| stata | 您所在的位置:网站首页 › stata中ttail函数怎么用 › stata |
stata
|
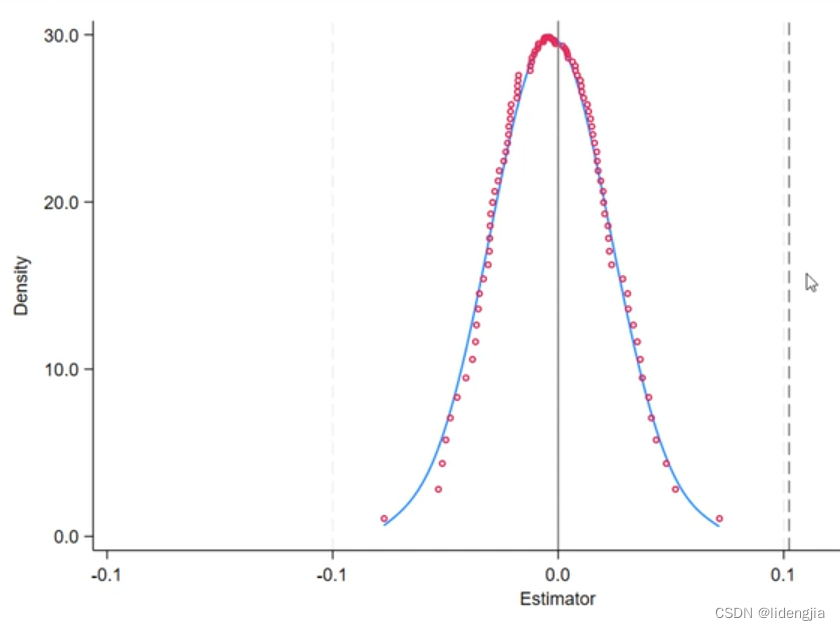
实证小李-六步法(找数据,想机制,跑基准,稳健性,内生性,异质性) 本次要讲的是-稳健性检验-安慰剂检验通常用于did做实证分析时,其他虚拟政策对y是没有影响的,现在一般采用permute检验,这个命令可以省去很多代码量,具体的视频讲解请移步: https://www.bilibili.com/video/BV1kH4y177VM/spm_id_from=333.999.0.0&vd_source=d6cea42a005ed788519a8f3c726b3db0这里将did换成你使用的did,默认命名规范为did permute did beta=_b[did] se =_se[did] df=e(df_r), reps(100) rseed(123) saving ("anweiji.dta",replace):reghdfe edu did $firmvar $cityvar,absorb(industry city year) vce(cluster stkcd)绘图,这里注意 t_value =beta/se,其中beta是did之前的回归系数,se是标准误,t值得计算为回归系数除以标准误。 use "anweiji.dta",clear gen t_value =beta/se gen p_value=2*ttail(df,abs(beta/se))**xtitle(“Estimator”,size(0.8)):**设置 x 轴的标题为 “Estimator”,并指定标题的大小为默认大小的 80%。 **xline(0.0512,lc(black0.5) lp(dash)):**在 x 轴上绘制一条虚线,位置在 0.0512 处,线条颜色为黑色的一半(即灰色),线型为虚线。 **xlabel(-0.8(0.1)0.8,format(%4.1f) labsize(small)):**设置 x 轴的刻度标签为从 -0.8 到 0.8,间隔为 0.1,格式为保留一位小数,标签大小为小号。 **yline(0.1,lc(black*0.5) lp(dash):**在 y 轴上绘制一条虚线,位置在 0.1 处,线条颜色为黑色的一半(即灰色),线型为虚线。 **ytitle(“Density”,size(*0.8))):**设置 y 轴的标题为 “Density”,并指定标题的大小为默认大小的 80%。 **ylabel(,nogrid format(%4.1f labsize(small))):**设置 y 轴的标签格式为保留一位小数,标签大小为小号,不显示网格线。 **note(“”) 和 caption(“”):**分别设置注释和标题为空。 **graphregion(fcolor(white)):**设置图形区域的背景色为白色。 注意这个绘制要将你的0.0512换成你的回归系数,即beta得具体值,这张图要说明的是,经过虚拟政策检验以后,大部分得值都集中在0附近,且服从正态分布。 dpplot beta,xline(0.0512,lc(black*0.5) lp(dash)) xline(0,lc(black*0.5) lp(solid)) xtitle("Estimator",size(*0.8)) xlabel(-0.1(0.05)0.1,format(%4.1f) labsize(small)) ylabel(,nogrid format(%4.1f) labsize(small)) note("") caption("") graphregion(fcolor(white))
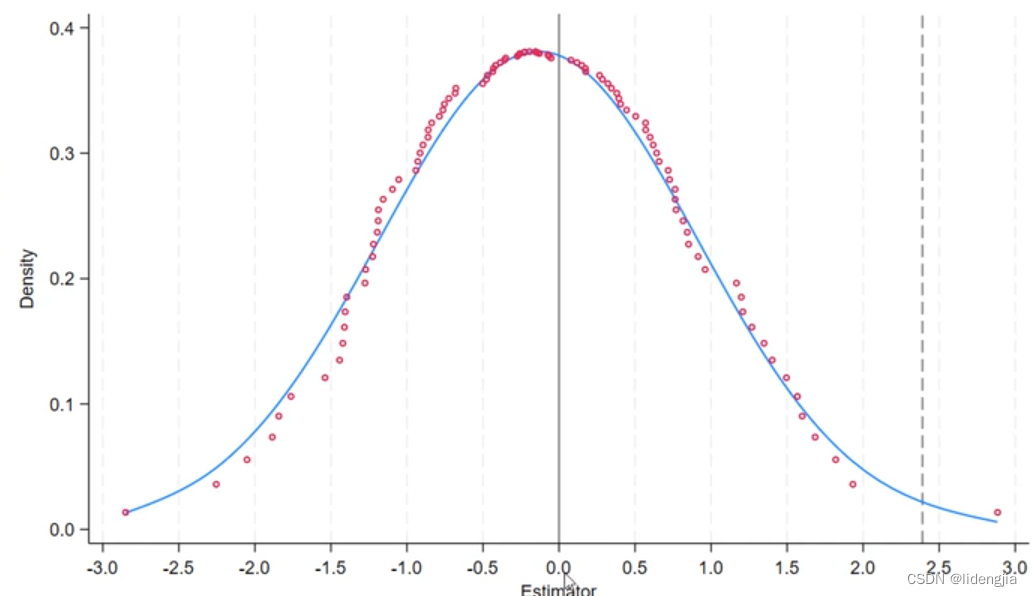
这里要将2.39换成你主回归的t值,然后绘制图形。 dpplot t_value,xline(2.39,lc(black*0.5) lp(dash)) xline(0,lc(black*0.5) lp(solid)) xtitle("Estimator",size(*0.8)) xlabel(-3(0.5)3,format(%4.1f) labsize(small)) ytitle("Density",size(*0.8)) ylabel(,nogrid format(%4.1f) labsize(small)) note("") caption("") graphregion(fcolor(white))
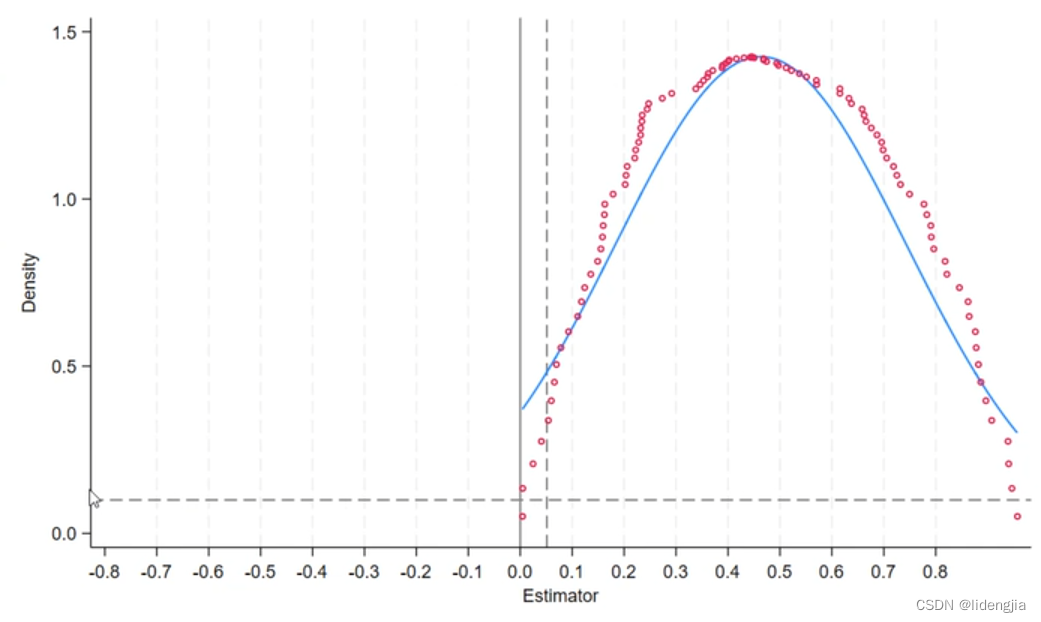
这里不变0.0512还是beta的系数,但是要更换yline(0.1,lc(black*0.5) lp(dash),因为0.1代表不显著。结果大部分要在0.1得上面,yline是画0.1的横线 dpplot p_value,xline(0.0512,lc(black*0.5) lp(dash)) xline(0,lc(black*0.5) lp(solid)) xtitle("Estimator",size(*0.8)) xlabel(-0.8(0.1)0.8,format(%4.1f) labsize(small)) yline(0.1,lc(black*0.5) lp(dash) ytitle("Density",size(*0.8))) ylabel(,nogrid format(%4.1f labsize(small))) note("") caption("") graphregion(fcolor(white))
导出图片: graph export "安慰剂检验.png",width(1000) replace最后补充一下t值,p值,标准误之间的关系,好记心不如烂笔头,总是记不住 在统计学中,t 值(t-value)是用来衡量样本统计量与总体参数之间差异的一种度量。它的计算方式是将样本统计量与假设的总体参数之间的差异除以标准误(standard error)。标准误是样本统计量的标准差,表示样本统计量与总体参数的估计值之间的不确定性。 p 值(p-value)是在假设检验中用来判断样本统计量是否足够极端,从而决定是否拒绝原假设的概率。p 值越小,表示观察到的样本统计量在原假设下出现的概率越低,因此拒绝原假设的依据越强。 综上所述,t 值的绝对值越大,表示样本统计量与总体参数之间的差异越大,p 值越小,表示样本统计量越不可能是由于随机因素导致的。标准误则是衡量样本统计量的不确定性,可以帮助解释 t 值和 p 值的意义。 在多元回归中,t 值用于检验回归系数(coefficients)是否显著不等于零,从而判断自变量对因变量的影响是否显著。t 值的计算公式如下: |
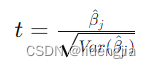 兄弟们stata和计量是补充统计知识的好途径,可以说你从另一角度打开了统计学的大门,可以方便你做机器学习,理解一些求和和统计量之间的关系,而且难度极低,如果你能手敲代码并会一定的debug,那你一定会进步神速。
兄弟们stata和计量是补充统计知识的好途径,可以说你从另一角度打开了统计学的大门,可以方便你做机器学习,理解一些求和和统计量之间的关系,而且难度极低,如果你能手敲代码并会一定的debug,那你一定会进步神速。【本文地址】