| sql server查询中文乱码问题解决 | 您所在的位置:网站首页 › sqlserver结果栏 › sql server查询中文乱码问题解决 |
sql server查询中文乱码问题解决
|
问题描述: 在使用Navicat Premium 连接ms server,查询文件使用情况的时候,发现中文出现乱码 具体如下:
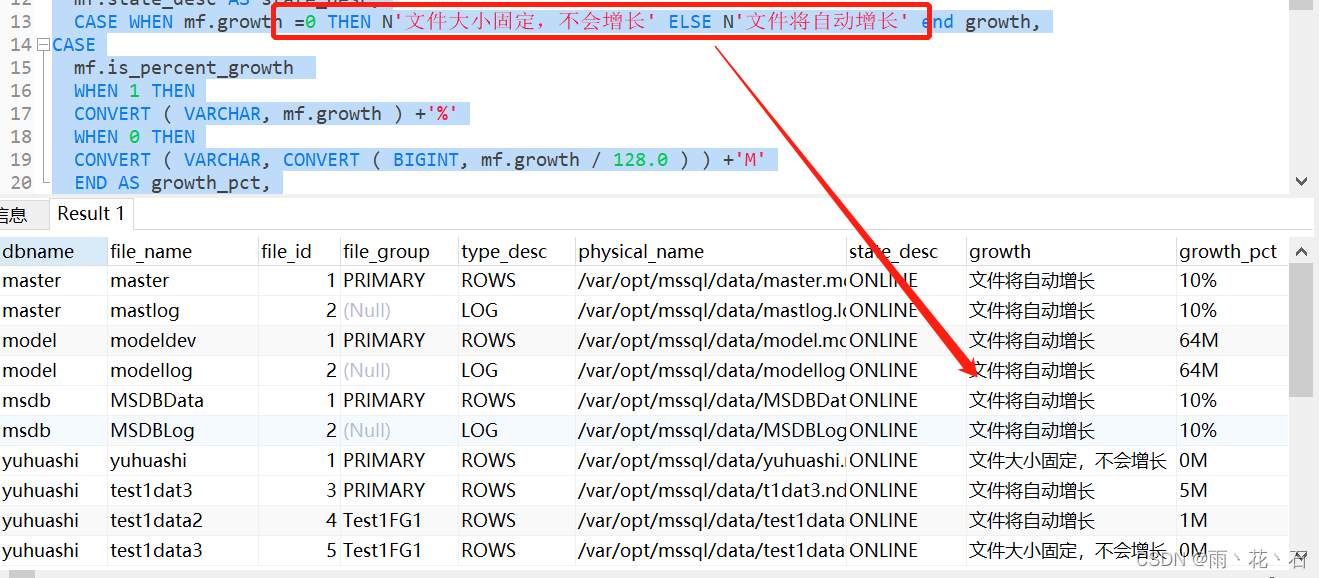
中文乱码的问题,在mysql或oracle中也经常遇到基本上都会字符集设置有关系,那ms server如何解决呢?通过设置字符集可不可以?有没有更加简便的方法呢? 问题分析: 带者上面的疑问,有没有不改字符集的方式更方便解决乱码的问题了吗? 网上找到了这样一段话 1, Unicode 数据使用 SQL Server 中的 nchar、varchar 和 ntext 数据类型进行存储。对于存1储来源于多种字符集的字符的列,可采用这些数据类型。当列中各项所包含的 Unicode 字符数不同时(至多为 4000),使用 nvarchar 类型。当列中各项为同一固定长度时(至多为 4000 个 Unicode 字符),使用 nchar 类型。当列中任意项超过 4000 个 Unicode字符时,使用 ntext 类型。 在 Microsoft SQL Server 2000 中,传统上非 Unicode 数据类型允许使用由特定字符集定义的字符。字符集是在安装 SQL Server 时选择的,不能更改。使用 非Unicode 数据类型存储数据时,如varchar, char, text等,如果未指定字符排序序列时(字符集),使用默认的字符集,即使为某个字段指定了字符排序序列时,如果SQL Server 默认的排序序列与指定字段的排序序列不同时,不加N的话也会产生乱码,如默认的字符集是单字节的字符集如拉丁字符集(Collation name为Latin1_General_CI_AS)的时候,如果定义Name为Varchar类型,字符集为中文字符集时(Collation name为Chinese_PRC_CI_AS),用如下的插入语句也会乱码 insert a(name) values ('AA中'),因为数据插入的时候,默认还是用Latin1_General_CI_AS字符集送到服务器,再转换为Collation name为Chinese_PRC_CI_AS时,产生乱码,但如果改为如下的时候: insert a(name) values (N'AA中') 则能正确插入,因为通过N前缀,以UNICODE的形式送到SQLSERVER,然后再转换成Chinese_PRC_CI_AS时,就不会产生乱码。 2,UNICODE和非UNICODE之间的转换 2-1 UNICODE--〉非UNICODE:Convert(varchar(50), name Collate Chinese_PRC_CS_AS_KS_WS)--name 是nvarvhar类型的,如name是'AA中'的时候 Select DATALENGTH(Convert(varchar(50), name Collate Chinese_PRC_CS_AS_KS_WS)) from x, 返回的长度为4(UNICODE的时候为6) 2-2 非UNICODE--〉UNICODE的时候:Convert(nvarchar(50), name)--name是varchar类型的时候如name是'AA中'的时候 Select DATALENGTH(Convert(nvarchar(50), name)) from x, 返回的长度为6(非UNICODE的时候为4)问题处理: 按上面所说: 加N前缀指定后面的字符串为UNICODE常量, SQL Server 的 Unicode 数据类型是基于 SQL-92 标准中的国家字符数据类型。SQL-92 使用前缀字符 N 标识这些数据类型及其值。 那我们在中文前面加上N,验证一下:
问题总结: 说白了还是字符集的问题,只不过这里将字符串指定为UNICODE常量 |

【本文地址】
公司简介
联系我们