| 《如何使用SPSS进行相关性分析(二):两个类别变量的相关》 | 您所在的位置:网站首页 › spss可以输入分数吗 › 《如何使用SPSS进行相关性分析(二):两个类别变量的相关》 |
《如何使用SPSS进行相关性分析(二):两个类别变量的相关》
|
针对该研究问题,在SPSS中的具体分析过程可分为以下几步。 (一)处理数据在一份样本数据中,要分析的变量可能会存在不符合此次分析的数据,因此需要对这些数据进行缺失值处理,即将它们标记为缺失值,这样在分析中系统会自动将它们剔除。
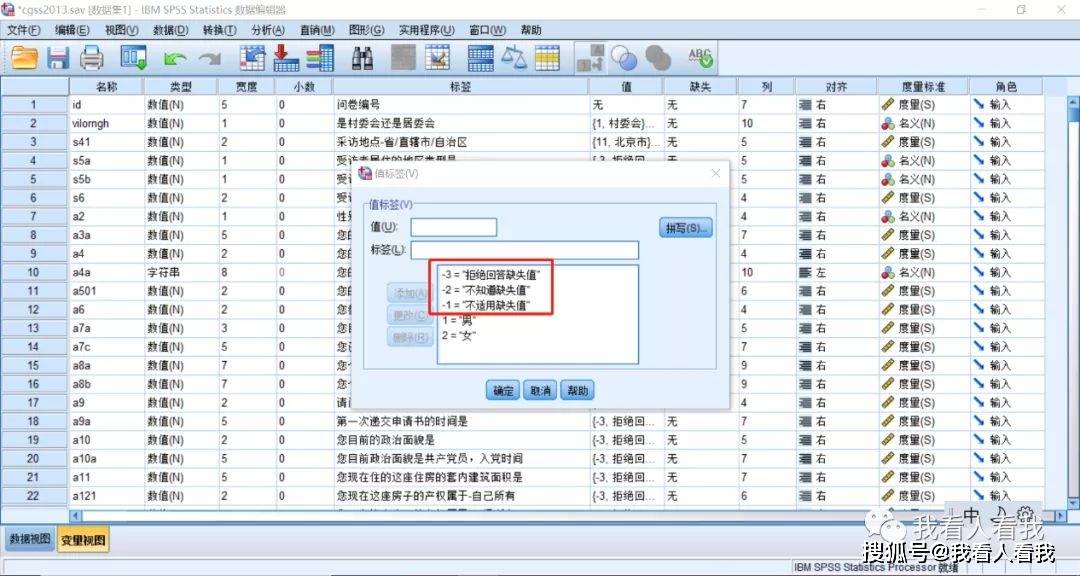
比如在性别这个变量中,存在-1、-2、-3这三个没有分析价值的值(查看路径:该变量对应的“值”列——省略号图标),这时候就可以将它们设置为缺失值。
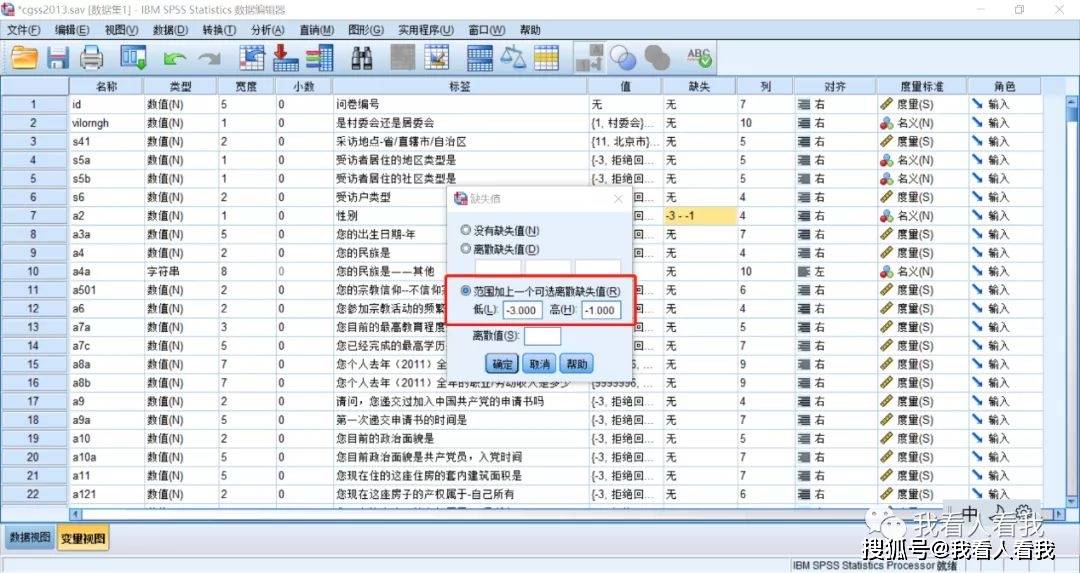
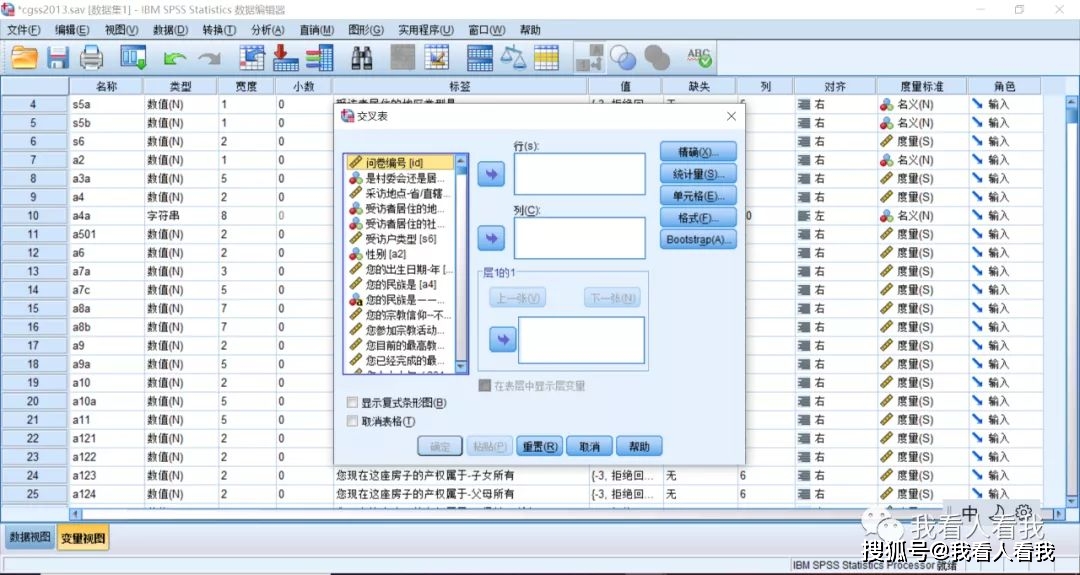
打开缺失值设置对话框(操作路径:该变量对应的“缺失”列),这里选择第三个选项,基于想要剔除的值设置缺失值范围。 变量政治面貌的缺失值设置也同理。设置好缺失值后,数据就符合我们的分析要求了。 (二)进行交叉列表分析操作1. 打开交叉列表分析对话框 操作路径:工具栏“分析”——描述统计——交叉表
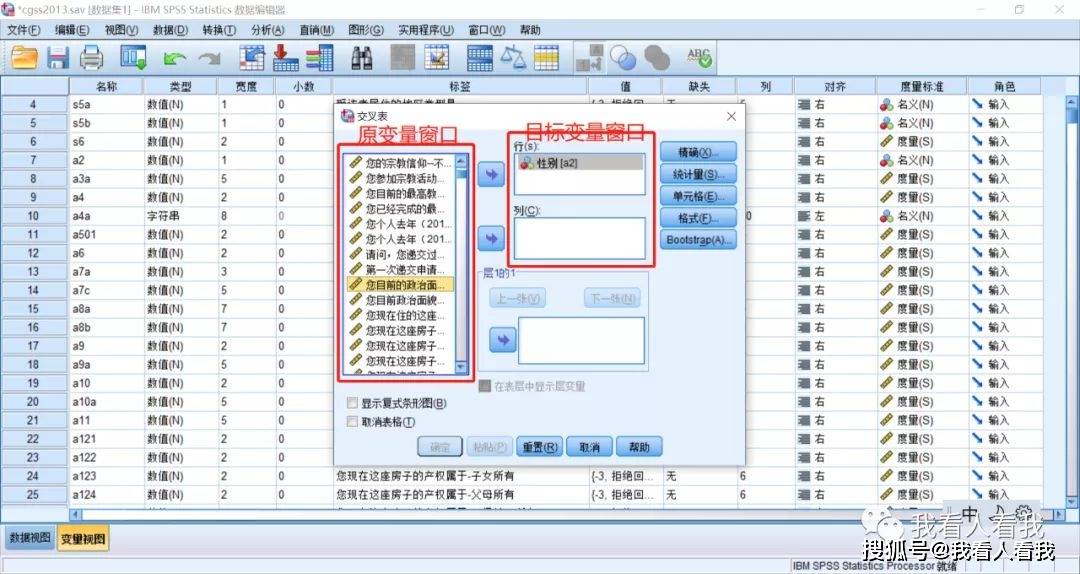
2. 确定交叉列表分析的变量 这里我们要分析的变量是“性别”和“政治面貌”,在交叉表对话框中,从左侧的原变量窗口中选择相应变量,添加到右侧的目标变量窗口。
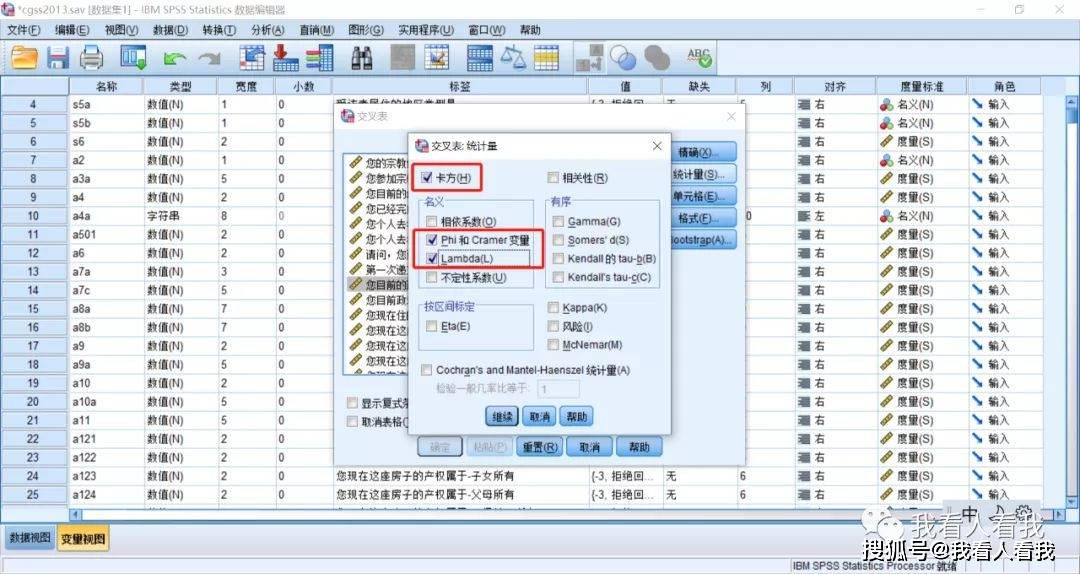
目标变量窗口中,“行”变量指的是,最后输出的数据在交叉表中以行的形式展现;“列”变量则是最后输出的数据在交叉表中以列的形式展现。一般来说,如果我们认为两个变量存在因果关系,我们习惯将自变量放在行变量窗口,因变量放在列变量窗口。 3. 选择统计分析内容 操作路径:交叉表对话框——统计量
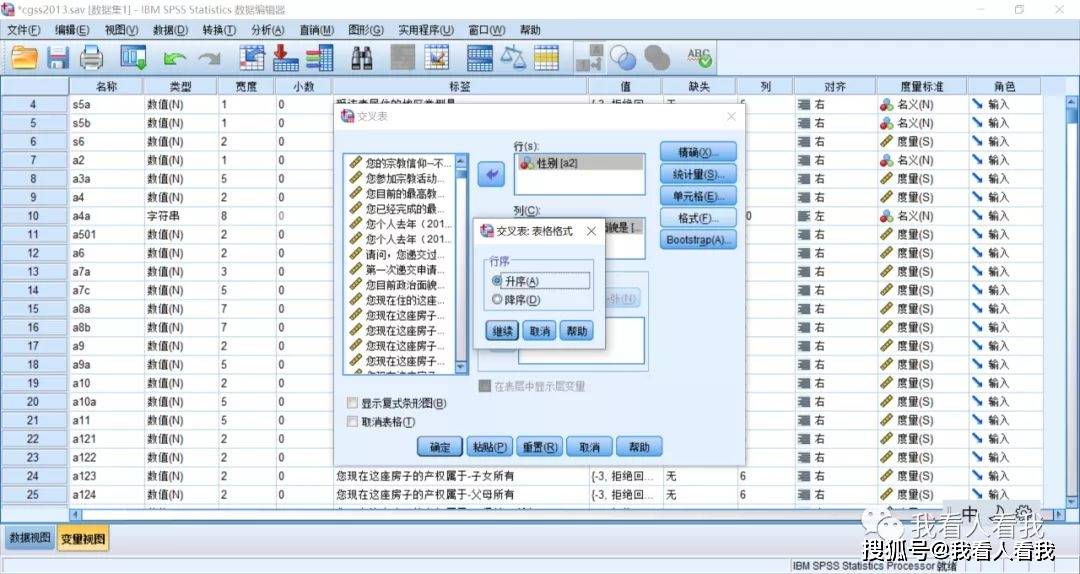
如果要将分析结果推论总体,则需选择卡方检验;统计量对话框中的“名义”所呈现的是名义变量即定类变量的相关系数测量方法,“有序”则是定序变量的相关系数测量方法。所以使用SPSS分析其实很简单,系统已经给出了针对性的方法,我们只要针对自己的实际分析情况来选择就好了。 这里我们要分析的是两个定类变量的相关关系,所以选择了Lambda相关测量法、古德曼(Goodman)和古鲁斯卡(Kruskal)的tau-y系数。 确定这三个统计量后,单击继续,返回主对话框。 4. 确定输出的交叉表单元格的值(操作路径:交叉表对话框——单元格) “计数”框中的“观察值”是指根据实际调查数据所输出的实际频数,“期望值”是指,当性别和政治面貌没有相关关系时,两个变量对应的理想频数。 “百分比”框中,如果是将自变量放入了行变量窗口中,则选择“行”;如果是将自变量放入了列变量窗口中,则选择“列”。 5. 确定交叉表的行顺序(操作路径:交叉表对话框——格式)
这里保持系统默认的“升序”。 最后点击确定,就可以输出统计分析结果了。 (三)解读统计分析结果在使用SPSS进行数据分析时,软件操作都比较简单,比较关键的是如何解读输出的统计结果。在统计结果中,主要看以下几个数据内容:案例处理摘要、交叉制表、方向度量、卡方检验。 1. 案例处理摘要 这个表是对我们所分析的数据的整体概述。从表中可以知道,我们分析的样本总量有11438个,其中有效样本量为11372个(即这次分析的实际样本总量),缺失样本(即在第一步数据处理中被我们标记为“缺失值”的没有分析价值的样本)66个。 2. 交叉制表 我们看交叉表的目标是,从数据中粗略判断两个变量是否存在相关关系。从表中来看,男性中中共党员的人数占比要远高于女性的情况,相反,男性中政治面貌为群众的人数占比则低于女性的情况,民主党派和共青团员的人数占比没有性别差异。因此,我们可以初步认为,性别与政治面貌存在相关关系。 3. 方向度量
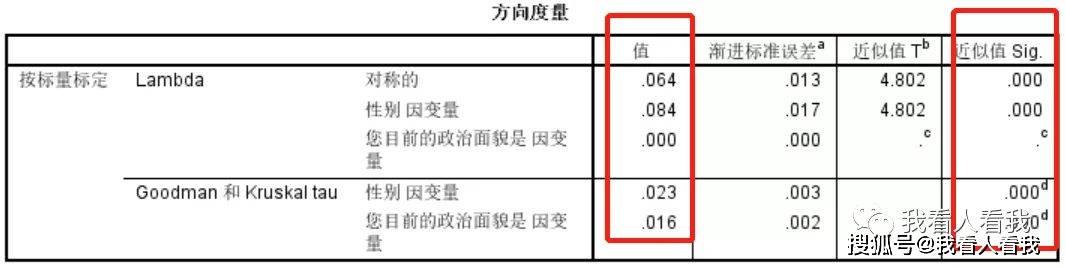
知道了性别与政治面貌存在相关关系,但具体相关程度是强还是弱,还需要通过“方向度量”表中的结果进行判断。 前面介绍到,Lambda测量方法会面向两种形式:一种是对称关系,即假定两个变量之间的关系是对称的,不区分自变量和因变量;另一种是不对称关系,即区分自变量和因变量。所以在表中我们可以看到Lambda输出的值中区分了这两种形式的三种结果:对称形式时,Lambda值为0.064;不对称形式时,性别为自变量、政治面貌为因变量的情况下,值为0.084。这种情况,我们一般主要看对称形式情况的值,即0.064。古德曼(Goodman)和古鲁斯卡(Kruskal)的tau-y系数只适用于不对称形式,这里应该是取性别为自变量、政治面貌为因变量比较合理,即值为0.023。 从结果来看,虽然性格和政治面貌存在相关性,但这种相关非常的弱。另外,从表中的最后一列显著性水平P值中,我们可以看到P值为0,说明样本中性别与政治面貌存在的弱相关,在总体中是显著存在的。 4. 卡方检验 卡方检验的目的是,通过随机样本数据来推论总体是否也存在同样的结论。卡方检验是属于显著度检验的一种,其基本逻辑是,先设定一个原假设,即两个变量不存在相关关系,比如性别和政治面貌不存在相关关系,然后通过显著度检验结果,来决定是否接受原假设。如果检验结果拒绝了原假设,我们就有理由相信,这两个变量存在相关关系。是否应该接受或拒绝原假设,主要看的是p值(Sig值),即显著性水平,p值表示的是接受原假设的概率有多大,主要是基于小概率原理,这里我们就不展开讲,后面有机会再详细介绍。 这里的卡方检验中,我们主要看红框一列的p值,p值为0,表明原假设成立的概率为0,即原假设性别与政治面貌不存在相关关系这个事件是不可能发生的。因此,我们可以认为,在总体中,男女两性的政治面貌是存在差异的。 需要注意的是,卡方检验对交叉表中的期望频次计数是有要求的,即要求期望频次计数一般不能小于5,如果有小于5的单元格,则要求不能超过总单元格的20%,否则会放大卡方值,使原本不相关的变量变成是相关的。如果出现单元格数比较多又要进行卡方检验,可以先对单元格进行合并处理,再做卡方检验。 二、 两个定序变量的相关性分析两个定序变量之间的相关分析,也称为等级相关分析,其分析思路与定类变量类似,不过定序变量的量化层次要比定类变量高一个层次,因此相关性测量可以选择包含更多信息的等级相关系数来描述变量之间的相关性大小和方向。 1. 首先,通过交叉列表的方法粗略判断是否存在相关关系 2. 其次,通过相关系数测量方法来测量相关性大小和相关性方向 定类变量之间的相关关系是没有方向的,相关系数取值范围为[0,1];但定序变量及其以上的测量层次则可以描述变量之间的相关性方向,系数取值范围为[-1,1]。等级相关分析测量方法可以选择古德曼(Goodman)和古鲁斯卡(Kruskal)的Gamma系数,以及萨默斯(Somers)的dy系数 (1)Gamma 相关测量法 Gamma 系数适用于分析对称的相关关系(即不区分自变量和因变量),系数值范围为[-1,1],既能表示相关的程度,也表示相关的方向。 (2)Somers 的dy系数相关测量法 Somers dy系数适用于分析不对称的相关关系(即需要区分自变量和因变量),系数值范围为[-1,1],既能表示相关的程度,也表示相关的方向。 Gamma 系数和Somers dy系数的目标都是分析两列等级数据的关系,因此统称为级序相关法,其基本逻辑是:根据任何两个个案在某变量上的等级来预测他们在另一个变量的等级时,可以减少的误差多少。 接下来,我们以休闲调查的数据来进行实际案例操作。 由于等级相关分析的思路与定类变量之间的相关分析类似,其在SPSS的操作也无大的区别,主要是在统计量的选择和统计结果的解读存在一定差异。所以后面我们就只讲下差异的部分。 研究问题:在休闲调查中,人们的文化程度与他们对周围居住环境的满意度是否存在相关性? (一)确定统计分析内容这里我们以“文化程度”为行变量,对周围居住环境满意度为列变量。 选择统计量的时候,我们没有选卡方检验,主要考虑到交叉表中的期望频次计数存在较多小于5的单元格,不适合使用做卡方检验,因此只选择了用于测量等级相关系数的Gamma系数和Somers的dy系数。 (二)解读统计结果统计结果主要输出了四份数据内容:案例处理摘要、交叉表、方向度量、对称度量,和定类变量之间的相关分析差不多。这里我们主要看方向度量和对称度量。 1. 方向度量
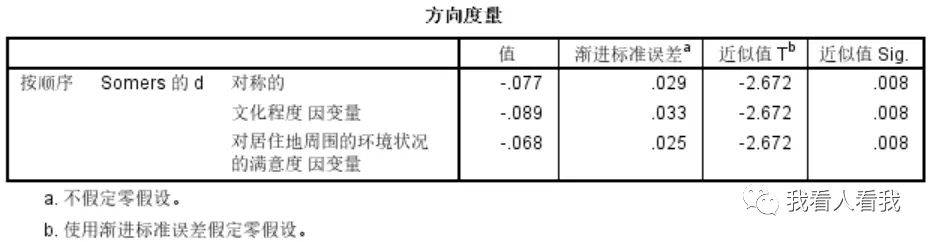
方向度量表记录的是Somers的dy系数的结果。从表中可以看到,系数值为-0.077,表示文化程度与对周围居住环境满意度存在比较弱的负相关;p值为0.008,说明在总体中,这种弱负相关是显著存在的 。 2. 对称度量
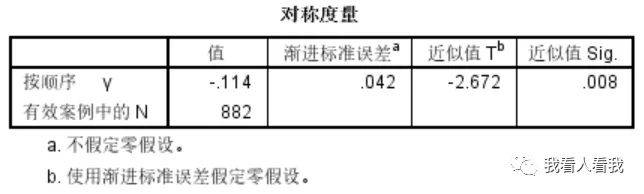
对称度量表记录的是Gamma系数的结果。这里需要对SPSS的输出结果更正一下,表中的“Y”其实是错误的,没有这样的相关性测量方法,实际应该显示为“Gamma”。 Gamma系数值为-0.114,文化程度与对周围居住环境满意度存在弱负相关;p值为0.008,样本统计结果可以推论总体。 后续还将继续介绍:(1)两个定距变量的相关分析;(2)定类和定距变量的相关分析 【#关于作者#】 中山大学人类学硕士,用户研究工程师、数据分析师,微信公众号【我看人看我】,主要分享SPSS统计分析、用户研究理论与方法、社会科学研究与方法等。返回搜狐,查看更多 |
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |