| SPSS K均值聚类(k | 您所在的位置:网站首页 › spss如何做年龄分析表图 › SPSS K均值聚类(k |
SPSS K均值聚类(k
|
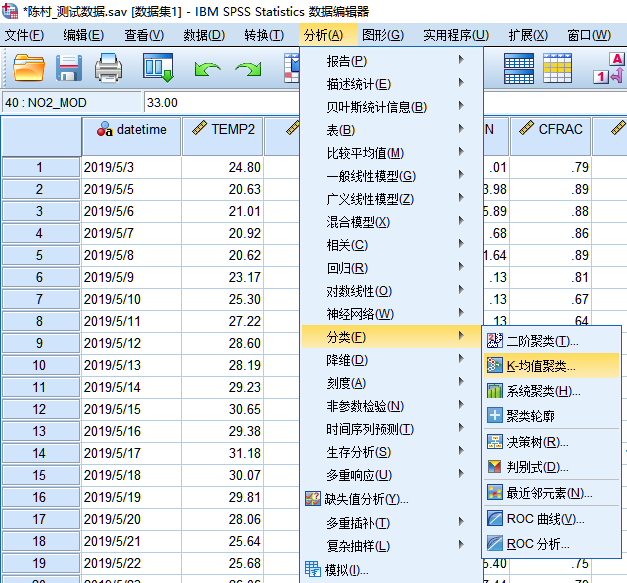
1. 打开数据,依次选择 分析-> 分类 -> K-均值聚类…
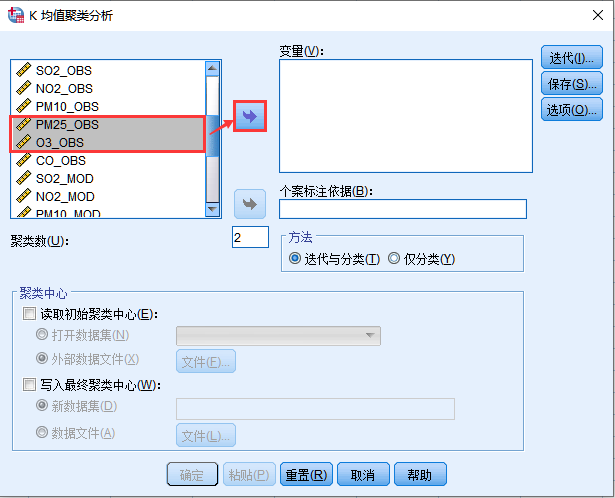
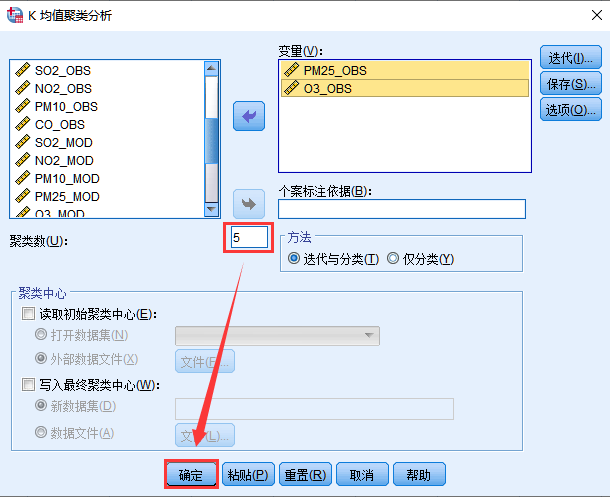
2. 将分类的关键变量选入,这里以PM2.5和O3的监测数据为例。
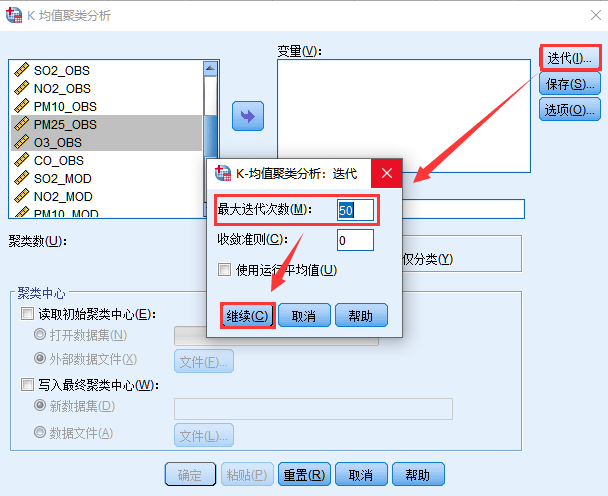
3. 单击 迭代…,将 最大迭代次数设置成一个将大的数值,单机 继续
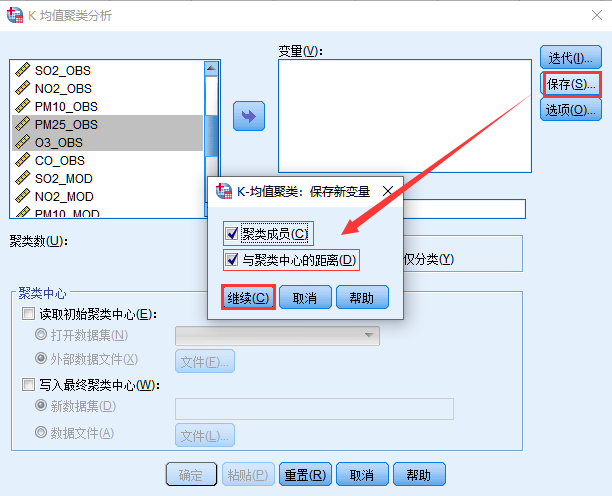
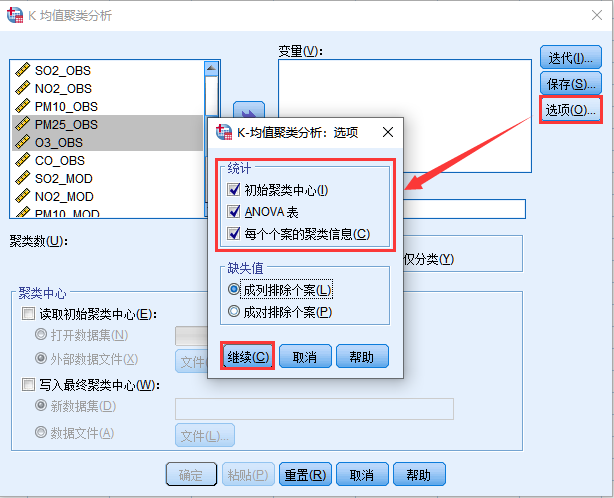
4. 单击 保存…,勾选 聚类成员和与聚类中心的距离,单击 继续
5. 单击 选项…,勾选 统计中的所有选项,缺失值中选择 成列排除个案,单击 继续
6. 聚类数设置为5,单击确定
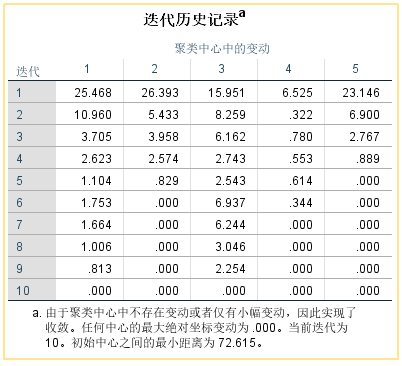
7. 结果解读:迭代历史记录,反应了迭代过程中聚类中心的变动情况。第10次无变动,说明算法收敛。
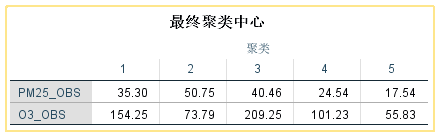
8. 结果解读:最终聚类中心,是个各类的均值,可用于之后的分类。
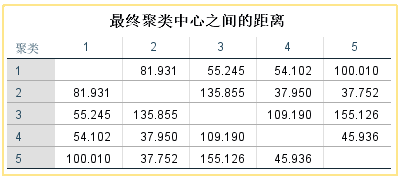
9. 结果解读:最终聚类中心之间的距离,可用于分析聚类情况是否合适,是否有必要减少或增加类的数量
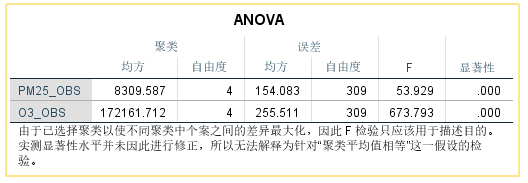
10. 结果解读:ANOVA(单因素方差分析),可根据F值大小近似得到变量对聚类的贡献,如下表说所示,重要程度排序为 O3_OBS > PM25_OBS,同时 二者的显著性均低于0.05,均对聚类有显著的贡献。
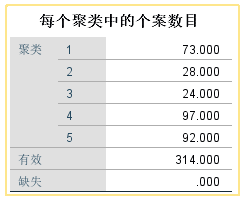
11 .结果解读:每个聚类中的个案数目,统计各类别数目及缺失情况。
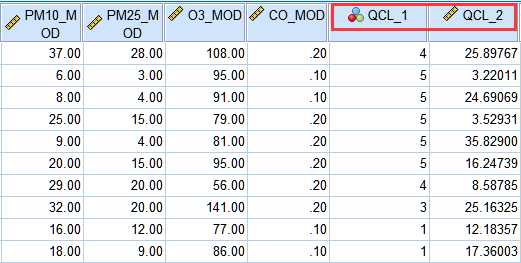
12. 聚类结果,会保存在数据表中,QCL_1标注个案的类别,QCL_2表示个案与聚类中心的距离
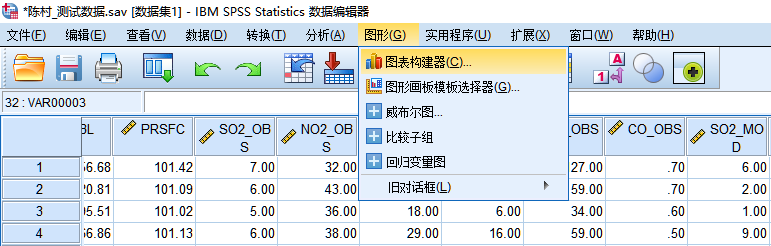
13. 可视化,依次选择 图形 -> 图表构建器…
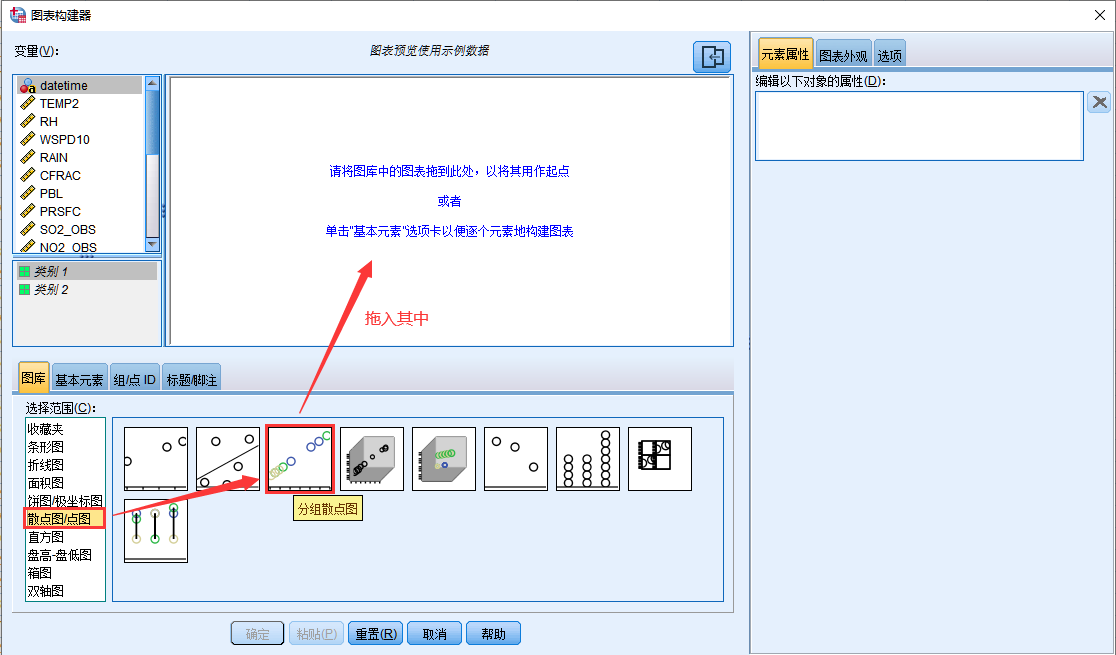
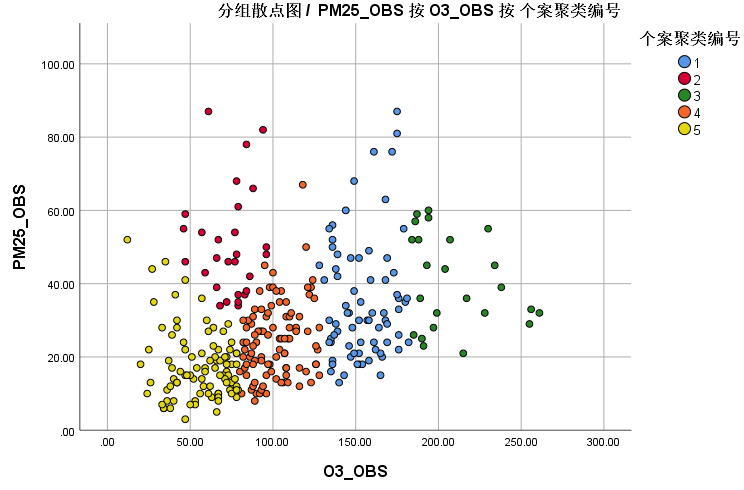
14. 选择 散点图/点图 中的分组散点图,将其拖入绘图展示区中
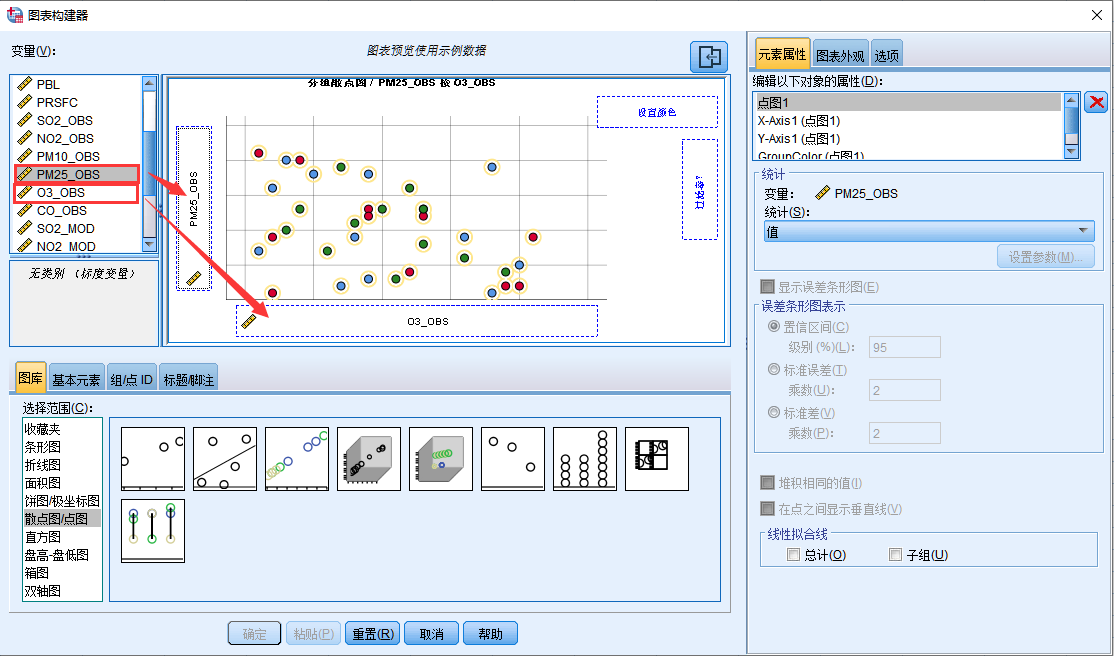
15. 将O3_OBS和PM25_OBS分别拖入横轴和纵轴
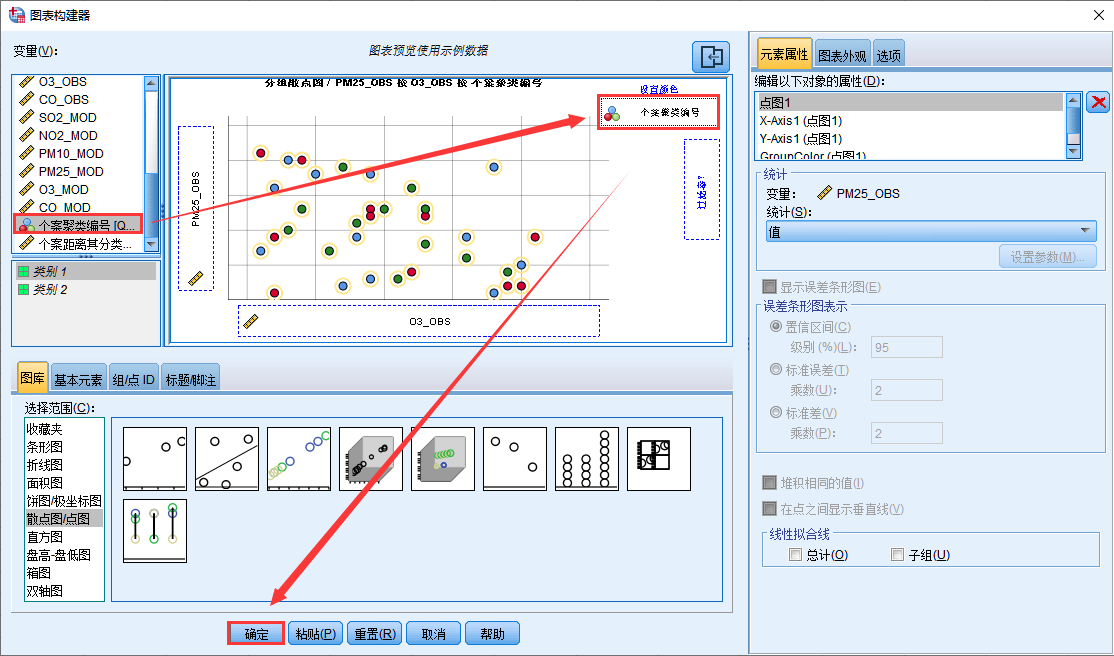
16. 将个案聚类编号拖入设置颜色方框中,单击确定
17. 绘图效果如下所示,可以直观展示聚类效果。
参考资料: https://www.sohu.com/a/208536450_109461 https://blog.csdn.net/weixin_44255182/article/details/108969852
|
【本文地址】