| 数据分享 | 您所在的位置:网站首页 › r语言kmeans聚类算法中国的研究现状 › 数据分享 |
数据分享
|
全文链接:http://tecdat.cn/?p=32540
聚类分析是一种常见的数据挖掘方法,已经广泛地应用在模式识别、图像处理分析、地理研究以及市场需求分析。本文主要研究聚类分析算法K-means在电商评论数据中的应用,挖掘出虚假的评论数据(点击文末“阅读原文”获取完整代码数据)。 相关视频 本文主要帮助客户研究聚类分析在虚假电商评论中的应用,因此需要从目的出发,搜集相应的以电商为交易途径的评论信息。对调查或搜集得到的信息进行量化录入处理,以及对缺失值过多的分析对象进行删除。之后进行多维度的数据描述。由于地图最多只能显示三维空间,而顾客指标属性很可能不止三个,因此在数据描述中可以进行单一指标与某个确定指标的二维展示,这样大致先了解客户分布。 最终,通过应用改进的K-means算法对数据进行挖掘,得出了直观有用的形象化结论,对之后公司管理层做销售决策提供了必要的依据。本次改进,也可以作为今后其他数据的参考,来进行其他数据的可靠挖掘,可以说提供了可靠的参照。 研究内容本项目主要是针对现实中的市场营销与统计分析方法的结合,来挖掘潜在的客户需求。随着电子商务的发展和用户消费习惯改变,电商在销售渠道的比重将大大增强,2014年电商销售已经超过了店面销售的数量。因此,这为通过数据挖掘算法来分析客户的交易选择行为,将客户的喜好通过分类来组别,这样进一步能挖掘潜在客户和已交易客户的下一步潜在需求。 本文在基础的K-means聚类算法的基础上,结合该算法固有的一些缺陷,提出了一些改进措施,即通过改进的K-means聚类算法来对“B2C电商评论信息数据集”数据进行处理,在最终得到结果之后依据形象化的结论提出相应的公司决策,以满足市场的要求。 K-means的改进文献[7]是Huang为克服K-means算法仅适合于数值属性数据聚类的局限性,提出的一种适合于分类属性数据聚类的K-modes算法"该算法对K-means进行了3点扩展:引入了处理分类对象的新的相异性度量方法(简单的相异性度量匹配模式),使用mode:代替means,并在聚类过程中使用基于频度的方法修正modes,以使聚类代价函数值最小化"这些扩展允许人们能直接使用K-means范例聚类有分类属性的数据,无须对数据进行变换"K-modes算法的另一个优点是modes,能给出类的特性描述,这对聚类结果的解释是非常重要的"事实上,K-modes算法比K-means算法能更快收敛,与K-means算法一样,K-modes算法也会产生局部最优解,依赖于初始化modes的选择和数据集中数据对象的次序。初始化modes的选择策略尚需进一步研究。 1999年,Huang等人[8]证明了经过有限次迭代K-modes算法仅能收敛于局部最小值。 K-medoids聚类算法的基本策略就是通过首先任意为每个聚类找到一个代表对象(medoid)而首先确定n个数据对象的k个聚类;(也需要循环进行)其它对象则根据它们与这些聚类代表的距离分别将它们归属到各相应聚类中(仍然是最小距离原则)。 综合考虑以上因素,本文考虑了孤立点。传统的聚类分析将全部点进行聚类,而不考虑可能存在的孤立点对聚类结果的干扰,这使得聚类结果缺乏可靠性和稳定性。对于聚类结果,需要进行判别分析,包括内分析和外分析。内分析主要是在聚类之后,点到类中心的阈值来寻找孤立点,从而剔除孤立点,保证样本和聚类中心的可靠性,在剔除了孤立点后需要重新计算类中心,如果出现极端情况,甚至有可能进行再一次聚类分析;外分析是指在确定好最终的聚类结果后,进行外样本预测,使聚类结果更加稳定。 分析 数据集与环境本文的实验环境为Windows操作系统,R编程环境。同时选取了“B2C电商评论信息数据集”作为实验对象。这个数据集中包含了2370条B2C电商评论信息(查看文末了解数据免费获取方式)。 数据文件:
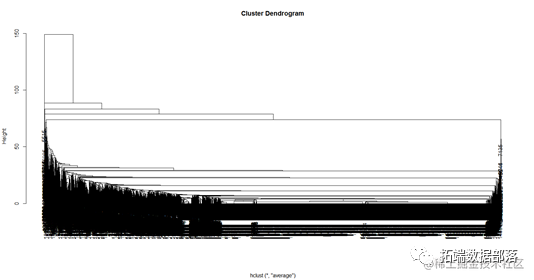
在这里,为了提高算法效率,降低数据的稀疏性,本文首先导入文本数据,对该数据进行文本挖掘。筛选出所有评论中词频最高的前30个词汇,用作实验的聚类属性。 # == 分词+频数统计 words=unlist(lapply(X=data, FUN=segmentCN));每个高频词汇和其词频数据如下表所示: wordfreq漂亮547喜欢519颜色477质量474丝巾452不错435好评425谢谢277非常273解释263愉快237生活229满意226继续225宝贝222美丽217一天214提供214努力213祝愿212衷心212赏赐212感恩212收到211没有187色差141好看126图片120可以110通过中文分词Rwordseg词频云软件包可以根据不同的词汇的词频高低来显示文本挖掘的高频词汇的总体结果。通过将词频用字体的大小和颜色的区分,我们可以明显地看到哪些词汇是高频的,哪些词汇的频率是差不多的,从而进行下一步研究。 实验采用上述数据集得到的高频词汇得到每个用户和高频词汇的频率矩阵。 记录漂亮喜欢颜色质量丝巾满意100000020100003110000411000050000106100000710000080010009020000100000011101101012000000131002111400000015110100160100001710111018000000用户词汇频率矩阵表格的一行代表用户的一条评论,列代表高频词汇,表中的数据代表该条评论中出现的词汇频率。 结果及分析 K-均值聚类算法的虚假评论聚类结果用K-mean进行分析,选定初始类别中心点进行分类。 一般是随机选择数据对象作为初始聚类中心,由于kmeans聚类是无监督学习,因此需要先指定聚类数目。 层次聚类是另一种主要的聚类方法,它具有一些十分必要的特性使得它成为广泛应用的聚类方法。它生成一系列嵌套的聚类树来完成聚类。 从树的直观表示来看,当height取80的时候,树的分支可以大概分成2类,分成的类别比较清楚和直观,因此我们取k等于2,分别对应虚假评论和真实评论。
点击标题查阅往期内容
R语言文本挖掘:kmeans聚类分析上海玛雅水公园景区五一假期评论词云可视化
左右滑动查看更多
01
02
03
04
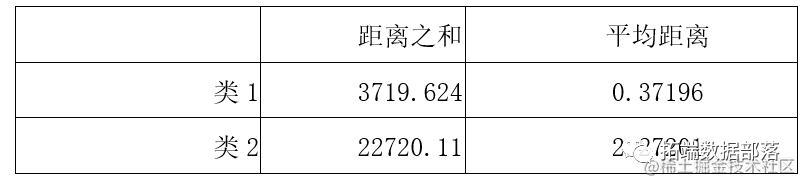
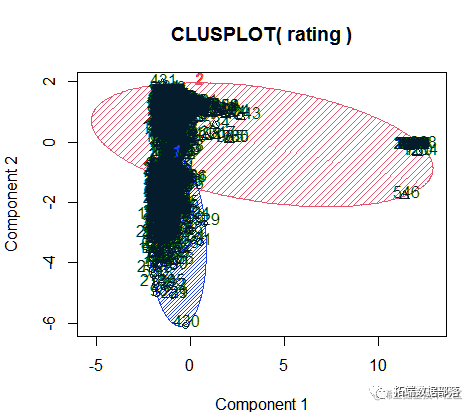
通过设定距离阈值k=2,我们找出了3356个异常值并将其剔除。 然后绘制聚类散点图,通过聚类图,我们可以看到真实评论和虚假评论明显地被分成了两个聚类簇。
最后对2个类分别做了词频统计,并用词频云表示每个类的特征。 真实评论 wordcloud(colnames(c
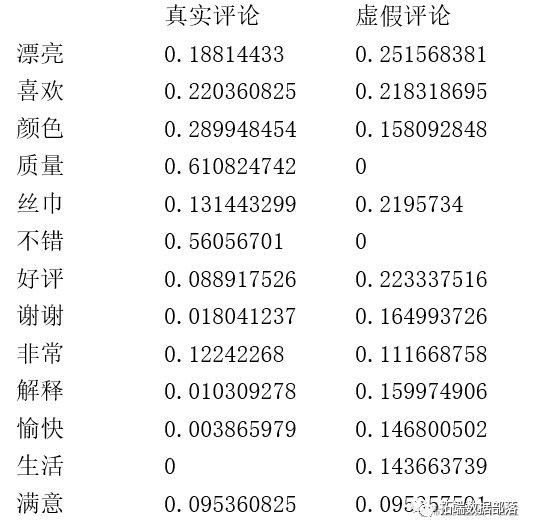
从词频云图可以看到,真实的评价中的主要关键词是质量,不错,色差等,从这些关键词来看,本文可以推测这类用户主要看重的是商品的功能性和质量型,并且主要集中在一些基本的特征,如质量、色差。也可以推测这些用户的商品评论没有太多华丽的词汇,而只是简单的不错,谢谢等。因此,可以认为真实的评论一般比较简单,并且会有一些对商品具体的方面的不足进行描述如色差,而不是一味的非常好、喜欢、愉快等。 虚假评论类别中主要的关键词是好评!,感恩!,美丽!,赏赐!、努力!祝愿!等词汇。从这些关键词我们大致可以推测这类用户主要使用的是一些华丽的词藻。他们比较看重评论的夸张度和给人的好感度,更在乎评论给别的买家造成的美好体验。这些用户往往使用很“完美”的评价,大多使用好评、美丽、感恩等评价很高的词汇,而没有很关注商品的质量和具体的细节,一般套用了相近的评论模板,因此可以认为是虚假评论。 参考文献[1]T Zhang.R.Ramakrishnan and M.ogihara.An efficient data clustering method for very largedatabases.In Pror.1996 ACM-SlGMOD hat.Conf.Management of Data,Montreal.Canada,June 1996:103.114. [2]邵峰晶,于忠清,王金龙,孙仁城 数据挖掘原理与算法(第二版) 北京:科学出版社 ,2011, ISBN 978-7-03-025440-5. [3]张建辉.K-meaIlS聚类算法研究及应用:[武汉理工大学硕士学位论文].武汉:武汉理工大学,2012. [4]冯超.K-means 类算法的研究:[大连理工大学硕士学位论文].大连:大连理工大学,2007. [5]曾志雄.一种有效的基于划分和层次的混合聚类算法.计算机应用,2007,27(7):1692.1695. [6]范光平.一种基于变长编码的遗传K-均值算法研究:[浙江大学硕士学位论文].杭州:浙江大学,2011. [7]孙士保,秦克云.改进的K-平均聚类算法研究.计算机工程,2007,33(13):200.202. [8]孙可,刘杰,王学颖.K均值聚类算法初始质心选择的改进.沈阳师范大学学报,2009,27(4):448-450. [9]Jain AK,Duin Robert PW,Mao JC.Statistical paaern recognition:A review.IEEE Trans.Actions on Paaem Analysis and Machine Intelligence,2000,22(1):4-37. [10]Sambasivam S,Theodosopoulos N.Advanced data clustering methods ofmining web documents.Issues in Informing Science and Information Technology,2006,8(3):563.579. 数据获取 在公众号后台回复“电商评论数据”,可免费获取完整数据。
点击文末“阅读原文” 获取全文完整代码数据资料。 本文选自《数据分享|R语言聚类、文本挖掘分析虚假电商评论数据:K-MEANS(K-均值)、层次聚类、词云可视化》。
点击标题查阅往期内容 【视频】文本挖掘:主题模型(LDA)及R语言实现分析游记数据 NLP自然语言处理—主题模型LDA案例:挖掘人民网留言板文本数据 Python主题建模LDA模型、t-SNE 降维聚类、词云可视化文本挖掘新闻组数据集 自然语言处理NLP:主题LDA、情感分析疫情下的新闻文本数据 R语言对NASA元数据进行文本挖掘的主题建模分析 R语言文本挖掘、情感分析和可视化哈利波特小说文本数据 Python、R对小说进行文本挖掘和层次聚类可视化分析案例 用于NLP的Python:使用Keras进行深度学习文本生成 长短期记忆网络LSTM在时间序列预测和文本分类中的应用 用Rapidminer做文本挖掘的应用:情感分析 R语言文本挖掘tf-idf,主题建模,情感分析,n-gram建模研究 R语言对推特twitter数据进行文本情感分析 Python使用神经网络进行简单文本分类 用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类 R语言文本挖掘使用tf-idf分析NASA元数据的关键字 R语言NLP案例:LDA主题文本挖掘优惠券推荐网站数据 Python使用神经网络进行简单文本分类 R语言自然语言处理(NLP):情感分析新闻文本数据 Python、R对小说进行文本挖掘和层次聚类可视化分析案例 R语言对推特twitter数据进行文本情感分析 R语言中的LDA模型:对文本数据进行主题模型topic modeling分析 R语言文本主题模型之潜在语义分析(LDA:Latent Dirichlet Allocation) R语言对NASA元数据进行文本挖掘的主题建模分析 R语言文本挖掘、情感分析和可视化哈利波特小说文本数据 Python、R对小说进行文本挖掘和层次聚类可视化分析案例 用于NLP的Python:使用Keras进行深度学习文本生成 长短期记忆网络LSTM在时间序列预测和文本分类中的应用 用Rapidminer做文本挖掘的应用:情感分析 R语言文本挖掘tf-idf,主题建模,情感分析,n-gram建模研究 R语言对推特twitter数据进行文本情感分析 Python使用神经网络进行简单文本分类 用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类 R语言文本挖掘使用tf-idf分析NASA元数据的关键字 R语言NLP案例:LDA主题文本挖掘优惠券推荐网站数据 Python使用神经网络进行简单文本分类 R语言自然语言处理(NLP):情感分析新闻文本数据 Python、R对小说进行文本挖掘和层次聚类可视化分析案例 R语言对推特twitter数据进行文本情感分析 R语言中的LDA模型:对文本数据进行主题模型topic modeling分析 R语言文本主题模型之潜在语义分析(LDA:Latent Dirichlet Allocation)
|












【本文地址】