| 机器学习之逻辑回归 | 您所在的位置:网站首页 › sigmoid函数用于分类问题还是回归问题 › 机器学习之逻辑回归 |
机器学习之逻辑回归
|
1.逻辑回归介绍
逻辑回归是一种常用的统计学习方法,通常用于处理分类问题。尽管名字中包含"回归"一词,但逻辑回归实际上用于解决分类问题,而不是回归问题。逻辑回归的基本思想是通过一个称为"逻辑函数"或"sigmoid函数"的特定函数来建立分类模型。
2.sigomid函数
a.公式 代码解释 先假设一个输入,用数组theta来存储0.初始值全部赋值为θ,从0开始使用梯度上升进行修改。 第一个for循环表示的是不断进行迭代,就是累次进行梯度上升。内部的for循环就是对θ的每个值进行修改。theta[j] += alpha*(np.sum((y - h) * X[:, j]) / m)就是套用上面给定的参数更新公式进行迭代。 4.实验 a.数据集获取和处理 使用鸢尾花数据集鸢尾花数据集的"Sepal.Length" "Sepal.Width" 两列来代表二维坐标轴的横纵坐标。由于是二分类问题所以选择,鸢尾花数据集中的setosa和versicolor类别。为了方便将versicolor赋值为0,setosa赋值为1。对迭代次数赋值为1000,步长alafa赋值为0.01。 代码展示data = pd.read_csv(r"C:\Users\林硕\Desktop\ljhg.txt", sep=' ') X = data.iloc[:, :2].values y1 = data.iloc[:, -1].values print(X); len1=len(y1); y=np.zeros(len1); for i in range(len1): if y1[i] == 'setosa': y[i]=1 if y1[i] == 'versicolor': y[i]=0 print(y) X = np.c_[np.ones(X.shape[0]), X] num = 1000 alafa = 0.1 2.散点图
思路:
用plt.rcParams['font.sans-serif'] = ['SimHei']使得图像上面可以正常显示中文。用plt.scatter将数据中的点都画到图上
代码展示:plt.rcParams['font.sans-serif'] = ['SimHei']
plt.scatter(X[:, 1], X[:, 2], c=y, cmap='viridis')
plt.xlabel('Sepal.Length')
plt.ylabel('Sepal.Width')
plt.title('散点图')
plt.show() 4.利用逻辑回归进行分类
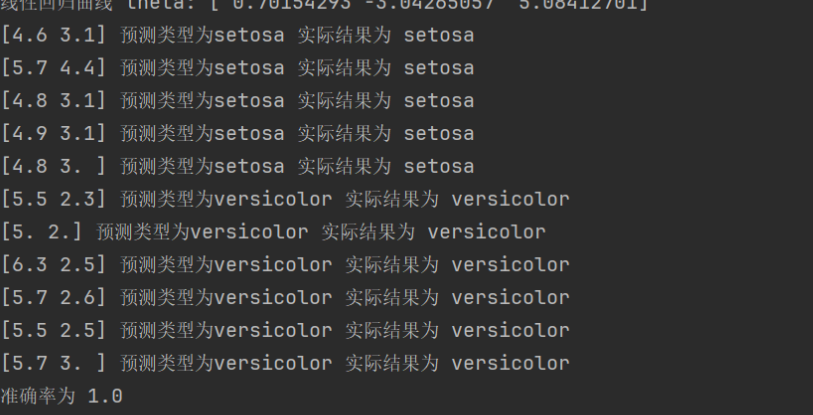
思路:导入测试集处理数据,将每个数据代入线性回归方程,对得到的值再带入sigmoid函数上映射到0,1上。大于0.5就是正,小于就是负。分类正确就记录下来从而统计准确率
代码展示
test_data = pd.read_csv("C:\Users\林硕\Desktop\ljhgtest.txt", sep='\s+')
X_test = test_data[["Sepal.Length", "Sepal.Width"]].values
y_test = test_data["Species"].values
cnt=len(y_test)
print(X_test[1][0])
num=0
for i in range(cnt):
t = theta[0] + theta[1] * X_test[i][0] + theta[2] * X_test[i][1]
res1 = res1 = sigmoid(t)
print(X_test[i],end=' ')
flag=0
if res1 >= 0.5 :
flag=1
print(f"预测类型为setosa",end=' ')
else :
print(f"预测类型为versicolor",end=' ')
print("实际结果为",y_test[i])
if flag1 and y_test[i]'setosa':
num=num+1
if flag0 and y_test[i]'versicolor':
num=num+1
print("准确率为",num/cnt)
6.实验中的问题 1.学习率的选取上需要选择合适的数据,太大太小都会影响程序的准确率。 2.逻辑回归实际上就是线性回归加上sigmoid的函数,但是在实验的过程中线性回归得到的只有一个类别的拟合函数而逻辑回归得到的是多个类别分开的曲线。 3.实验中容易出现过拟合欠拟合的问题 需要通过交叉验证、正则化等方法来解决。 5.总结 逻辑回归优缺点 优点: 简单而高效:逻辑回归模型相对简单,易于实现和理解,训练速度快,适用于大规模数据集。 输出结果具有概率意义:逻辑回归输出的结果可以被解释为属于某个类别的概率,便于理解和解释模型的预测结果。 对线性可分问题表现良好:在线性可分的情况下,逻辑回归能够取得很好的分类效果。 缺点: 对非线性数据拟合能力有限:逻辑回归假设了特征之间是线性相关的,对于非线性关系的数据拟合能力有限。 容易受到特征相关性影响:当特征之间存在较强的相关性时,逻辑回归模型可能会表现不稳定,导致模型性能下降。 需要处理高维度特征:在高维度特征空间下,逻辑回归模型容易出现过拟合的问题,需要进行特征选择或者正则化处理。 总实验代码import numpy as np import pandas as pd import matplotlib.pyplot as plt def sigmoid(z): return 1.00 / (1.00 + np.exp(-z)) def sr(X, y, theta): m = len(y) h = sigmoid(X.dot(theta)) res = (1 / m) * (y.dot(np.log(h)) + (1 - y).dot(np.log(1 - h))) return res def td(X, y, num_iterations, alpha): m, n = X.shape theta = np.zeros(n) for iteration in range(num_iterations): h = sigmoid(np.dot(X, theta)) for j in range(n): theta[j] += alpha*(np.sum((y - h) * X[:, j]) / m) return thetadata = pd.read_csv(r"C:\Users\李烨\Desktop\ljhg.txt", sep=' ') X = data.iloc[:, :2].values y1 = data.iloc[:, -1].values print(X) len1 = len(y1) y=np.zeros(len1) for i in range(len1): if y1[i] == 'setosa': y[i]=1 if y1[i] == 'versicolor': y[i]=0 print(y) X = np.c_[np.ones(X.shape[0]), X] num = 1000 alafa = 0.1 theta = td(X, y, num, alafa) print("线性回归曲线 theta:", theta) plt.rcParams['font.sans-serif'] = ['SimHei'] plt.scatter(X[:, 1], X[:, 2], c=y, cmap='viridis') plt.xlabel('Sepal.Length') plt.ylabel('Sepal.Width') plt.title('散点图') plt.show() xi = np.linspace(np.min(X[:, 1]), np.max(X[:, 1]), 100) yi = -(theta[0] + theta[1] * xi) / theta[2] plt.scatter(X[:, 1], X[:, 2], c=y, cmap='viridis') plt.plot(xi, yi, "r-", label='线性回归曲线') plt.xlabel('Sepal.Length') plt.ylabel('Sepal.Width') plt.title('鸢尾花数据集二分类') plt.legend() plt.show() test_data = pd.read_csv("C:\Users\李烨\Desktop\ljhgtest.txt", sep='\s+') X_test = test_data[["Sepal.Length", "Sepal.Width"]].values y_test = test_data["Species"].values cnt=len(y_test) print(X_test[1][0]) num=0 for i in range(cnt): t = theta[0] + theta[1] * X_test[i][0] + theta[2] * X_test[i][1] res1 = sigmoid(t) print(X_test[i],end=' ') flag=0 if res1 >= 0.5 : flag=1 print(f"预测类型为setosa",end=' ') else : print(f"预测类型为versicolor",end=' ') print("实际结果为",y_test[i]) if flag1 and y_test[i]'setosa': num=num+1 if flag0 and y_test[i]'versicolor': num=num+1 print("准确率为",num/cnt) |
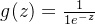 z的取值为负无穷到正无穷,相对应的函数的取值为[0,1]通过这个函数可以将任意值映射到[0,1],在此基础上我们给定一个阈值,如果大于该阈值就判断为正类,否则负类,这样就可以进行分类预测。sigmoid函数在机器学习和深度学习领域有着广泛的应用,是构建模型和解决分类问题中的重要工具。
b.sigmoid函数的输入
预测函数!
z的取值为负无穷到正无穷,相对应的函数的取值为[0,1]通过这个函数可以将任意值映射到[0,1],在此基础上我们给定一个阈值,如果大于该阈值就判断为正类,否则负类,这样就可以进行分类预测。sigmoid函数在机器学习和深度学习领域有着广泛的应用,是构建模型和解决分类问题中的重要工具。
b.sigmoid函数的输入
预测函数!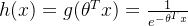 其中
其中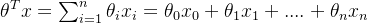 我们用h(x)来表示预测为正类的概率那么预测为负类的概率就为1-h(x)
当二分类的时候就用1来表示正类用0来表示负类,那么我们就可以得到公式:
我们用h(x)来表示预测为正类的概率那么预测为负类的概率就为1-h(x)
当二分类的时候就用1来表示正类用0来表示负类,那么我们就可以得到公式: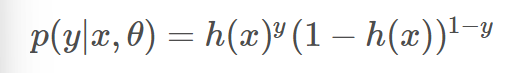 使得y取值为0和1都能表示为预测为y的概率
c.sigmoid函数代码
def sigmoid(z): return 1 / (1 + np.exp(-z))
3.梯度上升
a.似然函数
公式!
使得y取值为0和1都能表示为预测为y的概率
c.sigmoid函数代码
def sigmoid(z): return 1 / (1 + np.exp(-z))
3.梯度上升
a.似然函数
公式!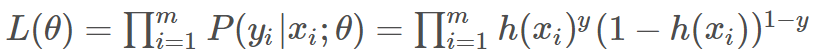 介绍:似然函数来描述观测数据属于不同类别的概率分布,然后通过最大化似然函数来估计模型参数。也就是说我们要使得这个似然函数的值尽可能大,才能使得这个函数拟合效果好。这时候我们就需要求导求出这个函数的极值。但是由于这个函数求导计算量大,所以我们可以对这个函数取对数,得到对数似然函数。
对数平均似然函数公式:
介绍:似然函数来描述观测数据属于不同类别的概率分布,然后通过最大化似然函数来估计模型参数。也就是说我们要使得这个似然函数的值尽可能大,才能使得这个函数拟合效果好。这时候我们就需要求导求出这个函数的极值。但是由于这个函数求导计算量大,所以我们可以对这个函数取对数,得到对数似然函数。
对数平均似然函数公式: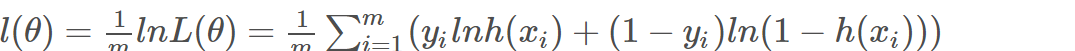 通过取对数可以将原来的乘法运算转换为加法运算,减少计算量
对数似然函数代码
def srhs(X, y, theta):
m = len(y)
h = sigmoid(X.dot(theta))
res = (1/m) * (y.dot(np.log(h)) + (1-y).dot(np.log(1-h)))
return res
代码解释:
m是y的样本数量,theta是以数组存储的θ,也就是上面说的θ1到θn,也就是sigmoid的输入,线性回归方程。h得到的也是一个列向量,是数据集x中每个样本点代入到sigmoid函数中的值。因为是累加的,所以我们最后结果就可以直接将其分为两部分用矩阵相乘计算。最后返回一个浮点型的值。
b.梯度下降
求似然函数最大值的时候用梯度上升求解,当求损失函数最小值时用梯度下降求解,损失函数公式就是平均似然函数乘-1后的结果。
c.学习率
如果学习率设置的太大可能导致模型参数在每次迭代中波动较大,使得模型无法收敛到最优解。同时过大的学习率可能导致参数更新跨越最优解,使得模型无法收敛到局部最小值或全局最小值。
如果设置的太小会导致参数更新幅度过小,从而使得模型收敛速度变慢。以及
可能使得模型在局部最优解处震荡,难以跳出局部最优解找到更好的全局最优解。
普通梯度上升和随机梯度上升的区别主要就体现在学习率的选取上,随机梯度上升的学习率是随机的也就是不固定的。容易在训练过程中产生震荡,但是可以通过调整学习率解决这个问题。
下面是似然函数求极大值的过程
通过取对数可以将原来的乘法运算转换为加法运算,减少计算量
对数似然函数代码
def srhs(X, y, theta):
m = len(y)
h = sigmoid(X.dot(theta))
res = (1/m) * (y.dot(np.log(h)) + (1-y).dot(np.log(1-h)))
return res
代码解释:
m是y的样本数量,theta是以数组存储的θ,也就是上面说的θ1到θn,也就是sigmoid的输入,线性回归方程。h得到的也是一个列向量,是数据集x中每个样本点代入到sigmoid函数中的值。因为是累加的,所以我们最后结果就可以直接将其分为两部分用矩阵相乘计算。最后返回一个浮点型的值。
b.梯度下降
求似然函数最大值的时候用梯度上升求解,当求损失函数最小值时用梯度下降求解,损失函数公式就是平均似然函数乘-1后的结果。
c.学习率
如果学习率设置的太大可能导致模型参数在每次迭代中波动较大,使得模型无法收敛到最优解。同时过大的学习率可能导致参数更新跨越最优解,使得模型无法收敛到局部最小值或全局最小值。
如果设置的太小会导致参数更新幅度过小,从而使得模型收敛速度变慢。以及
可能使得模型在局部最优解处震荡,难以跳出局部最优解找到更好的全局最优解。
普通梯度上升和随机梯度上升的区别主要就体现在学习率的选取上,随机梯度上升的学习率是随机的也就是不固定的。容易在训练过程中产生震荡,但是可以通过调整学习率解决这个问题。
下面是似然函数求极大值的过程
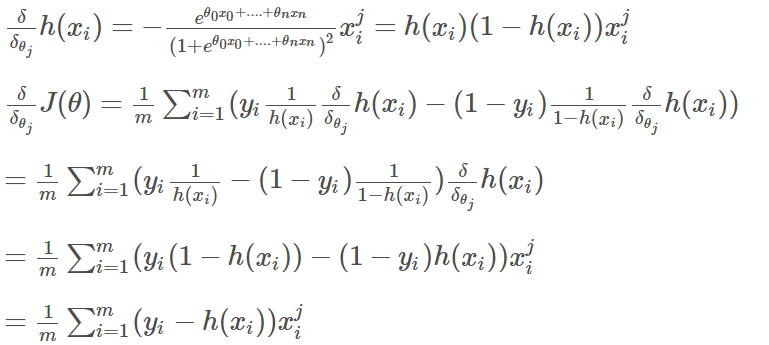 参数更新公式
θj:=θj+α1m∑mi=1(yi−h(xi))xji
梯度上升代码
def gradient_ascent(X, y, num, alpha):
m, n = X.shape
theta = np.zeros(n)
for i in range(num_):
h = sigmoid(np.dot(X, theta))
参数更新公式
θj:=θj+α1m∑mi=1(yi−h(xi))xji
梯度上升代码
def gradient_ascent(X, y, num, alpha):
m, n = X.shape
theta = np.zeros(n)
for i in range(num_):
h = sigmoid(np.dot(X, theta))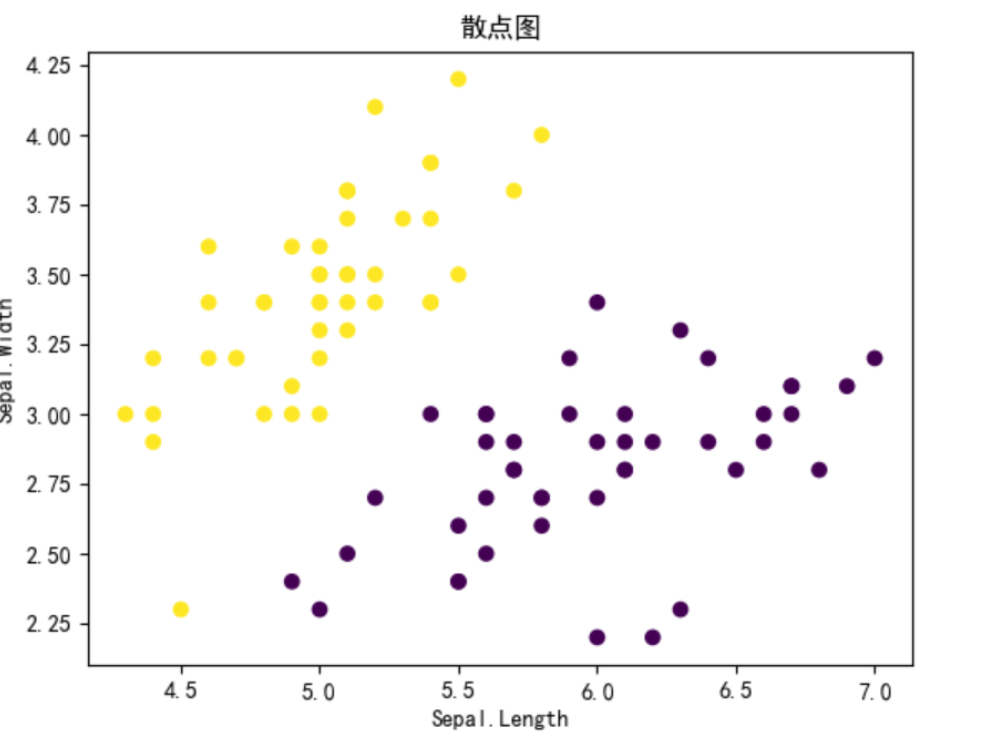 3.逻辑回归曲线
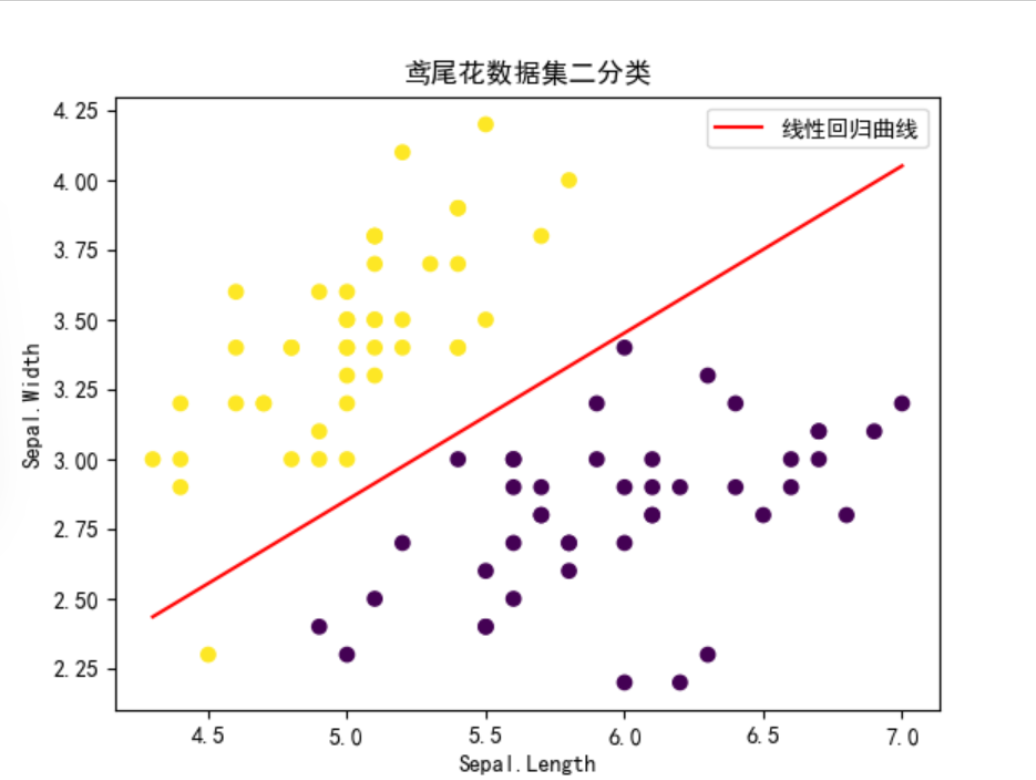
要连接一条直线,有多个点可以选取。在x的范围内平均取100个点,由于特征只有两个所以线性回归方程可以是θ0x0+θ1x1+....+θnxn=0
所以第二个特征的解析式的取值就为代码所示。然后把点带入得到直线
代码展示xi = np.linspace(np.min(X[:, 1]), np.max(X[:, 1]), 100)
yi = -(theta[0] + theta[1] * xi) / theta[2]
plt.scatter(X[:, 1], X[:, 2], c=y, cmap='viridis')
plt.plot(xi, yi, "r-", label='线性回归曲线')
plt.xlabel('Sepal.Length')
plt.ylabel('Sepal.Width')
plt.title('鸢尾花数据集二分类')
plt.legend()
plt.show()
3.逻辑回归曲线
要连接一条直线,有多个点可以选取。在x的范围内平均取100个点,由于特征只有两个所以线性回归方程可以是θ0x0+θ1x1+....+θnxn=0
所以第二个特征的解析式的取值就为代码所示。然后把点带入得到直线
代码展示xi = np.linspace(np.min(X[:, 1]), np.max(X[:, 1]), 100)
yi = -(theta[0] + theta[1] * xi) / theta[2]
plt.scatter(X[:, 1], X[:, 2], c=y, cmap='viridis')
plt.plot(xi, yi, "r-", label='线性回归曲线')
plt.xlabel('Sepal.Length')
plt.ylabel('Sepal.Width')
plt.title('鸢尾花数据集二分类')
plt.legend()
plt.show()
【本文地址】