| 歌词分析浅析 | 您所在的位置:网站首页 › samson歌曲 › 歌词分析浅析 |
歌词分析浅析
|
歌词分析浅析 最近正在考虑新歌推荐的问题,突然想起了一直没有处理过的对象-歌词,想利用歌词做点什么,没什么目的,尝试了歌词分词,歌词相似度计算、歌词分类、word2vec歌词聚合、查找相似歌曲,最终收获了一个根据歌词产生类似歌曲的方法。 一、歌词预处理 歌词数据源是某音乐网站top1万的歌曲的歌词。 歌词文本的一种格式是lrc格式,其中时间用[]隔开,歌词解析器根据时间来解析。原始格式和展现格式如下图所示。
歌词的开头一般会有歌曲名,演唱者,作词,作曲等相关信息,这些信息我认为是冗余信息,暂时没有用。我统计了一万首歌曲的前5行,80%的歌词都是这些信息而不是歌曲正文。有的歌曲的前10行会有发行公司等更详细的信息,大约占比50%。所以,我采取的办法是,前5行直接删除,5-20行检查是否有特殊关键字词,以免这些公众信息影响到后面的分析。
二、歌词分词 为了分析歌词,我需要把歌词文本分词,使用python的jieba库。以行为单位。分词时可以选择所需要的词的词性,分词的模式。第一次时,我只选择了分词结果中的名词,精确模式。比如《沧海一声笑》的一句歌词分词结果如下:
可以看到,这种方式提取的很精炼,但是也少了一些词语。比如“涛”“浪”这些词语也是可以体现出歌词的意思的。
三、使用one hot模式求相似文档 我首先尝试的是将文档所有的词合并形成词典,然后文档根据词语onehot编码,然后计算余弦相似度,进行匹配。具体步骤如下: 1、对每篇文档的每句歌词进行分词 2、一篇文档的所有语句的分词结果进行合并,相同单词的权重相加 3、抽取所有文档的分词结果,形成词典 4、根据词典,对文档进行one hot编码 5、计算两篇文档的cos 这种方法类似于比较两篇文档中的共同词的个数,共同词越多,相似度就越高。 所有的文档是那一万个歌词文本,得到的结果很不好,《沧海一声笑》http://music.taihe.com/song/209713 关联度最高的是一首《英雄》(http://music.taihe.com/song/127609605)。经过分析,计算两篇文档的cos时,大部分文档的交集几乎没有,《沧海一声笑》和《英雄》关联最高,因为有两个词语相同。交集很少的原因是分词的时候大部分词都被过滤了,我调整了分词过程,取出更多的词语。和上次相比,交集变多了,但是匹配结果并没有改变。尝试其他方法
四、使用word2vec算法求相似的句子 word2vec是一种将词语转换成向量的算法,它需要先根据语料库进行训练,然后根据优化后的模型将词语转换成向量。这种向量的每一维和one hot编码形成词向量很不同,后者的每一个特征都是对应着一个词语,前者的每一个特征并没有这种对应,别人称向量所在的空间为语义空间,比较含糊。 我使用gensim库进行的word2vec训练,用法可以搜索下,工具比较方便。具体步骤如下: 1、对于每个文档对每一句歌词进行分词,并删除停用词 2、将每篇文档分词得到的结果以行为单位,传给gensim库,进行训练 3、形成模型并保存 得到模型后,我首先尝试的是输入一句歌词,看看得到哪些相似的歌词句子。 首先将输入语句进行分词,然后利用gensim模型求得每个词的词向量,将所有向量相加即得到输入语句的向量。然后加载1万首歌的所有行的分词结果,对与每一行gensim也是采用上述方法求得向量,然后计算相似度。试了几句,感觉还有点意思。
接着是尝试根据歌词求出相似文本,尝试的第一个方法是,在上个步骤的基础上,取出1000个最相似的语句,然后查找这些语句对应的歌曲,统计歌曲出现次数,出现次数多的歌曲排在前面。这个结果很不好,“涛浪淘尽 红尘俗世知多少”这句歌词,求出来前几个都是古文歌曲或者佛教相关的。我检查了下一方面是因为歌词中语句是有重复的,当一句相似性高的语句重复出现时,对应歌曲次数也会增加。另一方面这种统计方法不好。 尝试的第二个方法是,计算文本的排名时,首先将相关的句子相似性之和求出来,然后作为文本的权重。这种方式效果比上次要好,我选择一首歌《小手拍拍》,输入其中歌词“小手拍拍”,排在前几位的有很多是“小蓓蕾组合”的儿歌。但是仍然感觉有欠缺,so continue。 五、分析歌词每一句,查看关联的歌曲 这次我更深入一点,用四中方法看看关联的歌词和所属歌曲。还是《沧海一声笑》的例子,结果如下(每个case为一句歌词,结果为歌词和所在歌曲)。 case1“江山笑 烟雨遥” 关联的有红歌:人民的江山万万年 《乌苏里江船歌》 武侠的:狼烟起江山北望 《精忠报国》 情歌:宁叫那玉皇大帝的江山乱 《一对对鸳鸯水上漂》 前两个也就罢了毕竟也是关于江山的,但是最后一个真是醉了。
Case2 “涛浪淘尽 红尘俗世知多” 关联的有情歌:悄入俗世看红尘 《如美画卷》 搞笑的:三十六变闯荡江湖浪海涛涛 《八戒八戒》 情歌: 不语红尘是非 《南水湖之恋》 这个还可以,但是《八戒八戒》很不协调。大家可以听听小沈阳这个《八戒八戒》是个搞笑歌曲。
Case3 “清风笑 竟惹寂寥” 有武侠歌曲: 红尘笑笑寂寥 《江湖笑》 儿歌: 满身的泥水惹人笑 《卖报歌》 古风歌:花香惹人醉 《一枝梅》 情歌:夜夜笙歌悲伤的基调在附和 《弹指笙歌》 同case2
根据歌词关联的语句,排在前面的是句子中有相同字词的,然后是有相似字词的句子。但是取前10个相似的句子,没有发现有哪首歌曲在每句关联的都出现的。 歌曲的基调和曲风,很不协调。《沧海一声笑》本来是武侠歌曲,但是匹配的语句有情歌,红歌,搞笑的,儿歌,很不协调,不能一起听。
接着我验证了歌词相似性 输入“江山”,根据gensim计算的相似词语结果为 改尽 0.488296121359 留取 0.458217412233 阙 0.436691373587 恩怨 0.431696951389 玉皇大帝 0.417178690434 对垒 0.410254210234 疏见 0.403560757637 花容 0.402410417795 浩荡 0.399048864841 俊俏 0.395890295506
My God! 竟然真有“玉皇大帝”
输入“烟雨” 傲然 0.494560539722 杨柳岸 0.477914631367 落花 0.474694132805 亭台 0.443738073111 拱桥 0.437748551369 损友 0.421411365271 绦丝画 0.416027069092 枯叶 0.411495625973 淡褐色 0.408756405115 琥珀色 0.408508956432 这个“杨柳岸”还不错
输入“俗世” 二人转 0.436299115419 惊叹 0.430071979761 花缎 0.419449537992 暮 0.418323099613 纵横 0.403639376163 宿敌 0.392917782068 不同寻常 0.391267389059 嗔痴 0.390879631042 蜿蜒 0.390167474747 一搏 0.384135723114 这个“二人转”很有“哲理”了,俗世众人谁没看过小品呢。
六、网上资料 虽然计算相似词语的时候,感觉有点意思。但是还是不实用。于是去网上搜了下。结果如下 1、《我用Python分析了42万字的歌词,为了搞清楚民谣歌手们在唱些什么》 这个博客分析了民谣歌手的情绪,季节,城市,方法如下: 歌手的情绪:通过词语分成两类,开心和不开心,永远晚安倔强是正面,黑暗孤独沉默是负面。 歌手喜欢的季节:春夏秋冬出现的次数 歌手喜欢的城市:通过统计歌词中某个城市出现的次数 歌词中:时间如明天和昨天这些出现的次数,代表歌手喜欢向前看还是向后看 这种方式需要有词库,然后分词,最后统计下。 2、《我分析了 6.5W 字的歌词,看到了这样的周杰伦》 这个博客分析了周杰伦歌曲的风格,方法和上面的类似。角度新颖,还分析了歌词出现“妈妈”和“爸爸”的次数,还有颜色的词语。 3、利用歌词做情感分析的论文 这个方向论文很多,可惜我没看懂。一首歌曲的感情主要看旋律,歌词也可以,但是用处不大。 4、利用论坛帖子产生音乐 这是湾湾的一篇论文,论文的目的是当用户在论坛里发了一段表示心情的话后,根据这段话来产生相关的音乐。根据这篇文章所写,它产生的音乐可以匹配到这段话的情绪,听起来很有意思,还没来尝试。 七、对歌词进行聚类分析 另外扫到一篇博客说聚类,于是我尝试了K-means算法对文档进行聚类。使用sklearn.cluster的kmeans包,可以很容易的进行训练。歌词使用的向量是将分词结果进行去重后,歌词的最终向量是分词向量之和。 先后尝试了将一万个歌词分成2个类,5个类和10个类。发现它会把英文结果放在一起,把中文的歌词放在一起。但是最后我检查了同一类中的歌词文本,并没有发现有什么相似之处,遂放弃。
八、根据歌词相似性产生电台歌曲 我们的业务有个电台(fm.taihe.com)。其原理是每个频道配置好一堆歌曲,然后用户点进去后,就根据用户喜好将电台歌曲排序后推荐出来。其实电台中的歌曲旋律和歌词内容都是差不多的,根本不需要在根据用户喜好进行推荐。难道一个喜好儿歌的用户,点进“单身情歌”频道后,你还要把“小蓓蕾”的歌曲往前排吗! 电台有个缺点,需要人工添加数据。这样造成有些歌曲不太适合这个频道,很难被发现;歌曲更新很慢,往往是长期不更新。单说第二点,打算用歌词相似的歌曲去填充电台。 首先选了一个明显的单身情歌频道,池子歌曲为48首,如下所示
然后用这48首歌曲根据歌词相似性产生新的歌曲,步骤如下: 1、计算48首歌曲对应歌词的向量,方法类似5 2、对没首歌曲,根据歌词的向量从1万首歌中获取相似度最高的5首相似歌曲,使用余弦相似度,并排除原有的48首歌曲 3、将所有相似歌曲排序,获取前100首歌曲。 获得的歌曲如下:
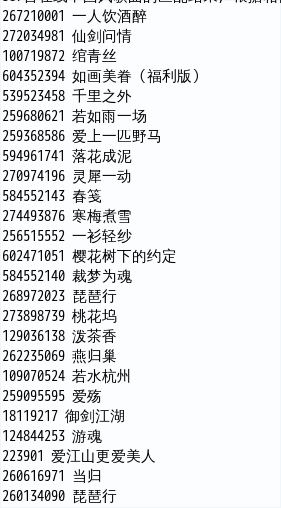
这些歌曲还不错,和单身情歌很搭配。 后来又使用了中国风这个频道,获得结果如下:(音乐原始歌曲池有杰伦的歌曲,所以匹配结果里面被过滤掉了)
到此为止,解析歌词就结束了。 代码: https://github.com/delltower/machine_learn |





【本文地址】