| SparkRDD | 您所在的位置:网站首页 › spark的转换操作collect › SparkRDD |
SparkRDD
|
转换算子
一、单value型转换算子(只使用1个RDD):
1、map 将数据进行转换,数据量不会增加和减少
2、mapPartitions 以分区为单位将一个分区内的数据进行批处理操作,且可以执行过滤操作
3、mapPartitionsWithIndex 功能类似mapPartiutions算子,只是加入了每个分区的索引,可以选择性的对某些分区进行操作
4、flatMap 扁平化操作,即将集合嵌套类型的数据或者可转换为嵌套集合的类型的数据转换为非嵌套集合
5、glom 将元素合并为分区数量的数组,不需要传参数
6、groupBy 通过给定函数计算所得key进行分组,返回一个键值对,键为key的类型,值为Iterable,有shuffer
7、filter 将数据根据相应规则进行过滤,符合的保留,不符合的丢弃,过滤后分区不变。
8、sample 抽样算子
9、distinct 去重算子,将传入的数据集中相同的数据去除多余的保留一个
10、coalesce 缩减分区,默认不打乱分区,只是缩减分区,即将几个分区合并在一起
11、rePartition 扩大分区,扩大时必然会导致同一个分区的数据分到不同的分区,这就会发生shuffle
12、sortBy 排序算子,将分区数据进行排序,分区数不变,但会产生shuffle
二、双value型转换算子(使用两个RDD):
1、intersection 对两个RDD求交集然后将结果封装为一个RDD,两个RDD数据类型必须一致
2、subtract 对两个RDD求差集然后将结果封装为一个RDD,两个RDD数据类型必须一致
3、union 求两个RDD元素的并集,然后将结果封装为一个RDD,两个RDD数据类型必须一致
4、zip 将两个 RDD 中的元素以键值对的形式进行合并,不要求数据类型一致,但要求分区数一致且每个分区中元素数量一致
三、键值类型转换算子(数据源为键值对):
1、partitionBy 传入一个Partitioner进行重新分区,默认的分区器是HashPartitioner,也可以自定义分区器,存在shuffer
2、reduceByKey 将相同key的数据的value执行传入reduceByKey函数的操作,存在shuffer
3、groupByKey 根据key进行分组,分组后形成key,Iterator(value)格式的元组,存在shuffer
4、aggregateByKey 将分区内和分区间的计算分开,第一个参数列表传初始值,第二个参列表传递分区内和分区间计算规则,存在shuffer
5、foldByKey 作用和aggregate一样,当分区内函数和分区间函数相同时,spark提供了简化的算子foldByKey,存在shuffer
6、combineByKey 传入三个参数,第一个参数将value转换为指定数据类型,第二第三个参数表示分区内与分区间计算规则,存在shuffer
7、join 对两个不同的数据源进行自然连接,相同的key的value会连接在一起形成元组,存在shuffer
8、leftOuterJoin 左外连接,以左边的数据为主,若左边数据存在,右边数据不存在,那么形成左边数据+None的组合,存在shuffer
9、rightOuterJoin 右外连接,以右边的数据为主,若右边数据存在,左边数据不存在,那么形成右边数据+None的组合,存在shuffer
10、cogroup 首先在数据源内进行key的分组,再对两个数据源进行连接操作,存在shuffer
文章目录
转换算子
一、单value型转换算子(只使用1个RDD)
1、map
2、mapPartitions
3、mapPartitionsWithIndex
4、flatMap
5、glom
6、groupBy
7、filter
8、sample
9、distinct
10、coalesce
11、rePartition
coalesce算子和rePartition算子比较
12、sortBy
二、双value型转换算子(使用两个RDD)
1、intersection
2、subtract
3、union
4、zip
三、键值类型转换算子(数据源为键值对)
1、partitionBy
2、reduceByKey
3、groupByKey
reduceByKey与groupByKey比较
4、aggregateByKey
5、foldByKey
6、combineByKey
reduceByKey、foldByKey、aggregateByKey、combineByKey 的区别
7、join
8、leftOuterJoin
9、rightOuterJoin
10、cogroup
一、单value型转换算子(只使用1个RDD)
1、map
def map[U: ClassTag](f: T => U): RDD[U] = withScope
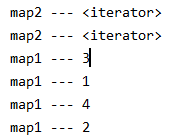
map算子将分区内的数据一个一个执行某个函数,类似串行操作,主要是将数据进行转换,数据不会增加和减少。 val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) val mapRDD: RDD[Int] = rdd.map((_: Int) * 2) 2、mapPartitions def mapPartitions[U: ClassTag]( f: Iterator[T] => Iterator[U], preservesPartitioning: Boolean = false): RDD[U] = withScopemapPartitions算子以分区为单位将一个分区内的数据进行批处理操作,传入一个迭代器,输出一个迭代器,且可以执行过滤操作,因此元素个数可能发生增加或减少。 map和mapPartitions二者性能比较:map类似串行,mapPartitions类似批处理,因此后者性能较高。但mapPartitions算子计算时将分区数据全部加载进内存,等处理完整个分区后才释放内存,因此在内存不足的情况下建议使用map。 val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) val mapRDD1: RDD[Int] = rdd.map( (num: Int) => { println("map1 --- " + num) num } ) val mapRDD2: RDD[Int] = mapRDD1.mapPartitions( (it: Iterator[Int]) => { println("map2 --- " + it) it } )
功能类似mapPartiutions算子,只是加入了每个分区的索引,可以选择性的对某些分区进行操作。 val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) val mpRDD: RDD[(Int, Int)] = rdd.mapPartitionsWithIndex( (index: Int, it: Iterator[Int]) => { it.map((index, _: Int)) } ) mpRDD.collect().foreach(println)
扁平化操作,即将集合嵌套类型的数据或者可转换为嵌套集合的类型的数据转换为非嵌套集合 val rdd: RDD[List[Int]] = sc.makeRDD(List(List(1, 2), List(3, 4))) val flatRDD: RDD[Int] = rdd.flatMap((list: List[Int]) => list) flatRDD.collect().foreach(println)
将元素合并为分区数量的数组,不需要传参数 val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) val glomRDD: RDD[Array[Int]] = rdd.glom() glomRDD.collect().foreach((list: Array[Int]) => println(list.mkString(",")))
通过给定函数计算所得key进行分组,返回一个键值对,键为key的类型,值为Iterable,该算子会将数据打乱,即会进行shuffle。shuffle过程会进行分组,但分区数不变,即一个分区可能包含多个组,示例如下 val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2) //groupBy会将数据源中的每一个数据进行分组判断,根据返回的分组key进行分组 //相同的key的值的数据会放置在一个组中 val groupRDD: RDD[(Int, Iterable[Int])] = rdd.groupBy((_: Int) % 3) groupRDD.collect().foreach(println |
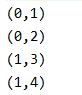
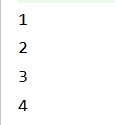
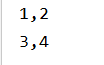
【本文地址】
公司简介
联系我们