| Flask源码篇:Flask路由规则与请求匹配过程(超详细,易懂) | 您所在的位置:网站首页 › session对象与application对象有何区别 › Flask源码篇:Flask路由规则与请求匹配过程(超详细,易懂) |
Flask源码篇:Flask路由规则与请求匹配过程(超详细,易懂)
|
目录
1 启动时路由相关操作(1)分析app.route()(2)分析add_url_rule()(3)分析Rule类(4)分析Map类(5)分析MapAdapter类(6)分析 url_rule_class()(7)分析map.add(rule)
2 请求进来时路由匹配过程(1)分析wsgi_app(2)分析request_context(3)分析ctx.push(4)分析full_dispatch_request
3 总结
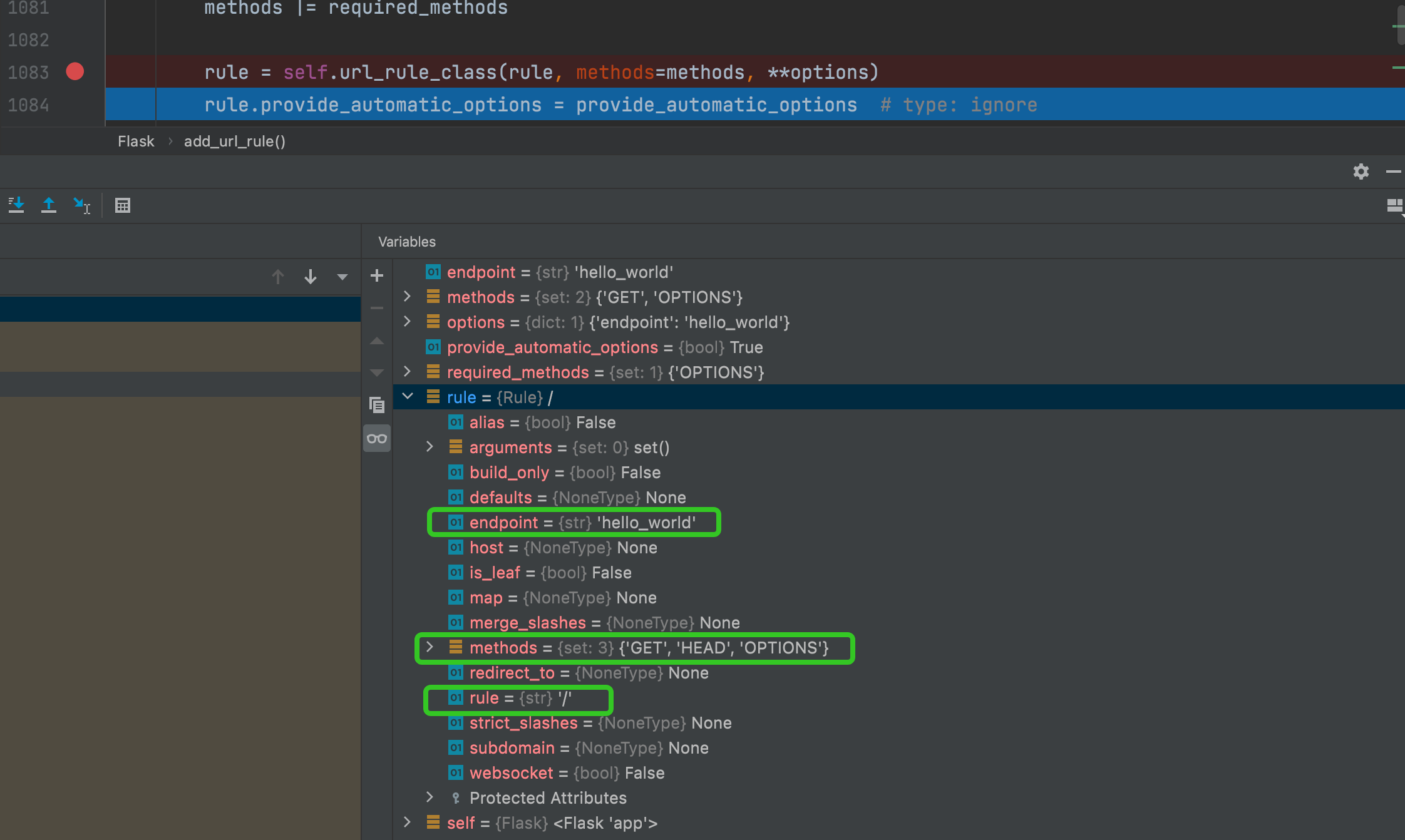
如果不想看具体的解析过程,可以直接看总结,一样可以看懂! 1 启动时路由相关操作所谓的路由原理,就是Flask如何创建自己的路由体系,并当一个请求到来时,如何根据路由体系准确定位处理函数,并响应请求。 本节还是以最简单一个Flask应用例子来展开讲解路由原理,如下: from flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello World!' if __name__ == '__main__': app.run() (1)分析app.route()首先路由的注册是通过scaffold(Flask继承scaffold)包下的route()装饰器实现的,其源码如下: def route(self, rule: str, **options: t.Any) -> t.Callable: def decorator(f: t.Callable) -> t.Callable: # 获取endpoint endpoint = options.pop("endpoint", None) # 添加路由,rule就是app.route()传来的路由字符串,及'/' self.add_url_rule(rule, endpoint, f, **options) return f return decorator可以看到这个装饰器主要做了两件事:1.获取endpoint;2.添加路由。 其中最重要的是函数add_url_rule(),用来添加路由映射。 补充: endpoint是在后面Flask存储路由和函数名映射的时候用到,如果没有指定,默认是被装饰的函数名。具体如何使用,后面还会分析到;因为app.route()的本质还是add_url_rule()函数,所以我们也可以直接使用这个函数,用法可以参考文章Flask路由。 (2)分析add_url_rule()下面来看下add_url_rule做了哪些事,其核心源码如下: class Flask(Scaffold): # 这里只有要讨论的主要代码,其他代码省略了 url_rule_class = Rule url_map_class = Map def __init__( self, import_name: str, static_url_path: t.Optional[str] = None, static_folder: t.Optional[t.Union[str, os.PathLike]] = "static", static_host: t.Optional[str] = None, host_matching: bool = False, subdomain_matching: bool = False, template_folder: t.Optional[str] = "templates", instance_path: t.Optional[str] = None, instance_relative_config: bool = False, root_path: t.Optional[str] = None, ): super().__init__( import_name=import_name, static_folder=static_folder, static_url_path=static_url_path, template_folder=template_folder, root_path=root_path, ) self.url_map = self.url_map_class() self.url_map.host_matching = host_matching self.subdomain_matching = subdomain_matching def add_url_rule( self, rule: str, endpoint: t.Optional[str] = None, view_func: t.Optional[t.Callable] = None, provide_automatic_options: t.Optional[bool] = None, **options: t.Any, ) -> None: # 1.如果没提供endpoint,获取默认的endpoint if endpoint is None: endpoint = _endpoint_from_view_func(view_func) # type: ignore options["endpoint"] = endpoint # 2.获取请求方法,在装饰器@app.route('/index', methods=['POST','GET'])的method参数 # 如果没有指定,则给个默认的元组("GET",) # 关于provide_automatic_options处理一些暂不看 methods = options.pop("methods", None) if methods is None: methods = getattr(view_func, "methods", None) or ("GET",) if isinstance(methods, str): raise TypeError( "Allowed methods must be a list of strings, for" ' example: @app.route(..., methods=["POST"])' ) methods = {item.upper() for item in methods} # Methods that should always be added required_methods = set(getattr(view_func, "required_methods", ())) # starting with Flask 0.8 the view_func object can disable and # force-enable the automatic options handling. if provide_automatic_options is None: provide_automatic_options = getattr( view_func, "provide_automatic_options", None ) if provide_automatic_options is None: if "OPTIONS" not in methods: provide_automatic_options = True required_methods.add("OPTIONS") else: provide_automatic_options = False # Add the required methods now. methods |= required_methods # 3.重要的一步:url_rule_class方法实例化Rule对象 rule = self.url_rule_class(rule, methods=methods, **options) rule.provide_automatic_options = provide_automatic_options # type: ignore # 4.重要的一步:url_map(Map对象)的add方法 self.url_map.add(rule) # 5.判断endpoint和view_func的映射存不存在,如果已经有其他view_func用了这个endpoint,则报错,否则新的映射加到self.view_functions里 # self.view_functions继承自Scaffold,是一个字典对象 if view_func is not None: old_func = self.view_functions.get(endpoint) if old_func is not None and old_func != view_func: raise AssertionError( "View function mapping is overwriting an existing" f" endpoint function: {endpoint}" ) self.view_functions[endpoint] = view_func分析上面源码,这个方法主要做了以下几件事: 如果没提供endpoint,获取默认的endpoint;获取请求方法,在装饰器@app.route('/index', methods=['POST','GET'])的method参数,如果没有指定,则给个默认的元组(“GET”,);self.url_rule_class():实例化Rule对象,Rule类后面还会再讲解;调用self.url_map.add()方法,其中self.url_map是一个Map对象,后面还会再讲解;self.view_functions[endpoint] = view_func添加endpoint和view_func的映射。其中实例化Rule对象和self.url_map.add()是Falsk路由里的核心,下面分析Rule类和Map类。 (3)分析Rule类Rule类在werkzeug.routing模块下,其源码较多,这里也只摘取我们用到的主要代码,如下: class Rule(RuleFactory): def __init__( self, string: str, methods: t.Optional[t.Iterable[str]] = None, endpoint: t.Optional[str] = None, # 此处省略了其他参数的代码 ... ) -> None: if not string.startswith("/"): raise ValueError("urls must start with a leading slash") self.rule = string self.is_leaf = not string.endswith("/") self.map: "Map" = None # type: ignore self.methods = methods self.endpoint: str = endpoint # 省略了其他初始化的代码 def get_rules(self, map: "Map") -> t.Iterator["Rule"]: """获取map对象的rule迭代器""" yield self def bind(self, map: "Map", rebind: bool = False) -> None: """把map对象绑定到Rule对象上,并且根据rule和map信息创建一个path正则表达式,存储在rule对象的self._regex属性里,路由匹配的时候用""" if self.map is not None and not rebind: raise RuntimeError(f"url rule {self!r} already bound to map {self.map!r}") # 把map对象绑定到Rule对象上 self.map = map if self.strict_slashes is None: self.strict_slashes = map.strict_slashes if self.merge_slashes is None: self.merge_slashes = map.merge_slashes if self.subdomain is None: self.subdomain = map.default_subdomain # 调用compile方法创建一个正则表达式 self.compile() def compile(self) -> None: """编写正则表达式并存储到属性self._regex中""" # 此处省略了正则的解析过程代码 regex = f"^{''.join(regex_parts)}{tail}$" self._regex = re.compile(regex) def match( self, path: str, method: t.Optional[str] = None ) -> t.Optional[t.MutableMapping[str, t.Any]]: """这个函数用于校验传进来path参数(路由)是否能够匹配,匹配不上返回None""" # 省去了部分代码,只摘录了主要代码,看一下大致逻辑即可 if not self.build_only: require_redirect = False # 1.根据bind后的正则结果(self._regex正则)去找path的结果集 m = self._regex.search(path) if m is not None: groups = m.groupdict() # 2.编辑匹配到的结果集,加到一个result字典里并返回 result = {} for name, value in groups.items(): try: value = self._converters[name].to_python(value) except ValidationError: return None result[str(name)] = value if self.defaults: result.update(self.defaults) return result return NoneRule类继承自RuleFactory类,主要参数有: string:路由字符串methods:路由方法endpoint:endpoint参数一个Rule实例代表一个URL模式,一个WSGI应用会处理很多个不同的URL模式,与此同时产生很多个Rule实例,这些实例将作为参数传给Map类。 (4)分析Map类Map类也在werkzeug.routing模块下,其源码较多,这里也只摘取我们用到的主要代码,主要源码如下: class Map: def __init__( self, rules: t.Optional[t.Iterable[RuleFactory]] = None # 此处省略了其他参数 ) -> None: # 根据传进来的rules参数维护了一个私有变量self._rules列表 self._rules: t.List[Rule] = [] # endpoint和rule的映射 self._rules_by_endpoint: t.Dict[str, t.List[Rule]] = {} # 此处省略了其他初始化操作 def add(self, rulefactory: RuleFactory) -> None: """ 把Rule对象或一个RuleFactory对象添加到map并且绑定到map,要求rule没被绑定过 """ for rule in rulefactory.get_rules(self): # 调用rule对象的bind方法 rule.bind(self) # 把rule对象添加到self._rules列表里 self._rules.append(rule) # 把endpoint和rule的映射加到属性self._rules_by_endpoint里 self._rules_by_endpoint.setdefault(rule.endpoint, []).append(rule) self._remap = True def bind( self, server_name: str, script_name: t.Optional[str] = None, subdomain: t.Optional[str] = None, url_scheme: str = "http", default_method: str = "GET", path_info: t.Optional[str] = None, query_args: t.Optional[t.Union[t.Mapping[str, t.Any], str]] = None, ) -> "MapAdapter": """ 返回一个新的类MapAdapter """ server_name = server_name.lower() if self.host_matching: if subdomain is not None: raise RuntimeError("host matching enabled and a subdomain was provided") elif subdomain is None: subdomain = self.default_subdomain if script_name is None: script_name = "/" if path_info is None: path_info = "/" try: server_name = _encode_idna(server_name) # type: ignore except UnicodeError as e: raise BadHost() from e return MapAdapter( self, server_name, script_name, subdomain, url_scheme, path_info, default_method, query_args, )Map类有两个个非常重要的属性: self._rules,属性是一个列表,存储了一系列Rule对象;self._rules_by_endpoint:其中有个核心方法add(),这里就是我们分析app.add_url_rule()方法是第4步调用的方法。后面会详细讲解。 (5)分析MapAdapter类在Map类中,会用到MapAdapter类,下面我们认识下这个类: class MapAdapter: """`Map.bind`或`Map.bind_to_environ` 会返回这个类 主要用来做匹配 """ def match( self, path_info: t.Optional[str] = None, method: t.Optional[str] = None, return_rule: bool = False, query_args: t.Optional[t.Union[t.Mapping[str, t.Any], str]] = None, websocket: t.Optional[bool] = None, ) -> t.Tuple[t.Union[str, Rule], t.Mapping[str, t.Any]]: """匹配请求的路由和Rule对象""" # 只摘摘录了主要代码,省略了大量代码... # 这里是主要步骤:遍历map对象的rule列表,依次和path进行匹配 for rule in self.map._rules: try: # 调用rule对象的match方法返回匹配结果 rv = rule.match(path, method) except RequestPath as e: # 下面省略了大量代码... # 返回rule对象(或endpoint)和匹配的路由结果 if return_rule: return rule, rv else: return rule.endpoint, rvMap.bind或Map.bind_to_environ 方法会返回MapAdapter对象。 其中MapAdapter对象核心方法是match,主要步骤是遍历map对象的rule列表,依次和path进行匹配,当然也是调用rule对象的match方法返回匹配结果。 接下来可以稍微独立的看下Map类和Rlue对象联合起来怎么用,看下面一个例子: from werkzeug.routing import Map, Rule m = Map([ Rule('/', endpoint='index'), Rule('/blog', endpoint='blog/index'), Rule('/blog/', endpoint='blog/detail') ]) # 返回一个MapAdapter对象 map_adapter = m.bind("example.com", "/") # MapAdapter对象的 match方法会返回匹配的结果 print(map_adapter.match("/", "GET")) # ('index', {}) print(map_adapter.match("/blog/42")) # ('blog/detail', {'id': 42}) print(map_adapter.match("/blog")) # ('blog/index', {})可以看到,Map对象通过bind返回了一个MapAdapter对象,MapAdapter对象的match方法可以找到路由匹配的结果。 (6)分析 url_rule_class()add_url_rule的第一个主要步骤就是rule = self.url_rule_class(rule, methods=methods, **options),即创建一个Rule对象。 在分析Rlue类的时候,知道了Rule对象主要有string(路由字符串)、methods、endpoint3个属性。在下面以一个具体的示例,看下实例化的Rule对象是什么样子的。 还是一开始最上面的示例,我们看下通过@app.route('/')代码后到实例化Rule对象的时候,这个对象的具体属性,通过debug如下:
可以看到,rule对象的rule属性是传的路由,endpoint属性是通过函数名获取的,method属性是支持的请求方法,'HEAD’和OPTIONS是默认添加的。 (7)分析map.add(rule)add_url_rule的第二个主要步骤就是self.url_map.add(rule),即调用Map对象的add方法。 在第4步分析Map对象时,有提到过,现在再回头仔细看下这个方法做了什么: def add(self, rulefactory: RuleFactory) -> None: """ 把Rule对象或一个RuleFactory对象添加到map并且绑定到map,要求rule没被绑定过 """ for rule in rulefactory.get_rules(self): # 调用rule对象的bind方法 rule.bind(self) # 把rule对象添加到self._rules列表里 self._rules.append(rule) # 把endpoint和rule的映射加到属性self._rules_by_endpoint里 self._rules_by_endpoint.setdefault(rule.endpoint, []).append(rule) self._remap = True其实主要就是 把上一步实例化的Rule对象或一个RuleFactory对象添加到Map对象并且绑定到map。 主要做了两件事: 调用rule对象的bind方法rule.bind(self):在分析Rule类时,提到过这个方法,它主要作用是把map对象绑定到Rule对象上,并且根据rule和map信息创建一个正则表达式(Rule对象的self._regex 属性)。把rule对象添加到Map对象的self._rules列表里;把endpoint和rule的映射加到Map对象的属性self._rules_by_endpoint(一个字典)里;我们可以通过示例看下Map对象在add之后变成了什么样,通过debug,结果如下:
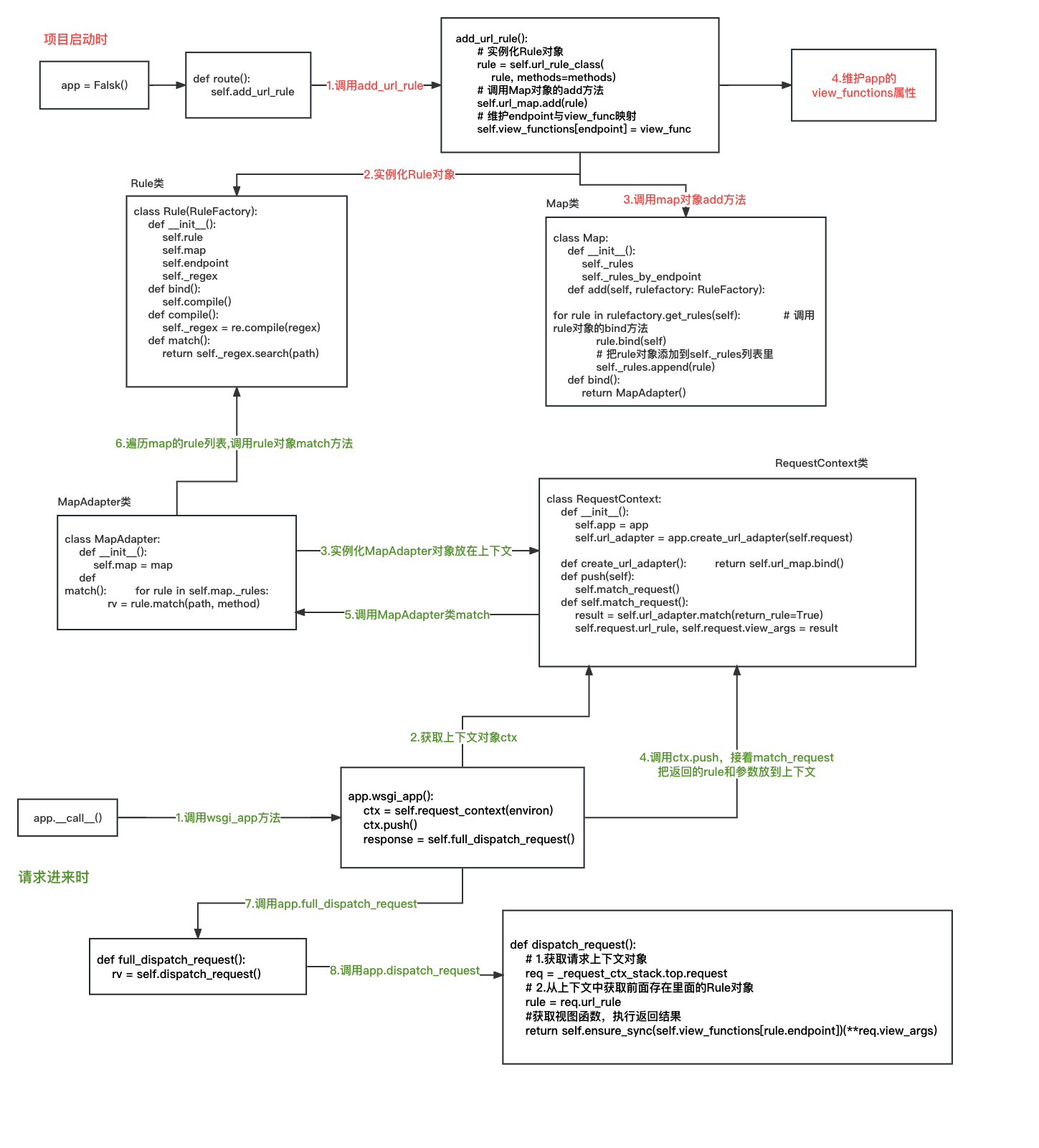
可以看到,Map的self._rules和self._rules_by_endpoint属性都含有新加的’/'路由对应的数据(其中/static/是默认添加的静态文件的位置路由)。 上面就分析完了,如何添加一个路由映射的。 2 请求进来时路由匹配过程 (1)分析wsgi_app下面分析下,当前一个请求进来时,如何根据前面Map和Rlue对象来进行路由匹配的。 上一章中我们分析了当请求进来时会先经过wsgi服务器处理完请求后调用Flask app的__call__方法,其代码如下: def __call__(self, environ: dict, start_response: t.Callable) -> t.Any: """The WSGI server calls the Flask application object as the WSGI application. This calls :meth:`wsgi_app`, which can be wrapped to apply middleware. """ return self.wsgi_app(environ, start_response)可以看到其实就是调用了app的wsgi_app()方法。其代码如下: def wsgi_app(self, environ: dict, start_response: t.Callable) -> t.Any: # 1.获取请求上下文 ctx = self.request_context(environ) error: t.Optional[BaseException] = None try: try: # 2.调用请求上下文的push方法 ctx.push() # 3.调用full_dispatch_request()分发请求,获取响应结果 response = self.full_dispatch_request() except Exception as e: error = e response = self.handle_exception(e) except: error = sys.exc_info()[1] raise return response(environ, start_response) finally: if self.should_ignore_error(error): error = None ctx.auto_pop(error)其中有3个主要步骤: 获取请求上下文:ctx = self.request_context(environ)调用请求上下文的push方法:ctx.push()调用full_dispatch_request()分发请求,获取响应结果:response = self.full_dispatch_request()下面来逐个分析下每个步骤的作用。 (2)分析request_contextwsgi_app方法的第一个主要步骤。 这个方法主要就是获取一个上下文对象。 需要把environ(环境变量等)传入到方法中。上下文在Flask中也是一个重要的概念,当然关于上下文的解析下章会重点解析。此章只关注我们我们需要的。 def request_context(self, environ: dict) -> RequestContext: return RequestContext(self, environ)此方法就是创建一个RequestContext对象。RequestContext类部分源码如下: class RequestContext: def __init__( self, app: "Flask", environ: dict, request: t.Optional["Request"] = None, session: t.Optional["SessionMixin"] = None, ) -> None: self.app = app if request is None: request = app.request_class(environ) self.request = request self.url_adapter = None try: # 此处是重点,调用了Falsk对象的create_url_adapter方法获取了MapAdapter对象 self.url_adapter = app.create_url_adapter(self.request) except HTTPException as e: self.request.routing_exception = e self.flashes = None self.session = session # 其他代码省略... # 其他方法的源码省略...在创建RequestContext对象的初始化方法中,有个很重要的步骤就是获取MapAdapter对象。 前面第4节我们分析过它的作用,主要就是用来匹配路由的。 下面我们看下create_url_adapter源码: def create_url_adapter( self, request: t.Optional[Request] ) -> t.Optional[MapAdapter]: if request is not None: if not self.subdomain_matching: subdomain = self.url_map.default_subdomain or None else: subdomain = None # 此处是重点,调用了Map对象的bind_to_environ方法 return self.url_map.bind_to_environ( request.environ, server_name=self.config["SERVER_NAME"], subdomain=subdomain, ) if self.config["SERVER_NAME"] is not None: # 此处是重点,调用了Map对象的bind方法 return self.url_map.bind( self.config["SERVER_NAME"], script_name=self.config["APPLICATION_ROOT"], url_scheme=self.config["PREFERRED_URL_SCHEME"], ) return None可以看到,这个方法的主要作用就是调用Map对象的bind_to_environ方法或bind方法。前面讲Map类的时候也分析过,这两个方法主要是返回了MapAdapter对象。 (3)分析ctx.pushwsgi_app方法的第二个主要步骤。 wsgi方法里获取到上下文对象后,就调用了push方法,其代码如下(只保留了核心代码): class RequestContext: def __init__( self, app: "Flask", environ: dict, request: t.Optional["Request"] = None, session: t.Optional["SessionMixin"] = None, ) -> None: # 代码省略 pass def match_request(self) -> None: try: # 1.调用了MapAdapter对象的match方法,返回了rule对象和参数对象 result = self.url_adapter.match(return_rule=True) # 2.把rule对象和参数对象放到请求上下文中 self.request.url_rule, self.request.view_args = result except HTTPException as e: self.request.routing_exception = e def push(self) -> None: """Binds the request context to the current context.""" # 此处省略了前置校验处理代码(上下文、session等处理) if self.url_adapter is not None: # 调用了match_request方法 self.match_request()可以看到push方法主要是调用了match_request方法,这个方法主要做了如下两件事: 调用了MapAdapter对象的match方法,会根据Map对象存储的路由信息去匹配当前请求的路由,返回了rule对象和参数对象。把rule对象和参数对象放到请求上下文中。 (4)分析full_dispatch_requestwsgi_app方法的第三个主要步骤。 full_dispatch_request方法源码如下: def full_dispatch_request(self) -> Response: self.try_trigger_before_first_request_functions() try: request_started.send(self) rv = self.preprocess_request() if rv is None: # 这里是主要的步骤:分发请求 rv = self.dispatch_request() except Exception as e: rv = self.handle_user_exception(e) return self.finalize_request(rv)其中dispatch_request()是核心方法。 dispatch_request()方法源码如下: def dispatch_request(self) -> ResponseReturnValue: # 1.获取请求上下文对象 req = _request_ctx_stack.top.request if req.routing_exception is not None: self.raise_routing_exception(req) # 2.从上下文中获取前面存在里面的Rule对象 rule = req.url_rule # if we provide automatic options for this URL and the # request came with the OPTIONS method, reply automatically if ( getattr(rule, "provide_automatic_options", False) and req.method == "OPTIONS" ): return self.make_default_options_response() # 这里是重点:根据rule对象的endpoint属性从self.view_functions属性中获取对应的视图函数, # 然后把上下文中的参数传到视图函数中并调用视图函数处理请求,返回处理结果 return self.ensure_sync(self.view_functions[rule.endpoint])(**req.view_args)这个方法主要步骤如下: req = _request_ctx_stack.top.request:获取请求上下文对象rule = req.url_rule:从上下文中获取前面存在里面的Rule对象,就是ctx.push()方法放进上下文的根据rule对象的endpoint属性从self.view_functions属性中获取对应的视图函数,然后把上下文中的参数传到视图函数中并调用视图函数处理请求,返回处理结果:return self.ensure_sync(self.view_functions[rule.endpoint])(**req.view_args)至此,一个完整的请求就处理完啦。 3 总结根据以上分析,对路由规则和请求匹配总结如下: 应用启动时: app.route()调用add_url_rule方法。add_url_rule方法里:调用self.url_rule_class()实例化Rule对象;add_url_rule方法里:调用self.url_map.add()方法,把Rule对象、endpoint与视图函数的映射关系存储到Map对象中。add_url_rule方法里:self.view_functions[endpoint] = view_func添加endpoint和view_func的映射。请求匹配过程: 请求进来时有WSGI服务器处理并调用了Flask app的__call__方法,再调用了wsgi_app方法;wsgi_app方法里创建一个上下文对象:ctx = self.request_context(environ)。然后实例化了MapAdapter对象作为上下文对象属性;wsgi_app方法里调用上下文对象的push方法:ctx.push()。这个方法主要使用MapAdapter对象的match方法。MapAdapter对象的match方法,去调用rule对象的match方法。这个方法根据Map对象存储的路由信息去匹配当前请求的路由,得到了rule对象和参数对象放到上下文对象里。wsgi_app方法里调用full_dispatch_request方法,然后里面再调用dispatch_request()方法;dispatch_request()方法里:获取请求上下文对象,拿到里面的Rule对象,根据rule对象的endpoint属性从self.view_functions属性中获取对应的视图函数,然后把上下文中的参数传到视图函数中并调用视图函数处理请求,返回处理结果。整个流程图如下:
其中上半部分项目启动时如何使用Rule和Map对象建立路由规则;下半部分是请求进来时,如何使用路由规则进行匹配。 |

【本文地址】