| Scikit–Learn数据挖掘 | 您所在的位置:网站首页 › sklearn实战 › Scikit–Learn数据挖掘 |
Scikit–Learn数据挖掘
|
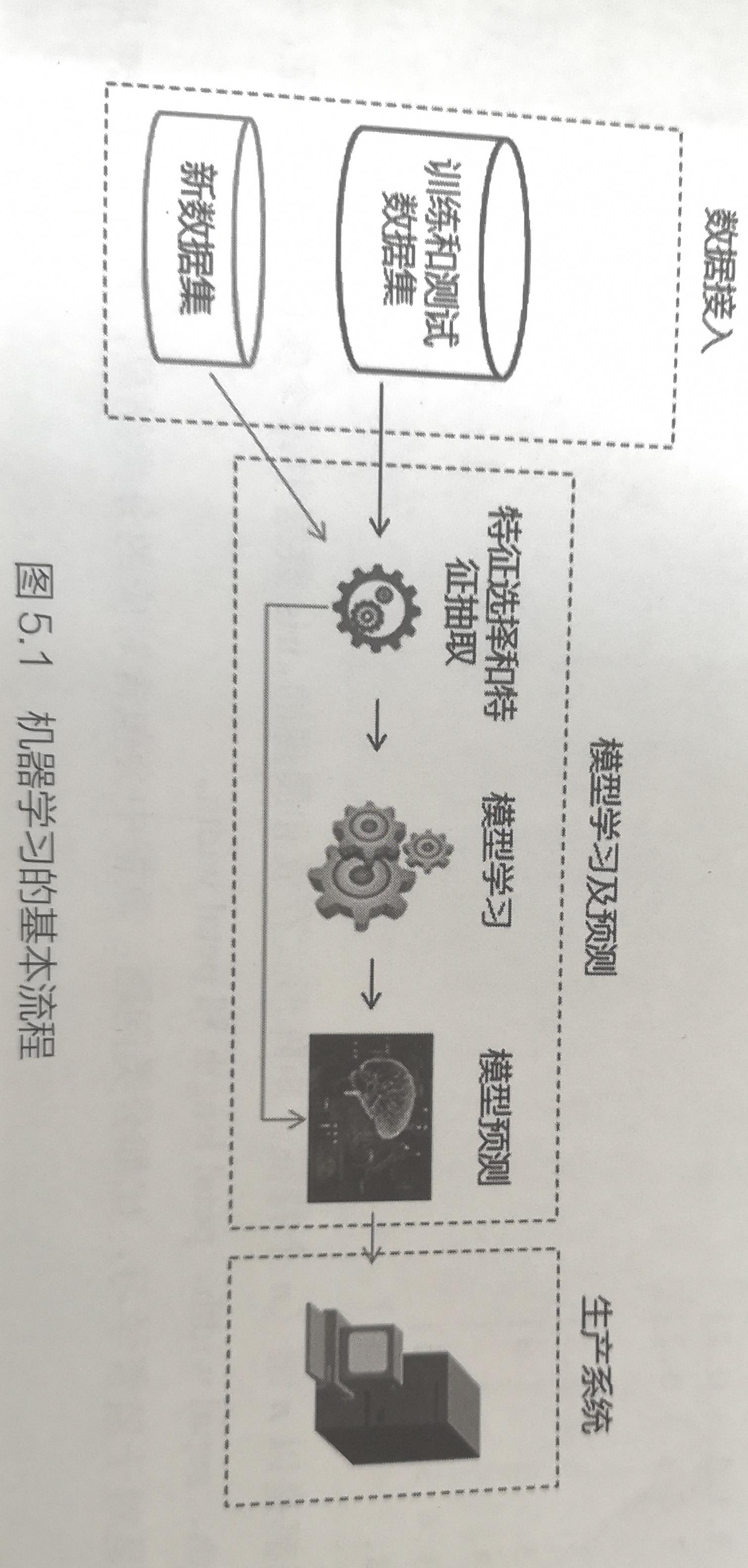
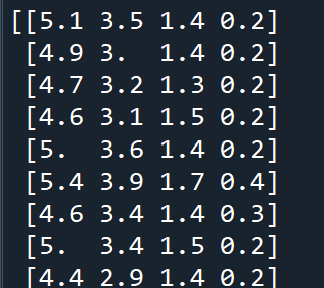
Scikit-Learn是一个紧密结合Python科学计算库(Numpy,Scipy,Matplotlib),集成经典机器学习算法的python模块,其最大的特点是:为用户提供各种各种机器学习的算法接口,可以让用户简答,高效的进行数据挖掘和数据分析,本篇主要记录如何利用SciKit-Learn工具箱进行机器学习的基本流程 S.1 机器学习问题 一般机器学习可以这样理解:假如我们有n个样本的数据集,想要预测未知数据的属性,如果描述每个样本的数字不止一个,比如一个多维数组的条目(也叫作多变量数据),那么这个样本就有多个属性或特征 我们可以将学习问题分为两类:有监督机器学习&&无监督机器学习 有监督学习指数据集中原本就包括了我们将要预测的属性,有监督学习问题一般有两个分类 1.分类:样本属于两个或多个类别,我们希望通过从已有标识类别的数据中学习,来预测未标记数据的分类。eg识别手写数字就是一个分类问题,其目标是将每个输入向量对应到有穷的数字类别 2.回归:如果希望输出的是一个或多个连续变量,那么这项任务叫做“回归”,eg. 根据时间,气候,云层,风速等来预测明天的气温 无监督学习的训练数据包括了输入向量X的集合,但没有相对应的目标变量,这类问题的目标可以是 1.发掘数据中相似样本的分组,称作“聚类” 2.确定输入样本空间中的数据分布,称作“密度估计”, 还可将数据从高维度投射到二维或三维空间,以便数据可视化 S2.机器学习基本流程 首先载入分析数据集 然后调用SciKit-Learn工具箱中的机器学习模型进行学习和预测 最后部署模型并对接生产系统进行应用 S3。数据处理【数据接入,数据集分割,】 数据处理是数据挖掘中最重要,最基础的一环,包括数据字段清洗,缺失值和极端值处理、训练和测试数据划分等,下面主要记录如何把待分析的数据集载入python,如何对数据集进行操作,以满足机器学习算法的需要 S3.1数据接入 方法很多,和实际业务紧密联系,如果数据存储在Oracle数据库中,则需要利用python连接数据库,如果数据已csv格式存在本地,则可以直接利用Pandas库的read_csv函数进行数据读取 根据数据源的不同,载入数据集的方法也不同,下面记录通过Scikit-Learn自带的标准数据集来说明,以自带的数据采集iris为例来说明, Scikit-Learn载入数据集的代码如下 from sklearn import datasetsiris = datasets.load_iris() #Scikit-Learn载入数据集 Scikit-Learn载入的数据集以类似字典的形式存放该对象中包含了所有有关该数据的数据信息,其中的数据值统一存放在.data的成员中,若需要将iris数据显示出来,只需显示iris的data成员 print(iris.data) #显示iris数据(只需显示iris的data成员) 数据都是以n维(n个特征)矩阵形式存放和展现的,iris数据中每个实例有四个特征,分别为:sepal length ,sepal width,petal length ,petal width 对于监督学习,比如分类问题,数据中包含对应的分类结果,其存在.target成员中, print(iris.target) #查看iris.target的分类标签数据 S3.2数据集分割 在进行建模时,一般会把数据集分为训练数据集和测试数据集,目的是为了在数据集上拟合模型儿在测试数据集上测试模型的性能,以便获取一个最佳的模型结果 Scikit-Learn中对一个整理好的数据集进行划分用的是 train_test_split函数,调用形式如下 x_train,x_test,y_train,y_test =cross_validation.train_test_split(train_data, #要分割的数据集train_target,#目标变量test_size = 0.4,#测试数据集的样本占比train_size = 0.6,#训练数据集的样本占比random_state = 0 #随机数种子,不同的种子会造成不同的随机采样结果,相同的种子采样结果相同) 案例 import numpy as npfrom sklearn.model_selection import train_test_splitx,y = np.arange(10).reshape((5,2)),range(5)print(x)print(y)运行结果: [[0 1] [2 3] [4 5] [6 7] [8 9]]range(0, 5) 下面使用函数train_test_split进行数据分割,比如 测试数据抽取30%,具体代码如下 X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.3,random_state = 12345)print('X_train结果:')print(X_train)print('X_test结果:')print(X_test)print('y_train结果:')print(y_train) print('y_test结果:') print(y_test) #运行结果X_train结果:[[6 7] [2 3] [4 5]]X_test结果:[[0 1] [8 9]]y_train结果:[3, 1, 2]y_test结果:[0, 4] 再比如,对Scikit-Learn自带的数据集iris进行分割,并进行建模,程序如下: 首先导入数据 import numpy as npfrom sklearn import model_selectionfrom sklearn import datasetsfrom sklearn import svm#下载iris数据集iris = datasets.load_iris()#获取数据集iris的结构iris.data.shape,iris.target.shapeprint(iris.data.shape)print(iris.target.shape) 运行结果,数据集有150个样本,4个自变量,1个目标变量 (150,4) (150,) 接着对数据集进行分割,测试占30%,训练70%代码如下 #调用train_test_split分割数集irisX_train,X_test,y_train,y_test = model_selection.train_test_split(iris.data,iris.target,test_size = 0.3,random_state = 0)print(X_train.shape,y_train.shape)print(X_test.shape,y_test.shape) 运行结果,训练数集有105个样本,测试45个 (105, 4) (105,)(45, 4) (45,) 最后,调用支持向量机模型接口,在训练数集上进行模拟训练,并对数据集进行模型性能测试,代码如下 #调用SVM模型进行学习clf = svm.SVC(kernel = 'linear',C = 1).fit(X_train,y_train)#计算在测试集上模型准确率clf.score(X_test,y_test)print(clf.score(X_test,y_test)) 运行结果,正确率约为97.8% 0.9777777777777777
#代码print("早点睡觉不然会死掉!")
|

【本文地址】