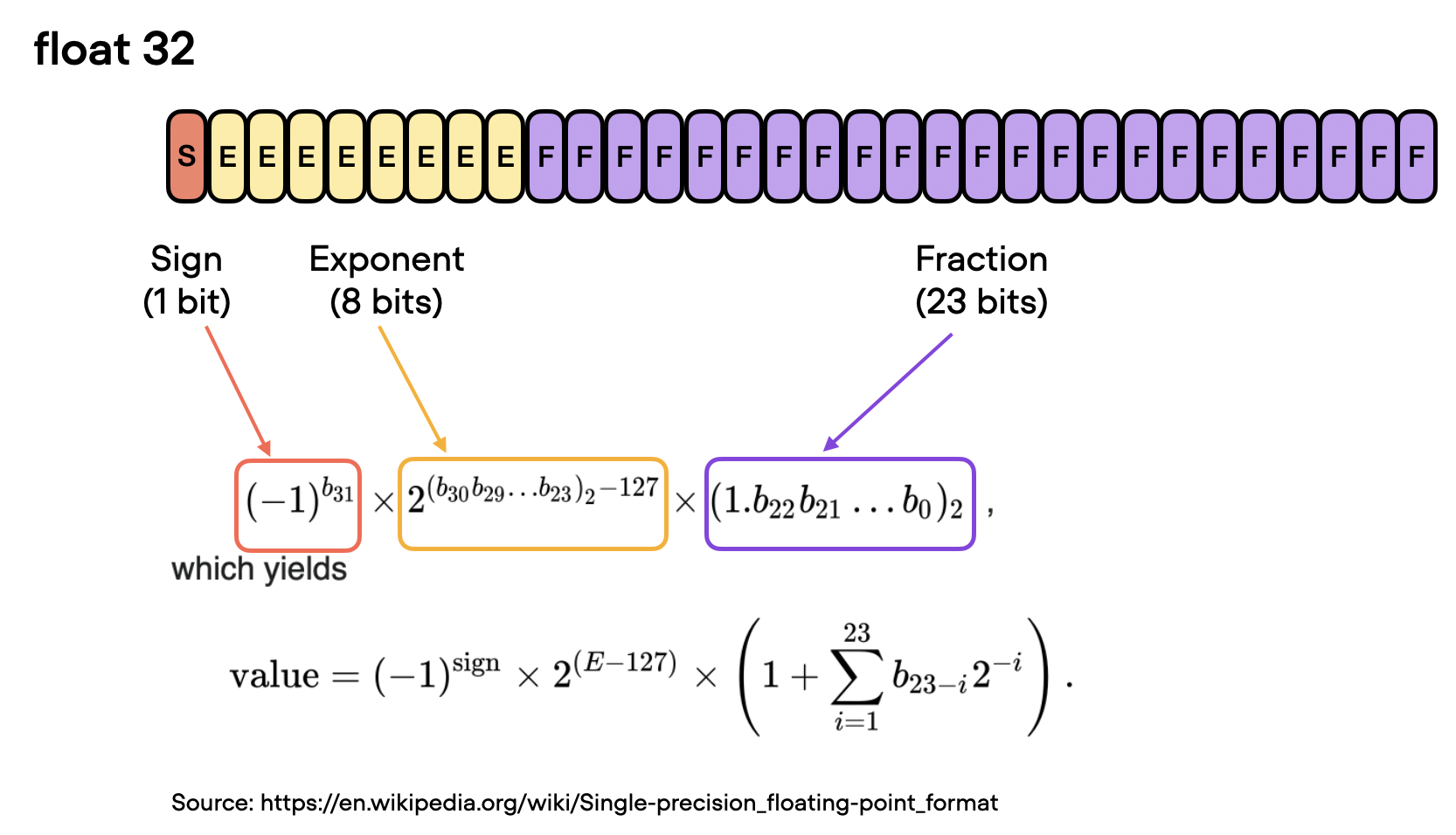
在浮点数中,值表示为尾数、底数的指数和符号的乘积。有效数字与小数点后的数字相关但不等同。如果您对确切的公式感兴趣(如下图所示)。但是,为方便起见,我们可以将有效数字视为“分数”或“分数值”。
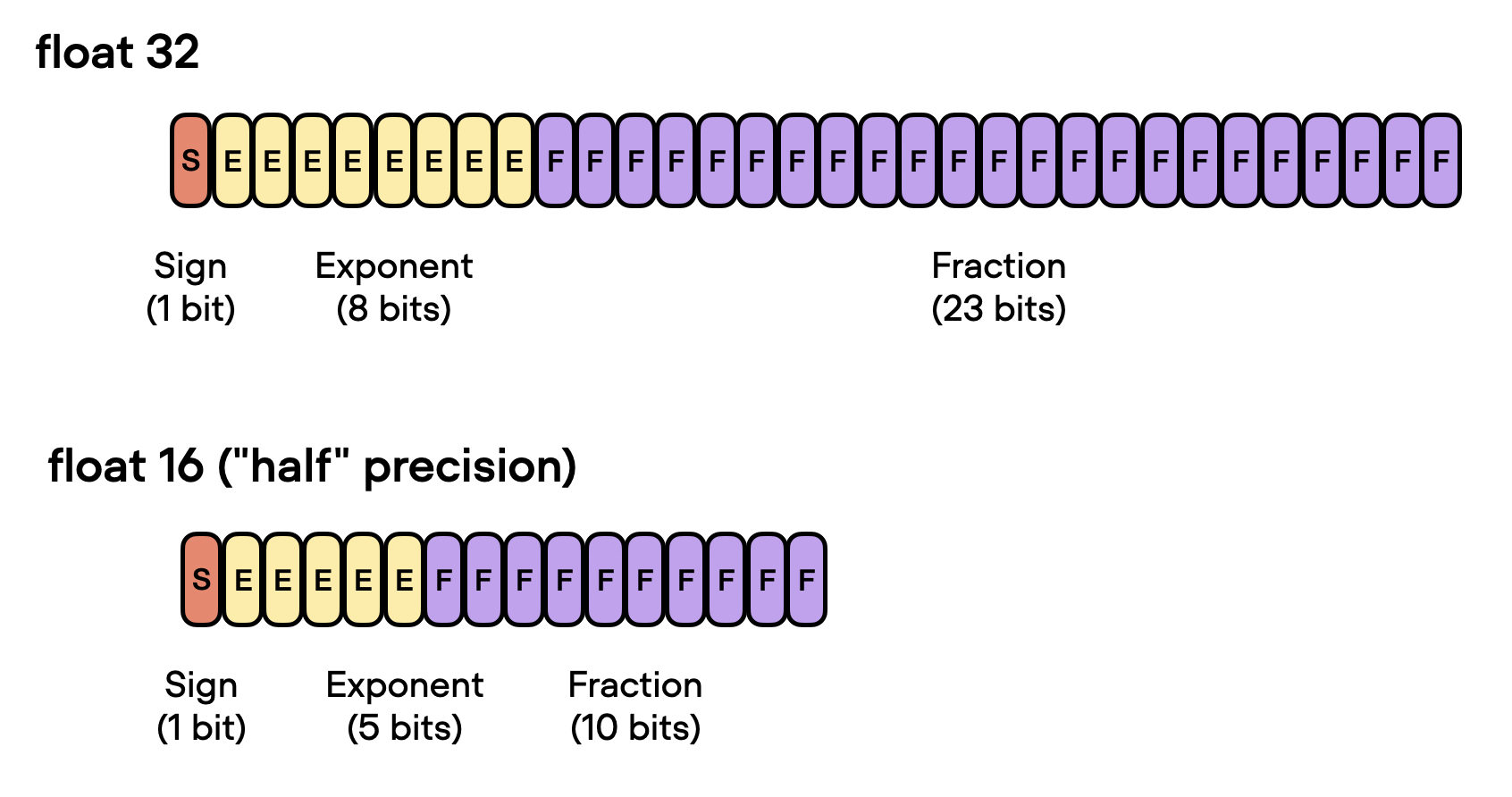
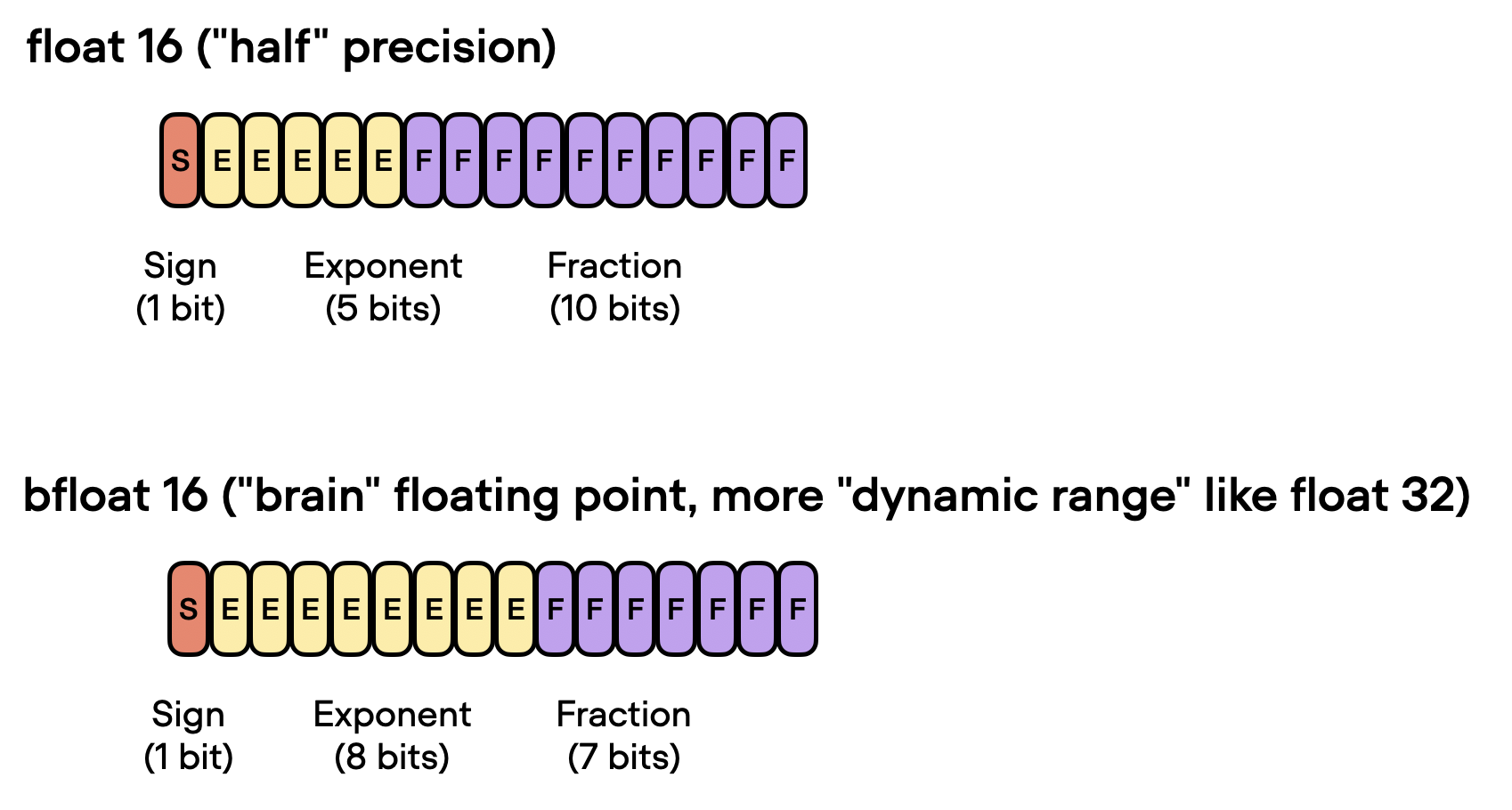
因此,回到使用较低精度背后的动机,在 GPU 上训练深度神经网络时,32 位浮点运算优于 64 位运算的主要原因主要有两个: 减少内存占用。使用 32 位浮点数的主要优点之一是与 64 位浮点数相比,它们需要的内存减少一半。这允许更有效地使用 GPU 内存,从而能够训练更大的模型(和更大的批量大小)。增加计算和速度。由于 32 位浮点运算需要更少的内存,因此 GPU 可以更快地处理它们,从而缩短训练时间。这种加速在深度学习中至关重要,因为在深度学习中训练复杂的模型可能需要几天甚至几周的时间。 从 32 位精度到 16 位精度既然讨论了 32 位浮点数的好处,我们还能更进一步吗?我们可以!最近,混合精度训练成为一种常见的训练方案,我们暂时使用 16 位精度进行浮点计算,通常称为“半”精度。
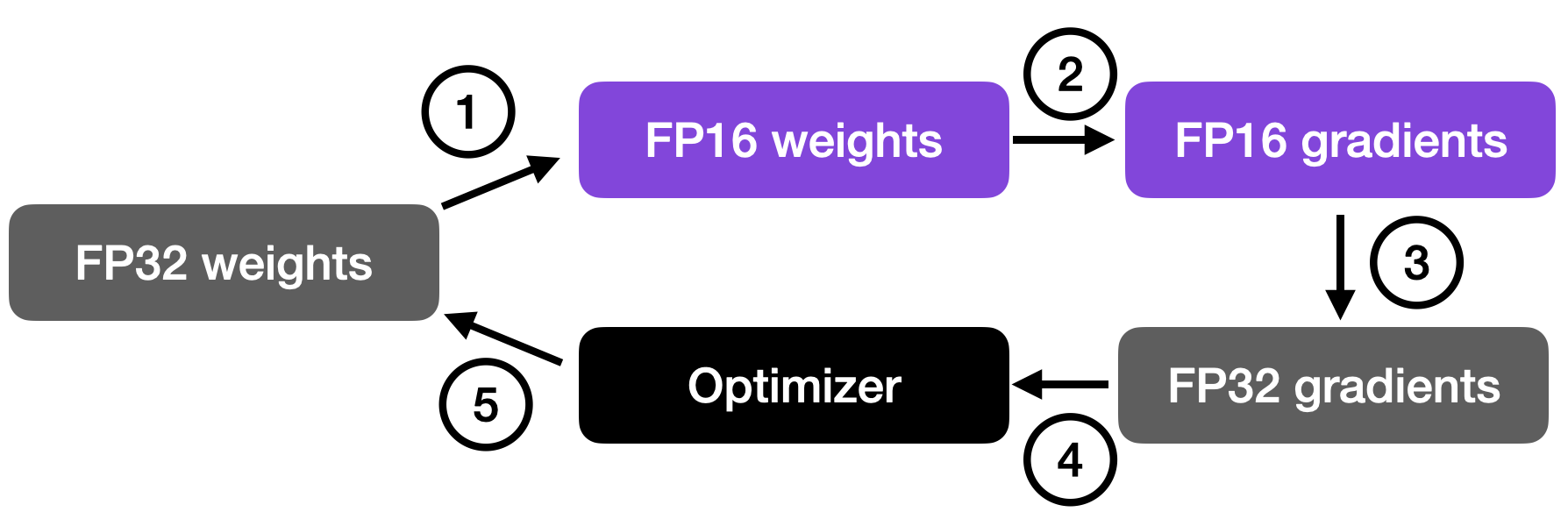
如上图所示,float16 的指数少了 3 位,小数值少了 13 位。 但在讨论混合精度训练背后的机制之前,让我们让不同位精度级别之间的差异更加直观和切实。考虑 PyTorch 中的以下代码示例: import torch torch.set_printoptions(precision=60) print(torch.tensor(1/7, dtype=torch.float64))tensor(0.142857142857142849212692681248881854116916656494140625000000, dtype=torch.float64) print(torch.tensor(1/7, dtype=torch.float32))tensor(0.142857149243354797363281250000000000000000000000000000000000) print(torch.tensor(1/7, dtype=torch.float16))tensor(0.142822265625000000000000000000000000000000000000000000000000, dtype=torch.float16) 上面的代码示例表明精度越低,我们在小数点后看到的准确数字就越少。 深度学习模型通常对较低精度的算法具有鲁棒性。在大多数情况下,使用 32 位浮点数而不是 64 位浮点数导致的精度略有下降不会显着影响模型的预测性能,因此值得进行权衡。然而,当我们降低到 16 位精度时,事情会变得棘手。您可能会注意到,由于不精确、数值溢出或下溢,损失可能变得不稳定或不收敛。 上溢和下溢是指某些数字超出精度格式可以处理的范围的问题,例如,如下所示: print(torch.tensor(10**7, dtype=torch.float32))tensor(10000000.) print(torch.tensor(10**7, dtype=torch.float16))tensor(inf, dtype=torch.float16) 顺便说一句,虽然上面的代码片段显示了一些关于不同精度类型的实际示例,但您也可以通过[torch.finfo]()如下所示直接访问数值属性: print(torch.finfo(torch.float32))finfo(resolution=1e-06, min=-3.40282e+38, max=3.40282e+38, eps=1.19209e-07, smallest_normal=1.17549e-38, tiny=1.17549e-38, dtype=float32) torch.finfo(torch.float16)finfo(resolution=0.001, min=-65504, max=65504, eps=0.000976562, smallest_normal=6.10352e-05, tiny=6.10352e-05, dtype=float16) 上面的代码显示最大的 float32 数字是 340,282,000,000,000,000,000,000,000,000,000,000,000(通过max);例如,float16 数字不能超过值 65,504。 因此,在本节中,我们鼓励在现代深度学习中使用“混合精度”训练而不是 16 位精度训练。但是这种混合精度训练是如何工作的呢?为什么它被称为“混合”精度训练而不只是 16 位精度训练?让我们在下面的部分中回答这些问题。 混合精度训练机制它被称为“混合”而不是“低”精度训练,因为我们没有将所有参数和操作都转换为 16 位浮点数。相反,我们在训练期间在 32 位和 16 位操作之间切换,因此称为“混合”精度。 如下图所示,混合精度训练涉及将权重转换为低精度(FP16)以加快计算速度,计算梯度,将梯度转换回高精度(FP32)以实现数值稳定性,并使用缩放后的原始权重进行更新梯度。
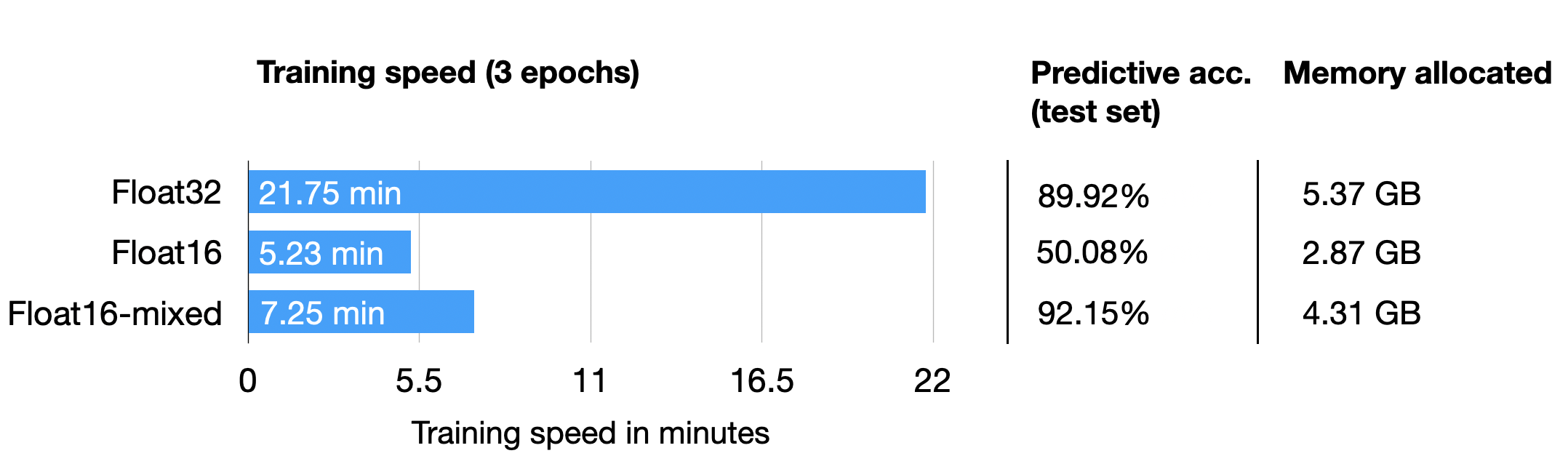
这种方法允许进行有效的训练,同时保持神经网络的准确性和稳定性。 更详细地,步骤如下。 将权重转换为 FP16:在此步骤中,神经网络的权重(或参数)最初为 FP32 格式,将转换为精度较低的 FP16 格式。这减少了内存占用并允许更快的计算,因为 FP16 操作需要更少的内存并且可以由硬件更快地处理。计算梯度:神经网络的前向和后向传递使用较低精度的 FP16 权重执行。这一步计算损失函数相对于网络权重的梯度(偏导数),用于在优化过程中更新权重。将梯度转换为 FP32:计算 FP16 中的梯度后,它们将转换回更高精度的 FP32 格式。这种转换对于保持数值稳定性和避免使用低精度算法时可能发生的梯度消失或爆炸等问题至关重要。乘以学习率并更新权重:现在在 FP32 格式中,梯度乘以学习率(在优化过程中确定步长的标量值)。然后使用第 4 步的产品更新原始 FP32 神经网络权重。学习率有助于控制优化过程的收敛,对于实现良好的性能至关重要。上面的过程听起来很复杂,但实际上,实现起来非常简单。在下一节中,我们将看到如何通过仅更改一行代码来使用混合精度训练来微调 LLM。 混合精度代码示例使用 PyTorch 的autocast上下文管理器,幸运的是混合精度训练不是很复杂。此外,借助 PyTorch 的开源Fabric库,可以更轻松地在常规训练和混合精度训练之间切换,并且只需要更改一行代码。(由于没有人工干预或修改训练代码,这通常也被称为自动混合精度训练。) 因此,首先,我们将研究一个编码器-LLM,我们根据运行时间、预测准确性和内存要求为监督分类任务(此处:用于对电影评论的情绪进行分类的 DistilBERT)进行微调。特别是,我们将微调变压器的所有层。 稍后,我们还将看到不同精度级别的选择如何影响像 LLaMA 这样的大型语言模型。 微调基准让我们从以 float32 位精度以常规方式微调 DistilBERT 模型的代码开始,这是 PyTorch 中的默认设置: from datasets import load_dataset from lightning import Fabric import torch from torch.utils.data import DataLoader import torchmetrics from transformers import AutoTokenizer from transformers import AutoModelForSequenceClassification ########################## ### 1 加载数据集 ########################## # ... omitted for brevity ######################################### ### 2 数据转换为tokenizer ######################################### # ... omitted for brevity ######################################### ### 3 设置dataloader ######################################### # ... omitted for brevity ######################################### ### 4 初始化模型 ######################################### fabric = Fabric(accelerator="cuda", devices=1) fabric.launch() model = AutoModelForSequenceClassification.from_pretrained( "distilbert-base-uncased", num_labels=2) optimizer = torch.optim.Adam(model.parameters(), lr=5e-5) model, optimizer = fabric.setup(model, optimizer) train_loader, val_loader, test_loader = fabric.setup_dataloaders( train_loader, val_loader, test_loader) ######################################### ### 5 微调 ######################################### start = time.time() train( num_epochs=3, model=model, optimizer=optimizer, train_loader=train_loader, val_loader=val_loader, fabric=fabric ) ######################################### ### 6 验证 ######################################### # ... omitted for brevity print(f"Time elapsed {elapsed/60:.2f} min") print(f"Memory used: {torch.cuda.max_memory_reserved() / 1e9:.02f} GB") print(f"Test accuracy {test_acc.compute()*100:.2f}%")上面的代码被简化以节省空间,但您可以在 GitHub 上访问完整的代码示例。 在单个 A100 GPU 上训练的结果如下: Python implementation: CPython Python version : 3.9.16 torch : 2.0.0 lightning : 2.0.2 transformers: 4.28.1 Torch CUDA available? True ... Train acc.: 97.28% | Val acc.: 89.88% Time elapsed 21.75 min Memory used: 5.37 GB Test accuracy 89.92%现在,将其与 float16 混合精度训练进行比较,我们只需更改一行代码,从 fabric = Fabric(accelerator="cuda", devices=1)到 fabric = Fabric(accelerator="cuda", devices=1, precision="16-mixed")结果如下: Train acc.: 97.39% | Val acc.: 92.21% Time elapsed 7.25 min Memory used: 4.31 GB Test accuracy 92.15%在上面,我们可以看到所需的内存减少了,这可能是因为以 16 位精度执行矩阵乘法。此外,训练速度提高了大约 3 倍,这是巨大的。 一个有趣的、意想不到的观察结果是预测准确度也提高了。一个可能的解释是,这是由于使用较低精度的正则化效果。较低的精度可能会在训练过程中引入一定程度的噪声,这可以帮助模型更好地泛化并减少过度拟合,从而可能导致验证集和测试集的准确性更高。 出于好奇,我们还将通过以下方式添加常规(非混合)float16 训练的结果 fabric = Fabric(accelerator="cuda", devices=1, precision="16-mixed")(请注意,这目前需要通过 .从最新的开发人员分支安装 Lightning 。) pip install git+https://github.com/Lightning-AI/lightning@master不幸的是,这会导致损失不收敛,因此,准确度等于对该数据集的随机预测 (50%)。 Epoch: 0003/0003 | Batch 2700/2916 | Loss: nan Epoch: 0003/0003 | Train acc.: 49.86% | Val acc.: 50.80% Time elapsed 5.23 min Memory used: 2.87 GB Test accuracy 50.08%上面的结果总结在下表中:
正如我们所见,float16 混合精度几乎与纯 float16 精度训练(这里存在数值问题)一样快,并且也优于 float32 预测性能,这可能是由于上面讨论的正则化效果。 张量核和矩阵乘法精度顺便说一句,如果您在支持张量核的 GPU 上运行之前的代码,您可能已经在终端中通过 PyTorch 看到以下消息: You are using a CUDA device ('NVIDIA A100-SXM4-40GB') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read . set_float32_matmul_precision.html#torch.set_float32_matmul_precision因此,默认情况下,PyTorch 使用“最高”精度进行矩阵乘法。但是,如果我们想以更高的精度换取性能(如PyTorch 文档中所述),您还可以设置 torch.set_float32_matmul_precision("high")或者 torch.set_float32_matmul_precision("medium")(默认值通常是“最高”。) 上面的设置将使用 bfloat16 数据类型进行矩阵乘法,这是 float16 的一种特殊类型——下一节将详细介绍 bfloat16 类型。因此,换句话说,torch.set_float32_matmul_precision("high"/"medium")如果您的 GPU 支持张量核心,则使用将隐式启用混合精度训练(通过矩阵乘法)。 这对结果有何影响?我们来看一下:
因此,正如我们在上面看到的,对于 float32 精度,降低矩阵乘法精度具有显着效果,将计算性能提高 2.5 倍并将内存需求减半。此外,预测准确性增加,可能是由于前面提到的较低精度的正则化效应。 事实上,使用矩阵乘法精度较低的float32训练在性能上几乎等同于float16混合精度训练。此外,为 float16 启用较低的矩阵乘法精度不会改善结果,因为 float16 混合精度训练已经使用 float16 精度进行矩阵乘法。 Brain浮点数另一种浮点格式最近流行起来,即Brain Floating Point (bfloat16)。Google 为机器学习和深度学习应用开发了这种格式,特别是在他们的张量处理单元 (TPU) 中。与传统的 float16 格式相比,Bfloat16 以降低精度为代价扩展了动态范围。
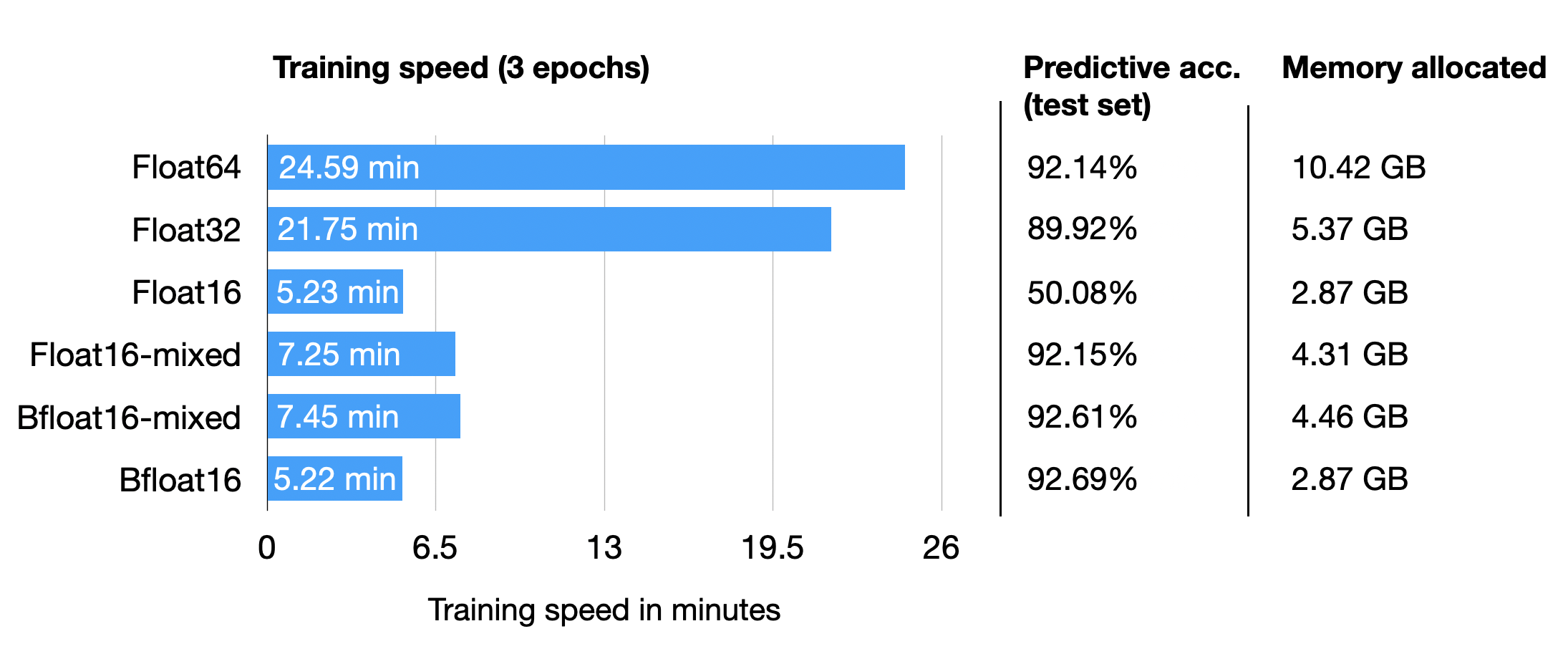
扩展的动态范围有助于 bfloat16 表示非常大和非常小的数字,使其更适合可能遇到各种值的深度学习应用程序。但是,较低的精度可能会影响某些计算的准确性或在某些情况下导致舍入误差。但在大多数深度学习应用程序中,这种精度降低对建模性能的影响微乎其微。 虽然 bfloat16 最初是为 TPU 开发的,但这种格式现在也得到了多个 NVIDIA GPU 的支持,首先是 A100 Tensor Core GPU,它们是 NVIDIA Ampere 架构的一部分。 您可以bfloat16通过以下代码检查您的 GPU 是否支持: torch.cuda.is_bf16_supported()True bfloat16 能让我们进一步受益吗?为了回答这个问题,让我们通过更改一行代码来添加运行先前 DistilBERT 代码的 bfloat16 结果 fabric = Fabric(accelerator="cuda", devices=1, precision="16-mixed")到 fabric = Fabric(accelerator="cuda", devices=1, precision="bf16-mixed")(完整的脚本可以在 GitHub 上找到。) 为了完整起见,我还添加了 float64 运行的结果。为了好玩,我们也试试常规(不是混合精度)bfloat16 训练:
有趣的是,float64 在这里实现了比 float32 更高的精度,这与我们之前关于较低精度对该模型具有正则化效果的论点相矛盾。然而,有趣的一点是,与 float16 相比,Bfloat16 混合精度训练在预测性能方面略微提高了结果;不过,它使用了更多的内存。 总而言之,float16 和 bfloat16 混合精度训练在这里表现得比较相似,这并不意外。 有趣的是,bfloat16 更大的动态范围还允许我们在没有混合精度训练的情况下训练模型,常规 float16 训练失败。请注意,这是一个幸运的巧合,在许多情况下,我经历过完整的 bfloat16 训练不如 bfloat16 混合精度训练。 高效的低精度推理和 LLaMA混合精度训练可以扩展到深度学习模型中的推理,以提高效率、减少内存占用并加速计算。但是,我们必须记住,在推理过程中应用较低的精度可能会由于数值精度降低而导致模型精度略有下降。然而,在许多深度学习应用程序中,对准确性的影响是最小的,并且是减少内存使用和加快计算的好处的可接受权衡。 事实上,上面的混合精度微调代码在计算训练、验证和测试集精度时,已经使用 16 位精度通过 Fabric 设置进行推理。由于 DistilBERT 是一个相对较小的模型,因此推理速度仅占总运行时间的一小部分。 因此,为了包含一个稍微更有趣的推理示例,让我们看看Meta 流行的用于生成文本的 LLaMA 模型。在这里,我们将使用用户友好的Lit-LLaMA 存储库,它使用相同的 Fabric 代码来实现我们之前使用的 16 精度。 然而,由于在 TB 级数据上预训练大型语言模型的成本相对较高,我们将使用 Meta 现有的模型检查点在推理过程中评估模型,生成新文本。
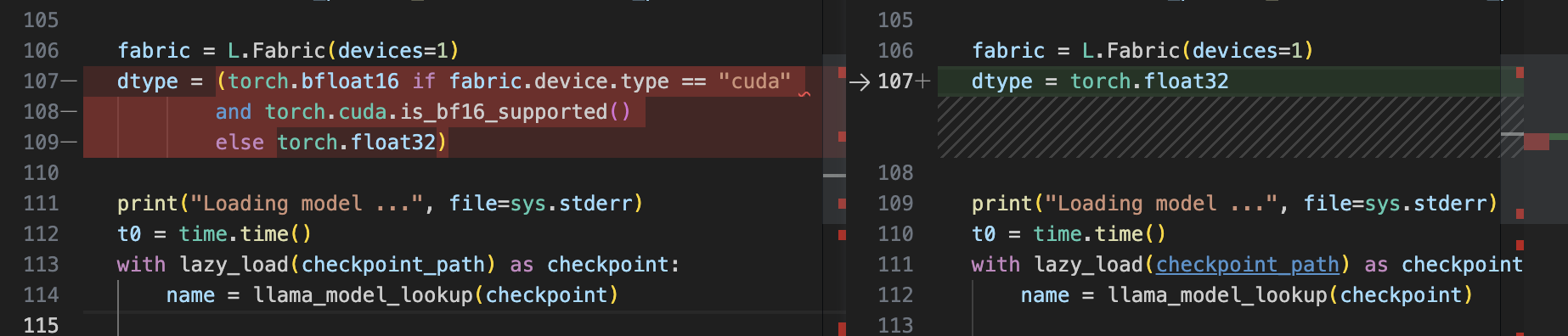
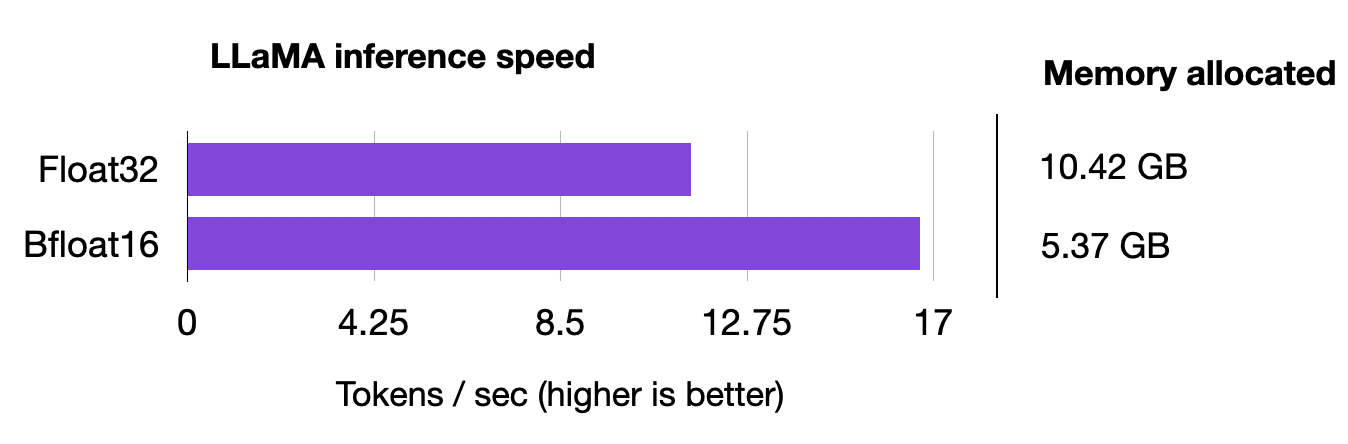
如果您是第一次使用存储库,请参阅安装部分以安装要求和下载权重的操作指南。 设置存储库后,我们可以使用generate.py脚本根据提示生成文本,默认使用 bfloat16: python generate.py --prompt "Large language models are" # uses bfloat16 Loading model ... Time to load model: 24.84 seconds. Global seed set to 1234 Large language models are an effective solution to the sequential inference task of natural language understanding, but are unfeasible for mobile applications. In this paper, we investigate a simple, yet effective approach to reduce the computational and memory demands of large language models by removing Time for inference 1: 2.99 sec total, 16.70 tokens/sec Memory used: 13.52 GB为了将其与 float32 精度进行比较,我们必须手动修改脚本,将 Fabric 设备类型torch.bfloat16从torch.float32. !
修改后,让我们使用generate.py与上面相同的提示重新运行脚本: python generate.py \\ --prompt "Large language models are" # disabled bfloat16, using float32 Loading model ... Time to load model: 17.93 seconds. Global seed set to 1234 Large language models are an effective solution to the sequential data modelling tasks, but the huge size of these models makes them difficult to learn due to the large amount of parameters and the time to train them. The high computational cost, as well as the long training times Time for inference 1: 4.36 sec total, 11.47 tokens/sec Memory used: 27.02 GB我们可以看到模型现在使用了两倍的内存,模型现在慢了 30%。
如果我们想在推理过程中进一步提高模型性能,我们还可以超越较低的浮点精度并使用量化。量化将模型权重从浮点数转换为低位整数表示,例如 8 位整数(最近甚至是 4 位整数)。 然而,由于这已经是一篇很长的博文,我们将在以后的文章中进行更详细的解释。 同时,Lit-LLaMA已经支持int8 量化( LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale)和 int4 量化( GPTQ: Accurate Post -Training Quantization for Generative Pre-trained Transformers )你想试一试! 结论在本文中,我们了解了如何使用 16 位精度技术将 LLM 分类器的训练速度显着提高 3 倍。此外,我们还能够将内存消耗减半! 此外,我们研究了生成式 AI 模型的推理速度,并且能够将性能提高 30%,同时将内存效率提高一倍。 因此,如果您使用支持混合精度训练的 GPU,那么值得使用它,因为它就像更改一行代码一样简单! |



【本文地址】