| LightGBM核心解析与调参 | 您所在的位置:网站首页 › smooth算法简介 › LightGBM核心解析与调参 |
LightGBM核心解析与调参
|
导语
LightGBM 作为近两年微软开源的模型,相比XGBoost有如下优点: 更快的训练速度和更高的效率:LightGBM使用基于直方图的算法。例如,它将连续的特征值分桶(buckets)装进离散的箱子(bins),这是的训练过程中变得更快。还有一点是LightGBM的分裂节点的方式与XGBoost不一样。LGB避免了对整层节点分裂法,而采用了对增益最大的节点进行深入分解的方法。这样节省了大量分裂节点的资源。下图一是XGBoost的分裂方式,图二是LightGBM的分裂方式。 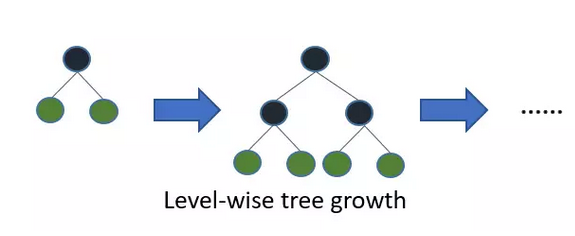
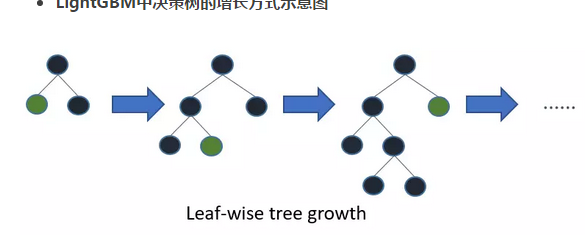
更低的内存占用:使用离散的箱子(bins)保存并替换连续值导致更少的内存占用。 更高的准确率(相比于其他任何提升算法):它通过leaf-wise分裂方法产生比level-wise分裂方法更复杂的树,这就是实现更高准确率的主要因素。然而,它有时候或导致过拟合,但是我们可以通过设置 max-depth 参数来防止过拟合的发生。 大数据处理能力:相比于XGBoost,由于它在训练时间上的缩减,它同样能够具有处理大数据的能力。 支持并行学习 LightGBM 核心参数介绍我们都知道,XGBoost 一共有三类参数通用参数,学习目标参数,Booster参数,那么对于LightGBM,我们有核心参数,学习控制参数,IO参数,目标参数,度量参数,网络参数,GPU参数,模型参数,这里我常修改的便是核心参数,学习控制参数,度量参数等。更详细的请看LightGBM中文文档 核心参数boosting:也称boost,boosting_type.默认是gbdt。 LGB里面的boosting参数要比xgb多不少,我们有传统的gbdt,也有rf,dart,doss,最后两种不太深入理解,但是试过,还是gbdt的效果比较经典稳定 num_thread:也称作num_thread,nthread.指定线程的个数。 这里官方文档提到,数字设置成cpu内核数比线程数训练效更快(考虑到现在cpu大多超线程)。并行学习不应该设置成全部线程,这反而使得训练速度不佳。 application:默认为regression。,也称objective, app这里指的是任务目标 regression regression_l2, L2 loss, alias=regression, mean_squared_error, mse regression_l1, L1 loss, alias=mean_absolute_error, mae huber, Huber loss fair, Fair loss poisson, Poisson regression quantile, Quantile regression quantile_l2, 类似于 quantile, 但是使用了 L2 loss binary, binary log loss classification application multi-class classification multiclass, softmax 目标函数, 应该设置好 num_class multiclassova, One-vs-All 二分类目标函数, 应该设置好 num_class cross-entropy application xentropy, 目标函数为 cross-entropy (同时有可选择的线性权重), alias=cross_entropy xentlambda, 替代参数化的 cross-entropy, alias=cross_entropy_lambda 标签是 [0, 1] 间隔内的任意值 lambdarank, lambdarank application 在 lambdarank 任务中标签应该为 int type, 数值越大代表相关性越高 (e.g. 0:bad, 1:fair, 2:good, 3:perfect) label_gain 可以被用来设置 int 标签的增益 (权重)valid:验证集选用,也称test,valid_data, test_data.支持多验证集,以,分割 learning_rate:也称shrinkage_rate,梯度下降的步长。默认设置成0.1,我们一般设置成0.05-0.2之间 num_leaves:也称num_leaf,新版lgb将这个默认值改成31,这代表的是一棵树上的叶子数 device:default=cpu, options=cpu, gpu 为树学习选择设备, 你可以使用 GPU 来获得更快的学习速度 Note: 建议使用较小的 max_bin (e.g. 63) 来获得更快的速度 Note: 为了加快学习速度, GPU 默认使用32位浮点数来求和. 你可以设置 gpu_use_dp=true 来启用64位浮点数, 但是它会使训练速度降低 Note: 请参考 安装指南 来构建 GPU 版本 学习控制参数 feature_fraction:default=1.0, type=double, 0.0 < feature_fraction < 1.0, 也称sub_feature, colsample_bytree 如果 feature_fraction 小于 1.0, LightGBM 将会在每次迭代中随机选择部分特征. 例如, 如果设置为 0.8, 将会在每棵树训练之前选择 80% 的特征 可以用来加速训练 可以用来处理过拟合 bagging_fraction:default=1.0, type=double, 0.0 < bagging_fraction < 1.0, 也称sub_row, subsample 类似于 feature_fraction, 但是它将在不进行重采样的情况下随机选择部分数据 可以用来加速训练 可以用来处理过拟合 Note: 为了启用 bagging, bagging_freq 应该设置为非零值 bagging_freq: default=0, type=int, 也称subsample_freq bagging 的频率, 0 意味着禁用 bagging. k 意味着每 k 次迭代执行bagging Note: 为了启用 bagging, bagging_fraction 设置适当 lambda_l1:默认为0,也称reg_alpha,表示的是L1正则化,double类型 lambda_l2:默认为0,也称reg_lambda,表示的是L2正则化,double类型 cat_smooth: default=10, type=double 用于分类特征 这可以降低噪声在分类特征中的影响, 尤其是对数据很少的类别 度量函数 metric: default={l2 for regression}, {binary_logloss for binary classification}, {ndcg for lambdarank}, type=multi-enum, options=l1, l2, ndcg, auc, binary_logloss, binary_error … l1, absolute loss, alias=mean_absolute_error, mae l2, square loss, alias=mean_squared_error, mse l2_root, root square loss, alias=root_mean_squared_error, rmse quantile, Quantile regression huber, Huber loss fair, Fair loss poisson, Poisson regression ndcg, NDCG map, MAP auc, AUC binary_logloss, log loss binary_error, 样本: 0 的正确分类, 1 错误分类 multi_logloss, mulit-class 损失日志分类 multi_error, error rate for mulit-class 出错率分类 xentropy, cross-entropy (与可选的线性权重), alias=cross_entropy xentlambda, “intensity-weighted” 交叉熵, alias=cross_entropy_lambda kldiv, Kullback-Leibler divergence, alias=kullback_leibler 支持多指标, 使用 , 分隔总的来说,我还是觉得LightGBM比XGBoost用法上差距不大。参数也有很多重叠的地方。很多XGBoost的核心原理放在LightGBM上同样适用。 同样的,Lgb也是有train()函数和LGBClassifier()与LGBRegressor()函数。后两个主要是为了更加贴合sklearn的用法,这一点和XGBoost一样。 GridSearch 调参GridSearch 我在这里有介绍,可以戳进去看看。我主要讲讲LGBClassifier的调参用法。 数据我上传在这里:直接上代码! import pandas as pd import lightgbm as lgb from sklearn.model_selection import GridSearchCV # Perforing grid search from sklearn.model_selection import train_test_split train_data = pd.read_csv('train.csv') # 读取数据 y = train_data.pop('30').values # 用pop方式将训练数据中的标签值y取出来,作为训练目标,这里的‘30’是标签的列名 col = train_data.columns x = train_data[col].values # 剩下的列作为训练数据 train_x, valid_x, train_y, valid_y = train_test_split(x, y, test_size=0.333, random_state=0) # 分训练集和验证集 train = lgb.Dataset(train_x, train_y) valid = lgb.Dataset(valid_x, valid_y, reference=train) parameters = { 'max_depth': [15, 20, 25, 30, 35], 'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15], 'feature_fraction': [0.6, 0.7, 0.8, 0.9, 0.95], 'bagging_fraction': [0.6, 0.7, 0.8, 0.9, 0.95], 'bagging_freq': [2, 4, 5, 6, 8], 'lambda_l1': [0, 0.1, 0.4, 0.5, 0.6], 'lambda_l2': [0, 10, 15, 35, 40], 'cat_smooth': [1, 10, 15, 20, 35] } gbm = lgb.LGBMClassifier(boosting_type='gbdt', objective = 'binary', metric = 'auc', verbose = 0, learning_rate = 0.01, num_leaves = 35, feature_fraction=0.8, bagging_fraction= 0.9, bagging_freq= 8, lambda_l1= 0.6, lambda_l2= 0) # 有了gridsearch我们便不需要fit函数 gsearch = GridSearchCV(gbm, param_grid=parameters, scoring='accuracy', cv=3) gsearch.fit(train_x, train_y) print("Best score: %0.3f" % gsearch.best_score_) print("Best parameters set:") best_parameters = gsearch.best_estimator_.get_params() for param_name in sorted(parameters.keys()): print("\t%s: %r" % (param_name, best_parameters[param_name])) |
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |