| 从头学pytorch(五) 多层感知机及其实现 | 您所在的位置:网站首页 › pytorch感知机 › 从头学pytorch(五) 多层感知机及其实现 |
从头学pytorch(五) 多层感知机及其实现
|
多层感知机
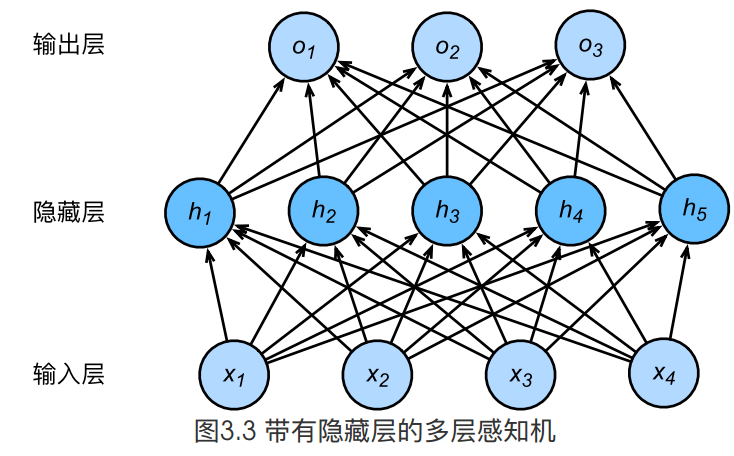
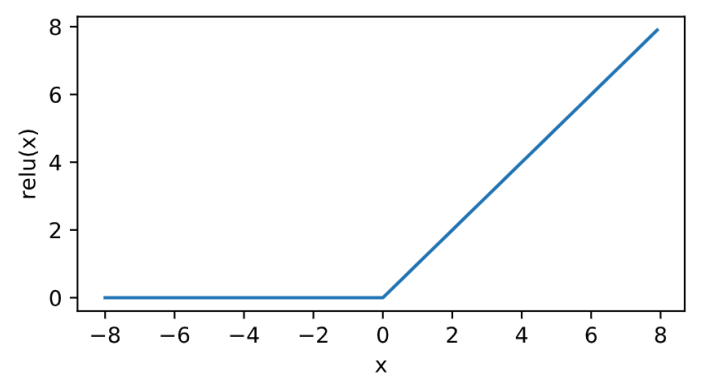
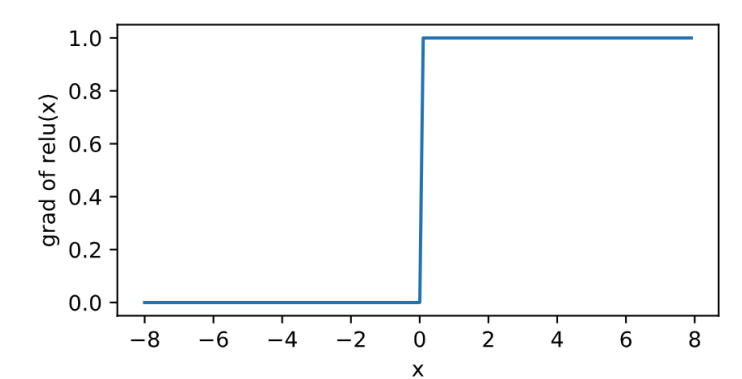
上图所示的多层感知机中,输入和输出个数分别为4和3,中间的隐藏层中包含了5个隐藏单元(hidden unit)。由于输入层不涉及计算,图3.3中的多层感知机的层数为2。由图3.3可见,隐藏层中的神经元和输入层中各个输入完全连接,输出层中的神经元和隐藏层中的各个神经元也完全连接。因此,多层感知机中的隐藏层和输出层都是全连接层。 具体来说,给定一个小批量样本\(\boldsymbol{X} \in \mathbb{R}^{n \times d}\),其批量大小为\(n\),输入个数为\(d\)。假设多层感知机只有一个隐藏层,其中隐藏单元个数为\(h\)。记隐藏层的输出(也称为隐藏层变量或隐藏变量)为\(\boldsymbol{H}\),有\(\boldsymbol{H} \in \mathbb{R}^{n \times h}\)。因为隐藏层和输出层均是全连接层,可以设隐藏层的权重参数和偏差参数分别为\(\boldsymbol{W}_h \in \mathbb{R}^{d \times h}\)和 \(\boldsymbol{b}_h \in \mathbb{R}^{1 \times h}\),输出层的权重和偏差参数分别为\(\boldsymbol{W}_o \in \mathbb{R}^{h \times q}\)和\(\boldsymbol{b}_o \in \mathbb{R}^{1 \times q}\)。 我们先来看一种含单隐藏层的多层感知机的设计。其输出\(\boldsymbol{O} \in \mathbb{R}^{n \times q}\)的计算为 \[\begin{aligned} \boldsymbol{H} &= \boldsymbol{X} \boldsymbol{W}_h + \boldsymbol{b}_h,\\ \boldsymbol{O} &= \boldsymbol{H} \boldsymbol{W}_o + \boldsymbol{b}_o, \end{aligned} \]也就是将隐藏层的输出直接作为输出层的输入。如果将以上两个式子联立起来,可以得到 \[\boldsymbol{O} = (\boldsymbol{X} \boldsymbol{W}_h + \boldsymbol{b}_h)\boldsymbol{W}_o + \boldsymbol{b}_o = \boldsymbol{X} \boldsymbol{W}_h\boldsymbol{W}_o + \boldsymbol{b}_h \boldsymbol{W}_o + \boldsymbol{b}_o. \]从联立后的式子可以看出,虽然神经网络引入了隐藏层,却依然等价于一个单层神经网络:其中输出层权重参数为\(\boldsymbol{W}_h\boldsymbol{W}_o\),偏差参数为\(\boldsymbol{b}_h \boldsymbol{W}_o + \boldsymbol{b}_o\)。不难发现,即便再添加更多的隐藏层,以上设计依然只能与仅含输出层的单层神经网络等价。 激活函数上面问题的根源就在于每一层的变换都是线性变换.线性变换的叠加依然是线性变换,所以,我们需要引入非线性.即对隐藏层的输出经过激活函数后,再作为输入输入到下一层. 几种常见的激活函数: relu sigmoid tanh relu \[\text{ReLU}(x) = \max(x, 0). \]其曲线及导数的曲线图绘制如下:
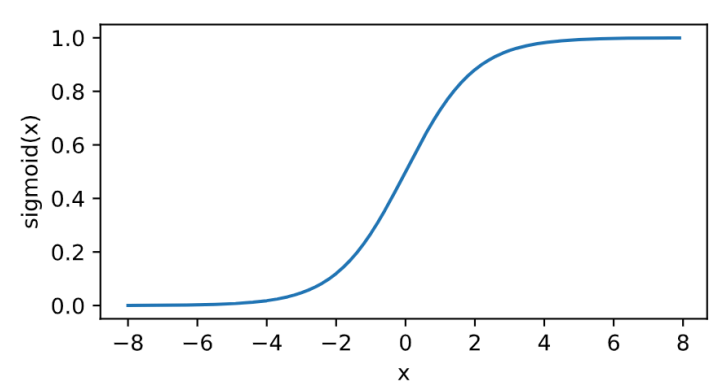
其曲线及导数的曲线图绘制如下: \[\text{sigmoid}(x) = \frac{1}{1 + \exp(-x)}. \]
其曲线及导数的曲线图绘制如下:
依然是之前用到的FashionMNIST数据集 batch_size = 256 num_workers = 4 # 多进程同时读取 def load_data(batch_size,num_workers): mnist_train = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST', train=True, download=True, transform=transforms.ToTensor()) mnist_test = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST', train=False, download=True, transform=transforms.ToTensor()) train_iter = torch.utils.data.DataLoader( mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers) test_iter = torch.utils.data.DataLoader( mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers) return train_iter,test_iter train_iter,test_iter = load_data(batch_size,num_workers) 模型参数初始化我们的神经网络有2层,所以相应的参数变成[W1,b1,W2,b2] ## num_inputs, num_outputs, num_hiddens = 784, 10, 256 #假设隐藏层有256个神经元 W1 = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_hiddens)), dtype=torch.float) b1 = torch.zeros(num_hiddens, dtype=torch.float) W2 = torch.tensor(np.random.normal(0, 0.01, (num_hiddens,num_outputs)), dtype=torch.float) b2 = torch.zeros(num_outputs, dtype=torch.float) params = [W1,b1,W2,b2] for param in params: param.requires_grad_(requires_grad=True) 模型定义模型需要用到激活函数relu以及将输出转换为概率的函数softmax. 所以首先定义好relu和softmax. relu定义: def relu(X): #print(X.shape) return torch.max(input=X,other=torch.zeros(X.shape))torch.max用法 softmax定义: def softmax(X): # X.shape=[样本数,类别数] X_exp = X.exp() partion = X_exp.sum(dim=1, keepdim=True) # 沿着列方向求和,即对每一行求和 #print(partion.shape) return X_exp/partion # 广播机制,partion被扩展成与X_exp同shape的,对应位置元素做除法模型结构定义: def net(X): X = X.view((-1,num_inputs)) #print(X.shape) H = relu(torch.matmul(X,W1) + b1) #print(H.shape) output = torch.matmul(H,W2) + b2 return softmax(output) 损失函数定义 def cross_entropy(y_hat, y): y_hat_prob = y_hat.gather(1, y.view(-1, 1)) # ,沿着列方向,即选取出每一行下标为y的元素 return -torch.log(y_hat_prob) 优化器定义 def sgd(params, lr, batch_size): for param in params: param.data -= lr * param.grad / batch_size # 注意这里更改param时用的param.data 模型训练定义精度评估函数 def evaluate_accuracy(data_iter, net): acc_sum, n = 0.0, 0 for X, y in data_iter: acc_sum += (net(X).argmax(dim=1) == y).float().sum().item() n += y.shape[0] return acc_sum / n训练: 数据加载 前向传播 计算loss 反向传播,计算梯度 根据梯度值,更新参数 清空梯度 加载下一个batch的数据,循环往复. num_epochs, lr = 5, 0.1 def train(): for epoch in range(num_epochs): train_l_sum, train_acc_sum, n = 0.0, 0.0, 0 for X, y in train_iter: #print(X.shape,y.shape) y_hat = net(X) l = cross_entropy(y_hat, y).sum() # 求loss l.backward() # 反向传播,计算梯度 sgd(params, lr, batch_size) # 根据梯度,更新参数 W1.grad.data.zero_() # 清空梯度 b1.grad.data.zero_() W2.grad.data.zero_() # 清空梯度 b2.grad.data.zero_() train_l_sum += l.item() train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item() n += y.shape[0] test_acc = evaluate_accuracy(test_iter, net) print('epoch %d, loss %.4f, train_acc %.3f,test_acc %.3f' % (epoch + 1, train_l_sum / n, train_acc_sum/n, test_acc)) train()输出如下: epoch 1, loss 1.0535, train_acc 0.629,test_acc 0.760 epoch 2, loss 0.6004, train_acc 0.789,test_acc 0.788 epoch 3, loss 0.5185, train_acc 0.819,test_acc 0.824 epoch 4, loss 0.4783, train_acc 0.833,test_acc 0.830 epoch 5, loss 0.4521, train_acc 0.842,test_acc 0.832 多层感知机的简单实现 必要的模块导入 import torch import torch.nn as nn import torch.nn.init as init import numpy as np #import matplotlib.pylab as plt import sys import torchvision import torchvision.transforms as transforms 获取和读取数据 batch_size = 256 num_workers = 4 # 多进程同时读取 def load_data(batch_size,num_workers): mnist_train = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST', train=True, download=True, transform=transforms.ToTensor()) mnist_test = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST', train=False, download=True, transform=transforms.ToTensor()) train_iter = torch.utils.data.DataLoader( mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers) test_iter = torch.utils.data.DataLoader( mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers) return train_iter,test_iter train_iter,test_iter = load_data(batch_size,num_workers) 模型定义及参数初始化这里我们使用torch.nn中自带的实现. 由于后续要定义的损失函数nn.nn.CrossEntropyLoss中包含了softmax的操作,所以这里不再需要定义relu和softmax. class Net(nn.Module): def __init__(self,num_inputs, num_outputs, num_hiddens): super(Net,self).__init__() self.l1 = nn.Linear(num_inputs,num_hiddens) self.relu1 = nn.ReLU() self.l2 = nn.Linear(num_hiddens,num_outputs) def forward(self,X): X=X.view(X.shape[0],-1) o1 = self.relu1(self.l1(X)) o2 = self.l2(o1) return o2 def init_params(self): for param in self.parameters(): #print(param.shape) init.normal_(param,mean=0,std=0.01) num_inputs, num_outputs, num_hiddens = 28*28,10,256 net = Net(num_inputs,num_outputs,num_hiddens) net.init_params() 定义损失函数 loss = nn.CrossEntropyLoss() 定义优化器 optimizer = torch.optim.SGD(net.parameters(),lr=0.5) 训练模型 def evaluate_accuracy(data_iter, net): acc_sum, n = 0.0, 0 for X, y in data_iter: acc_sum += (net(X).argmax(dim=1) == y).float().sum().item() n += y.shape[0] return acc_sum / n num_epochs=5 def train(): for epoch in range(num_epochs): train_l_sum, train_acc_sum, n = 0.0, 0.0, 0 for X, y in train_iter: y_hat=net(X) #前向传播 l = loss(y_hat,y).sum()#计算loss l.backward()#反向传播 optimizer.step()#参数更新 optimizer.zero_grad()#清空梯度 train_l_sum += l.item() train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item() n += y.shape[0] test_acc = evaluate_accuracy(test_iter, net) print('epoch %d, loss %.4f, train_acc %.3f,test_acc %.3f' % (epoch + 1, train_l_sum / n, train_acc_sum/n, test_acc)) train()输出如下: epoch 1, loss 0.0031, train_acc 0.709,test_acc 0.785 epoch 2, loss 0.0019, train_acc 0.823,test_acc 0.831 epoch 3, loss 0.0016, train_acc 0.844,test_acc 0.830 epoch 4, loss 0.0015, train_acc 0.855,test_acc 0.854 epoch 5, loss 0.0014, train_acc 0.866,test_acc 0.836可以看到这里的loss相比我们自己实现的loss小了很多,是因为torch里在计算loss的时候求的是这个batch的平均loss.我们自己实现的损失函数并没有求平均. |


【本文地址】