| MongoDB Change Streams性能优化实践 | 您所在的位置:网站首页 › slowest的中文 › MongoDB Change Streams性能优化实践 |
MongoDB Change Streams性能优化实践

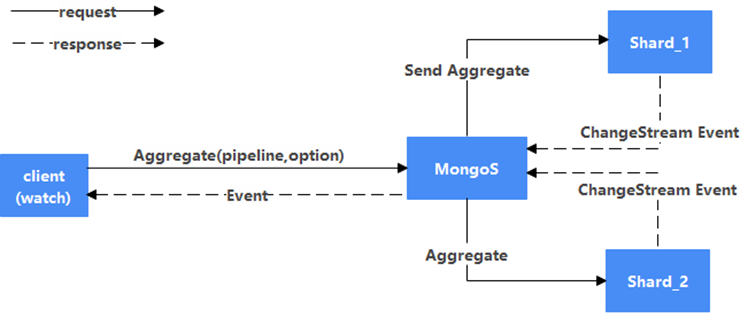
简介:基于MongoDB的应用程序通过Change Streams功能可以方便的实现对某个集合,数据库或者整个集群的数据变更的订阅,极大的方便了应用对数据库变化的感知,但是当前Change Streams对部分数据的变化并没有提供对应的事件(创建索引,删除索引,shardCollection)等,本文介绍一种新的事件订阅方式,来完善上述不足,并探讨通过并发预读的方式,来提升原生Change Streams的性能。本功能已在华为云 MongoDB 上实现。 一、前言 MongoDB作为一款优秀的NOSQL数据库,支持海量存储,查询能力丰富以及优秀的性能和可靠性,当前大部分云厂商都提供了兼容MongoDB协议的服务,用户使用广泛,深受国内外用户和企业的认可。 MongoDB从3.6版本开始提供了Change Stream特性,通过该特性,应用程序可以实时的订阅特定集合、库、或整个集群的数据变更事件,相比该特性推出之前通过监听oplog的变化来实现对数据变更的感知,非常的易用,该特性同时支持副本集和集群场景。 Change Streams功能目前支持大部分数据操作的事件,但是对于与部分其他操作,如创建索引,删除索引,ColMod, shardCollection并不支持,而且目前Change Streams内部实现是通过Aggregate命令的方式完成的, 对于分片集群场景下, 在mongos节点是通过单线程汇聚的方式完成从shard节点上oplog的拉取和处理,当实例写入压力很大的情况下,感知数据的实时变化会有延迟,性能有待提升,对于ChangeStreams目前的性能问题,官方也有过探讨https://jira.mongodb.org/browse/SERVER-46979。 本文通过深入分析当前的Change Stream实现机制,结合客户实际使用场景,提出了一种新的多并发预读的事件监听方式,来解决上述问题,并应用到客户实际迁移和数据库容灾的场景中。 二、Change Steams 机制介绍 Change Streams支持对单个集合,DB,集群进行事件订阅,当业务程序通过watch的方式发起订阅后,背后发生了什么,让我们一起来分析一下。 Change Streams内部实现是通过Aggregate的方式实现的,所以watch背后,对应的是客户端向MongoDB Server发起了一个Aggregate命令,且对Aggregate的pipeline 参数中,添加了一个$changeStream的Stage, 结合客户端其他参数,一起发给MongoDB Server。
当Mongo Server收到Aggregate命令后,解析后,会根据具体的请求,组合一个新的Aggregate命令,并把该命令发给对应的Shard节点,同时会在游标管理器(CursorManger)中注册一个新的游标(cursor),并把游标Id返回给客户端。 当Shard Server端收到Aggregate命令后,构建pipeline流水线,并根据pipeline参数中包括了Change Steams参数,确定原始扫描的集合为oplog,并创建对该集合上扫描数据的原始cursor, 和对应的查询计划执行器(PlanExecutor),构建PlanExecutor时候,用了一个特殊的执行Stage, 即ProxyStage完成对整个Pipeline的封装,此外也会把对应的游标ID返回给Mongos节点。 客户端利用从Mongos节点拿到游标ID, 在该游标上不断的执行getMore请求,服务端收到getMore请求后,最后通过cursor的next调用,转发请求到shard节点,拿到数据后,归并后返回可客户端,完成了整个Change Streams事件的订阅。 Shard上pipeline具体执行的细节不在本文重点介绍范围,这些就不详细展开了。 原生Change Stream目前使用上有如下限制: 1. 支持DDL事件不完善Change Stream目前支持的事件如下: Insert Event Update Event Replace Event Delete Event Drop Event Rename Event DropDatabase Event invalidate Event显然上述事件并没有完全覆盖MongoDB内部全部的数据变更的事件。 此外,对于在集合上监听的Change Streams, 当出现集合或者所属的DB被删除后,会触发一个invalidate Event, 该事件会把Change Streams的cursor关闭掉,导致Change Streams无法继续进行,对于通过Change Streams来实现容灾的场景,显然是不够友好的,需要重新建立新的Change Streams监听。 2. 事件拉取性能有待提升如上述分析,当前的Change Streams请求发到Mongos节点后,通过单线程的方式向每个Shard节点发送异步请求命令来完成数据的拉取,并做数据归并,如果将该方式替换为多线程并发拉取,对于分片表来说,性能会有提升。
三、 华为云并行Change Streams架构和原理 3.1 并发Change Streams架构介绍 针对上述的一些使用限制,华为云结合实际客户使用需求,提出一种新的并发Change Streams(Parallel Change Streams)的方式,来尝试解决上述问题。
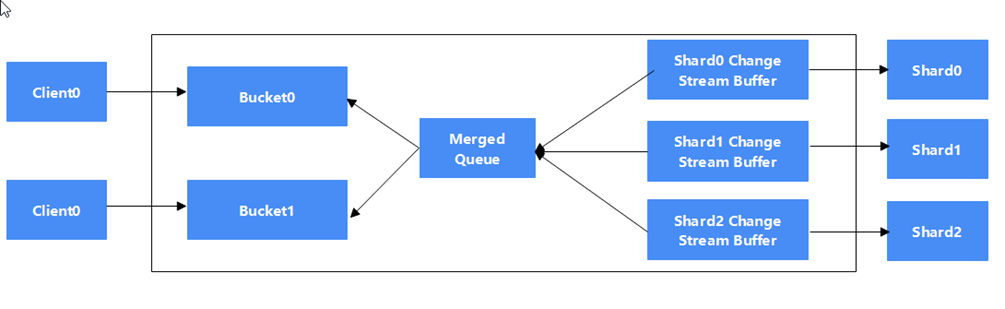
为了提升原生Change Streams的性能,我们在Mongos 节点引入如下几个新的组件: Change Streams Buffer 与Shard是一对一的关系。每个Change Streams Buffer 默认1GB,在Buffer满之前,该Buffer无条件的向对应的Shard(secondary节点)拉取Change Streams数据。 Merged Queue Merged Queue是一个内存队列,是Change Streams Buffer的消费者,是 Bucket的生产者。Merged Queue 归并所有Shard的Change Streams Buffer,并等待合适的时机按照规则放入对应Client的Bucket。 Bucket Bucket 是一个内存队列,是MergedQueue的消费者,是Client的生产者。每个Client对应一个Bucket。每个Bucket维护该Bucket内所有文档的的集合。 Merged Queue 与Bucket的交互过程 Merged Queue不停的从头部拿出尽可能多的数据,并从前往后的按照hash(document.ns)%n的规则放入对应的Bucket, document.ns是指这个文档的NameSpace, 所以同一个集合的数据一定在一个Bucket里面。 3.2 对DDL事件的增强 并发Change Stream除了支持原生的Change Stream外,还新增支持如下事件: CreateCollection Event CollMod Event CreateIndex Event Drop Index Event CreateView Event DropView Event ShardCollection Event本文以ShardCollection为例来说明如何实现新增DDL事件的支持: 当执行ShardCollection命令的时候,Config节点会向该集合的主Shard发送一个shardsvrShardCollection命令,主Shard收到改请求后,我们在该命令的处理流程中记录了一个type为noop的oplog, 并把该命令的详细内容写入到oplog的o2字段里面,以此来实现shardcollecton事件的追踪。 之后在处理Change Streams流程的pipeline中,我们对noop事件进行分析,如果其中内容包括了shardCollection事件相关的标记,则提取该事件,并返回给上层。 3.3 如何使用 1 如果想创建并发change Stream,需要先通过如下命令创建bucket和cursor: db.runCommand( { parallelChangeStream: 1, nBuckets: Required,, nsRegex: Optional,, startAtOperationTime: Optional,, })参数说明如下: parallelChangeStream :开启并行changeStream nBuckets:要创建的bucket的数目 nsRegex:可选,定义要订阅的集合,一个正则表达式。 startAtOperationTime:可选,表示订阅的事件从哪个时间点开始。 返回值: "cursors" : [ NumberLong("2286048776922859088"), NumberLong("2286048779108179584"), NumberLong("2286048780088774662"), NumberLong("2286048777169702425"), NumberLong("2286048779233363970"), NumberLong("2286048779250024945"), NumberLong("2286048776628281242"), NumberLong("2286048778209018113"), NumberLong("2286048778833886224"), NumberLong("2286048777951363227") ]Cursors :返回的Mongos侧的Cursor ID。 当获取到所有Cursor ID后,客户端就可以并发的(每个CursorId一个线程)通过getMore命令不断的从服务端拉取结果了。 断点续传ParallelChangeStream的断点续传通过startAtOperationTime实现,由于每个cursor的消费进度不一样,恢复的断点应该选用n个cursor的消费值的最小值。 四、性能对比 针对新的Parallel Change Stream和原生的Change Streams ,我们做了较长时间的对比测试分析,所有测试场景采用的测试实例如下: 实例规格:4U16G, 2个Shard(副本集) ,2个Mongos, 磁盘容量:500G 测试数据模型:通过YCSB 预置数据,单条记录1K , 单个分片表1000w条记录。 下面分几个场景分别介绍: 1. 集群模式1分片表场景测试测试方法: 1) 创建一个Hash分片的集合,预置16 Chunk 2) 启动YCSB , 对该集合进行Load数据操作,Load数据量为1000w ,设置的Oplog足够大,保证这些操作还在Oplog中 3) 分别启动原生Change Streams 和 Parallel Change Streams,通过指定startAtOperationTime来观察订阅1000w条记录分别需要花费的时间。 4) 由于是单个表, nBuckets 为1 测试数据如下: 读取总数据量 花费总时间(ms) TPS(个/s) Change Streams 1000w 432501 23148 Parallel Change Streams(1 bucket) 1000w 184437 54361 2. 集群模2分片表场景测试测试方法: 1) 创建2个Hash分片的集合,预置16 Chunk 2) 启动YCSB , 同时对这2个集合进行Load数据操作,每个集合Load数据量为1000w ,设置的Oplog足够大,保证这些操作还在Oplog中 3) 分别启动原生Change Streams和Parallel Change Streams,通过指定startAtOperationTime来观察订阅4000w条记录分别需要花费的时间。 4) 由于是2个表, nBuckets 为2 测试数据如下: 读取总数据量 花费总时间(ms) TPS(个/s) Change Streams 4000w 2151792 18484 Parallel Change Streams 4000w 690776 55248 3. 集群模式4分片表场景测试测试方法: 1) 创建4个Hash分片的集合,预置16 Chunk 2) 启动YCSB , 同时对这4个集合进行Load数据操作,每个集合Load数据量为1000w ,设置的Oplog足够大,保证这些操作还在Oplog中 3) 分别启动原生Change Streams和Parallel Change Streams,通过指定startAtOperationTime来观察订阅4000w条记录分别需要花费的时间。 4) 由于是4个表, nBuckets 为4 测试数据如下: 读取总数据量 花费总时间(ms) TPS(个/s) Change Streams 4000w 2151792 18596 Parallel Change Streams 4000w 690776 56577总结:通过实际测试可以看出来, Parallel Change Streams这种方式性能有极大的提升,实际上我们后续根据实例规格,通过调整内部Bucket和Buffer的缓存大小,性能还可以继续提升,同时随着分片表数据量和Shard节点数量的变多,和原生Change Streams 的性能优势会更加明显。 五、并发Change Streams使用场景分析 并发Change Streams非常适合在MongoDB集群的容灾场景,应用可以有针对性的设置对特定的集合或者DB进行监听,可以实时的感知到源端实例的数据变化,并快速的应用到目标端,整体实现较低RPO。 此外,并发Change Streams也可以应用到PITR场景中, 通过并发Change Streams良好的性能,实时实现动态数据的跟踪并记录,使得PITR的可恢复时间更短。 六、未来展望 当前的并行Change Streams的实现中,merge queue中的事件分发到bucket的事件中,我们采用的策略是基于事件的NameSpace的HASH值,传递给对应的bucket中,这种策略对于单集合的场景,性能优化有限,后续我们计划同时提供基于事件的ID内容的HASH值,把事件分发到不同的bucket中,这种方式能进一步的提升系统并发性能,带来更好的性能优化效果。 七、总结 通过引入一种新的并发Change Streams的方式,支持更多类别的MongoDB事件的订阅,同时在事件监听的性能方面相比原生有较大的提高,可以广泛应用在数据库实例容灾, PITR,数据在线迁移业务场景中,为客户带来更好的体验。 作者:华为云DDS内核组,华为云DDS内核组致力于提供高性能的云原生文档数据库。 也许您想阅读更多>>> MongoDB复制技术内幕 MongoDB 事务,复制和分片的关系 WiredTiger的时间戳事务设计及其正确性证明
添加小芒果微信(ID:mongingcom)进入中文用户组技术交流群。 来这里,点亮自己! MongoDB中文社区技术大会议题征集中,打开链接来这里分享经验与见解—— https://sourl.cn/f7Bgsf 活动资料发布消息订阅: https://sourl.cn/DgdiNd 点击申请加入核心用户组: https://sourl.cn/u8W8FU 获取MongoDB免费线上培训入口及配套资料: https://sourl.cn/EtVUrP 我们还将在上海广州深圳南京成都等城市举办技术大会,有合作意向请提前联系小芒果微信或社区核心成员。
 Tapdata DaaS – 一站式实时数据服务平台 (tapdata.net)
Tapdata Cloud – 免费在线异构数据库实时同步工具(cloud.tapdata.net)
Tapdata DaaS – 一站式实时数据服务平台 (tapdata.net)
Tapdata Cloud – 免费在线异构数据库实时同步工具(cloud.tapdata.net)
 长按二维码关注我们 Mongoing中文社区 MongoDB中文社区微信公众号 扫描关注,获取更多精彩内容 社区网站www.mongoing.com |



【本文地址】