| RVO:实时多智能体导航的交互速度避障 | 您所在的位置:网站首页 › rvo算法怎么结合a星 › RVO:实时多智能体导航的交互速度避障 |
RVO:实时多智能体导航的交互速度避障
|
原文地址:https://www.researchgate.net/publication/221073351_Reciprocal_Velocity_Obstacles_for_Real-Time_Multi-agent_Navigation 1. 简介近些年,多个移动智能体的运动规划问题成为一个越来越受关注的问题。无论在机器人领域,还是在视频游戏等多个其他领域,该问题都有很多的影响。解决这类问题的一个普遍思路是进行持续的导航。这些方法通常包括一个持续的“感知——行动”循环,在每个循环中,智能体通过感知模块观察周边环境,并通过行动模块进行移动。在这个过程中,全局路径规划和局部碰撞避让往往是解耦的。 因此,局部避障技术成为解决这类问题的关键技术,有很多人提出过各种方法。VO就是其中一种被广泛使用的方法。然而,这些模型通常都是基于障碍物是不能感知周围环境的非智能体,只能被动的沿预定速度运动的情况。然而这种假设导致这些模型无法适用在障碍物也可以进行避障,或多智能体互相避障的情形。在这种多智能体互相避障的情况下,往往会出现一些不符合预期的,且不真实的抖动现象。 2. 简单介绍VO及其问题关于VO避障的详细内容可以参照我的这篇文章:VO避障,本文只做简单的介绍。 2.1 VO避障的定义我们用A表示平面上正在进行移动的智能体,此时所在位置为PA,用B表示同一平面上的移动障碍物,此时位置为PB。用VOAB(VB)表示若持续以速度VB移动的情况下,在之后的某个时间会导致AB发生碰撞的所有A的速度VA的集合。 定义1: VOAB(VB) = { VA | λ(PA, VA - VB) ∩ B ⊕ -A ≠ φ} 其中: λ(p,v) = { p + tv | t >= 0}A ⊕ B = { a + b | a ∈ A,b ∈ B }-A = { -a | a 属于A }上式表明,如果VA ∈ VOAB(VB),那么A和B将在之后的某个时间发生碰撞,否则,VA便是在B的VO区域之外,二者将不会发生碰撞。如果VA位于VO的边界上,则在将来的某个时刻,A和B将会刚好擦肩而过(切线机动)。 图1: 现在,我们对VO的一些基本属性进行推导: 引理 2: 图2:
类似的,如果: 注意图2中,左半边和右半边区域有一部分重叠区域,这个区域内的速度会让A与B分离。 对于上文中所说的引理2和引理3,他们对于VO之外的区域依然有效。即,引理中的∈号可以被我们刚定义的两种符号中的任意一种代替。 引理4: 在将VO避障的概念应用与多个智能体的导航场景中时,每个智能体都会将其他的智能体视为移动的障碍物,并根据对方的信息和自己的信息计算生成VO区域,然后从VO之外的区域中选择一个速度进行避障。理想状态下,通过这一系列行为,将使二者避开彼此继续前进,然而,实际情况下,却可能会出现预期之外的抖动现象。 想象如下情景: 两个智能体A和B分别以VA和VB的速度前进,且VA和VB分别在对方的VO区域内。因此,如果双方继续以当前速度移动下去,必然会发生碰撞。此时,智能体A从针对B的VO区域之外选择了速度VA‘。同时,智能体B也进行了避障操作,从针对A的VO区域之外选择了速度VB’。 这种行动的结果是,A和B的速度都发生了变化,从而二者针对对方的VO区域也发生了变化。根据引理2,我们可以推导出,二者原来的速度都不在新的VO区域内: VB’ ∉ VOAB (vA) → VA ∉ VOBA (vB’) VA’ ∉ VOBA (vB) → VB ∉ VOAB (vA’) 如果A和B之前的速度(VA和VB)分别是各自的最优速度(如该速度是直接指向目标点的速度),而此时计算该速度并不在当下的VO区域内(新VO区域),那么A和B由于倾向性,会再次选择最优速度,也即VA和VB。于是二者又再次回到原来的状态,并且在下一个循环中再次重复上面的行为,从而产生抖动现象。 3. RVO介绍本节中我们将介绍一种解决上述抖动问题的新方法——RVO。它通过一种简单的方式来达到多智能体安全平滑的导航,并且在这个过程中,智能体之间不需要互相通信。 3.1 定义RVO的基本思想很简单:在避障行为的速度选择时,与VO避障中智能体单纯选择VO区域之外的速度不同,这里我们选择的新速度是VO之外的某个速度与当前速度的平均值。 RVO的一般定义如下: RVOAB(VB,VA) = {VA’ | 2VA’ - VA ∈ VOAB(VB)} RVOAB(VB,VA)表示A的当前速度与VO区域VOAB(VB)内任意速度的平均速度的集合。对原VO区域进行平移,使其顶点移动到(VA + VB)/2时,便可得到此RVO区域的范围,如下图: 图3: 下面我们将证明RVO的两点特性:无碰撞和无抖动。 3.2.1 无碰撞假设A当前速度VA,B当前速度VB,AB分别选择RVO区域之外的速度VA’ 和 VB’。在AB都选择自己的同一边(左或右)进行避障时,下面的引理会证明此时是安全无碰撞的。 引理6:
对于AB需要同时选择各自同一边的这个前提,当二者中有一个选择了RVO外与当前速度最接近的速度时(下文简称最近避障速度),我们可以证明得到,另外一个智能体,也会对应做出同一选择。这个论断基于以下事实: 对于智能体A,如果VA + u是其对于B的最近避障速度,那么对于智能体B,其对于A的最近避障速度为VB-u对于智能体A,如果其对于B的最近避障速度在RVO区域的右侧,则对于智能体B,其对于A的最近避障也位于RVO区域的右侧(左侧同理)。属于和不属于对于以上事实同样适用。 引理7: VA + u ∉ RVOAB(VB, VA) ↔ VB - u ∉ RVOBA(VA, VB) 证明: VA + u ∉ RVOAB(VB, VA) ↔ 2(VA + u) - VA ∉ VOAB(VB) ↔ 2(VB - u) - VB ∉ VOBA(VA) ↔ VB - u ∉ RVOBA(VA, VB) 3.2.3 无抖动当选择最近避障速度时,也可保证不会发生抖动现象。以下引理可证: 引理8: VA ∈ RVOAB(VB, VA) ↔ VA ∈ RVOAB(VB - u, VA + u) 证明: VA ∈ RVOAB(VB, VA) ↔ 2VA - VA - VB ∈ VOAB(0) ↔ 2VA - VA - VB - u + u ∈ VOAB(0) ↔ VA ∈ RVOAB(VB - u, VA + u) 由以上引理可知,对于智能体A而言,当AB同时选择最近避障速度时,AB的新速度分别是VA+ u 和 VB- u ,此时又构成了新的RVO区域 RVOAB(VB - u, VA + u),而A在避障前的旧速度VA仍然在此时的新RVO区域之内,因此A不会在之后再次选择VA,对于B同理,这样就避免了抖动现象的发生。 3.3 RVO推广在上面的内容中,我们隐式地假设了每个智能体在避免碰撞的过程中各自平均分担了相同的避让。而实际上,各个智能体之间可能在规避碰撞的过程中分别承担不同比例。基于这个理念,我们将RVO的概念进行推广。在AB避障模型中,我们定义αAB为整个避障过程中A所承担的部分,自然地,B所承担的部分即为αBA = 1 - αAB(可见,在之前的表述中,我们一直都是在隐式的假设 αAB = αBA = 1/2)。 其表达的思想是,对于智能体A而言,在避障时选择的新速度VA’不再是当前速度VA与RVO区域外的任意速度VRA二者的平均值(1/2 )VA + (1/2)VRA,而是按照一个动态的权重进行划分,即VA’ = αABVR + (1 - αAB)VA。整理可得 VR = (1/αAB)VA’ + (1 - 1/αAB)VA。智能体B同理。由此我们可以推广RVO的定义: RVOAB(VB, VA, αAB) = {VA’ | (1/αAB)VA’ + (1 - 1/αAB)VA ∈ VOAB(VB)} 同样的,对原VO区域进行平移,使其顶点位于点(1 - αAB)VA + αABVB 时,便可得到此时RVO区域的范围,如下图。 图4: 本节介绍的是RVO在拥有大量智能体以及静态和非静态非智能障碍物的环境中的应用。 给定n个智能体A1…An,每个智能体Ai对应的当前位置表示为Pi,当前速度表示为Vi,目标位置表示为gi,优先速度表示为Vprefi。此外,用O表示非智能障碍物o的集合,Po表示障碍物的当前位置,VO表示障碍物的当前速度。对于静态障碍物,速度为0. 整体过程如下: 首先我们选定一个很短的时间段作为模拟过程的时间间隔,表示为Δt在每个时间段内,为每个智能体独立地选择新的速度,并据此更新其位置持续这个过程,直到所有智能体都达到其目标位置因此,在整个模拟过程中,每一步的新速度选择是最关键的地方。 4.1 CRVO(组合RVO区域)在之前的内容中,我们探讨了由一对智能体组成的系统的RVO区域。当环境扩展为由许多个智能体组成,并且包含静态和非静态非智能障碍物时,对于其中的任意一个智能体Ai而言,其要面对的RVO区域RVOi就变成了它对于其他所有智能体的独立RVO区域,以及对于非智能障碍物的VO区域的组合区域。可见,RVOi为组合RVO区域,即CRVO。CRVO的定义如下: RVOi = Uj≠iRVOij(vj, vi, αij) ∪ Uo∈OVOio(Vo) 理论上,每个智能体在选择速度时,只要从其CRVO区域之外选择,就可以无碰撞地导航直到目标位置。 4.2 AV区域(可达速度集合)在实际情况中,对于拥有速度Vi的任意智能体Ai,可能会存在某些运动学和动力学约束,从而对其能够实际达到的速度产生约束。我们将其能够实际达到的速度的集合用AVi(vi)表示。对于不同的智能体,由于其特性不同,可达速度集合也会有不同的情况。比如,假设智能体Ai存在最大速度 Vmaxi 和最大加速度 amaxi ,那么它的可达速度集合为: AVi(Vi) = {VI’ | ||Vi’|| < Vmaxi ∩ ||Vi’ - Vi|| < amaxiΔt } 4.3 速度选择在每个模拟循环的开始,我们需要先为每个智能体 Ai 确定它此时的最优速度,这个速度应该是直接指向其目标点的,用Vprefi 表示。接下来,需要为每个智能体选择新的速度作为当前速度。理想情况下,这个新速度应该在智能体Ai 的CRVO区域之外、在其可达速度集合之内,且与此时的最优速度最相近。然而,实际环境中可能存在着过多的智能体和障碍物,使得CRVO完全填满了AV区域。为了解决这个问题,在选择速度时,允许选择CRVO内的速度,即只要速度位于可达速度集合内就可以被选择。同时,对于每个速度都定义了一个惩罚值 penaltyi(Vi’)。这个值的大小与两方面因素有关:1是当前选择速度与此时最优速度的距离,2是当前选择速度导致碰撞的预期发生时间。由此,惩罚值的定义如下: penaltyi(Vi’) = wi / tci(Vi’) + || Vprefi - Vi’ || 其中wi是用于表示智能体在某些方面的特性,比如攻击性、活跃性之类的,会根据智能体的不同具体情况而定。 tci(Vi’)表示碰撞的预期发生时间,计算也很简单: 对于非智能体的VOAB(VB), 可以通过求解等式 λ(PA, VA - VB) = B ⊕ −A来得到对于智能体的RVOAB(VB, VA),可以通过求解λ(PA, 2VA - VA - VB) = B ⊕ −A得到对于CRVO,碰撞的预期发生时间所有智能体和非智能体求得的 tci(Vi’) 中的最小值对于CRVO之外的速度,也就是不会发生碰撞的情况,tci(Vi’) 为无限大我们通过对于可达速度区域AVi(Vi)内的速度进行均匀的随机采样,并计算样本速度的惩罚值,以惩罚值最低的一个作为本次选择的最新速度。 4.4 邻近区域上文我们曾经提到过,在CRVO的情况下,计算惩罚值中的碰撞预期发生时间时,是取的所有智能体和非智能体中预期碰撞时间的最小值,对于那些与Ai距离过于遥远的对象来说,与它们发生碰撞的预期时间显然更长,计算出来的值根本不会被选中,因此,在实际的计算过程当中,完全可以节省下这部分计算量。 我们以Ai的当前位置为中心定义了一个区域,称为邻近区域,用 NRi 表示,只有在邻近区域之内的智能体和非智能体才会速度选择时被计算在内。通过这种方式,便可减少很多计算量,对算法进行优化。至于邻近区域的最优大小,则可能跟环境内物体的平均速度、模拟的时间间隔等诸多因素有关。 此外,邻近区域除了减少计算量,提高运行效率之外,也可以用于对某些自然特性的实现,比如视野范围等。 5. 实验数据略 |
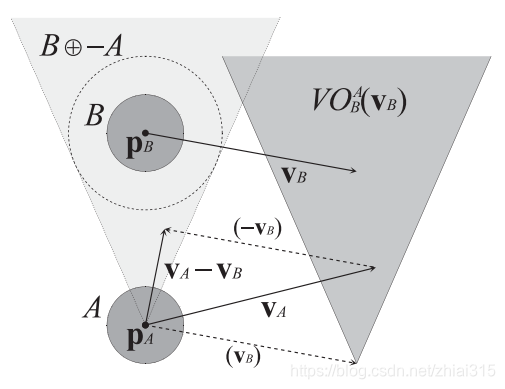 上图为VO区域的示意图,由图可知,VO区域是一个以VB为顶点的圆锥形。
上图为VO区域的示意图,由图可知,VO区域是一个以VB为顶点的圆锥形。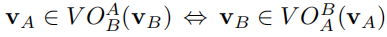 引理 3:
引理 3: 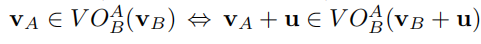 从上文定义1即可推导出引理2和引理3.
从上文定义1即可推导出引理2和引理3.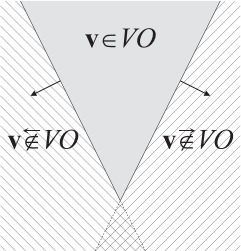 此时,我们将VO之外的区域也考虑进去,如上图所示,通过VO 区域的两条边界,将VO之外的区域分成两个半平面。并且我们增加两种符号:
此时,我们将VO之外的区域也考虑进去,如上图所示,通过VO 区域的两条边界,将VO之外的区域分成两个半平面。并且我们增加两种符号: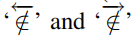 如果:
如果: 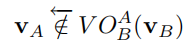 表示VA位于VO之外的左半边区域内,这个区域内的速度会让A从B的左侧穿过。
表示VA位于VO之外的左半边区域内,这个区域内的速度会让A从B的左侧穿过。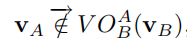 则表示VA位于VO之外的右半边区域内,这个区域内的速度会让A从B的右侧穿过。
则表示VA位于VO之外的右半边区域内,这个区域内的速度会让A从B的右侧穿过。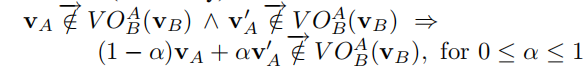
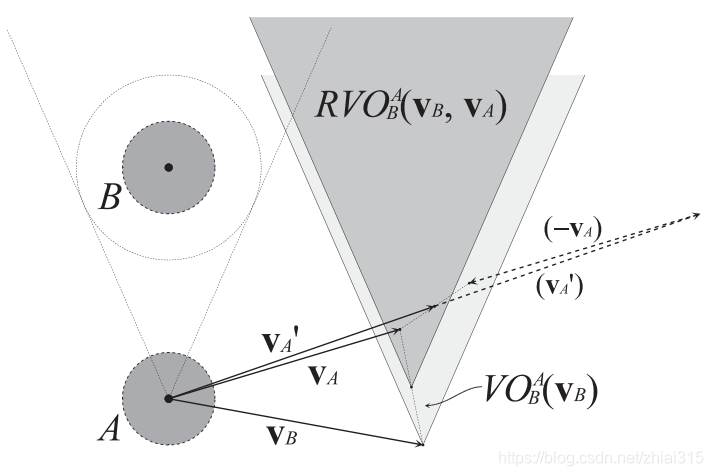
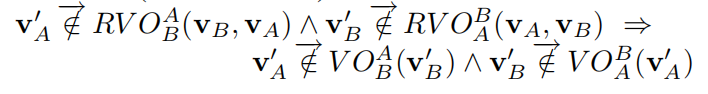
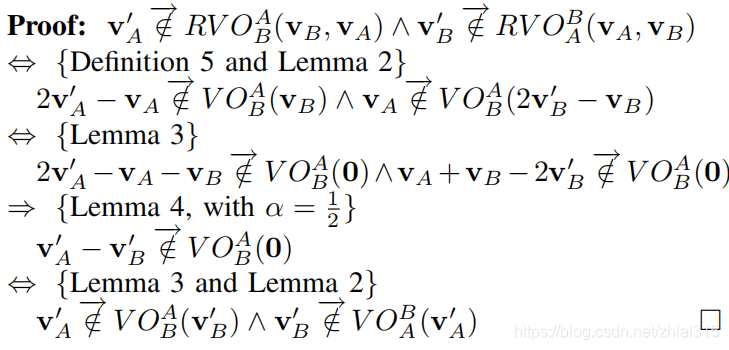 这里的符号实在打不出来。。。就直接截图了,证明过程很简单,运用上文的各种引理很容易就能推导得出。
这里的符号实在打不出来。。。就直接截图了,证明过程很简单,运用上文的各种引理很容易就能推导得出。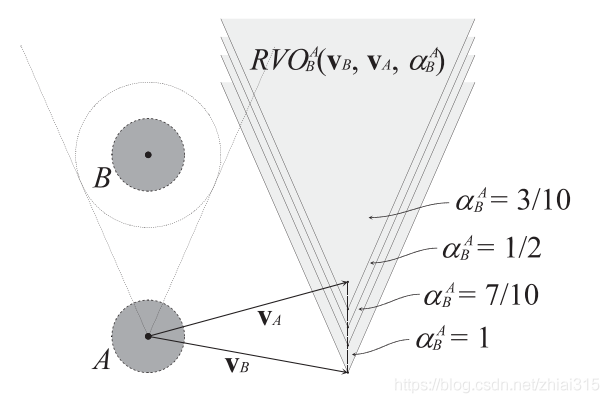 上文中的各个引理对于RVO的推广定义依然适用(有兴趣的老板自己证吧),因此对于广义的RVO来讲,依然是满足无碰撞无抖动的。
上文中的各个引理对于RVO的推广定义依然适用(有兴趣的老板自己证吧),因此对于广义的RVO来讲,依然是满足无碰撞无抖动的。【本文地址】