| “傻瓜”学计量 | 您所在的位置:网站首页 › stata的ols回归代码 › “傻瓜”学计量 |
“傻瓜”学计量
|
提纲: 自变量和因变量 控制变量 (选择 多重共线性 stata检验多重公共线性) 各模型的适用条件 回归结果解读 1 自变量与因变量 1.1要知道谁是“因”谁是“果”
举例:
是 2.1.2 控制变量与主要自变量可以互换位置吗?可以,并不影响回归结果。但是一般来说不这么做。 2.1.3 两者区别是什么?因果关系。主要自变量是我们想要研究的,后面还要解释与Y的因果关系。而控制变量只要不影响回归结果就可以了。 2.2 如何选择控制变量?按照自己的领域,多看前人的文献进行选择。 2.3 多重共线性 2.3.1 如果控制变量之间,存在高度相关or完美相关,即该模型存在多重共线性问题。如果两个控制变量之间存在多重共线性问题,则该变量之前的系数就会出现误差,其实际经济意义不准确。 2.3.2 多重共线性的检验 (1)容忍性(Tolerance) (2)方差膨胀系数(vif,variance inflation factor)stata操作如下: regress 因变量 自变量 进行OLS回归 estat vif 计算方差膨胀系数的指令 若回归结果vif值>10,则存在多重共线性问题。 3 如何选择模型(根据因变量Y)先来个总结,方便大家对比记忆 (不用严格连续,如人民币单位“元”) (误差项符合正态分布) (2)stata指令reg 因变量 自变量 进行OLS的回归 (3)结果解读最后一行“cons",全称“constant",是指常数项,对应的是 第三列"t",看这个回归系数是否显著。 3.1.2 y是0-1变量:Logit/Probit回归 (1)注意: Logit 和 Probit 的适用条件 假设一般实证中,logit使用较多。因为比较好解读。 (2)stata指令logit 因变量 自变量 probit 因变量 自变量 3.1.3 y是分类变量:ologit或者mlogit回归 ologit和 mlogit回归 的适用条件 分类变量ologit有序mlogit回归无序 3.1.4 y是计数变量:poisson回归(stata指令相同)计数变量(count variable):例如,多少人、多少次、多少天 计数变量的特点:整数 非负数 各种模型使用条件已经放在本节开头⬆ 4 回归结果解读(超详细)
主要汇报:回归模型的拟合程度、一些针对模型的指标
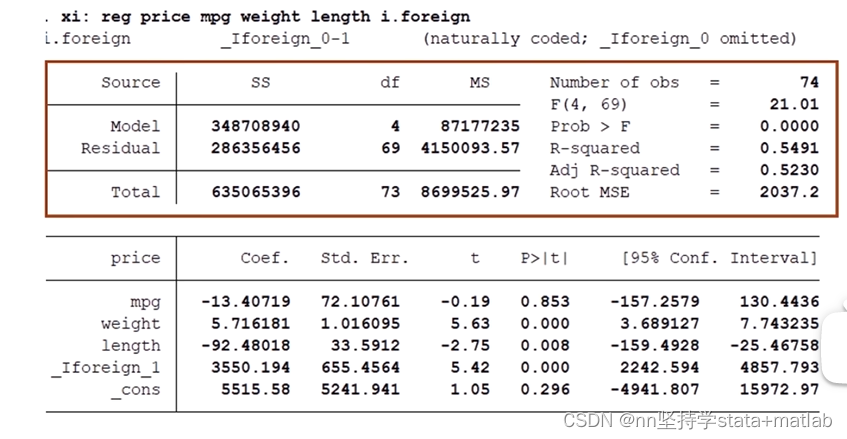
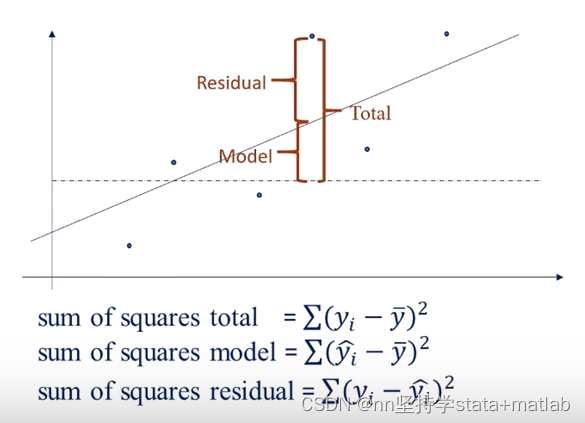 SS 平方和第一列 SS 平方和第一列 SSM sum of squares model 预测值和平均值之间的距离平方和; 模型的平方和; SSR sum of squares residual 真实值与预测值之间的距离的平方和; 误差项的平方和 ; total (sum of squares total,SST)真实值和平均值之间的距离平方和; 原始数据的离散程度; 第二列df 自由度(左侧第二列) (degree of freedom) n-k-1:是SSR的自由度 n-1:是SST的自由度 自由度:是衡量我们能够自由变动/自由取值的样本数量。 可以用“线性无关组“来理解。 n-k-1:这是因为我们在求回归结果的时候,需要估计k+1个未知参数。这里k是我们自变量的个数,所以有k个 MS (mean squared) 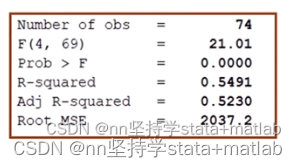 第一行number of obs 第一行number of obs 样本量,换句话说就是,我们计算回归结果所使用的原始数据的数量。 (检查这里和描述性统计中的样本量数值相差大不大。若相差比较大,则回归模型可能出错了) 第二行F检验第三列的第一行/第三列第二行 针对模型进行的总体显著性检验。换句话说就是用来检验 有兴趣的化可以看看为何要构建F统计量,空降0:24 线性回归结果详细解读/实证研究系列视频/系数的经济含义、显著性/R方,调整的R方/F检验/方差分析、SST SSR SSM、自由度、Mean squared_哔哩哔哩_bilibili 第三行P值也就是F值对应的P值 stata会帮我们查好 以上面的例子为例,即是说,在原假设( 换句话说,我们能获得这个值的概率极小,所以我们可以在1%的水平下拒绝原假设。即 R-squared (左边的表格数据计算的) 衡量预测值能拟合实际值的程度; 取值范围0-1; 该指标要根据同领域的文献情况来定,跟前辈差不多就可以了; 第五行Adj R-squaredn:样本量 k:自变量个数 n-k-1:是SSR的自由度(左侧第二列,df, degree of freedom) n-1:是SST的自由度 为了应对无限增加控制变量,从而使得R^2的数据看起来更好的情况;创造了调整后的R^2。 即,每增加一个变量,会对这个R-squared 有一个小小的惩罚。换句话说,就是人R^2就是在比较,新增加的这个变量所带来的拟合程度的提高和所带来的惩罚哪个更大一些。 第六行Root MSE(root mean square of error)左侧最后一个值,是右边表格第三列的第二行指标的算数平方根。 衡量回归模型中误差项的大小。 4.2 下半部分主要汇报:回归系数
每一个自变量前的 前四行,分别是 (这里涉及到如何解释回归模型变量系数,后附表格) 最后一行 _cons对应的值是 the standard error of coefficient 回归系数标准物:用来衡量回归系数的波动情况+检验我们的回归系数是否显著的不为零。 为什么回归系数有一个标准物? 因为我们第一列的系数,实际上是个估计量,而非真实值。这样的话我们采用不同的样本,就会产生不同的估计值。 第三列t统计量意义:回归系数对应的t值:针对回归系数做一个假设检验,检验回归系数是不是不等于0。 公式:统计量 计算方法:第一列/第二列 理由如下: 单样本t检验,检验我们的估计量是否等于某一个数值。 T值 回归系数对应的p值 stata给出了对应第三列t值的p值 以上面的例子为例: mpg:0.85=85%,并不是一个小概率事件,因此我们不能拒绝原假设,不能说我们的回归系数显著区别于零。也即,回归系数不显著; weight:p=0.0001.65,或者p值1.96,或者p值12.58,或者p值 |

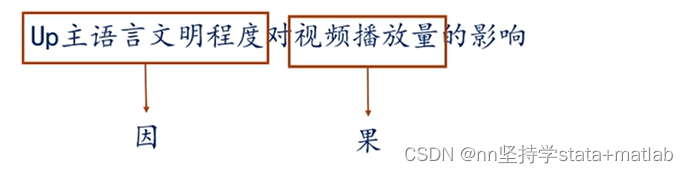 在一般的多元线性回归模型中,重要的自变量放前面,叫做“主要自变量”,如下图所示:
在一般的多元线性回归模型中,重要的自变量放前面,叫做“主要自变量”,如下图所示:



【本文地址】