| [领域综述] | 您所在的位置:网站首页 › sound跟listen的区别 › [领域综述] |
[领域综述]
|
1. 视听场景理解 人类对真实世界的感知涉及对多种感官数据的复杂分析,包括视觉、听觉、触觉、味觉、嗅觉以及其他感官数据。许多心理学和大脑认知研究表明,结合不同的感官数据对于人类感知至关重要。视觉和听觉作为人类感知世界最重要的两种感官,在现实世界中往往是互补的。例如,在一场音乐会场景中,同时观看乐器演出和听乐器的声音比只看或只听更能够让人们享受音乐会。乐器的视觉属性和声音属性是一种天然的对应关系,人类会无意识地将它们进行关联。因此,相对于以往的基于视觉模态的场景理解任务,联合视听两种感官信息往往比单一模态表现更准确有效。 受此启发,越来越多的研究者开始聚焦于视听场景理解这一领域的探索,这一领域的典型任务包括视听事件定位、视听视频解析、视听问答、视听分割等,本文将简单介绍一下这些任务的目标及由来,更具体的任务定义和解决方法可以参阅原论文。 由于知乎编辑器对Markdown语法的支持不够完善,图片等展示效果不佳,读者也可以选择访问 [CSDN](视听场景理解经典任务) 2. 主要任务2.1 引入声音以提升视觉场景理解感知能力1) Audio-visual Action Recognition [1] 视听行为识别任务是指从视频或音频中检测和识别人类的行为。 日常生活中的很多视频同时伴随着视觉画面和声音,以往的视频行为识别研究通常只基于视觉模态信息来探索,但是由于光照、遮挡、拍摄角度等因素会严重干扰视频行为识别模型的性能,而声音作为视频动作伴随的一种天然模态信息,可以不受上述原因干扰,与视觉模态联合使用,并有效的提升模型的识别性能。下图所示的是一个经典的视听行为识别的框架。  图1 视听行为识别任务 [1] 图1 视听行为识别任务 [1]2) Audio-visual Crowd Counting [2] 视听人群计数任务,即整合视觉和听觉信息以用于视觉人群计数,特别是极端环境下的人群计数任务。 如下图所示,从左到右分别是:低光照强噪声的输入图像、Ground truth密度图、使用视听信息预测的密度图、仅使用视觉信息的预测密度图。可以看到在这种极端环境下,融合视觉和听觉两种模态特征的计数结果要远好于只基于视觉模态的计数结果。  图2 视听人群计数任务 [2] 图2 视听人群计数任务 [2]任务提出动机:以往的基于视觉模态的人群计数研究引起了广泛的关注,但却受到遮挡、距离等极端因素而发展受限。受神经生物学的启发,环境声音可能是场景中人群计数的重要线索,即我们感知到的环境声音越大,人就越多。随着智能设备(相机、手机、监控等)的普及,视听数据可以较容易的获取,故将环境声音纳入视觉人群计数的研究有着重要的价值。同时视听人群计数的任务提出也主要回答以下几个问题: 结合来自视觉和听觉模态的特征是否比在极端条件下仅使用视觉特征进行人群计数更好?在不同的照明、噪声和遮挡条件下,视听人群计数结果如何变化?我们如何施加音频信息以有效地辅助视觉感知,即如何融合两种模态信息?3) Audio-visual Retrieval [3] Audio-visual Retrieval,即音视频检索任务,指从大量的音频或视频样本库中,根据用户提供的音频或视频查询,返回与之相关的其他音视频样本的任务。 该任务的目的是通过学习一个模型或算法,使其能够理解音视频数据之间的语义相似性,并能够根据查询找到最相关的样本。在实际应用中,音视频检索任务可以用于许多场景,例如音乐检索、视频检索、图像检索等,旨在提高用户的检索效率和准确性。 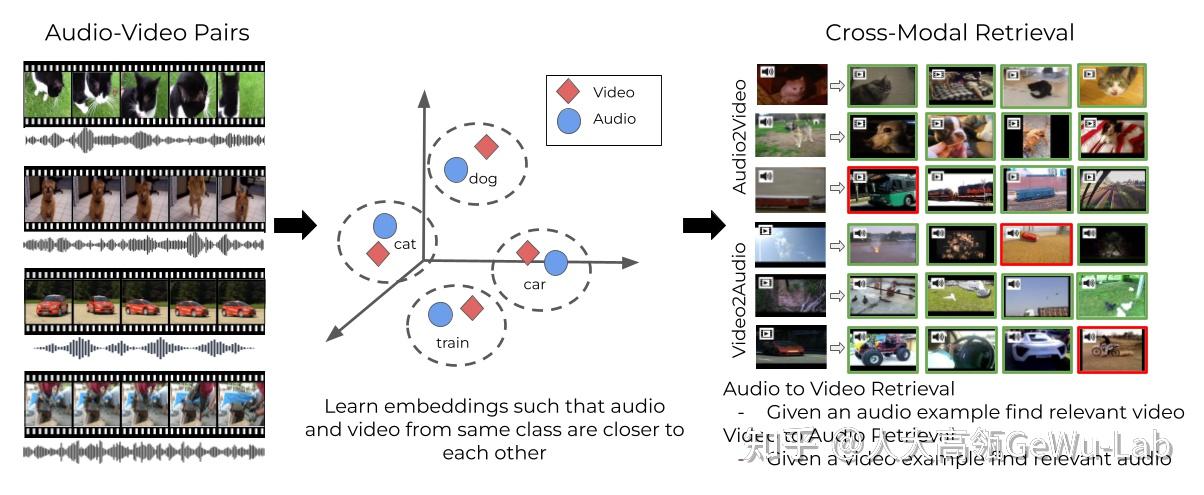 图3 Audio-visual Retrieval任务的示例 [3] 图3 Audio-visual Retrieval任务的示例 [3]在Audio-visual Retrieval任务中,一个具有代表性的工作是Image2song[4],任务定义是为图像寻找语义相关的歌曲。该任务依赖于具体的图像内容分析,属于基于语义/标签的音乐检索类别,它根据特定的准则检索适合歌曲以满足用户需求。下图展示了一个具体的示例,在一个圣诞节场景中,所拍的照片包含了盛装出席的宾客和装饰精美、挂满礼物的圣诞树,这些场景内容共同营造了一个欢乐的节日氛围。然而,照片仅仅体现在视觉模态,并不能够很好地传递上述场景所具有欢快气氛。受到大脑多通道知觉以及可视化音乐和音乐化视觉等相关研究的启发,多维度的感官刺激(如视觉、听觉和触觉等)会给人带来丰富的感官体验。如果将照片同一首应景的歌曲相结合,那么其所带来的感受就会明显提高。如下图所示,这些歌词信息包含众多同图片内容标签相同的词汇,它们被认为是二者相关的内容。因此在 Image2song 任务中,歌词被作为歌曲的文本语义源用于跨模态检索。  图4 Image2song [4] 图4 Image2song [4]Image2song任务的主要有以下两个难点:1)图像和歌曲是两种迥异的模态数据,例如前者是非时序数据而后者是时序的。更重要的是,歌词并不是为某一张图片专门编写的,这使得它们之间具有明显的内容描述鸿沟(content description gap)。2)现在并不存在有效的图像-歌曲关联数据集,这使得很难以一种数据驱动的方式进行关联学习建模。 4) Audio-visual Captioning [5] 视听视频描述任务是指通过对音视频内容的分析,从中提取关键信息,然后生成相应的文字描述。 该任务的目的是让机器能够像人一样理解音视频内容,并能够准确地描述出来。通常,音视频描述任务可以分为两种类型:一种是对视频进行描述,另一种是对音频进行描述。对于视频描述,可以提取视频中的对象、场景、动作等关键信息,并将其转化为自然语言描述;对于音频描述,则可以提取音频中的情感、语音内容等关键信息,并生成相应的文字描述。在实际应用中,音视频描述任务可以用于视频摘要生成、视频搜索、自动字幕生成、智能语音助手等方面,可以极大地提高用户的使用体验。  Audio-visual Captioning任务示例 [5]2.2 视听结合迈向更高阶的场景理解 Audio-visual Captioning任务示例 [5]2.2 视听结合迈向更高阶的场景理解1) Visual Sound Localization [6] 视听声源定位任务是在不依赖类别注释的情况下,将声音与相关视觉区域进行语义关联,即既要定位发声对象的区域,又要识别其类别。 如下图所示,在一个鸡尾酒场景里,包含了发声的吉他、发声的大提琴和没有发声的萨克斯,任务的目标是有区别的定位出发声的乐器、并过滤掉无声的乐器。  图6 视听声源定位任务 [6] 图6 视听声源定位任务 [6] 我们的日常生活由于多模态场景组成,其中声音和视觉信息最为普遍。对于人类来说,可以很自然的识别出自然视听场景中的目标是否发声,但是对于机器来说,在没有类别注释的情况下识别视听场景中的对象是否发生具有较大的挑战。 2) Audio-visual Sound Separation [7] Audio-visual Sound Separation(视听声源分离)任务旨在借助视听场景中的视觉信息分离出音轨中各个声源的声音。 人类会无意识的将不同声音及其对应的视觉目标进行关联,即使在嘈杂的环境中也是如此。如下图所示的吉他和小提琴重奏的场景中,借助吉他和小提琴的视觉信息可以帮助其各自的声音分离出来。  图7 视听声源分离 [7] 图7 视听声源分离 [7]现实世界的视听场景包含了无声物体等影响视听感知学习的挑战,如乐器多重奏场景中存在多个相同的乐器或者多个不发声的乐器、也有可能存在发声的乐器没有出现在视频画面中,这些问题和挑战为视听声源分离任务留下了很大的探索空间。 3) Audio-visual Event Localization (AVE) [8] 视听事件(AVE)被定义为视频片段中既可见又可听的事件,具体分为3个任务: 完全监督视听事件定位:预测输入视频的那个时间段具有视听事件以及该事件属于哪个类别; 弱监督视听事件定位:与监督式事件定位不同的是输入的视频标签只有video-level的; 事件不可知的跨模态定位:给定一个模态的事件片段,定位出另一个模态的事件片段。如下图所示,图1(a)展示了一个audio-visual事件,黄色框表示时序标注;图1(b)表示的是通过一个模态事件去定位事件的另一个模态的片段。  图 8 AVE事件示意图 [8] 图 8 AVE事件示意图 [8]AVE被提出的主要动机有以下几点: 对听觉和视觉模态的联合推理是否优于对它们的独立推理?在有噪音的训练条件下,结果如何变化?如何知道一种模态是否帮助了另一种模态?如何更好地融合两种模态的信息?如果通过一种模态的信息去定位出其对应的内容在另一个模态中的位置?以这几个动机为出发点,设计了上述的三种定位任务。 4) Audio-visual Video Parsing (AVVP)[9] 视听视频解析(AVVP)任务,旨在定位出视频中事件的时序边界,并将它们标记为可听、可见或两者兼之的事件。 如下图所示,一个10秒的视频中,狗在声音模态上的事件是4-8秒,在视觉模态上的事件是2-5秒,视听事件是4-5秒(该时间段内既能看见狗,又能听见狗叫)。  图 9 AVVP事件示意图 [9] 图 9 AVVP事件示意图 [9]提出AVVP任务的动机:以往的关于视听研究往往是假设时序上的事件是关联的,但是在实际场景中,很多视频中的事件只能听见其声音却没有其对应的视觉画面,同时也有很多事件只有画面没有对应的声音,或者视听事件发生的时间并不是一致的。如视频镜头外行使的汽车和人的说话声音,这样的例子无处不在。所以这就引出了一个基本问题,即一个视频中哪些事件是可听的、哪些事件是可见的、还有哪些事件是既可听又可见的,以及我们如何有效的检测这些事件在视频中的发生的时间和位置。 要探究这个问题,就要找到相关视听事件的开始和结束的时间边界,然而由于监督式学习的任务需要大量密集的标注,成本极高。故当前的AVVP任务以弱监督学习的方式开展,即对相关的数据集(LLP)的训练集只提供video-level的标注,在训练和测试集上进行second-level的标注。 5) Audio-visual Segmentation (AVS)[10] 视听分割(AVS),旨在分割出发声物,而后生成发声物的精细化分割图,其任务设置包含以下两种: 单声源(Single-source)下的视听分割多声源(Multi-sources)下的视听分割考虑到在多声源的发声物体分割比单声源更难,因此作者设置单声源在半监督条件下进行,多声源则以全监督条件进行。  图10 AVS任务的示例 [10] 图10 AVS任务的示例 [10]AVS提出的动机:截止到目前,研究者们在视听学习这一领域已经取得了较大的进展,如视听匹配、视听事件定位、声源定位等。前两者作为一个分类任务,都可以归结于给定一张图像和一段音频,判断二者是否描述同一个事件/物体;声源定位想要定位到发声物体的大致区域,趋近于目标检测,但是是以热力图可视化的形式表示定位的结果。尽管这些任务都很有趣,但都不能够很好的勾勒出物体的形状,离精细化的视听场景理解似乎还差临门一脚。为此,视听分割任务提出要准确分割出视频帧中正在发声的物体全貌,即以音频为指导信号,确定分割哪个物体并得到其完整的像素级掩码图。 6) Audio-visual Scene-Aware Dialog (AVSD)[11] 视听场景感知对话(AVSD)任务,即是通过使用自然语言回答用户关于动态场景的问题来进行对话。 如下图所示,智能体基于动态视觉场景、音频和历史对话(之前的对话轮次)来生成回应,其目标是开发一种能够感知时间动态的会话智能体,从而更好地理解场景并提供更准确的回应。回答此类问题需要全面了解场景中的视觉和音频信息,以及它们的时序关系,此外由于人类交流很少只有单轮对话,因此还需要了解对话的顺序,如"她"和“它”指的是什么。  图11 AVSD任务示例 [11] 图11 AVSD任务示例 [11]AVSD提出的动机:以视觉感知为基础的对话模型需要用自然语言进行对话回答关于图像的问题,即对于给定的问题,系统需要将其响应与输入的图像以及历史对话信息进行关联,然而静态图像缺乏上下文信息,无法进行有效的场景感知和理解。此外已有的对话系统是由用户语音输入触发的,系统响应的内容受到训练数据(一组对话)限制,而且法使用基于多模态的输入(如视觉和非语音音频)来理解动态场景,因此使用此类对话系统的机器无法就周围发生的事情进行对话。故AVSD任务的提出可以充分探索真实对话场景的感知。 7) Audio-visual Question Answering (AVQA)[12] 视听问答(AVQA)任务,旨在回答有关不同视觉对象、声音及其在视频中的关联的问题。 如下图所示的单簧管双重奏场景,当回答 “哪个单簧管先发声?”的问题时,需要在视听场景中先定位出发声的单簧管,并在时序维度上重点聚焦于哪个单簧管先发出声音。要正确回答这个问题,本质上需要有效地对视听场景理解和时空推理。对于这个例子,若我们仅考虑基于视觉模态的 VQA 模型则很难对问题中涉及的声音信息进行处理,相反,若我们只考虑基于声音模态的 AQA 模型,同样难以对问题中涉及的空间位置信息进行处理。但是,我们可以看到同时使用听觉和视觉信息可以很容易的对场景进行理解并正确的回答上述问题。  图12 AVQA任务的示例 [12] 图12 AVQA任务的示例 [12]AVQA提出的动机:近年来,研究人员在声音对象感知、音频场景分析、视听场景解析和内容描述等方面取得了显著进展。尽管这些方法能将视觉对象与声音关联,但它们中的大多数在复杂视听场景下的跨模态推理能力仍然有限。相比之下,人类可以充分利用多模态场景中的上下文内容和时间信息来解决复杂的场景推理任务,如视听问答任务等。现有的视觉问答(VQA)和声音问答(AQA)方法等往往只关注单一模态,从而不能很好的在真实的视音场景中进行复杂的推理任务。 8) Audio-visual Navigation (AVN)[13] 视听导航(AVN),即在具有视觉和声音信息的仿真3D环境中,令智能体通过接受到的视觉和声音信息,导航到声源附近。 具体来说,在一个episode(一次游戏)中,智能体的初始位置是一个陌生环境的随机位置,同时在同一环境中的某个位置也会随机生成一个声源。 智能体在每次决策时会收到一个1秒的音频(波形形式),它的目标就是导航到目标位置。由于没有全局的地图,智能体只能通过解析音频和RGB-D的图像来完成导航任务 如下左图,展示了一个室内环境的top-down map,并且在上面绘制了声压的热力图。由于反射、吸收等声学现象的存在,智能体收到的声音中编码了整个房间的几何、结构和材料信息,并且我们可以发现,音频的变化实际上很好的反映了导航的路径。从这个角度上讲,音频实际上可以帮助设置一个中间的目标(例如该图中的门就是一个很理想的中间目标)。所以在AVN导航中的基本思路是:音频用于设置目标,RGB-D用于导航过程中的避障。 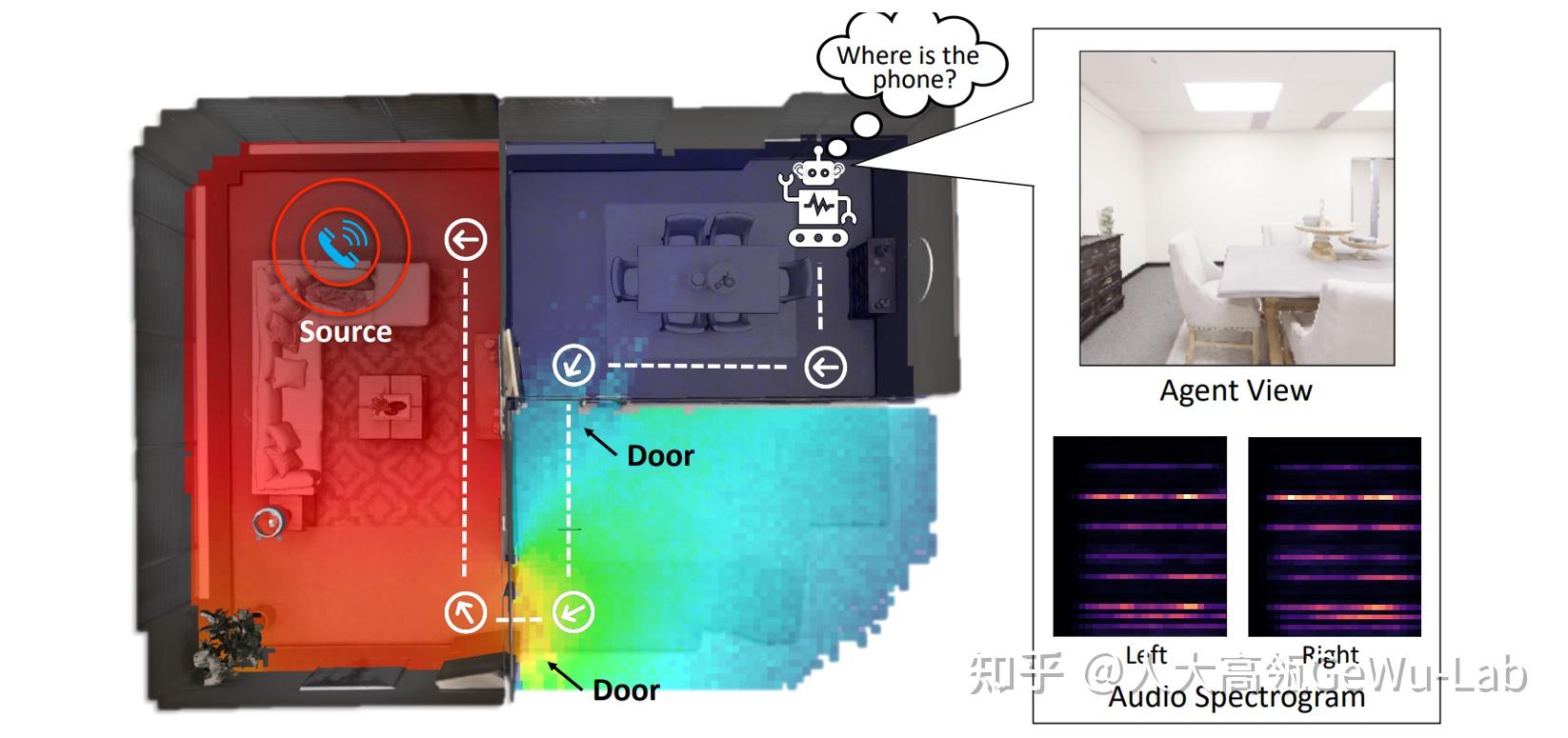 图13 AVN任务的示例 [13] 图13 AVN任务的示例 [13]AVN的动机:目前的导航任务(Object Goal Navigation,Image Goal Navigation)大多只利用视觉模态来做导航,部分工作在视觉-语言导航这一任务中展开了研究,但是它们都忽略了一个事实:在导航过程中,音频会扮演一个非常重要的角色,特别是对于视障人士以及一些利用声波导航的动物,它们可以利用声音的反馈来判断空间的几何形状、遮挡物体以及它们的材料。另外,当目标位置在可视范围之外时,如果目标物体可以发声,那么声音会是一个很好的信息载体,因为它在一定程度上揭示了目标的相对位置(例如,可以通过手机铃声找到手机的位置)。还有一点,如果视觉模态不可靠时(例如,存在灯光闪烁,这会对视觉模态的分布产生影响,从而影响视觉encoder提取的特征),听觉信息就变得非常重要。 2.3 视听融合在其他领域的探索1) Audio-visual Aerial Scene Recognition [14] 视听航空场景识别任务,即同时使用遥感图像和声音作为输入,识别空中拍摄区域的场景。 该任务主要根据观察到的某些特定的声音事件在特定的地理位置更容易被听到,故提出利用声音事件中的特征来提高空中场景识别的性能。因为很多场景的外观和其声音是密切关联的,如在火车站大概率会有广播声、露天体育馆大部分会有呼喊声等。如下图所示,同时结合视觉和声音模态可以更有效的识别出目标场景。  图14 视听航空场景识别任务 [14] 图14 视听航空场景识别任务 [14]任务提出动机:空中场景识别是遥感领域中的一项基本任务,近年来取得了显著的研究进展并受到广泛关注,但其受光照条件、季节变化等的影响比较严重,而难以突破识别瓶颈。受认知神经科学中的多通道感知理论(人类的感知通常受益于视觉和听觉知识的整合)启发,研究人员认为鸟瞰场景中的声音在一定程度上不受光照、季节等因素的影响,可以被认为空中场景识别的有利因素,故一种新的视听空中场景识别任务逐渐被关注到。 2.4 视听感知带来的社会意义1) Listen to the Image [15] 该任务主要使用视听感官替代装置通过将视觉信息转换为声音信息来帮助盲人感知视觉环境。 如何让盲人“看到”现实的世界是个有用且有挑战性的任务,已有统计表明盲人失明的主要原因是眼部疾病,其大脑皮层的视觉皮质并没有受到损伤。故依据跨模态可塑性理论让盲人通过其他感官(如耳朵)接受外界视觉信息并进行感知是有可行性的。基于此,研究者已经提出很多跨感官信息传输设备来帮助残障人士恢复感知。而这些设备被统称为感知替代设备。 如下图所示,在盲人前额挂载一个摄像头,视觉到听觉的感知替代设备(vOICe)将摄像头采集得到的图像编码为声音,并将声音传输到盲人所佩戴的耳机中进行播放。经过对设备反复的学习和训练,遮住眼的正常被试和真正盲人被试都能够通过编码的声音信号识别不同的物体。相关的神经影像研究也表明经过训练的被试在听 vOICe 编码声音时,其视觉皮质是被激活的,一些盲人被试甚至报告说他们看到了前面的物体,甚至包括物体的颜色。  图15 vOICe设备使用示意图 [15] 图15 vOICe设备使用示意图 [15]以往的基于雇佣盲人来评估vOICe 编码质量的方式存在两大问题:1)基于人类被试的评估需要进行复杂的训练和测试步骤,盲人在此过程中需要维持注意力高度集中和高压的状态很长一段时间,与人并不友好且具有低效的特征;2)需要进行大量的对比实验以保证评估结果的可靠性,但这需要很大的成本开销。随着机器学习技术的发展,机器感知模型具有的高效经济、便于使用等诸多优点可以解决了人类被试进行评估时所存在的问题。因此基于机器感知模型聚焦于视音转换编码方案的评估优化,以提升盲人视觉感知能力的研究逐步被研究人员关注。 3. 总结人类对于理解周围场景的能力是基于多种感官提供的信息的。视觉、听觉、味觉、嗅觉和触觉等感官提供不同的信息,但同时也相互补充。这种多感官的信息整合能力是人类理解周围环境的基础。例如,观看电影需要同时运用视觉和听觉来获取更全面的信息,否则无法理解电影的情节。听到救护车声音时,我们往往会自然地关注声音来源的位置,因此更容易注意到救护车的存在。设计能够理解场景的模型算法是人工智能领域中的一个基本问题。目前,视觉场景理解技术已经有了很大进展,如时序定位、视觉问答等。这些技术利用视觉算法对图像/视频进行处理,从而实现对物体、场景和事件的识别、分类和定位等。然而,这些技术通常只关注场景中的视觉信息,而忽略了其他感官提供的信息。 视觉和声音作为现实世界中天然存在的且十分重要的模态信息,如何有效的整合这两种模态信息对实现更好的场景理解有着至关重要的作用,如在视障辅助设备中,利用声音来帮助盲人理解周围环境是非常有意义的;在监控领域,利用视听信息整合技术也可以更准确地识别和跟踪目标。然而,当前视听场景理解领域还存在很多挑战。如何更好地关联视听信息、如何更好地实现跨模态信息的推理任务、如何探究视听联合学习模型中的可解释性等,都是需要探索的问题。因此,需要更多的研究人员和爱好者一起加入视听理解社区,共同推动这一领域的发展。 作者:李光耀 审校:侯文轩,胡迪 参考文献[1] R. Arandjelovic, A. Zisserman, “Look, Listen and Learn,” in Proceedings of the IIEEE International Conference on Computer Vision (ICCV), 2017, pp. 609-617. [2] D. Hu, L. Mou, Q. Wang, J. Gao, Y. Hua, D. Dou, and X. X. Zhu, “Ambient sound helps: Audiovisual crowd counting in extreme conditions,” arXiv preprint arXiv:2005.07097, 2020. [3] K. Parida, N. Matiyali, T. Guha, and G. Sharma, “Coordinated joint multimodal embeddings for generalized audio-visual zero-shot classification and retrieval of videos,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 3251–3260. [4] X. Li, D. Hu, and X. Lu, “Image2song: Song retrieval via bridging image content and lyric words,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 5649–5658. [5] Y. Tian, C. Guan, J. Goodman, M. Moore, and C. Xu, “Audio-visual interpretable and controllable video captioning,” in IEEE Computer Society Conference on Computer Vision and Pattern Recognition workshops, 2019. [6] D. Hu, R. Qian, M. Jiang, X. Tan, S. Wen, E. Ding, W. Lin, and D. Dou, “Discriminative sounding objects localization via self-supervised audiovisual matching,” Advances in Neural Information Processing Systems, vol. 33, pp. 10077–10087, 2020. [7] Y. Tian, D. Hu, and C. Xu, “Cyclic co-learning of sounding object visual grounding and sound separation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2745–2754. [8] Y. Tian, J. Shi, B. Li, Z. Duan, and C. Xu, “Audio-visual event localization in unconstrained videos,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 247–263. [9] Y. Tian, D. Li, and C. Xu, “Unified multisensory perception: Weakly-supervised audio-visual video parsing,” in Proceedings of the European Conference on Computer Vision (ECCV), 2020, pp. 436–454. [10] J. Zhou, J. Wang, J. Zhang, W. Sun, J. Zhang, S. Birchfield, D. Guo, L. Kong, M. Wang, and Y. Zhong, “Audio–visual segmentation,” in Proceedings of the European Conference on Computer Vision (ECCV), 2022, pp. 386–403. [11] I. Schwartz, A. G. Schwing, and T. Hazan, “A simple baseline for audio-visual scene-aware dialog,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 12548–12558. [12] G. Li, Y. Wei, Y. Tian, C. Xu, J.-R. Wen, and D. Hu, “Learning to answer questions in dynamic audio-visual scenarios,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 19108-19118. [13] C. Chen, U. Jain, C. Schissler, S. V. A. Gari, Z. Al-Halah, V. K. Ithapu, P. Robinson, and K. Grauman, “Soundspaces: Audio-visual navigation in 3d environments,” in Proceedings of the European Conference on Computer Vision (ECCV), 2020, pp. 17–36. [14] D. Hu, X. Li, L. Mou, P. Jin, D. Chen, L. Jing, X. Zhu, and D. Dou, “Cross-task transfer for geotagged audiovisual aerial scene recognition,” in roceedings of the European Conference on Computer Vision (ECCV), 2020, pp. 68–84. [15] D. Hu, D. Wang, X. Li, F. Nie, and Q. Wang, “Listen to the image,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 7972–7981. |
【本文地址】