| R数据挖掘 第三篇:聚类的评估(簇数确定和轮廓系数)和可视化 | 您所在的位置:网站首页 › r语言kmeans聚类算法折线图 › R数据挖掘 第三篇:聚类的评估(簇数确定和轮廓系数)和可视化 |
R数据挖掘 第三篇:聚类的评估(簇数确定和轮廓系数)和可视化
|
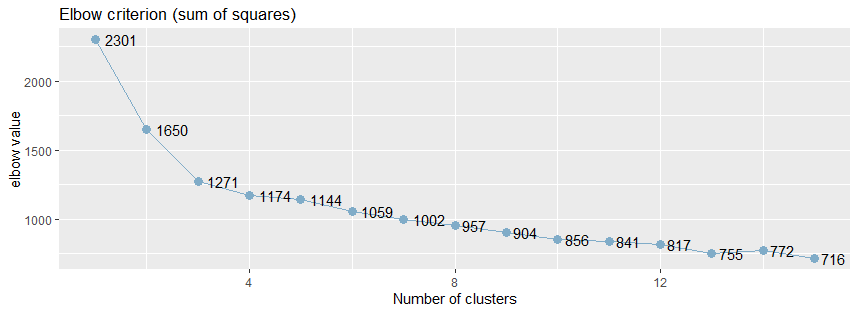
在实际的聚类应用中,通常使用k-均值和k-中心化算法来进行聚类分析,这两种算法都需要输入簇数,为了保证聚类的质量,应该首先确定最佳的簇数,并使用轮廓系数来评估聚类的结果。 一,k-均值法确定最佳的簇数通常情况下,使用肘方法(elbow)以确定聚类的最佳的簇数,肘方法之所以是有效的,是基于以下观察:增加簇数有助于降低每个簇的簇内方差之和,给定k>0,计算簇内方差和var(k),绘制var关于k的曲线,曲线的第一个(或最显著的)拐点暗示正确的簇数。 1,使用sjc.elbow()函数计算肘值 sjPlot包中sjc.elbow()函数实现了肘方法,用于计算k-均值聚类分析的肘值,以确定最佳的簇数: library(sjPlot) sjc.elbow(data, steps = 15, show.diff = FALSE)参数注释: steps:最大的肘值的数量 show.diff:默认值是FALSE,额外绘制一个图,连接每个肘值,用于显示各个肘值之间的差异,改图有助于识别“肘部”,暗示“正确的”簇数。sjc.elbow()函数用于绘制k-均值聚类分析的肘值,该函数在指定的数据框计算k-均值聚类分析,产生两个图形:一个图形具有不同的肘值,另一个图形是连接y轴上的每个“步”,即在相邻的肘值之间绘制连线,第二个图中曲线的拐点可能暗示“正确的”簇数。 绘制k均值聚类分析的肘部值。 该函数计算所提供的数据帧上的k均值聚类分析,并产生两个图:一个具有不同的肘值,另一个图绘制在y轴上的每个“步”(即在肘值之间)之间的差异。 第二个图的增加可能表明肘部标准。 library(effects) library(sjPlot) library(ggplot2) sjc.elbow(data,show.diff = FALSE)从下面的肘值图中,可以看出曲线的拐点大致在5附近:
2,使用NbClust()函数来验证肘值 从上面肘值图中,可以看到曲线的拐点是3,还可以使用NbClust包种的NbClust()函数,默认情况下,该函数提供了26个不同的指标来帮助确定簇的最终数目。 NbClust(data = NULL, diss = NULL, distance = "euclidean", min.nc = 2, max.nc = 15, method = NULL, index = "all", alphaBeale = 0.1)参数注释: diss: |
【本文地址】
公司简介
联系我们